Size Doesn't Matter: Cosine-Scored Sparse Autoencoders
Pith reviewed 2026-07-01 07:12 UTC · model grok-4.3
The pith
Cosine-scored sparse autoencoders learn more human-recognizable features than inner-product ones at matched reconstruction quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
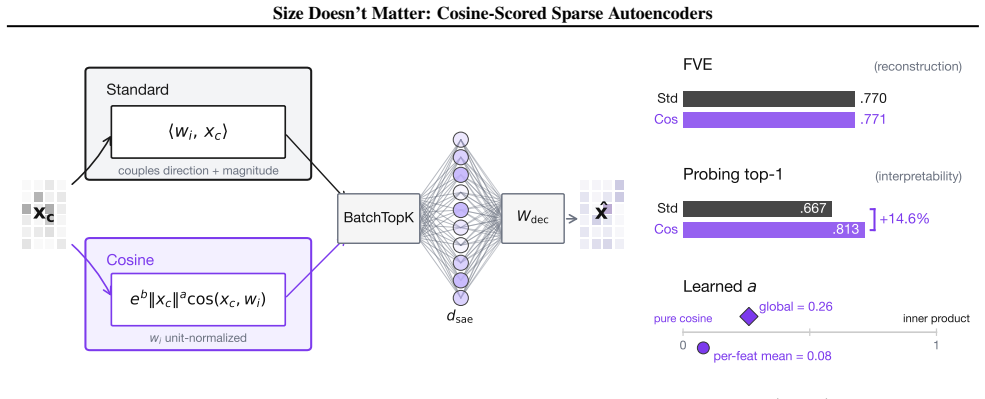
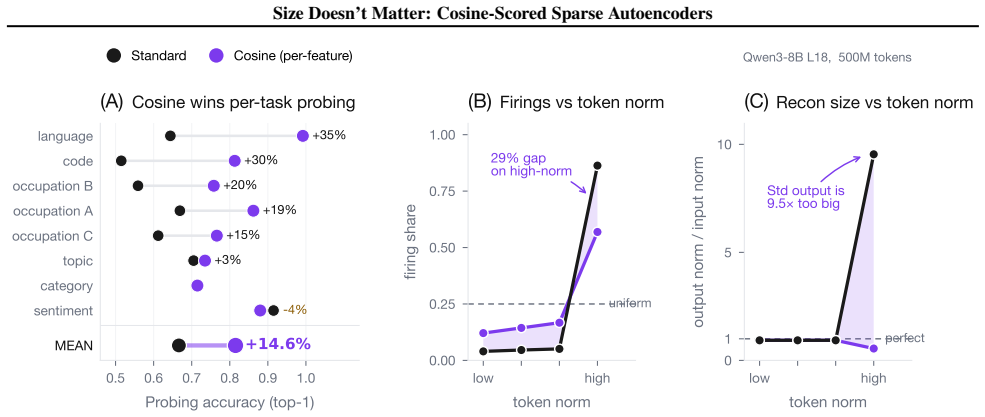
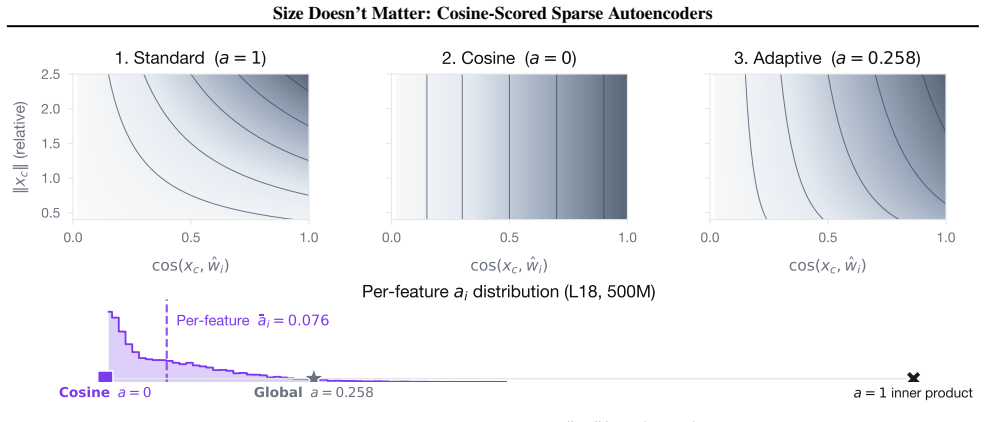
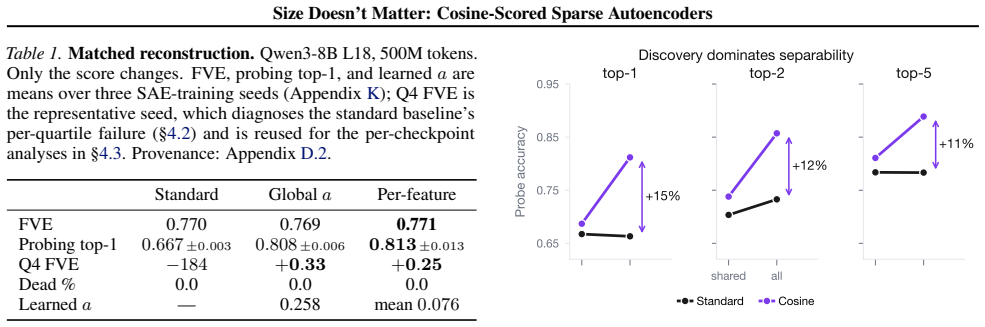
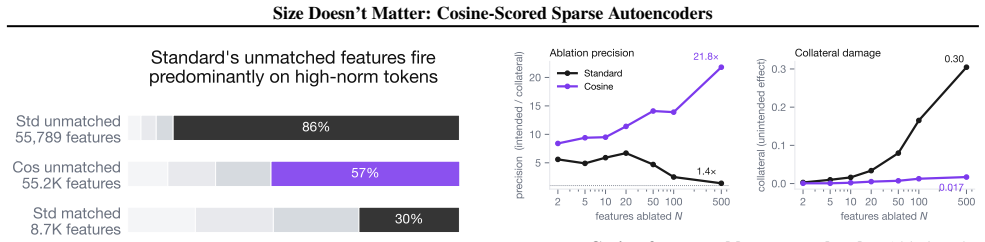
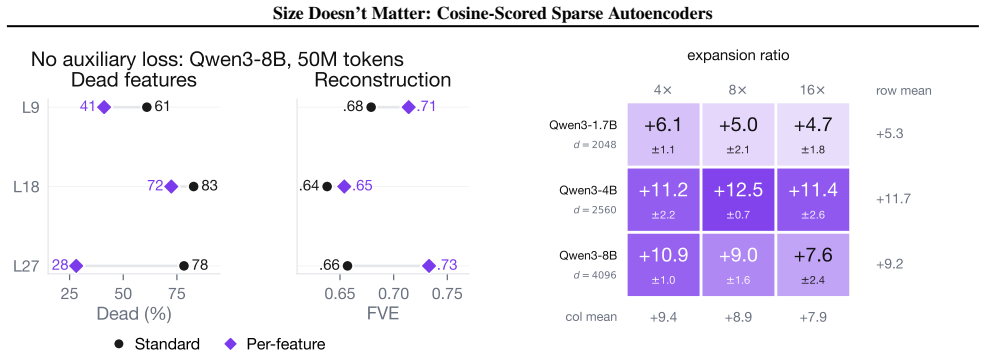
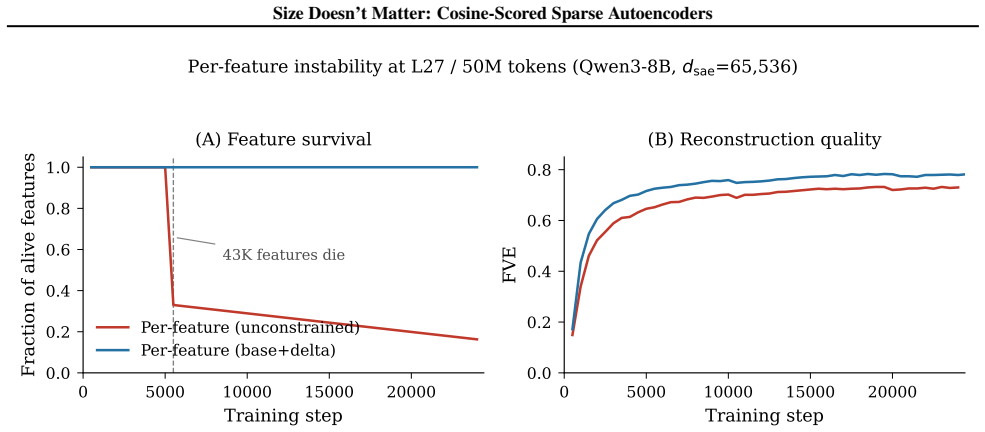
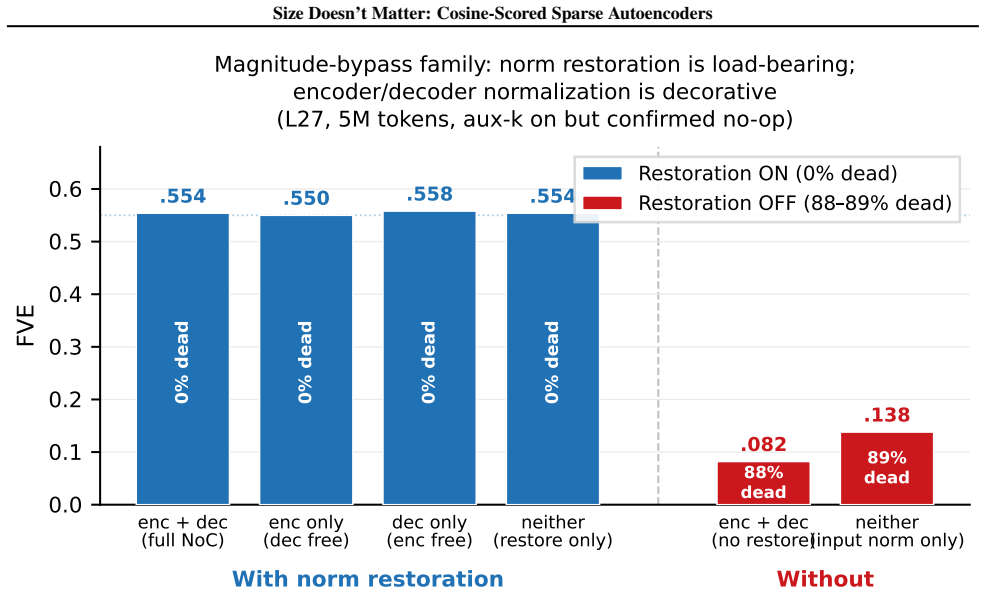
Replacing the inner-product score in sparse autoencoders with a learned blend of cosine similarity and input magnitude causes the optimizer to rely almost entirely on cosine similarity. No feature ever assigns more than half its weight to magnitude. At equal reconstruction loss, the cosine version produces substantially more features that align with human-recognizable concepts and fewer that activate only on token norm.
What carries the argument
The cosine-scored encoder, a learned linear combination of cosine similarity and input magnitude used in place of inner product for feature activation.
If this is right
- Dictionary capacity is no longer spent on norm-only detectors.
- More slots become available for directional, content-based features.
- Loss reweighting alone cannot replicate the gain; the scoring function geometry matters.
- The improvement is observed across some but not all depths and tasks.
- Cosine scoring is presented as the default choice for normalized representations.
Where Pith is reading between the lines
- Any dictionary-learning method on normalized activations could benefit from directional scoring to reduce wasted capacity.
- The same scoring change might improve other sparse coding techniques that currently rely on inner products.
- A direct test would be to run both scorers on the same non-normalized activations and compare feature quality.
- If the pattern holds, training pipelines for interpretability work could default to cosine scoring without added cost.
Load-bearing premise
Sublayer normalization has already removed all magnitude information that the model actually uses, rendering norm detection pointless.
What would settle it
Measure interpretability on a non-normalized layer or model where magnitude still carries signal; if cosine scoring loses its advantage there, the claim is falsified.
Figures



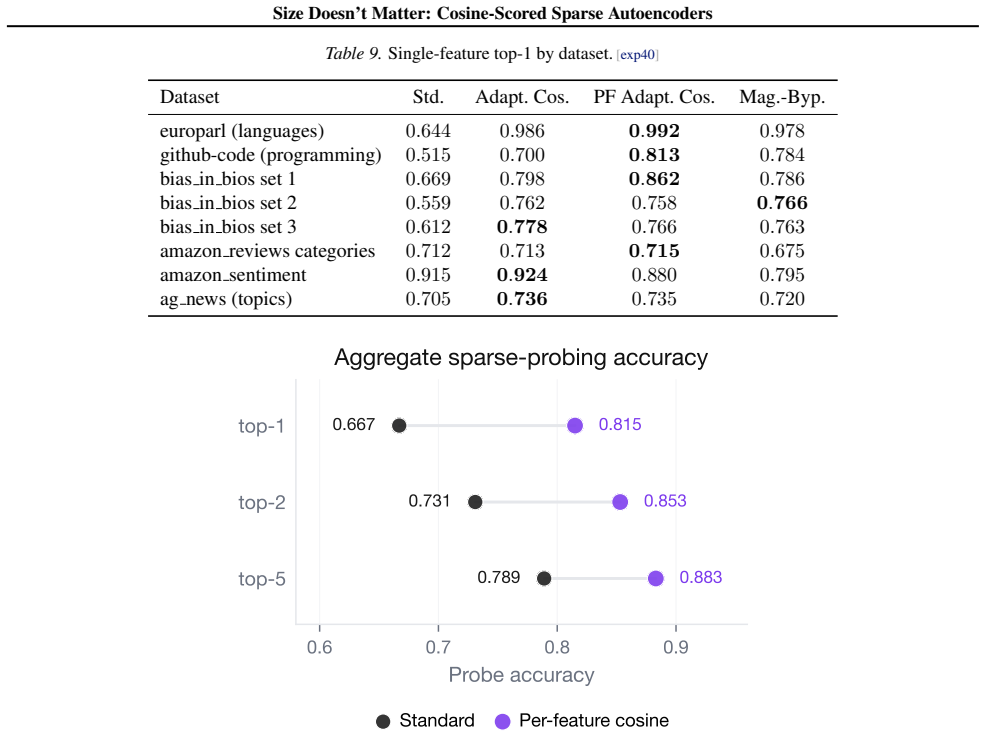
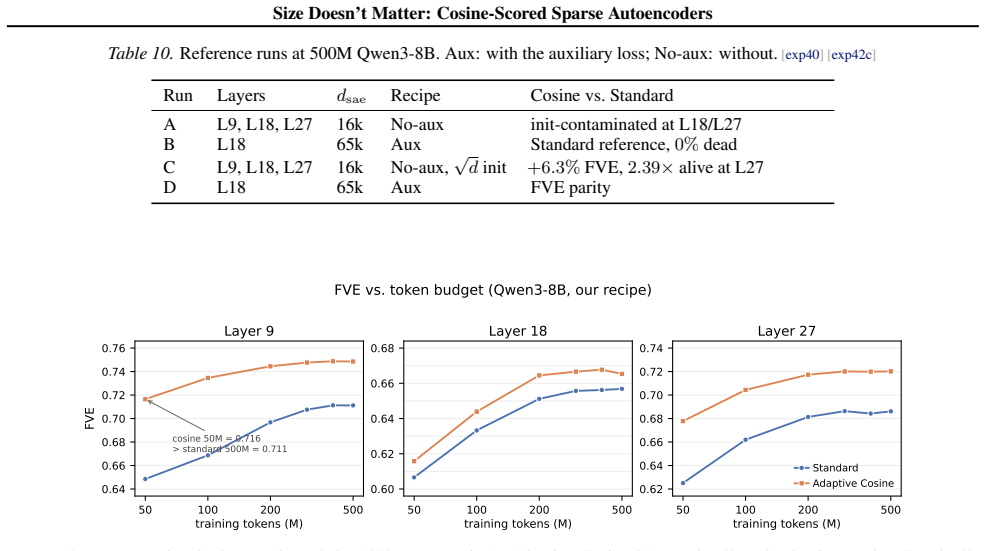
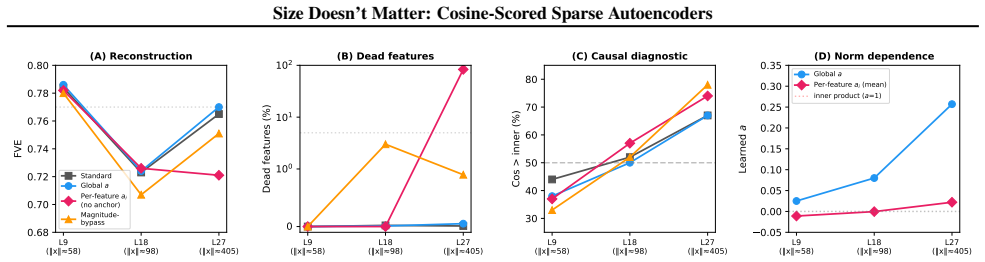
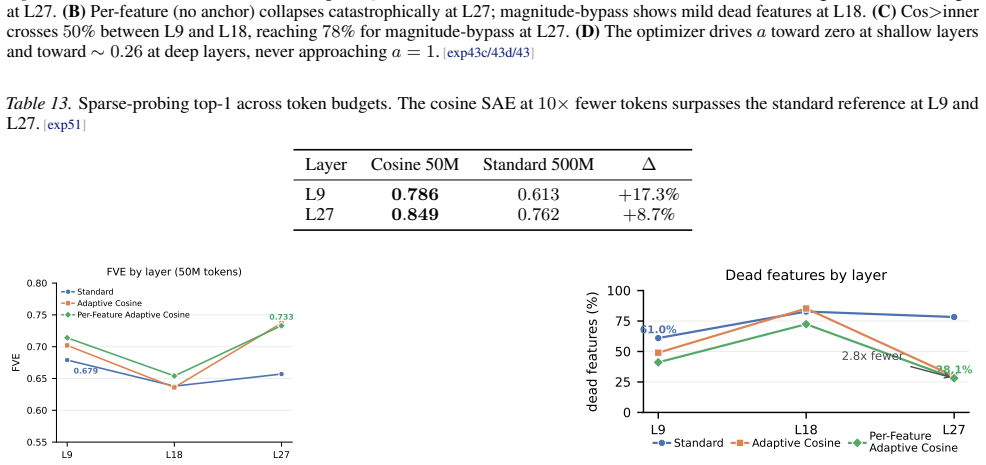
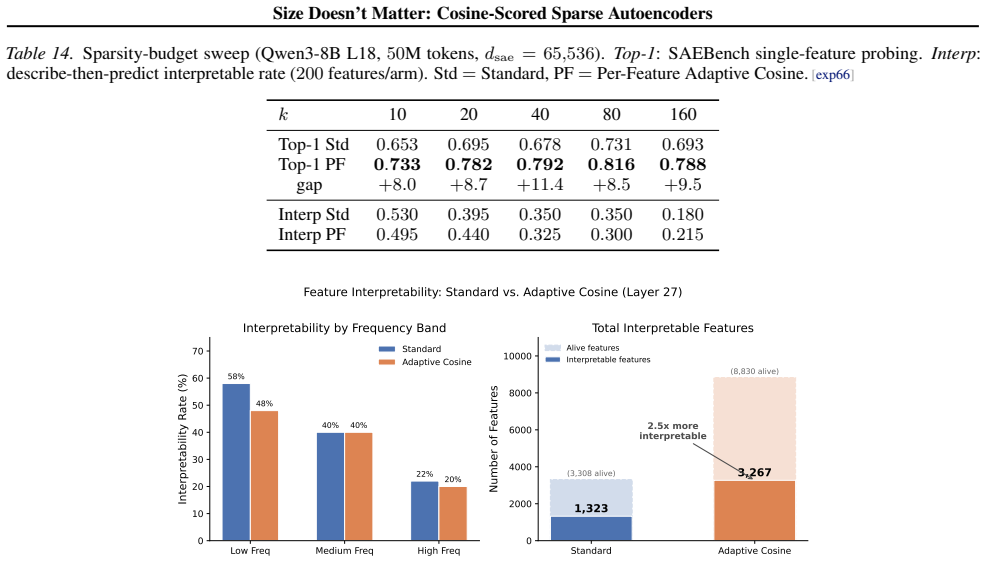
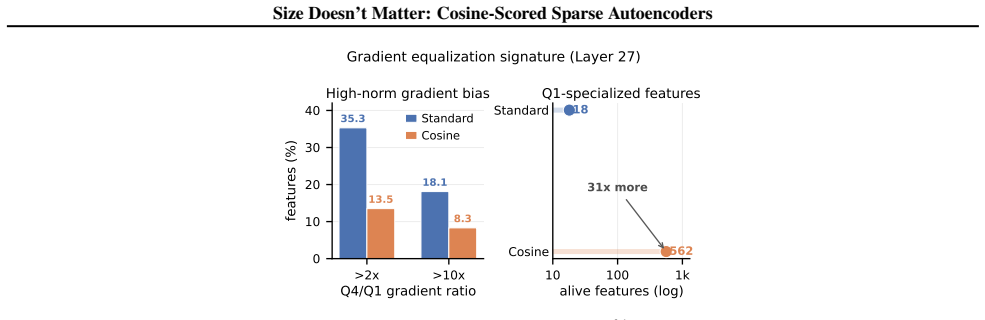
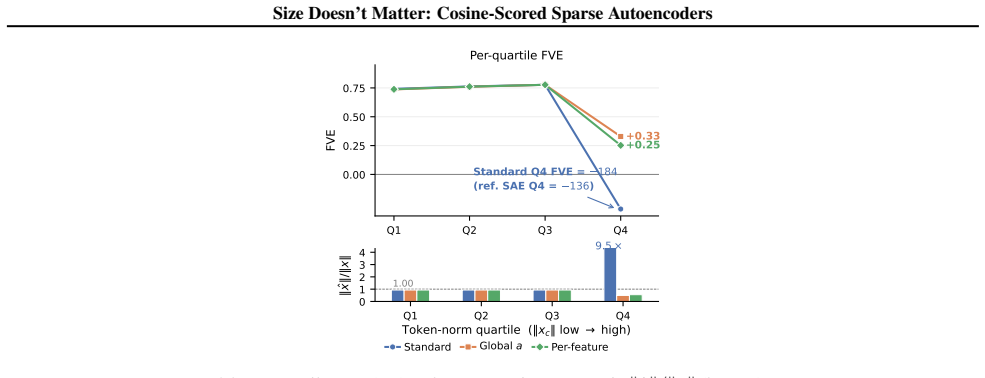
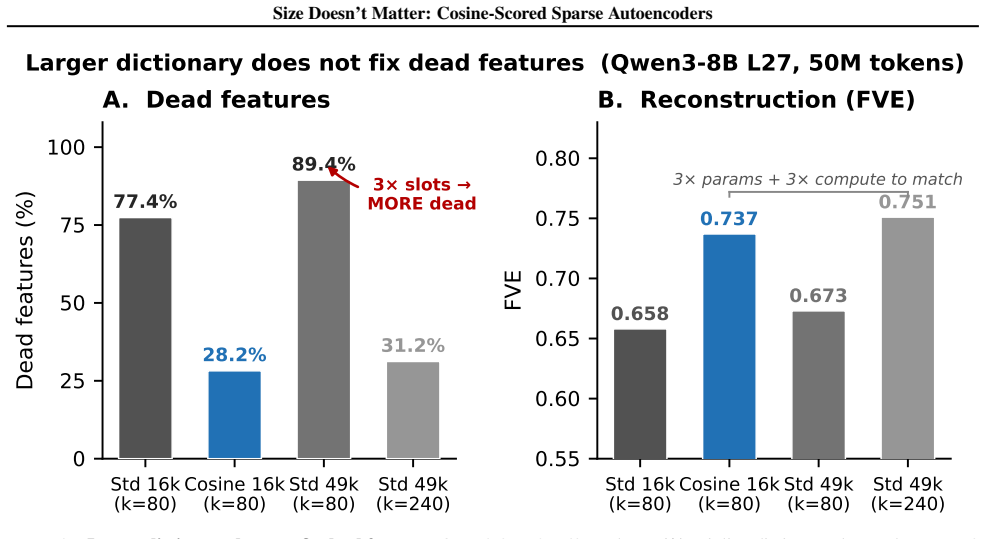
read the original abstract
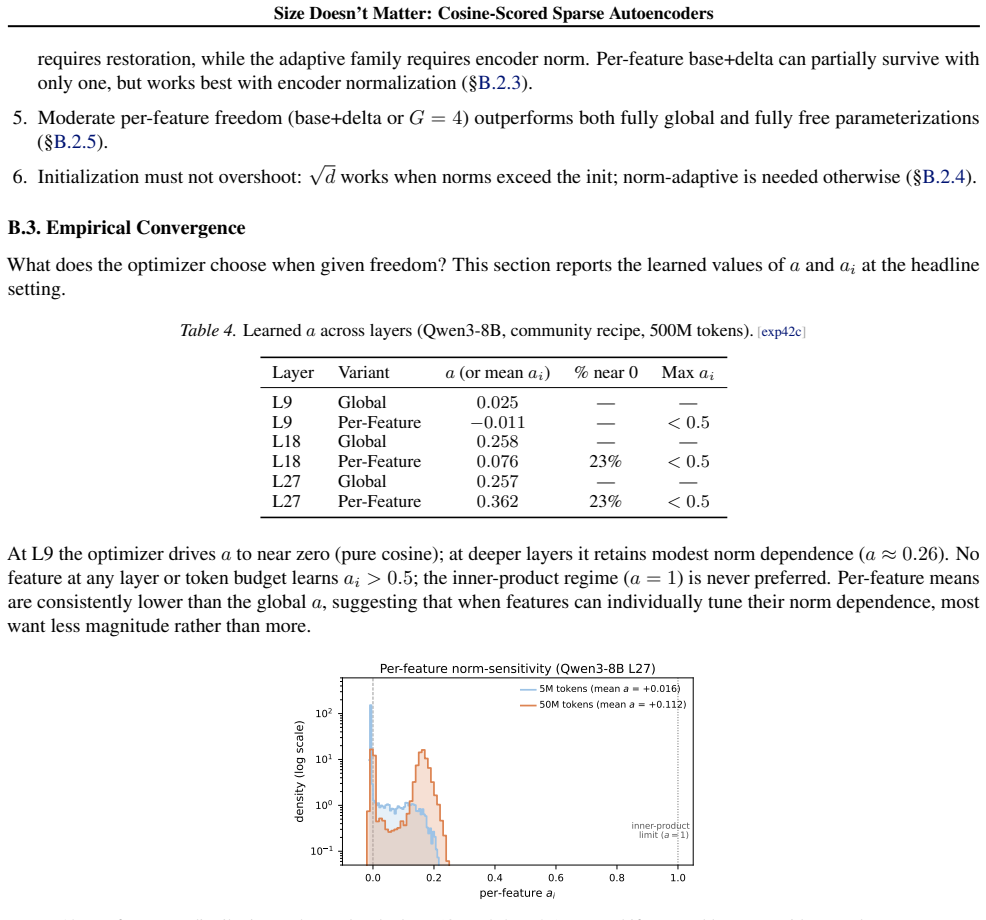
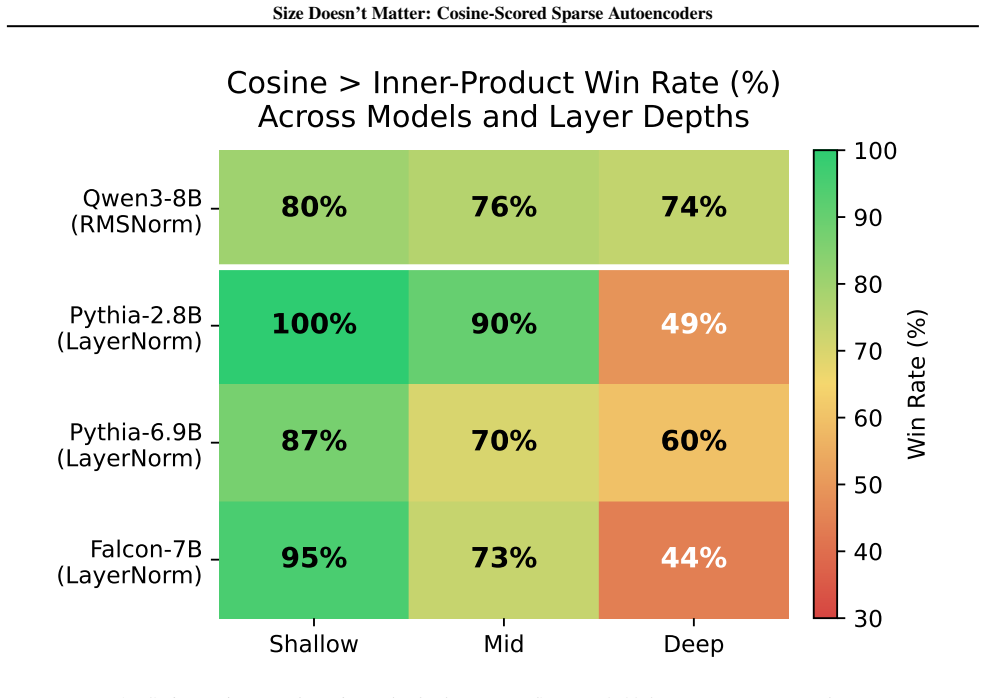
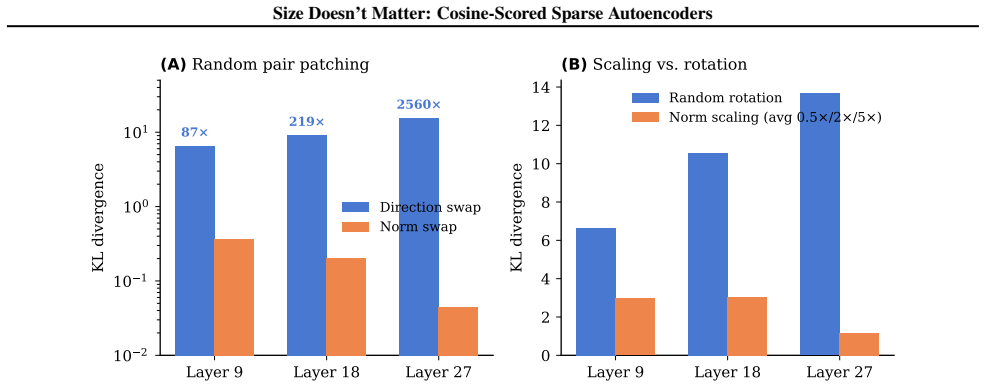
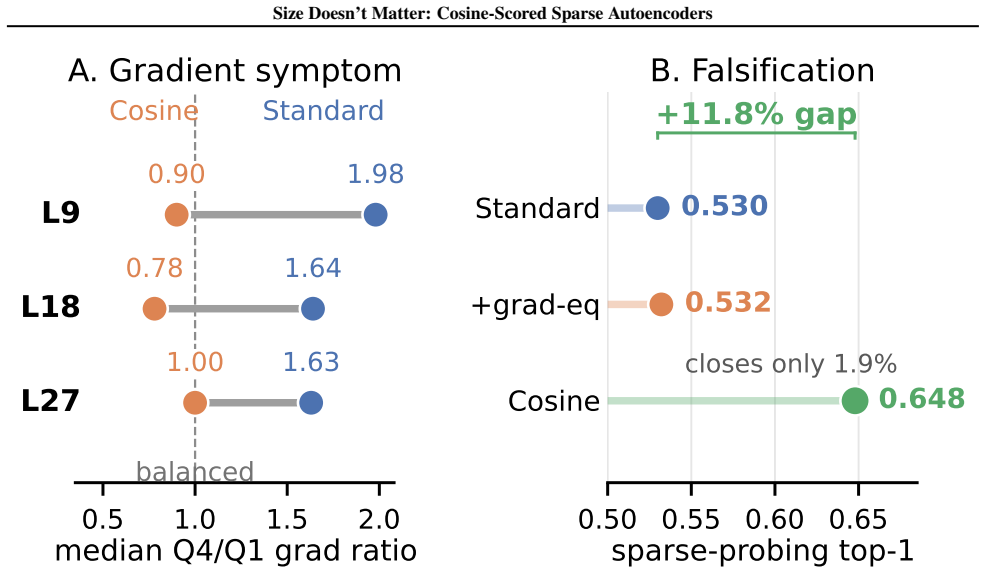
Sparse autoencoders (SAEs) detect features via inner product, so a feature's activation scales with both its directional alignment and the input's norm. Features that fire on token norm therefore claim dictionary slots regardless of content alignment. This matters because sublayer normalization has already discarded the magnitude the score measures, so the encoder detects a quantity the model does not read. We replace the score with a learned blend of cosine similarity and input magnitude, letting the optimizer choose how much norm to use; a per-feature extension lets each feature decide independently. In both regimes, training is free to recover inner product but never does, with no feature ever choosing more than half-magnitude dependence. At matched reconstruction, the cosine encoder learns features that align with human-recognizable concepts far more often than standard, filling dictionary slots that inner product wastes on norm detectors. Loss reweighting that equalizes gradients barely closes the gap, confirming forward-pass score geometry as the lever. The advantage is not universal across tasks or depths, but we believe cosine scoring should be the default for dictionary learning on normalized representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes cosine-scored (or blended cosine-magnitude) sparse autoencoders as a replacement for standard inner-product SAEs. It argues that inner-product scoring wastes dictionary capacity on norm detectors because activations scale with input magnitude, which sublayer normalization has already removed from the model's view; cosine scoring avoids this and yields more human-recognizable features at matched reconstruction error. Empirical results show the optimizer never recovers full inner-product behavior, loss reweighting does not close the gap, and the advantage is not universal across tasks or depths.
Significance. If the empirical advantage in feature interpretability holds under controlled conditions, the work would provide a simple, low-cost modification to dictionary learning that improves alignment with human concepts without sacrificing reconstruction. The observation that training never selects full magnitude dependence is a useful negative result. However, the claimed mechanism is undermined by the normalization premise itself.
major comments (2)
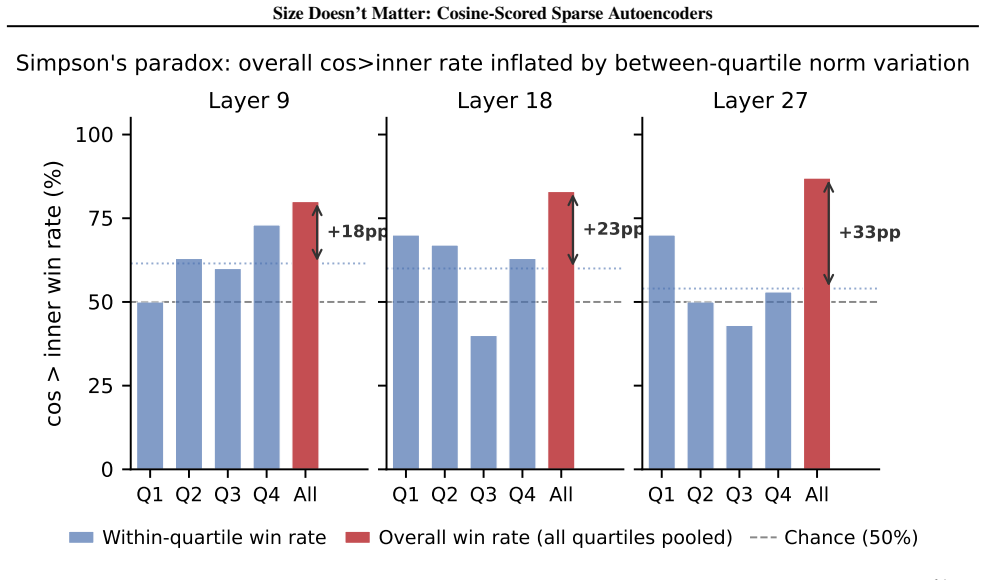
- [Abstract] Abstract and introduction: the core motivation states that inner-product SAEs 'waste dictionary slots on norm detectors' because 'sublayer normalization has already discarded the magnitude the score measures.' After LayerNorm/RMSNorm, ||x|| is fixed at approximately √d for every token, so f·x reduces to a constant times ||f||·cos(θ) with zero variance in the magnitude term. No feature can selectively detect 'token norm' because the quantity has no variance across inputs. This renders the stated reason for preferring cosine scoring internally inconsistent with the normalization premise used to motivate the work.
- [Abstract] The central empirical claim (cosine scoring produces more human-recognizable concepts at matched reconstruction) rests on the above motivation. Without a corrected account of why inner-product scoring underperforms, it is unclear whether the observed difference is due to score geometry or to some other uncontrolled factor in the training setup.
minor comments (1)
- [Abstract] Abstract supplies no quantitative metrics, dataset details, statistical tests, or operational definition of 'human-recognizable concepts,' making the strength of the reported advantage impossible to assess from the summary alone.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We agree that the motivational framing in the abstract and introduction contains an inconsistency regarding norm detection and will revise it. We address the comments point by point below.
read point-by-point responses
-
Referee: Abstract and introduction: the core motivation states that inner-product SAEs 'waste dictionary slots on norm detectors' because 'sublayer normalization has already discarded the magnitude the score measures.' After LayerNorm/RMSNorm, ||x|| is fixed at approximately √d for every token, so f·x reduces to a constant times ||f||·cos(θ) with zero variance in the magnitude term. No feature can selectively detect 'token norm' because the quantity has no variance across inputs. This renders the stated reason for preferring cosine scoring internally inconsistent with the normalization premise used to motivate the work.
Authors: We acknowledge that the original motivation is internally inconsistent as stated. Since the input norm is constant after normalization, there is no variance for features to detect 'token norm'. The actual issue with inner-product scoring is that the activation is scaled by the learned feature norm ||f||, which can cause the optimizer to favor features with larger norms irrespective of their conceptual alignment. This wastes dictionary capacity on features that are not purely direction-based. We will revise the abstract and introduction to provide a corrected account of why inner-product scoring underperforms, focusing on the role of feature norm in the score rather than input norm detection. revision: yes
-
Referee: The central empirical claim (cosine scoring produces more human-recognizable concepts at matched reconstruction) rests on the above motivation. Without a corrected account of why inner-product scoring underperforms, it is unclear whether the observed difference is due to score geometry or to some other uncontrolled factor in the training setup.
Authors: While the motivation requires correction, the empirical results stand on their own. We demonstrate through multiple experiments that the optimizer does not recover inner-product behavior, that reweighting the loss to balance gradients does not eliminate the advantage of cosine scoring, and that the improvement in feature interpretability occurs at matched reconstruction quality. These controls suggest the difference arises from the score geometry in the forward pass. We will update the manuscript to present the empirical findings with the revised mechanistic explanation. revision: partial
Circularity Check
No circularity; results are empirical comparisons
full rationale
The paper's claims rest on training multiple SAEs under different scoring regimes and reporting reconstruction quality plus human-interpretable feature counts. No derivation chain, fitted parameter, or self-citation is presented as a 'prediction' that reduces to the input by construction. The norm-detector motivation is an interpretive premise, not a load-bearing mathematical step that tautologically produces the reported advantage.
Axiom & Free-Parameter Ledger
free parameters (1)
- blend weight (global or per-feature)
axioms (1)
- domain assumption Sublayer normalization has already discarded the magnitude the score measures, so the encoder detects a quantity the model does not read.
Reference graph
Works this paper leans on
-
[1]
Root Mean Square Layer Normalization
Root Mean Square Layer Normalization , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 1910.07467 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[2]
Findings of the Association for Computational Linguistics: EMNLP , year =
Query-Key Normalization for Transformers , author =. Findings of the Association for Computational Linguistics: EMNLP , year =. 2010.04245 , archivePrefix =
-
[3]
Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
All Bark and No Bite: Rogue Dimensions in Transformer Language Models Obscure Representational Quality , author =. Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =. 2109.04404 , archivePrefix =
-
[4]
2022 , eprint =
Dettmers, Tim and Lewis, Mike and Belkada, Younes and Zettlemoyer, Luke , booktitle =. 2022 , eprint =
2022
-
[5]
The Linear Representation Hypothesis and the Geometry of Large Language Models
The Linear Representation Hypothesis and the Geometry of Large Language Models , author =. International Conference on Machine Learning (ICML) , year =. 2311.03658 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
International Conference on Learning Representations (ICLR) , year =
The Geometry of Categorical and Hierarchical Concepts in Large Language Models , author =. International Conference on Learning Representations (ICLR) , year =. 2406.01506 , archivePrefix =
-
[7]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and Goel, Shashwat and Li, Nathaniel and Byun, Michael J. and Wang, Zifan and Mallen, Alex and Basart, Steven and Koyejo, Sanmi and Song, Dawn and Fredrikson, Matt and Kolter, J. ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
2023 , eprint =
Linear Representations of Sentiment in Large Language Models , author =. 2023 , eprint =
2023
-
[9]
2023 , howpublished =
Towards Monosemanticity: Decomposing Language Models with Dictionary Learning , author =. 2023 , howpublished =
2023
-
[10]
2023 , eprint =
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author =. 2023 , eprint =
2023
-
[11]
2022 , eprint =
Toy Models of Superposition , author =. 2022 , eprint =
2022
-
[12]
2024 , eprint =
Scaling and Evaluating Sparse Autoencoders , author =. 2024 , eprint =
2024
-
[13]
2024 , eprint =
Improving Dictionary Learning with Gated Sparse Autoencoders , author =. 2024 , eprint =
2024
-
[14]
Jumping Ahead: Improving Reconstruction Fidelity with
Rajamanoharan, Senthooran and Lieberum, Tom and Sonnerat, Nicolas and Conmy, Arthur and Varma, Vikrant and Kram. Jumping Ahead: Improving Reconstruction Fidelity with. 2024 , eprint =
2024
-
[15]
Batchtopk sparse autoencoders.arXiv preprint arXiv:2412.06410,
Bussmann, Bart and Leask, Patrick and Nanda, Neel , year =. 2412.06410 , archivePrefix =
-
[16]
2025 , eprint =
Learning Multi-Level Features with Matryoshka Sparse Autoencoders , author =. 2025 , eprint =
2025
-
[17]
2025 , eprint =
Data Whitening Improves Sparse Autoencoder Learning , author =. 2025 , eprint =
2025
-
[18]
2025 , eprint =
Overcoming Sparsity Artifacts in Crosscoders to Interpret Chat-Tuning , author =. 2025 , eprint =
2025
-
[19]
Zhu, Xudong and Khalili, Mohammad Mahdi and Zhu, Zhihui , year =. 2510.00404 , archivePrefix =
-
[20]
Korznikov, Vladimir and Belrose, Nora and Sharkey, Lee , year =. 2509.22033 , archivePrefix =
-
[21]
Nasiri-Sarvi, Ali and others , year =. 2602.12403 , archivePrefix =
-
[22]
2026 , howpublished =
2026
-
[23]
2025 , eprint =
Karvonen, Adam and Rager, Can and Lin, Johnny and Tigges, Curt and Bloom, Joseph and Chanin, David and Lau, Yeu-Tong and Farrell, Eoin and Conmy, Arthur and McDougall, Callum and Lo Piano, Federico and Templeton, Adly and Marks, Sam and Wright, Benjamin and Bricken, Trenton and Conerly, Tom and Smith, Lewis and Nanda, Neel , booktitle =. 2025 , eprint =
2025
-
[24]
Gulko, Alex and Peng, Yusen and Kumar, Sachin , year =. 2509.00691 , archivePrefix =
-
[25]
2026 , eprint =
Chanin, David and Garriga-Alonso, Adri. 2026 , eprint =
2026
-
[26]
Wu, Zhengxuan and Arora, Aryaman and Geiger, Atticus and Wang, Zheng and Huang, Jing and Jurafsky, Dan and Manning, Christopher D. and Potts, Christopher , year =. 2501.17148 , archivePrefix =
-
[27]
arXiv preprint arXiv:2502.04878 , year=
Sparse Autoencoders Do Not Find Canonical Units of Analysis , author =. International Conference on Learning Representations (ICLR) , year =. 2502.04878 , archivePrefix =
-
[28]
arXiv preprint arXiv:2409.14507 , year=
A is for Absorption: Studying Feature Splitting and Absorption in Sparse Autoencoders , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2409.14507 , archivePrefix =
-
[29]
2026 , eprint =
Falsifying Sparse Autoencoder Reasoning Features in Language Models , author =. 2026 , eprint =
2026
-
[30]
2025 , eprint =
Measuring Sparse Autoencoder Feature Sensitivity , author =. 2025 , eprint =
2025
-
[31]
International Conference on Machine Learning (ICML) , year =
Interpretability Illusions in the Generalization of Simplified Models , author =. International Conference on Machine Learning (ICML) , year =. 2312.03656 , archivePrefix =
-
[32]
Michaud, Isaac Liao, Wes Gurnee, and Max Tegmark
Not All Language Model Features Are One-Dimensionally Linear , author =. International Conference on Learning Representations (ICLR) , year =. 2405.14860 , archivePrefix =
-
[33]
2026 , eprint =
From Directions to Regions: Decomposing Activations in Language Models via Local Geometry , author =. 2026 , eprint =
2026
-
[34]
2026 , eprint =
From Data Statistics to Feature Geometry: How Correlations Shape Superposition , author =. 2026 , eprint =
2026
-
[35]
2025 , eprint =
Provably Extracting the Features from a General Superposition , author =. 2025 , eprint =
2025
-
[36]
2026 , eprint =
Stable and Steerable Sparse Autoencoders with Weight Regularization , author =. 2026 , eprint =
2026
-
[37]
2026 , eprint =
Improving Robustness in Sparse Autoencoders via Masked Regularization , author =. 2026 , eprint =
2026
-
[38]
2026 , eprint =
Identifying Intervenable and Interpretable Features via Orthogonality Regularization , author =. 2026 , eprint =
2026
-
[39]
PolySAE: Modeling Feature Interactions in Sparse Autoencoders via Polynomial Decoding
Koromilas, Panagiotis and others , year =. 2602.01322 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
2026 , eprint =
From Atoms to Trees: Building a Structured Feature Forest with Hierarchical Sparse Autoencoders , author =. 2026 , eprint =
2026
-
[41]
2026 , eprint =
Language Model Circuits Are Sparse in the Neuron Basis , author =. 2026 , eprint =
2026
-
[42]
2026 , eprint =
Sparse Auto-Encoders and Holism about Large Language Models , author =. 2026 , eprint =
2026
-
[43]
2025 , eprint =
Dimensional Collapse in Transformer Attention Outputs: A Challenge for Sparse Dictionary Learning , author =. 2025 , eprint =
2025
- [44]
-
[45]
2026 , eprint =
Why Linear Interpretability Works: Invariant Subspaces as a Result of Architectural Constraints , author =. 2026 , eprint =
2026
-
[46]
2026 , eprint =
Cosine-Normalized Attention for Hyperspectral Image Classification , author =. 2026 , eprint =
2026
-
[47]
International Conference on Machine Learning (ICML) , year =
Scaling Vision Transformers to 22 Billion Parameters , author =. International Conference on Machine Learning (ICML) , year =. 2302.05442 , archivePrefix =
-
[48]
Loshchilov, Ilya and Hsieh, Cheng-Ping and Sun, Simeng and Ginsburg, Boris , year =. 2410.01131 , archivePrefix =
-
[49]
2026 , eprint =
Step-Level Sparse Autoencoder for Reasoning Process Interpretation , author =. 2026 , eprint =
2026
-
[50]
2026 , eprint =
Interpretability without Actionability , author =. 2026 , eprint =
2026
-
[51]
2026 , eprint =
How Pruning Reshapes Features , author =. 2026 , eprint =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.