Gold Points Sniper: Self-guided Visual Reasoning in VLM for Fine-grained Action Understanding
Pith reviewed 2026-06-26 10:29 UTC · model grok-4.3
The pith
GPS framework lets lightweight vision-language models match GPT-4o on fine-grained human action understanding with higher factual accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
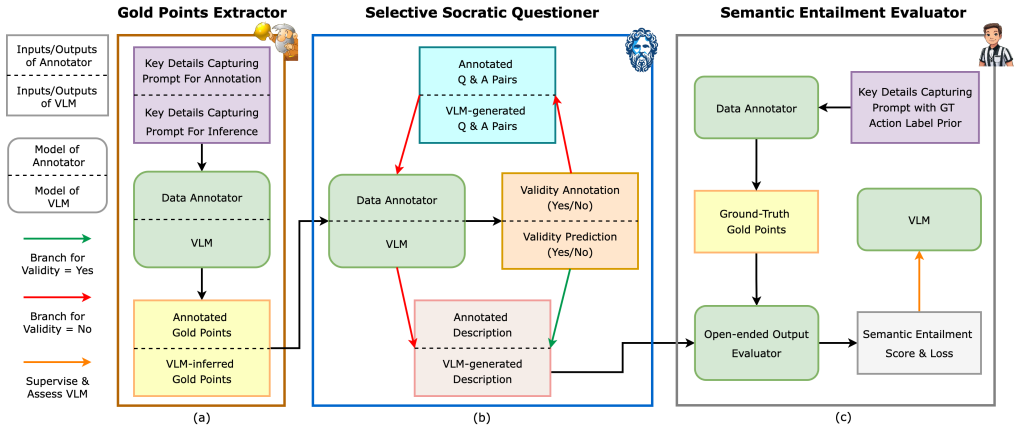
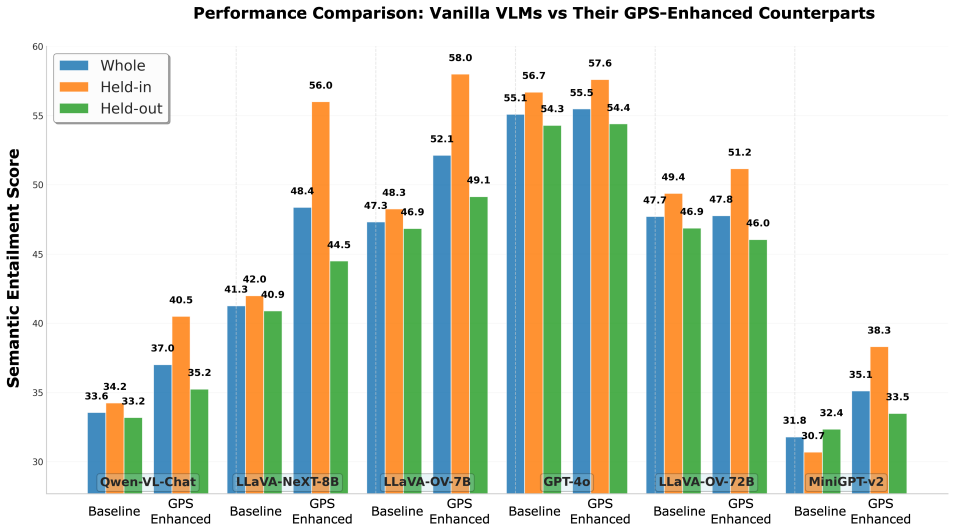
The Gold Points Sniper framework empowers lightweight VLMs with self-guided multimodal reasoning by training a Gold Points Extractor to identify critical action-relevant details, a Selective Socratic Questioner to validate and refine those details through selective self-questioning, and a Semantic Entailment Evaluator to quantitatively assess factual consistency, yielding substantial performance improvements on fine-grained action understanding.
What carries the argument
Gold Points Sniper (GPS) framework consisting of the Gold Points Extractor, Selective Socratic Questioner, and Semantic Entailment Evaluator modules that together enable self-guided visual reasoning in lightweight VLMs.
If this is right
- Lightweight VLMs can generate information-dense yet factually grounded descriptions of human actions from broad views.
- Robots gain a more reliable basis for interpreting human behavior in domestic environments.
- Some enhanced lightweight models reach performance comparable to GPT-4o while maintaining superior factual accuracy.
- The approach provides a foundation for fine-grained action understanding suited to domestic robotics.
Where Pith is reading between the lines
- The same three-module structure could be tested on action-understanding datasets drawn from different environments or camera angles.
- Deployment on physical robots would test whether the reported factual-accuracy gains reduce errors in live human-robot interactions.
- The selective-questioning and entailment steps might reduce hallucinations in other multimodal tasks that require both detail and correctness.
Load-bearing premise
The curated instruction-tuning dataset from the CAP benchmark supplies enough coverage and lacks bias so that measured gains will hold for genuine real-world fine-grained action understanding.
What would settle it
Evaluating the GPS-enhanced lightweight models on an independent collection of real-world videos unrelated to the CAP benchmark and finding no gains in factual accuracy or semantic understanding relative to unmodified baselines.
Figures




read the original abstract
Robots operating in everyday environments must understand fine-grained human actions, intentions, and contextual cues from broad views where people occupy only small regions, a capability unmet by current systems. While open-vocabulary action recognition methods remain limited to assigning predefined labels, and vision-language models (VLMs) face an inherent trade-off between informational richness and factual fidelity in their outputs, neither approach achieves the deep semantic interpretation required for reliable human-robot interaction. We propose Gold Points Sniper (GPS), a novel framework that empowers lightweight VLMs with self-guided multimodal reasoning capabilities for fine-grained human action understanding. Our approach comprises three key modules: Gold Points Extractor trains VLMs to identify critical action-relevant details, Selective Socratic Questioner validates and refines these details through selective self-questioning, and Semantic Entailment Evaluator quantitatively assesses factual consistency using semantic entailment classification. Extensive experiments on our curated instruction-tuning dataset based on the CAP benchmark demonstrate that GPS-enhanced lightweight VLMs achieve substantial performance improvements, with some models reaching performance comparable to proprietary GPT-4o while maintaining superior factual accuracy. Our work establishes a reliable foundation for fine-grained action understanding in domestic robotics, enabling robots to safely interpret human behavior through information-dense yet factually grounded descriptions. Source code, training configurations, annotation prompts, and dataset details are released at https://github.com/Haodi-Liu/GPS-Gold-Point-Sniper.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Gold Points Sniper (GPS), a framework with three modules—Gold Points Extractor, Selective Socratic Questioner, and Semantic Entailment Evaluator—to add self-guided multimodal reasoning to lightweight VLMs for fine-grained human action understanding in domestic robotics. It claims that GPS-enhanced models yield substantial performance gains on a curated instruction-tuning dataset derived from the CAP benchmark, with some reaching performance levels comparable to GPT-4o while exhibiting superior factual accuracy.
Significance. If the claimed gains are shown to be robust and generalizable, the work could offer a practical route to balancing informational density and factual fidelity in VLMs, addressing a recognized limitation for reliable human-robot interaction in everyday environments.
major comments (2)
- [Abstract] Abstract: the central claim of 'substantial performance improvements' and comparability to GPT-4o rests entirely on experiments performed on a single curated dataset, yet the abstract supplies no quantitative metrics, baselines, ablation results, or error analysis, so the support for the claim cannot be evaluated.
- [Abstract] Abstract (dataset curation): the headline numbers are measured exclusively on the authors' curated instruction-tuning set derived from CAP; without a described curation protocol, validation of coverage, or checks for selection bias that could favor the GPS modules, it is impossible to determine whether the reported gains diagnose genuine advances in real-world fine-grained action understanding.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that strengthening the abstract with quantitative support and clearer dataset details will improve the manuscript and address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'substantial performance improvements' and comparability to GPT-4o rests entirely on experiments performed on a single curated dataset, yet the abstract supplies no quantitative metrics, baselines, ablation results, or error analysis, so the support for the claim cannot be evaluated.
Authors: We agree that the abstract would be strengthened by including key quantitative results. In the revised manuscript we will update the abstract to report specific performance metrics (e.g., accuracy/F1 gains), baseline comparisons, and reference to ablation findings so that the central claims can be evaluated directly from the abstract. revision: yes
-
Referee: [Abstract] Abstract (dataset curation): the headline numbers are measured exclusively on the authors' curated instruction-tuning set derived from CAP; without a described curation protocol, validation of coverage, or checks for selection bias that could favor the GPS modules, it is impossible to determine whether the reported gains diagnose genuine advances in real-world fine-grained action understanding.
Authors: The current abstract notes that dataset details are released via the GitHub repository, but we acknowledge that a concise description of the curation protocol, coverage validation, and bias checks is missing from the abstract itself. We will revise the abstract to include a brief summary of these elements and will ensure the main text and supplementary material provide the full protocol so readers can assess potential selection effects. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces a three-module framework (Gold Points Extractor, Selective Socratic Questioner, Semantic Entailment Evaluator) and reports empirical performance gains on a curated instruction-tuning dataset derived from the CAP benchmark. No equations, parameter-fitting procedures, uniqueness theorems, or self-citations appear in the provided text that would reduce any claimed result to an input by construction. The reported improvements are direct measurements on the authors' dataset rather than predictions derived from self-defined quantities, satisfying the default expectation of a non-circular empirical methods paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Video action recognition with attentive semantic units,
Y . Chen, D. Chen, R. Liu, H. Li, and W. Peng, “Video action recognition with attentive semantic units,” inInternational Conference on Computer Vision (ICCV), pp. 10170–10180, 2023
2023
-
[2]
Enhancing human action recognition with fine-grained body move- ment attention,
R. Zhang, J. Xue, F. Lin, Q. Zhang, P. Smirnov, X. Ma, and X. Yan, “Enhancing human action recognition with fine-grained body move- ment attention,” in2024 IEEE International Conference on Multimedia and Expo (ICME), pp. 1–6, IEEE, 2024
2024
-
[3]
Denoiser: Rethinking the robustness for open-vocabulary action recognition,
H. Cheng, C. Ju, H. Wang, J. Liu, M. Chen, Q. Hu, X. Zhang, and Y . Wang, “Denoiser: Rethinking the robustness for open-vocabulary action recognition,”arXiv preprint arXiv:2404.14890, 2024
arXiv 2024
-
[4]
Generating action-conditioned prompts for open-vocabulary video action recognition,
C. Jia, M. Luo, X. Chang, Z. Dang, M. Han, M. Wang, G. Dai, S. Dang, and J. Wang, “Generating action-conditioned prompts for open-vocabulary video action recognition,” inProceedings of the 32nd ACM International Conference on Multimedia, pp. 4640–4649, 2024
2024
-
[5]
Large language models are visual reasoning coordinators,
L. Chen, B. Li, S. Shen, J. Yang, C. Li, K. Keutzer, T. Darrell, and Z. Liu, “Large language models are visual reasoning coordinators,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 36, pp. 70115–70140, 2023
2023
-
[6]
Froster: Frozen clip is a strong teacher for open-vocabulary action recognition,
X. Huang, H. Zhou, K. Yao, and K. Han, “Froster: Frozen clip is a strong teacher for open-vocabulary action recognition,” inInterna- tional Conference on Learning Representations (ICLR), 2024
2024
-
[7]
Enhancing video transformers for action understanding with vlm-aided training,
H. Lu, H. Jian, R. Poppe, and A. A. Salah, “Enhancing video transformers for action understanding with vlm-aided training,”arXiv preprint arXiv:2403.16128, 2024
arXiv 2024
-
[8]
Learning to generalize without bias for open-vocabulary action recognition,
Y . Yu, C. Cao, Y . Zhang, and Y . Zhang, “Learning to generalize without bias for open-vocabulary action recognition,”arXiv preprint arXiv:2502.20158, 2025
arXiv 2025
-
[9]
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond,”arXiv preprint arXiv:2308.12966, 2023
Pith/arXiv arXiv 2023
-
[10]
Improved baselines with visual instruction tuning,
H. Liu, C. Li, Y . Li, and Y . J. Lee, “Improved baselines with visual instruction tuning,” inConference on Computer Vision and Pattern Recognition (CVPR), pp. 26296–26306, 2024
2024
-
[11]
Minigpt-v2: large language model as a unified interface for vision-language multi-task learning,
J. Chen, D. Zhu, X. Shen, X. Li, Z. Liu, P. Zhang, R. Krishnamoorthi, V . Chandra, Y . Xiong, and M. Elhoseiny, “Minigpt-v2: large language model as a unified interface for vision-language multi-task learning,” arXiv preprint arXiv:2310.09478, 2023
Pith/arXiv arXiv 2023
-
[12]
A. Hurst, A. Lerer, A. P. Goucher, A. Perelman, A. Ramesh, A. Clark, A. Ostrow, A. Welihinda, A. Hayes, A. Radford,et al., “Gpt-4o system card,”arXiv preprint arXiv:2410.21276, 2024
Pith/arXiv arXiv 2024
-
[13]
Llava-next: Stronger llms supercharge multimodal capabilities in the wild,
B. Li, K. Zhang, H. Zhang, D. Guo, R. Zhang, F. Li, Y . Zhang, Z. Liu, and C. Li, “Llava-next: Stronger llms supercharge multimodal capabilities in the wild,” May 2024
2024
-
[14]
Llava-onevision: Easy visual task transfer,
B. Li, Y . Zhang, D. Guo, R. Zhang, F. Li, H. Zhang, K. Zhang, P. Zhang, Y . Li, Z. Liu,et al., “Llava-onevision: Easy visual task transfer,”Transactions on Machine Learning Research, 2024
2024
-
[15]
The kinetics human action video dataset,
W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijaya- narasimhan, F. Viola, T. Green, T. Back, P. Natsev,et al., “The kinetics human action video dataset,”arXiv preprint arXiv:1705.06950, 2017
Pith/arXiv arXiv 2017
-
[16]
Activitynet: A large-scale video benchmark for human activity under- standing,
F. Caba Heilbron, V . Escorcia, B. Ghanem, and J. Carlos Niebles, “Activitynet: A large-scale video benchmark for human activity under- standing,” inConference on Computer Vision and Pattern Recognition (CVPR), pp. 961–970, 2015
2015
-
[17]
Hmdb: a large video database for human motion recognition,
H. Kuehne, H. Jhuang, E. Garrote, T. Poggio, and T. Serre, “Hmdb: a large video database for human motion recognition,” inInternational Conference on Computer Vision (ICCV), pp. 2556–2563, IEEE, 2011
2011
-
[18]
Ucf101: A dataset of 101 human actions classes from videos in the wild,
K. Soomro, A. R. Zamir, and M. Shah, “Ucf101: A dataset of 101 human actions classes from videos in the wild,”arXiv preprint arXiv:1212.0402, 2012
Pith/arXiv arXiv 2012
-
[19]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhou,et al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in Neural Information Processing Systems (NeurIPS), vol. 35, pp. 24824–24837, 2022
2022
-
[20]
Mul- timodal chain-of-thought reasoning in language models,
Z. Zhang, A. Zhang, M. Li, hai zhao, G. Karypis, and A. Smola, “Mul- timodal chain-of-thought reasoning in language models,”Transactions on Machine Learning Research, 2024
2024
-
[21]
Multi-modal latent space learning for chain-of-thought reasoning in language models,
L. He, Z. Li, X. Cai, and P. Wang, “Multi-modal latent space learning for chain-of-thought reasoning in language models,” inAAAI Conference on Artificial Intelligence (AAAI), vol. 38, pp. 18180– 18187, 2024
2024
-
[22]
Kam-cot: Knowledge augmented multimodal chain-of-thoughts reasoning,
D. Mondal, S. Modi, S. Panda, R. Singh, and G. S. Rao, “Kam-cot: Knowledge augmented multimodal chain-of-thoughts reasoning,” in AAAI Conference on Artificial Intelligence (AAAI), vol. 38, pp. 18798– 18806, 2024
2024
-
[23]
Cumulative reasoning with large language models,
Y . Zhang, J. Yang, Y . Yuan, and A. C.-C. Yao, “Cumulative reasoning with large language models,”Transactions on Machine Learning Research, 2023
2023
-
[24]
Visual question decomposition on multimodal large language models,
H. Zhang, J. Liu, Z. Han, S. Chen, B. He, V . Tresp, Z. Xu, and J. Gu, “Visual question decomposition on multimodal large language models,” inEMNLP (Findings), 2024
2024
-
[25]
Putting people in llms’ shoes: Generating better answers via question rewriter,
J. Chen, B. Wang, Z. Jiang, and Y . Nakashima, “Putting people in llms’ shoes: Generating better answers via question rewriter,” inAAAI Conference on Artificial Intelligence (AAAI), vol. 39, pp. 23577– 23585, 2025
2025
-
[26]
Sq-llava: Self-questioning for large vision-language assistant,
G. Sun, C. Qin, J. Wang, Z. Chen, R. Xu, and Z. Tao, “Sq-llava: Self-questioning for large vision-language assistant,” inEuropean Conference on Computer Vision (ECCV), pp. 156–172, Springer, 2024
2024
-
[27]
Socratic questioning: Learn to self-guide multimodal reasoning in the wild,
W. Hu, H. Liu, L. Chen, F. Zhou, C. Xiao, Q. Yang, and C. Zhang, “Socratic questioning: Learn to self-guide multimodal reasoning in the wild,”arXiv preprint arXiv:2501.02964, 2025
arXiv 2025
-
[28]
Fine-grained activi- ties of people worldwide,
J. Byrne, G. Castañón, Z. Li, and G. Ettinger, “Fine-grained activi- ties of people worldwide,” inProceedings of Winter Conference on Applications of Computer Vision (WACV), pp. 3308–3319, 2023
2023
-
[29]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark,et al., “Learning transferable visual models from natural language supervision,” inInternational Conference on Machine Learning (ICML), pp. 8748–8763, PmLR, 2021
2021
-
[30]
X-clip: End- to-end multi-grained contrastive learning for video-text retrieval,
Y . Ma, G. Xu, X. Sun, M. Yan, J. Zhang, and R. Ji, “X-clip: End- to-end multi-grained contrastive learning for video-text retrieval,” in Proceedings of the 30th ACM international conference on multimedia, pp. 638–647, 2022
2022
-
[31]
Fine-tuned clip models are efficient video learners,
H. Rasheed, M. U. Khattak, M. Maaz, S. Khan, and F. S. Khan, “Fine-tuned clip models are efficient video learners,” inConference on Computer Vision and Pattern Recognition (CVPR), pp. 6545–6554, 2023
2023
-
[32]
Languagebind: Extending video-language pretraining to n-modality by language-based semantic alignment,
B. Zhu, B. Lin, M. Ning, Y . Yan, J. Cui, W. HongFa, Y . Pang, W. Jiang, J. Zhang, Z. Li,et al., “Languagebind: Extending video-language pretraining to n-modality by language-based semantic alignment,” in International Conference on Learning Representations (ICLR), 2024
2024
-
[33]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al- Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan,et al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.