HybridCodeAuthorship: A Benchmark Dataset for Line-Level Code Authorship Detection
Pith reviewed 2026-06-27 08:53 UTC · model grok-4.3
The pith
A new benchmark of interleaved human and AI Python lines shows detectors reach at most 0.56 F1 on line-level detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HybridCodeAuthorship supplies Python files whose lines alternate between human-authored and AI-generated content drawn from CodeSearchNet links; when two state-of-the-art detectors are evaluated on this data, the strongest performer records an F1 of 0.48 at the chunk level and 0.56 at the line level.
What carries the argument
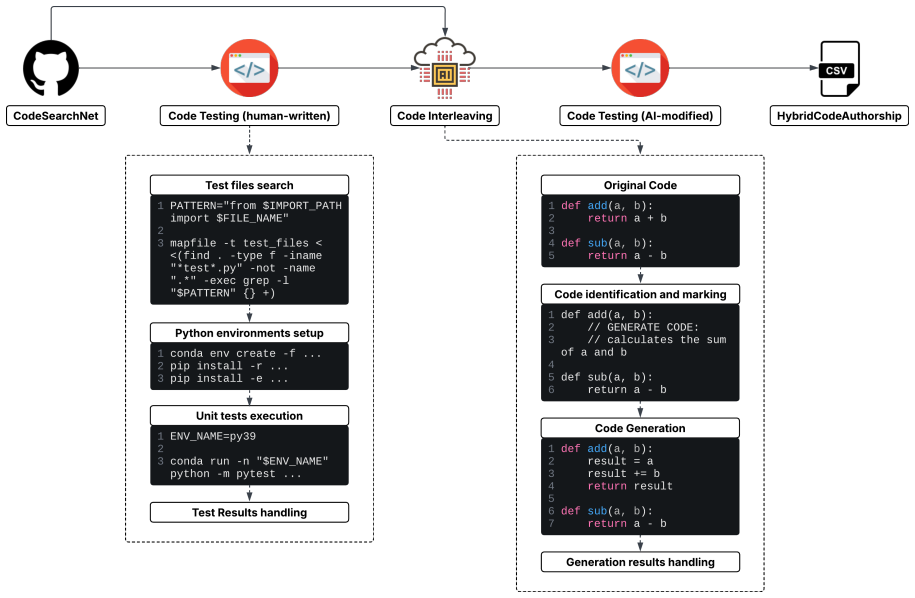
The dataset construction pipeline that interleaves human and AI lines inside single files drawn from CodeSearchNet repositories.
If this is right
- Fine-grained detection algorithms must be developed that operate on individual lines rather than whole files or functions.
- Risk-management and audit tools for codebases will require benchmarks that reflect mixed authorship rather than pure human or pure AI snippets.
- Performance ceilings reported on LeetCode-style problems do not transfer to interleaved industry code.
- Productivity analyses that rely on authorship signals will need line-level rather than file-level granularity.
Where Pith is reading between the lines
- If the interleaving method proves representative, then current detectors will need architectural changes that explicitly model line-by-line transitions rather than global statistical signatures.
- The low scores suggest that human and AI line distributions overlap more than whole-file distributions, which may guide future training of detectors on mixed rather than pure data.
- Extending the pipeline to additional languages or to multi-line AI insertions would test whether the reported difficulty generalizes beyond Python single-line interleaving.
Load-bearing premise
The specific way lines are chosen and interleaved from CodeSearchNet produces the same statistical patterns that arise when developers actually paste AI suggestions into their codebases.
What would settle it
Measure the same detectors on a collection of real industry repositories where each line has been labeled by the developer as either written by hand or accepted from an AI assistant; if the F1 scores remain below 0.6 the claim holds, while substantially higher scores would falsify it.
Figures

read the original abstract
Thanks to the rapid adoption of AI code assistants powered by large language models (LLMs), industry codebases are, increasingly, a hybrid of AI- and human-authored code. For risk management and productivity analysis purposes, it is crucial to enable fine-grained location detection of AI-generated code. To develop algorithms for this task, quality benchmarks are needed to assess performance. However, existing benchmarks tend to comprise academic, LeetCode-style problems and presume a code snippet is either completely human-authored or completely AI-authored, which is not reflective of the diverse intents and styles of industry codebases utilizing AI code assistants. To fill these gaps, we introduce HybridCodeAuthorship, a novel benchmark of Python code files with interleaved human- and AI-authored lines of code to simulate authentic utilization of AI code assistants. In this paper, we first present our dataset construction pipeline, which leverages CodeSearchNet, a massive collection of links to open sourced repositories on GitHub. We then benchmark the performance of two state-of-the-art AI-generated code detection algorithms at both the line- and chunk-level. Experimental results demonstrate that HybridCodeAuthorship is a challenging benchmark with a top-scoring algorithm, AIGCode Detector, obtaining a highest F1 score of 0.48 and 0.56 on chunk-level and line-level code detection tasks, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HybridCodeAuthorship, a benchmark of Python files containing interleaved human- and AI-authored lines constructed from CodeSearchNet to better reflect industry use of AI code assistants. It describes a construction pipeline and evaluates two detection algorithms (including AIGCode Detector) on line-level and chunk-level tasks, reporting peak F1 scores of 0.56 and 0.48 respectively, and concludes that the dataset constitutes a challenging benchmark for fine-grained authorship detection.
Significance. A validated benchmark with realistic interleaving statistics would be a useful contribution for developing line-level AI-code detectors, as existing resources are limited to whole-snippet all-human or all-AI labels. The reported low F1 scores would, if reproducible on authentic hybrid codebases, usefully quantify current detector limitations. The work supplies an explicit construction pipeline and empirical numbers, which are positive attributes.
major comments (2)
- [Dataset construction pipeline] Dataset construction pipeline (described after the abstract and in the methods section): the interleaving procedure is presented only at high level; no parameters are given for line-selection probability, run-length distribution, prompt-context retention, or edit-pattern simulation. Without these, it is impossible to assess whether the resulting authorship boundaries match real developer usage of AI assistants, which is load-bearing for the claim that the benchmark is industry-relevant.
- [Experimental results] Experimental results section: F1 scores of 0.48 (chunk) and 0.56 (line) are stated without error bars, number of evaluation runs, or statistical significance tests; baseline comparisons are also described only at high level. These omissions make it difficult to determine whether the scores reliably demonstrate that the benchmark is challenging.
minor comments (1)
- [Abstract] Abstract and results paragraphs would benefit from explicit mention of the number of files, total lines, and train/test split sizes to allow immediate assessment of scale.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight opportunities to improve reproducibility and statistical rigor, which we address point-by-point below. We will incorporate the suggested changes in a revised version.
read point-by-point responses
-
Referee: [Dataset construction pipeline] Dataset construction pipeline (described after the abstract and in the methods section): the interleaving procedure is presented only at high level; no parameters are given for line-selection probability, run-length distribution, prompt-context retention, or edit-pattern simulation. Without these, it is impossible to assess whether the resulting authorship boundaries match real developer usage of AI assistants, which is load-bearing for the claim that the benchmark is industry-relevant.
Authors: We agree that additional parameters are needed for full reproducibility and to allow readers to evaluate alignment with real-world AI assistant usage. In the revised manuscript we will expand the methods section with explicit values for line-selection probability, run-length distribution, prompt-context retention, and edit-pattern simulation. We will also release the complete construction pipeline as open-source code with a configuration file containing all parameters. revision: yes
-
Referee: [Experimental results] Experimental results section: F1 scores of 0.48 (chunk) and 0.56 (line) are stated without error bars, number of evaluation runs, or statistical significance tests; baseline comparisons are also described only at high level. These omissions make it difficult to determine whether the scores reliably demonstrate that the benchmark is challenging.
Authors: We acknowledge that the current experimental reporting lacks error bars, run counts, and significance testing, which limits assessment of result reliability. In the revision we will report mean F1 scores with standard deviations across multiple evaluation runs, include the exact number of runs performed, add statistical significance tests comparing the detectors, and provide more detailed descriptions of the baseline methods and their implementations. revision: yes
Circularity Check
No circularity: empirical dataset and benchmark evaluation
full rationale
The paper introduces a benchmark dataset via a CodeSearchNet-based interleaving pipeline and reports direct empirical F1 scores from running existing detectors on the resulting files. No derivation chain, first-principles prediction, fitted parameter renamed as output, or self-citation load-bearing step exists; the central claims are measurements on an explicitly constructed artifact rather than reductions to inputs by definition or prior self-work. The construction assumptions are stated as simulation choices and are open to external validation, not internally forced.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CodeSearchNet provides a suitable base of open-source Python repositories for constructing realistic hybrid code examples.
Reference graph
Works this paper leans on
-
[1]
HybridCodeAuthorship: A Benchmark Dataset for Line-Level Code Authorship Detection
Introduction Recent advances in generative AI are fundamen- tally reshaping the landscape of software develop- ment. AI code assistants powered by cutting-edge large language models (LLMs) are being rapidly adoptedbyindustrytoenhancedevelopers’produc- tivity.1 A number of studies have been published that attempt to quantify the benefits of AI-based code a...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
A benchmark dataset, HybridCodeAuthorship, composed of full code files with interleaved human-authored and AI-generated code
-
[3]
As part of the first contribution, we created Hy- bridCodeAuthorship 3 using a data construction pipeline that leverages CodeSearchNet (Husain et al., 2019)
Experimental results showing initial bench- mark performance of adapting two state- of-the-art AI-generated code detection algo- rithms for both line- and chunk-level code de- tection using HybridCodeAuthorship. As part of the first contribution, we created Hy- bridCodeAuthorship 3 using a data construction pipeline that leverages CodeSearchNet (Husain et...
2019
-
[4]
WeaskLLMstofirstselect distinct, atomic parts of human-authored code files and replace them with descriptive summaries of their functionality
which highlights the frequent edits and fine-grained interactions developers have with AI- generatedsuggestions. WeaskLLMstofirstselect distinct, atomic parts of human-authored code files and replace them with descriptive summaries of their functionality. These summaries serve as prox- ies for user-provided prompts, reflecting a devel- oper’s specific int...
2024
-
[5]
Alam et al
Related Work In recent years, numerous benchmark datasets have been proposed to evaluate the performance of AI code detection algorithms. Alam et al. (2023) developed GPTCloneBench, a large dataset of AI- Human clone pairs generated with GPT-3 (Brown et al., 2020). Demirok and Kutlu (2024) created AIGCodeSet, containing human-authored and AI- generated pa...
2023
-
[6]
Human” or “AI
Benchmark Construction We provide an illustration of the data construction pipelineforourbenchmarkdataset,HybridCodeAu- thorship, in Figure 1. The pipeline processes code files sampled from CodeSearchNet in two phases: code testing and code interleaving. Notably, both phases comprise multiple steps and code testing is invoked twice to run the same unit te...
2019
-
[7]
Unit Test Passed
HybridCodeAuthorship Dataset The HybridCodeAuthorship dataset comprises 10,488 records derived from 4,196 Python code files. Each file was independently rewritten by mul- tiple LLMs, resulting in several modified versions per source file. Of the 10,488 file records, 39% (4,103) of human-authored code files passed unit tests. Incomparison, 29%(3,000)ofthe1...
-
[8]
perplexity dis- parity
Experimental Results While HybridCodeAuthorship is intended to bench- mark the performance of AI-generated code detec- tion approaches at the line-level, for completeness we also report the results of chunk-level experi- ments. Chunk-level detection involves concatenat- ing consecutive lines of code with the same author, either human or AI. We benchmarked...
2025
-
[9]
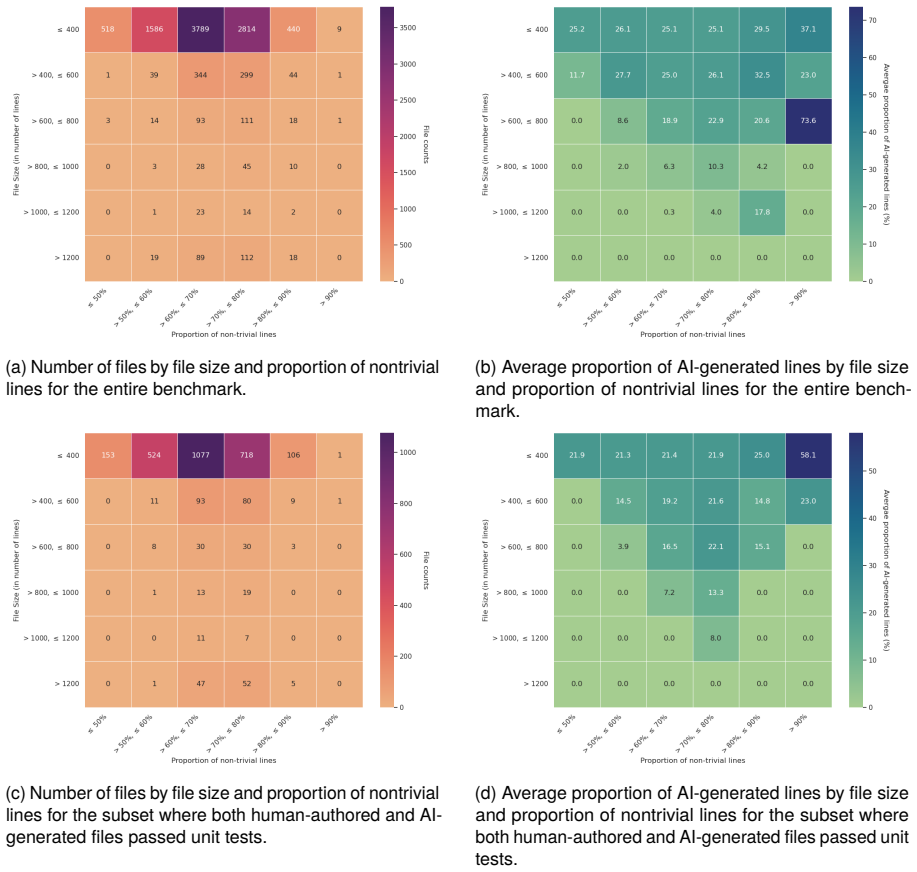
(a)Numberoffilesbyfilesizeandproportionofnontrivial lines for the entire benchmark
Limitations Although HybridCodeAuthorship is currently the only available dataset that simulates hybrid AI and human authorship at the fine-grained line level, there are some limitations to discuss. (a)Numberoffilesbyfilesizeandproportionofnontrivial lines for the entire benchmark. (b) Average proportion of AI-generated lines by file size and proportion o...
-
[10]
Chunk-level Precision0.101 0.540 Recall0.856 0.560 F10.1810.480
Conclusion In this paper, we present a novel benchmark dataset that will allow the development of algo- rithms to distinguish AI-generated versus human- LLM Dataset Split Granularity Metric Detection Algorithm DroidDetect AIGCode Detector GPT-OSS-120b Trivial Line-level Precision0.197 0.560 Recall0.986 0.570 F10.3280.560 . Chunk-level Precision0.101 0.540...
-
[11]
Bibliographical References Mohammed Abuhamad, Tamer Abuhmed, Dae- Hun Nyang, and David Mohaisen. 2020. Multi-χ: Identifying multiple authors from source code files.Proceedings on Privacy Enhancing Tech- nologies. Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman,AndyApplebaum,EdwinArbus,RahulK. Arora, et al. 2025. gpt-oss-120b & gpt-oss-20b model card. A...
-
[12]
In24thUSENIXSecuritySymposium (USENIX Security 15), pages 255–270
De-anonymizing programmers via code stylometry. In24thUSENIXSecuritySymposium (USENIX Security 15), pages 255–270. Sayan Chatterjee, Ching Louis Liu, Gareth Row- land, and Tim Hogarth. 2024. The impact of ai tool on engineering at anz bank an empirical study on github copilot within corporate environ- ment.arXiv preprint arXiv:2402.05636. Soohyeon Choi an...
-
[13]
arXiv preprint arXiv:2507.21693
MultiAIGCD: A comprehensive dataset for ai generated code detection covering multi- ple languages, models, prompts, and scenarios. arXiv preprint arXiv:2507.21693. BegumKaraciDeniz, ChandraGnanasambandam, Martin Harrysson, Alharith Hussin, and Shivam Srivastava. 2023. Unleashing developer produc- tivity with generative ai.McKinsey Digital, 7. Abhimanyu Du...
-
[14]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
CodeSearchNet challenge: Evaluating the state of semantic code search.arXiv preprint arXiv:1909.09436. Oseremen Joy Idialu, Noble Saji Mathews, Run- groj Maipradit, Joanne M. Atlee, and Mei Nagap- pan. 2024. Whodunit: Classifying code as hu- man authored or GPT-4 generated-a case study on CodeChef problems. InProceedings of the 21st International Conferen...
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[15]
CodeT5+: Open Code Large Language Models for Code Understanding and Generation
Codet5+: Opencodelargelanguagemod- elsforcodeunderstandingandgeneration.arXiv preprint arXiv:2305.07922. Yue Wang, Weishi Wang, Shafiq Joty, and Steven CH Hoi. 2021. Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation.arXiv preprint arXiv:2109.00859. Benjamin Warner, Antoine Chaffin, Benjamin Clavié, O...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[16]
Zhenyu Xu and Victor S Sheng
Distinguishing llm-generated from human- written code by contrastive learning.ACM Trans- actions on Software Engineering and Methodol- ogy, 34(4):1–31. Zhenyu Xu and Victor S Sheng. 2024. Detecting ai-generated code assignments using perplex- ity of large language models. InProceedings of the aaai conference on artificial intelligence, volume 38, pages 23...
2024
-
[17]
Albert Ziegler, Eirini Kalliamvakou, X Alice Li, Andrew Rice, Devon Rifkin, Shawn Simister, Ganesh Sittampalam, and Edward Aftandilian
LLM-as-a-coauthor: Can mixed human- writtenandmachine-generatedtextbedetected? InFindings of the Association for Computational Linguistics: NAACL 2024, pages 409–436. Albert Ziegler, Eirini Kalliamvakou, X Alice Li, Andrew Rice, Devon Rifkin, Shawn Simister, Ganesh Sittampalam, and Edward Aftandilian
2024
-
[18]
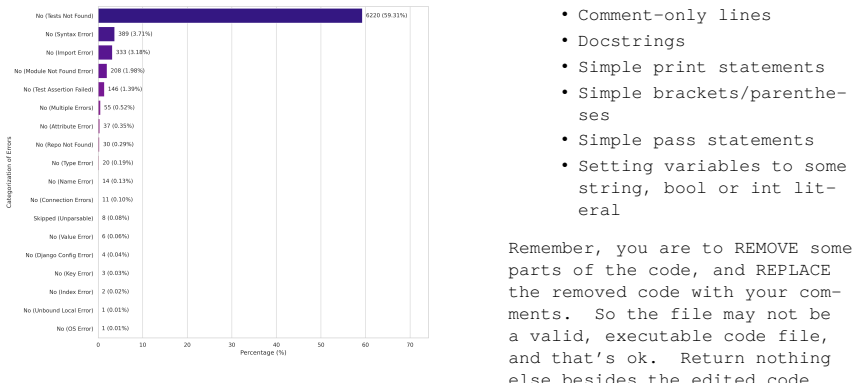
Measuring github copilot’s impact on pro- ductivity.CommunicationsoftheACM,67(3):54– 63. A. Test Error Analysis We categorized different errors raised in testing both human-authored and AI-modified code. The error distributions for the two scenarios are visual- izedinFigure3andFigure4,respectively. Bothdis- tributions share the most common errors as liste...
2025
-
[19]
the sections of code must be clearly atomic and logically separable from surrounding code, such that the selected code can be cleanly described (for example, don’t stop the deleted section in the middle of a for loop)
-
[20]
GENERATE CODE:
clearly distinguish comments added in this manner from other comments in the code by starting your comment with “GENERATE CODE:”
-
[21]
Your comments need to be de- tailed enough that someone without reference to the original code could plausibly reconstruct the code section with similar functionality (though not necessarily with the same exact syntax)
-
[22]
Try to be not super specific about the exact implemen- tation, the goal is not to describe it so specifically that there is only one pos- sible code string that meets the specified requirements
-
[23]
GENERATE CODE:
Do not replace non- significant, non-meaningful lines of code. Examples of these are: •Blank lines •Comment-only lines •Docstrings •Simple print statements •Simple brackets/parenthe- ses •Simple pass statements •Setting variables to some string, bool or int lit- eral Remember, you are to REMOVE some parts of the code, and REPLACE the removed code with you...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.