Does My Embedding Reflect That A = B? Evaluating Mathematical Equivalence in Embedding Models
Pith reviewed 2026-06-26 07:55 UTC · model grok-4.3
The pith
Embedding models group mathematical statements by terminology rather than underlying equivalence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
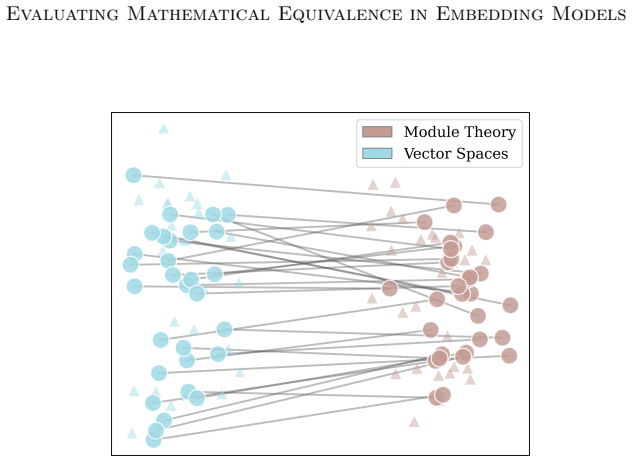
Current state-of-the-art embedding models tend to group statements by the terminology used to make them instead of the underlying math. The MELD dataset of mathematically equivalent but lexically different pairs exposes this behavior. A contrastive training approach that aligns informal statements with different formalizations produces embeddings that perform better on both informal-formal retrieval tasks and on MELD, which contains only natural-language statements.
What carries the argument
The MELD dataset of mathematically equivalent but lexically different statement pairs, together with a contrastive objective that pulls together informal statements and varied formalizations.
If this is right
- Embeddings trained this way retrieve informal statements from formal versions and vice versa more reliably.
- Navigation between different mathematical languages, such as natural language and systems like Lean, becomes more accurate.
- Search and discovery of related results across subfields improves because equivalent ideas expressed differently are placed closer together.
- Downstream applications that depend on recognizing mathematical identity across surface forms gain a measurable boost.
Where Pith is reading between the lines
- The same contrastive alignment idea could be applied to other domains where semantic equivalence is hidden by differing terminology, such as legal documents or scientific literature.
- If the method scales without needing large paired informal-formal corpora, it might reduce the annotation burden for building math-aware search tools.
- Models that succeed on MELD may still require separate checks to confirm they handle deeper structural equivalence beyond lexical variation.
Load-bearing premise
The lexical differences in MELD pairs do not systematically correlate with embedding distances in a manner that would turn the observed grouping failure into an artifact of dataset construction.
What would settle it
Construct a fresh set of mathematically equivalent statement pairs whose lexical variations are randomized or balanced across topics, then check whether the same models still fail to group by equivalence rather than wording.
Figures
read the original abstract
Because mathematics is highly abstract, a single statement can take very different forms depending on what subfield it is framed in. There are many examples where breakthroughs occurred after researchers discovered that a question had already been answered in a different field. At the same time, the growth of new resources related to formalization has increased the need for tools that enable efficient and reliable navigation between mathematical 'languages' (e.g., from Lean to natural language). In this paper, we investigate whether current embedding models capture mathematical equivalence. To do this, we introduce the Mathematically Equivalent but Lexically Different Pairs (MELD) Dataset, a collection of mathematically equivalent statements that are expressed in very different language. We show that current state-of-the-art embedding models tend to group statements by the terminology used to make them instead of the underlying math. Motivated by this, we propose a contrastive approach to learning embeddings of mathematical text that focuses on aligning informal statements with different formalizations. Our experiments demonstrate that this leads to improvements not only on informal-formal retrieval tasks but also on MELD, which only contains natural language statements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the MELD dataset of mathematically equivalent but lexically divergent statements to test whether embedding models capture mathematical equivalence. It claims that current SOTA models group statements by terminology rather than underlying math, and proposes a contrastive training procedure to align informal statements with different formalizations, reporting improvements on informal-formal retrieval and on MELD itself.
Significance. If the MELD construction is free of lexical confounds and the reported improvements are reproducible with proper baselines, the work would usefully document a limitation in existing embeddings for mathematical text and supply a targeted training method. The introduction of new data and a contrastive objective focused on math equivalence is a concrete contribution to mathematical NLP.
major comments (2)
- [Abstract] Abstract: the claim of demonstrated improvements on MELD and informal-formal retrieval is unsupported because the text supplies no quantitative results, dataset statistics, training details, or baseline comparisons.
- [MELD Dataset] MELD Dataset: the construction protocol, verification of mathematical equivalence, and controls for lexical confounds (length, syntactic complexity, subfield markers) are not described. This is load-bearing for the central claim that observed distances reflect terminology bias rather than other encoded features.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of demonstrated improvements on MELD and informal-formal retrieval is unsupported because the text supplies no quantitative results, dataset statistics, training details, or baseline comparisons.
Authors: We agree that the abstract, as a concise summary, does not include quantitative results. The body of the paper reports the experimental outcomes, but to make the abstract self-contained we will revise it to include key metrics (e.g., retrieval accuracy gains and MELD performance deltas), dataset statistics, and a brief note on the contrastive training setup and baselines. revision: yes
-
Referee: [MELD Dataset] MELD Dataset: the construction protocol, verification of mathematical equivalence, and controls for lexical confounds (length, syntactic complexity, subfield markers) are not described. This is load-bearing for the central claim that observed distances reflect terminology bias rather than other encoded features.
Authors: We acknowledge that the provided manuscript text does not detail the MELD construction. In the revised version we will expand the dataset section to describe the generation protocol, the verification of mathematical equivalence (via expert review and cross-checks against formal statements), and the controls applied for lexical confounds, including length matching, syntactic complexity balancing, and subfield diversity without marker leakage. revision: yes
Circularity Check
No circularity: empirical dataset construction and contrastive training are independent of fitted inputs
full rationale
The paper introduces the MELD dataset of mathematically equivalent but lexically divergent statements and evaluates existing embedding models on it, then trains a contrastive model to align informal and formal math text. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description. The central claims rest on new data and a new training procedure rather than any quantity defined in terms of itself or prior author work. This is the expected non-finding for an empirical methods paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Semi-Autonomous Mathematics Discovery with
Feng, Tony and Trinh, Trieu and Bingham, Garrett and Kang, Jiwon and Zhang, Shengtong and Kim, Sang-hyun and Barreto, Kevin and Schildkraut, Carl and Jung, Junehyuk and Seo, Jaehyeon and others , journal=. Semi-Autonomous Mathematics Discovery with
-
[2]
, title =
Knuth, Donald E. , title =. 2026 , month = April, day =
2026
-
[3]
2024 , month = sep, url =
Tao, Terence , title =. 2024 , month = sep, url =
2024
-
[4]
2026 , month = may, day =
Gowers, Timothy , title =. 2026 , month = may, day =
2026
-
[5]
Zheng, Daniel and von Glehn, Ingrid and Zwols, Yori and Beloshapka, Iuliya and Buesing, Lars and Roy, Daniel M and Wattenberg, Martin and Georgiev, Bogdan and Schmidt, Tatiana and Cowie, Andrew and others , journal=
-
[6]
arXiv preprint arXiv:2506.11085 , year=
LeanExplore: A search engine for Lean 4 declarations , author=. arXiv preprint arXiv:2506.11085 , year=
-
[7]
arXiv preprint arXiv:2605.13137 , year=
LeanSearch v2: Global Premise Retrieval for Lean 4 Theorem Proving , author=. arXiv preprint arXiv:2605.13137 , year=
-
[8]
Advances in Neural Information Processing Systems , volume=
Leandojo: Theorem proving with retrieval-augmented language models , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
International Conference on Learning Representations , volume=
Herald: A natural language annotated lean 4 dataset , author=. International Conference on Learning Representations , volume=
-
[10]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
A semantic search engine for mathlib4 , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[11]
arXiv preprint arXiv:2510.15940 , year=
Lean finder: Semantic search for mathlib that understands user intents , author=. arXiv preprint arXiv:2510.15940 , year=
-
[12]
arXiv preprint arXiv:2602.05216 , year=
Semantic search over 9 million mathematical theorems , author=. arXiv preprint arXiv:2602.05216 , year=
-
[13]
arXiv preprint arXiv:2104.01112 , year=
Naturalproofs: Mathematical theorem proving in natural language , author=. arXiv preprint arXiv:2104.01112 , year=
-
[14]
Ju, Haocheng and Dong, Bin , booktitle=
-
[15]
The Lean 4 Theorem Prover and Programming Language , author =. Automated Deduction – CADE 28: 28th International Conference on Automated Deduction, Virtual Event, July 12–15, 2021, Proceedings , pages =. 2021 , isbn =. doi:10.1007/978-3-030-79876-5_37 , abstract =
-
[16]
Proceedings of the 9th
The. Proceedings of the 9th. 2020 , month = jan, doi =
2020
-
[17]
Golden years of Moscow Mathematics
On Soviet mathematics of the 1950s and 1960s , author=. Golden years of Moscow Mathematics. Editors: S. Zdravkovska and PL Duren. History of Mathematics , volume=
-
[18]
2026 , journal=
Planar Point Sets with Many Unit Distances , author=. 2026 , journal=
2026
-
[19]
arXiv preprint arXiv:2605.20695 , year=
Remarks on the disproof of the unit distance conjecture , author=. arXiv preprint arXiv:2605.20695 , year=
-
[20]
2025 , url=
Octen Series: Optimizing Embedding Models to \#1 on RTEB Leaderboard , author=. 2025 , url=
2025
-
[21]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[22]
mathlib\_informal\_v4.16.0 , year =
-
[23]
arXiv preprint arXiv:2506.05176 , year=
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models , author=. arXiv preprint arXiv:2506.05176 , year=
-
[24]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Reimers, Nils and Gurevych, Iryna. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. 2019
2019
-
[25]
mathlib\_informal\_v4.19.0 , year =
-
[26]
2026 , howpublished =
Harrier-Oss-V1-27B , author =. 2026 , howpublished =
2026
-
[27]
2025 , eprint=
KaLM-Embedding-V2: Superior Training Techniques and Data Inspire A Versatile Embedding Model , author=. 2025 , eprint=
2025
-
[28]
2025 , eprint=
KaLM-Embedding: Superior Training Data Brings A Stronger Embedding Model , author=. 2025 , eprint=
2025
-
[29]
2025 , eprint=
Llama-Embed-Nemotron-8B: A Universal Text Embedding Model for Multilingual and Cross-Lingual Tasks , author=. 2025 , eprint=
2025
-
[30]
arXiv preprint arXiv:1802.03426 , year=
Umap: Uniform manifold approximation and projection for dimension reduction , author=. arXiv preprint arXiv:1802.03426 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.