Multimodal Concept Bottleneck Models
Pith reviewed 2026-06-26 18:10 UTC · model grok-4.3
The pith
Multimodal Concept Bottleneck Models add dual layers to CLIP so image and text embeddings align to shared concepts for interpretable zero-shot tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
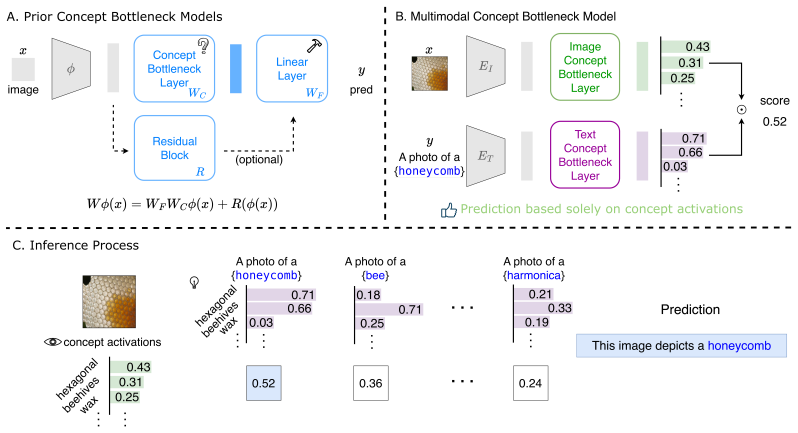
MM-CBM utilizes dual Concept Bottleneck Layers to align both the image and text embeddings into interpretable features. This allows us to perform new vision tasks like zero-shot classification or image retrieval in an interpretable way. Compared to existing methods, MM-CBM achieves up to 51.26% accuracy improvement on average across four standard benchmarks while maintaining high accuracy, staying within ~5% of black-box performance.
What carries the argument
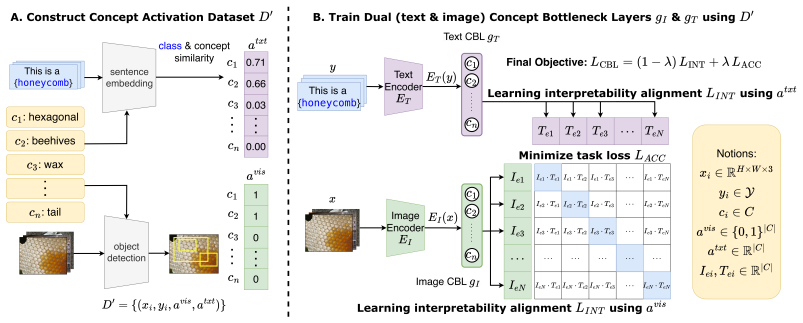
Dual Concept Bottleneck Layers that project CLIP image and text embeddings into a shared space of predefined concepts.
If this is right
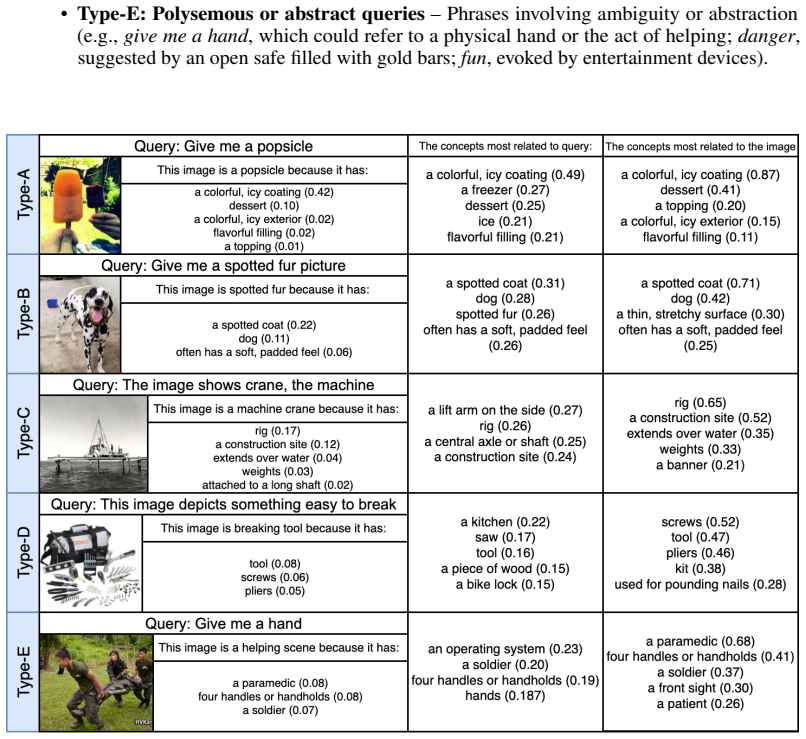
- Zero-shot classification decisions become traceable to individual concept activations.
- Image retrieval can rank results by matching concept vectors rather than raw embeddings.
- Accuracy on standard benchmarks rises by up to 51 percent relative to earlier CBMs.
- Performance remains within five percent of non-interpretable CLIP baselines.
Where Pith is reading between the lines
- The same dual-layer pattern could be inserted into other vision-language models that produce separate image and text embeddings.
- If the alignment holds, the set of concepts could be grown after training without retraining the backbone.
- Direct measurement of concept leakage on held-out tasks would give a quantitative check on the no-leakage premise.
Load-bearing premise
The dual concept bottleneck layers align image and text embeddings to shared concepts without significant information leakage or loss of generalization beyond the training concepts.
What would settle it
A test set of zero-shot classification or retrieval examples whose correct answers require concepts absent from the predefined set; if MM-CBM accuracy falls more than five percent below black-box performance or loses interpretability, the alignment claim fails.
Figures
read the original abstract
Concept Bottleneck Models (CBMs) enhance the interpretability of deep learning networks by aligning the features extracted from images with natural concepts. However, existing CBMs are constrained in their ability to generalize beyond a fixed set of predefined classes and the risk of non-concept information leakage, where predictive signals outside the intended concepts are inadvertently exploited. In this paper, we propose Multimodal Concept Bottleneck Model (MM-CBM) to address these issues and extend CBMs into CLIP. MM-CBM utilizes dual Concept Bottleneck Layers (CBLs) to align both the image and text embeddings into interpretable features. This allows us to perform new vision tasks like zero-shot classification or image retrieval in an interpretable way. Compared to existing methods, MM-CBM achieves up to 51.26% accuracy improvement on average across four standard benchmarks. Our method maintains high accuracy, staying within ~5% of black-box performance while offering greater interpretability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Multimodal Concept Bottleneck Model (MM-CBM) that extends standard Concept Bottleneck Models to CLIP by introducing dual Concept Bottleneck Layers (CBLs). These layers map both image and text embeddings onto a shared set of predefined concepts, enabling interpretable zero-shot classification and image retrieval while claiming to mitigate non-concept information leakage. Across four standard benchmarks the method is reported to deliver up to 51.26 % average accuracy improvement relative to prior CBMs and to remain within ~5 % of black-box CLIP performance.
Significance. If the dual-CBL construction demonstrably discards all non-concept signals and the reported gains survive standard controls for concept selection and statistical significance, the work would meaningfully extend the CBM paradigm into the multimodal zero-shot regime. The combination of interpretability with competitive zero-shot retrieval and classification would be a useful addition to the vision-language literature.
major comments (2)
- [Abstract] Abstract: the headline claim of 51.26 % average accuracy improvement and the assertion that dual CBLs prevent non-concept leakage are presented without any description of concept vocabulary construction, training procedure, or error bars. Because these details are load-bearing for both the performance and the interpretability claims, the abstract alone does not allow verification that the gains survive ordinary controls.
- [Method / Experiments] The central modeling assumption (that the chosen concept set spans essentially all variance in the CLIP embeddings) is not accompanied by any reported measurement of mutual information between post-CBL activations and the original embeddings, nor by an ablation that isolates concept-only versus full-embedding performance on the zero-shot tasks. Without such evidence the leakage concern raised in the skeptic note remains unaddressed.
minor comments (2)
- [Method] Notation for the two CBLs and the shared concept basis should be introduced with explicit equations rather than prose only.
- [Experiments] The four benchmarks are not named in the abstract; a table listing per-dataset numbers, concept counts, and black-box baselines would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond point-by-point to the major comments below, agreeing to revisions that improve clarity and evidence while defending the core methodological choices where they are supported by the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of 51.26 % average accuracy improvement and the assertion that dual CBLs prevent non-concept leakage are presented without any description of concept vocabulary construction, training procedure, or error bars. Because these details are load-bearing for both the performance and the interpretability claims, the abstract alone does not allow verification that the gains survive ordinary controls.
Authors: We agree the abstract is too concise for standalone verification. In the revision we will add a brief clause describing the concept vocabulary (derived from standard vision-language datasets aligned via CLIP text encoder) and the dual-CBL training objective. Error bars from repeated runs will be reported for all accuracy figures, and the 51.26 % figure will be explicitly defined as the mean relative improvement over prior CBM baselines across the four benchmarks. revision: yes
-
Referee: [Method / Experiments] The central modeling assumption (that the chosen concept set spans essentially all variance in the CLIP embeddings) is not accompanied by any reported measurement of mutual information between post-CBL activations and the original embeddings, nor by an ablation that isolates concept-only versus full-embedding performance on the zero-shot tasks. Without such evidence the leakage concern raised in the skeptic note remains unaddressed.
Authors: The dual-CBL construction projects both image and text embeddings onto an explicit shared concept space, which removes non-concept dimensions by design rather than by post-hoc filtering. While mutual-information statistics were not computed in the submitted version, the observed performance gap of only ~5 % relative to black-box CLIP on zero-shot tasks supplies supporting evidence that task-relevant information is retained. We will add an ablation comparing concept-bottleneck versus full-embedding performance and include mutual-information measurements between post-CBL and original embeddings in the revised experiments section. revision: partial
Circularity Check
No circularity; claims are empirical results, not derived quantities
full rationale
The paper reports empirical accuracy improvements (up to 51.26% avg. gain, within ~5% of black-box) from the MM-CBM architecture using dual CBLs on four benchmarks. No equations, derivations, or first-principles predictions appear in the abstract. The central claims rest on experimental outcomes rather than any fitted parameter renamed as a prediction, self-definitional mapping, or load-bearing self-citation chain. The method description (aligning embeddings to concepts) does not reduce to its inputs by construction; performance numbers are measured externally on held-out data. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Network dissection: Quantifying interpretability of deep visual representations
David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. Network dissection: Quantifying interpretability of deep visual representations. InCVPR, pages 6541–6549, 2017
2017
-
[2]
Interpreting clip with sparse linear concept embeddings (splice)
Usha Bhalla, Alex Oesterling, Suraj Srinivas, Flavio Calmon, and Himabindu Lakkaraju. Interpreting clip with sparse linear concept embeddings (splice). InAdvances in Neural Information Processing Systems, pages 84298–84328, 2024
2024
-
[3]
Language models can ex- plain neurons in language models
Steven Bills, Nick Cammarata, Dan Mossing, Henk Tillman, Leo Gao, Gabriel Goh, Ilya Sutskever, Jan Leike, Jeff Wu, and William Saunders. Language models can ex- plain neurons in language models. https://openaipublic.blob.core.windows.net/ neuron-explainer/paper/index.html, 2023
2023
-
[4]
Food-101–mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative components with random forests. InComputer vision–ECCV 2014: 13th European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part VI 13, pages 446–461. Springer, 2014
2014
-
[5]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[6]
Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts
Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3558–3568, 2021
2021
-
[7]
Jihye Choi, Jayaram Raghuram, Yixuan Li, and Somesh Jha. Adaptive concept bottleneck for foundation models under distribution shifts.arXiv preprint arXiv:2412.14097, 2024
-
[8]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3606–3613, 2014
2014
-
[9]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[10]
Multimodal neurons in artificial neural networks.Distill, 6(3): e30, 2021
Gabriel Goh, Nick Cammarata, Chelsea V oss, Shan Carter, Michael Petrov, Ludwig Schubert, Alec Radford, and Chris Olah. Multimodal neurons in artificial neural networks.Distill, 6(3): e30, 2021
2021
-
[11]
Natural language descriptions of deep visual features
Evan Hernandez, Sarah Schwettmann, David Bau, Teona Bagashvili, Antonio Torralba, and Jacob Andreas. Natural language descriptions of deep visual features. InICLR, 2021
2021
-
[12]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
Identifying interpretable subspaces in image representations
Neha Kalibhat, Shweta Bhardwaj, C Bayan Bruss, Hamed Firooz, Maziar Sanjabi, and Soheil Feizi. Identifying interpretable subspaces in image representations. InICML, pages 15623– 15638. PMLR, 2023
2023
-
[14]
Mohammad Ali Khan, Tuomas Oikarinen, and Tsui-Wei Weng. Concept-monitor: Understand- ing dnn training through individual neurons.arXiv preprint arXiv:2304.13346, 2023
-
[15]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[16]
Concept bottleneck models
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. InInternational conference on machine learning, pages 5338–5348. PMLR, 2020
2020
-
[17]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009. 10
2009
-
[18]
Scaling language-image pre-training via masking
Yanghao Li, Haoqi Fan, Ronghang Hu, Christoph Feichtenhofer, and Kaiming He. Scaling language-image pre-training via masking. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 23390–23400, 2023
2023
-
[19]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
2023
-
[20]
Visual classification via description from large language models
Sachit Menon and Carl V ondrick. Visual classification via description from large language models. InICLR, 2023
2023
-
[21]
Scaling open-vocabulary object detection
Matthias Minderer, Alexey Gritsenko, and Neil Houlsby. Scaling open-vocabulary object detection. InNeurIPS, 2024
2024
-
[22]
Clip-dissect: Automatic description of neuron rep- resentations in deep vision networks
Tuomas Oikarinen and Tsui-Wei Weng. Clip-dissect: Automatic description of neuron rep- resentations in deep vision networks. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[23]
Linear explanations for individual neurons
Tuomas Oikarinen and Tsui-Wei Weng. Linear explanations for individual neurons. InInterna- tional Conference on Machine Learning, pages 38639–38662. PMLR, 2024
2024
-
[24]
Label-free concept bottleneck models
Tuomas Oikarinen, Subhro Das, Lam Nguyen, and Lily Weng. Label-free concept bottleneck models. InICLR, 2023
2023
-
[25]
Cats and dogs
Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. In2012 IEEE conference on computer vision and pattern recognition, pages 3498–3505. IEEE, 2012
2012
-
[26]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InICML, 2021
2021
-
[27]
A multimodal automated interpretability agent
Tamar Rott Shaham, Sarah Schwettmann, Franklin Wang, Achyuta Rajaram, Evan Hernandez, Jacob Andreas, and Antonio Torralba. A multimodal automated interpretability agent. In Forty-first International Conference on Machine Learning, 2024
2024
-
[28]
Incremental residual concept bottleneck models
Chenming Shang, Shiji Zhou, Hengyuan Zhang, Xinzhe Ni, Yujiu Yang, and Yuwang Wang. Incremental residual concept bottleneck models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11030–11040, 2024
2024
-
[29]
Vlg-cbm: Training concept bottleneck models with vision-language guidance
Divyansh Srivastava, Ge Yan, and Tsui-Wei Weng. Vlg-cbm: Training concept bottleneck models with vision-language guidance. InNeurIPS, 2024
2024
-
[30]
Concept bottleneck large language models.ICLR, 2025
Chung-En Sun, Tuomas Oikarinen, Berk Ustun, and Tsui-Wei Weng. Concept bottleneck large language models.ICLR, 2025
2025
-
[31]
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang, and Yue Cao. Eva-clip: Improved training techniques for clip at scale.arXiv preprint arXiv:2303.15389, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
The caltech-ucsd birds-200-2011 dataset
Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech-ucsd birds-200-2011 dataset. 2011
2011
-
[34]
Transformers: State-of- the-art natural language processing
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. Transformers: State-of- the-art natural language processing. InEMNLP, 2020
2020
-
[35]
Learning concise and descriptive attributes for visual recognition
An Yan, Yu Wang, Yiwu Zhong, Chengyu Dong, Zexue He, Yujie Lu, William Yang Wang, Jingbo Shang, and Julian McAuley. Learning concise and descriptive attributes for visual recognition. InICCV, 2023. 11
2023
-
[36]
Clip-kd: An empirical study of clip model distillation
Chuanguang Yang, Zhulin An, Libo Huang, Junyu Bi, Xinqiang Yu, Han Yang, Boyu Diao, and Yongjun Xu. Clip-kd: An empirical study of clip model distillation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15952–15962, 2024
2024
-
[37]
Language in a bottle: Language model guided concept bottlenecks for interpretable image classification
Yue Yang, Artemis Panagopoulou, Shenghao Zhou, Daniel Jin, Chris Callison-Burch, and Mark Yatskar. Language in a bottle: Language model guided concept bottlenecks for interpretable image classification. InCVPR, 2023
2023
-
[38]
Post-hoc concept bottleneck models
Mert Yuksekgonul, Maggie Wang, and James Zou. Post-hoc concept bottleneck models. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[39]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023. 12 A Appendix A.1 Overview The appendix covers: A.2 concept set generation; A.3 interpretability enhancement strategies; A.4 unsupervised adapt...
2023
-
[40]
Concept length:Discard concepts exceeding 30 characters to maintain simplicity and interpretability
-
[41]
Similarity is measured via cosine similarity in a joint text embedding space, combining features from the CLIP ViT-B/16 text encoder and the all-mpnet-base-v2 sentence encoder
Similarity to target classes:Remove concepts overly similar to target class names, as they undermine the explanatory role of the CBM. Similarity is measured via cosine similarity in a joint text embedding space, combining features from the CLIP ViT-B/16 text encoder and the all-mpnet-base-v2 sentence encoder. Concepts with similarity greater than 0.85 to ...
-
[42]
If I had to describe this image using only one sentence with the words class, it would be:
Redundancy removal:Eliminate duplicate or near-synonymous concepts to ensure diversity in the bottleneck layer. Using the same embedding space, any concept with cosine similarity above0.9to an already retained concept is removed. This automated generation and filtering process substantially reduces the reliance on manual annota- tion while enabling scalab...
-
[43]
By removing negative values, we avoid this ambiguity
Disambiguating negative responses.As discussed in [ 30], it is often unclear whether a negative activation implies the negation of a concept or its complete absence. By removing negative values, we avoid this ambiguity
-
[44]
By zeroing out irrelevant (negative) dimensions, we strengthen the contribution of mean- ingful concepts
Amplifying relevant concept activations.Since similarity computations involve normaliza- tion, weak activations in high-dimensional spaces can lead to dilution of important signals. By zeroing out irrelevant (negative) dimensions, we strengthen the contribution of mean- ingful concepts. In the worst-case scenario, each dimension has a value of at most q 1...
-
[45]
barbershop
Improving inference reliability and efficiency.Without non-negativity, the product of two negative activations (from image and text encodings) may yield a misleadingly high similarity score, falsely indicating semantic alignment. Enforcing non-negativity eliminates this issue and also simplifies the computation and sorting steps during inference. A.4 Unsu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.