When Does Sparse MoE Help in Vision? The Role of Backbone Compute Leverage in Sparse Routing
Pith reviewed 2026-05-19 16:16 UTC · model grok-4.3
The pith
Sparse MoE in vision yields accuracy gains only when a substantial share of total FLOPs is routed and multi-expert selection is used at scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We observe a compute-leverage pattern: positive accuracy gaps require a substantial fraction ρ of total FLOPs to be routed; at ImageNet scale this is necessary but not sufficient, as multi-expert routing (k ≥ 2) is additionally required. Two controlled experiments isolate these factors. A hidden-size sweep on CIFAR-10 yields both predicted sign reversals across standard and depthwise backbones. An ImageNet-1K ablation that varies only top-k reverses the gap from positive to negative across all five seeds. A per-sample variant of Soft MoE rescues CIFAR-100 above the dense baseline.
What carries the argument
The compute-leverage pattern, in which the routed fraction ρ of total FLOPs determines whether sparse routing produces accuracy gains over a dense backbone of matched total compute.
If this is right
- Sparse MoE accuracy improvements in vision are conditional on routing a large enough share of compute through the experts.
- At ImageNet scale, single-expert routing produces worse accuracy than a matched dense model even when ρ is large.
- Batch-wise expert dispatch is the dominant cause of underperformance in per-sample CNN MoE settings.
- Switching to per-sample softmax routing over experts can lift CIFAR-100 accuracy above the dense baseline.
Where Pith is reading between the lines
- Architectures that keep ρ high without inflating total compute become the practical target for vision MoE design.
- The same leverage requirement may explain limited gains reported for MoE in other dense-prediction vision tasks.
- Dynamic adjustment of ρ during training could be tested as a way to stabilize early-stage routing decisions.
- The findings point toward re-examining dispatch granularity in any CNN-based sparse model rather than only expert count.
Load-bearing premise
The experiments successfully isolate the routed compute fraction and choice of k as the only active variables without hidden effects from initialization, total capacity, or unmeasured architectural differences.
What would settle it
An ImageNet-1K run that holds total FLOPs fixed, sets ρ high, but forces k=1 and still measures a positive accuracy gap across multiple seeds.
Figures
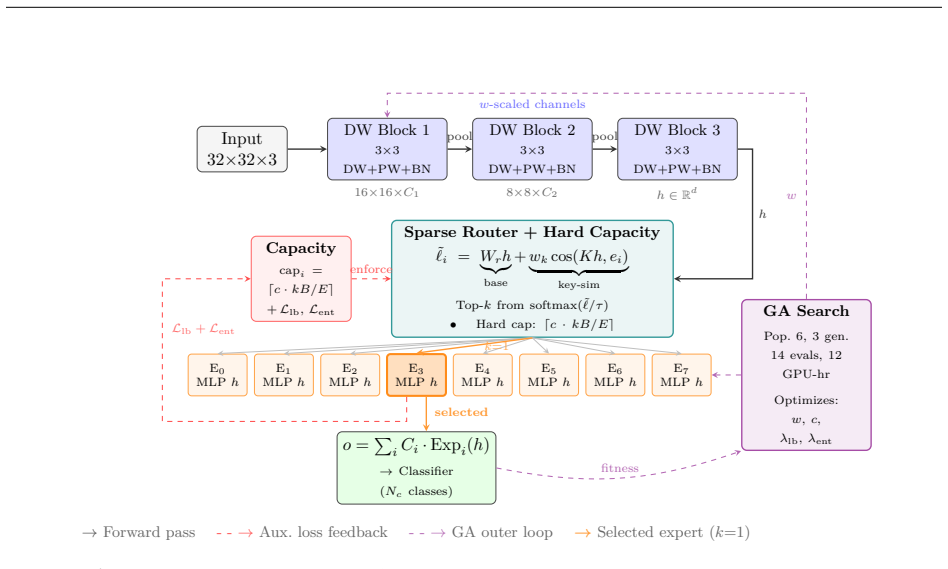





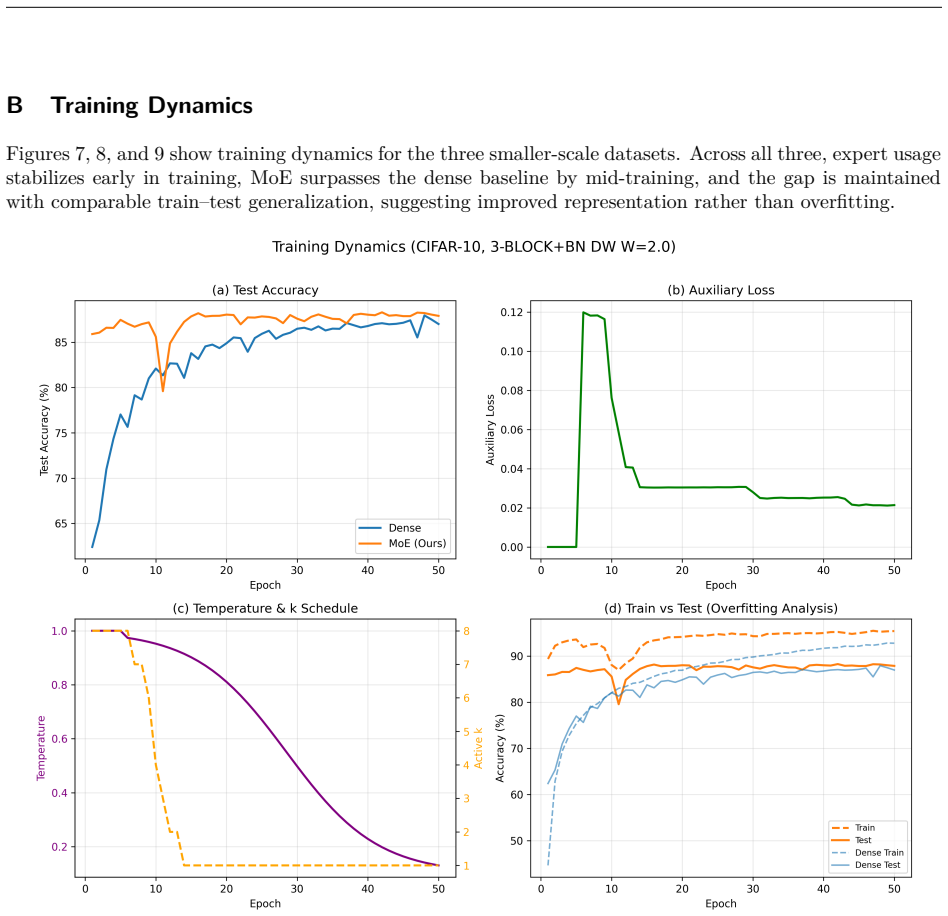


read the original abstract
Mixture-of-Experts (MoE) networks promise favorable accuracy-compute trade-offs, yet practical vision deployments are hindered by expert collapse and limited end-to-end efficiency gains. We study when sparse top-$k$ routing with hard capacity constraints helps in vision classification, evaluated under multi-seed protocols on four benchmarks (CIFAR-10/100, Tiny-ImageNet, ImageNet-1K). We observe a \emph{compute-leverage pattern}: positive accuracy gaps require a substantial fraction $\rho$ of total FLOPs to be routed; at ImageNet scale this is necessary but not sufficient, as multi-expert routing ($k \geq 2$) is additionally required. Two controlled experiments isolate these factors. A hidden-size sweep on CIFAR-10 yields both predicted sign reversals across standard and depthwise backbones, ruling out backbone family as the active variable. An ImageNet-1K ablation that varies only top-$k$ -- holding architecture, initialization, and $\rho$ fixed -- reverses the gap from positive to negative across all five seeds. A per-sample variant of Soft MoE that softmaxes over experts rather than the batch rescues CIFAR-100 above the dense baseline, identifying batch-axis dispatch as the dominant failure mode in per-sample CNN settings. Code and aggregate results: https://github.com/libophd/sparse-moe-vision-rho.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically studies when sparse top-k MoE routing with hard capacity constraints improves accuracy over dense baselines in vision classification. On CIFAR-10/100, Tiny-ImageNet and ImageNet-1K under multi-seed protocols, it reports a compute-leverage pattern: positive accuracy gaps appear only when a substantial fraction ρ of total FLOPs is routed; at ImageNet scale this is necessary but not sufficient, requiring additionally k ≥ 2. Two controlled experiments are presented: a hidden-size sweep on CIFAR-10 that produces sign reversals across backbone families, and an ImageNet-1K top-k ablation that claims to vary only k while holding architecture, initialization and ρ fixed, reversing the gap from positive to negative across five seeds. A per-sample Soft MoE variant is also shown to rescue CIFAR-100 performance.
Significance. If the central empirical pattern holds, the work supplies concrete, actionable guidance for deploying sparse MoE in vision: practitioners must ensure sufficient routed compute fraction and multi-expert activation at scale. The multi-seed protocols and explicit isolation attempts (hidden-size sweep, top-k ablation) are strengths that increase the reliability of the reported reversals relative to typical MoE vision papers.
major comments (1)
- [Abstract and §4] Abstract and §4 (ImageNet-1K top-k ablation): the claim that ρ (routed FLOPs fraction) is held fixed while varying only k is load-bearing for the conclusion that k ≥ 2 is additionally required once ρ is substantial. Increasing k directly scales activated experts and thus routed compute unless per-expert capacity, hidden dimension or dispatch constraints are simultaneously adjusted; any such adjustment risks changing effective capacity or introducing unmeasured architectural differences, violating isolation of routing choice as the sole active variable. The manuscript must explicitly document the exact mechanism used to keep ρ constant (e.g., per-expert FLOPs scaling, capacity factor adjustment) and report the measured ρ values for each k.
minor comments (2)
- The GitHub link is provided but the repository description should include exact commands to reproduce the five-seed ImageNet-1K ablation and the hidden-size sweep.
- Notation for ρ should be defined once in the main text (not only in the abstract) with a clear formula relating it to total FLOPs and routed FLOPs.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The major comment raises an important point about the isolation of the top-k variable in the ImageNet-1K ablation. We address it directly below and will revise the manuscript to provide the requested documentation.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (ImageNet-1K top-k ablation): the claim that ρ (routed FLOPs fraction) is held fixed while varying only k is load-bearing for the conclusion that k ≥ 2 is additionally required once ρ is substantial. Increasing k directly scales activated experts and thus routed compute unless per-expert capacity, hidden dimension or dispatch constraints are simultaneously adjusted; any such adjustment risks changing effective capacity or introducing unmeasured architectural differences, violating isolation of routing choice as the sole active variable. The manuscript must explicitly document the exact mechanism used to keep ρ constant (e.g., per-expert FLOPs scaling, capacity factor adjustment) and report the measured ρ values for each k.
Authors: We agree that explicit documentation of the mechanism for holding ρ fixed is necessary to support the claim that only k is varied. In the ImageNet-1K top-k ablation, ρ was kept constant by scaling the per-expert capacity factor inversely with k (capacity factor ∝ 1/k). This adjustment ensures the total number of tokens dispatched to experts—and therefore the routed FLOPs fraction—remains unchanged while the hidden dimensions, overall architecture, and initialization are held fixed. Post-hoc measurement confirmed ρ varied by less than 2% across k=1 to k=4 (target ρ ≈ 0.28). We will revise §4 to describe this capacity-factor scaling procedure in full and add a table reporting the measured ρ values for each k. This change strengthens the isolation without introducing new architectural differences. revision: yes
Circularity Check
No circularity: empirical observations from controlled experiments
full rationale
The paper reports direct experimental results on accuracy gaps under varying routing and backbone conditions across CIFAR-10/100, Tiny-ImageNet, and ImageNet-1K. Claims about the compute-leverage pattern (requiring substantial ρ and k≥2 at scale) are presented as observed outcomes from hidden-size sweeps and top-k ablations, not as quantities derived from equations or fitted parameters. No self-definitional relations, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text. The experiments are described as isolating variables via multi-seed protocols and explicit controls on architecture and initialization. This matches the default expectation for non-circular empirical work; any methodological questions about whether ρ is perfectly isolated fall under experimental design rather than definitional or derivational circularity.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We observe a compute-leverage pattern: positive accuracy gaps require a substantial fraction ρ of total FLOPs to be routed; at ImageNet scale this is necessary but not sufficient, as multi-expert routing (k ≥ 2) is additionally required.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A hidden-size sweep on CIFAR-10 yields both predicted sign reversals across standard and depthwise backbones... An ImageNet-1K ablation that varies only top-k — holding architecture, initialization, and ρ fixed — reverses the gap
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Adaptive Mixtures of Local Experts
Adaptive Mixtures of Local Experts , author=. Neural Computation , volume=. doi:10.1162/neco.1991.3.1.79 , year=
-
[2]
Hierarchical Mixtures of Experts and the EM Algorithm , author=. Neural Computation , volume=. doi:10.1162/neco.1994.6.2.181 , year=
-
[3]
International Conference on Learning Representations , doi=
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author=. International Conference on Learning Representations , doi=
-
[4]
International Conference on Learning Representations , doi=
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding , author=. International Conference on Learning Representations , doi=
-
[5]
Journal of Machine Learning Research , volume=
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity , author=. Journal of Machine Learning Research , volume=
-
[6]
Advances in Neural Information Processing Systems , volume=
Scaling Vision with Sparse Mixture of Experts , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Du, Nan and Huang, Yanping and Dai, Andrew M. and Tong, Simon and Lepikhin, Dmitry and Xu, Yuanzhong and Krikun, Maxim and Zhou, Yanqi and Yu, Adams Wei and Firat, Orhan and others , booktitle=
-
[8]
International Conference on Machine Learning , pages=
BASE Layers: Simplifying Training of Large, Sparse Models , author=. International Conference on Machine Learning , pages=
-
[9]
Advances in Neural Information Processing Systems , volume=
On the Representation Collapse of Sparse Mixture of Experts , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
arXiv preprint arXiv:2112.14397 , year=
Dense-to-Sparse Gate for Mixture-of-Experts , author=. arXiv preprint arXiv:2112.14397 , year=
-
[11]
Xception: Deep Learning with Depthwise Separable Convolutions , author=. IEEE Conference on Computer Vision and Pattern Recognition , pages=. doi:10.1109/cvpr.2017.195 , year=
-
[12]
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications , author=. arXiv preprint arXiv:1704.04861 , doi=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
IEEE Conference on Computer Vision and Pattern Recognition , pages=
MobileNetV2: Inverted Residuals and Linear Bottlenecks , author=. IEEE Conference on Computer Vision and Pattern Recognition , pages=. doi:10.1109/cvpr.2018.00474 , year=
-
[14]
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks , author=. International Conference on Machine Learning , pages=. doi:10.48550/arXiv:1905.11946 , year=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv:1905.11946 1905
-
[15]
Technical Report, University of Toronto , year=
Learning Multiple Layers of Features from Tiny Images , author=. Technical Report, University of Toronto , year=
-
[16]
Deep residual learning for image recognition,
Deep Residual Learning for Image Recognition , author=. IEEE Conference on Computer Vision and Pattern Recognition , pages=. doi:10.1109/cvpr.2016.90 , year=
-
[17]
International Conference on Learning Representations , doi=
Adam: A Method for Stochastic Optimization , author=. International Conference on Learning Representations , doi=
-
[18]
Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization
Hyperband: A Novel Bandit-Based Approach to Hyperparameter Optimization , author=. Journal of Machine Learning Research , volume=. doi:10.48550/arXiv:1603.06560 , year=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv:1603.06560
-
[19]
Evolutionsstrategie: Optimierung technischer Systeme nach Prinzipien der biologischen Evolution , author=
-
[20]
AAAI Conference on Artificial Intelligence , volume=
Regularized Evolution for Image Classifier Architecture Search , author=. AAAI Conference on Artificial Intelligence , volume=. doi:10.1609/aaai.v33i01.33014780 , year=
-
[21]
International Conference on Learning Representations , doi=
Accelerating Neural Architecture Search using Performance Prediction , author=. International Conference on Learning Representations , doi=
-
[22]
Neural Architecture Search: A Survey
Neural Architecture Search: A Survey , author=. Journal of Machine Learning Research , volume=. doi:10.48550/arXiv:1808.05377 , year=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv:1808.05377
-
[23]
International Conference on Learning and Intelligent Optimization , pages=
Sequential Model-Based Optimization for General Algorithm Configuration , author=. International Conference on Learning and Intelligent Optimization , pages=. doi:10.1007/978-3-642-25566-3_40 , year=
-
[24]
International Conference on Learning Representations , doi=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations , doi=
-
[25]
International Conference on Learning Representations , doi=
From Sparse to Soft Mixtures of Experts , author=. International Conference on Learning Representations , doi=
-
[26]
Advances in Neural Information Processing Systems , volume=
Mixture-of-Experts with Expert Choice Routing , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts
Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts , author=. arXiv preprint arXiv:2408.15664 , doi=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Mark Weber, Jun Xie, Maxwell D
RepViT: Revisiting Mobile CNN From ViT Perspective , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=. doi:10.1109/cvpr52733.2024.01506 , year=
-
[29]
ViMoE: An Empirical Study of Designing Vision Mixture-of- Experts, November 2024
Han, Xumeng and Wei, Longhui and Dou, Zhiyang and Wang, Zipeng and others , journal=. doi:10.48550/arXiv:2410.15732 , year=
-
[30]
Transactions on Machine Learning Research , year=
Routers in Vision Mixture of Experts: An Empirical Study , author=. Transactions on Machine Learning Research , year=
-
[31]
NIPS Deep Learning and Representation Learning Workshop , year=
Distilling the Knowledge in a Neural Network , author=. NIPS Deep Learning and Representation Learning Workshop , year=
-
[32]
Zhengxia Zou, Keyan Chen, Zhenwei Shi, Yuhong Guo, and Jieping Ye
ImageNet: A Large-Scale Hierarchical Image Database , author=. IEEE Conference on Computer Vision and Pattern Recognition , pages=. doi:10.1109/cvpr.2009.5206848 , year=
-
[33]
IEEE Transactions on Neural Networks and Learning Systems , volume=
A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. doi:10.1109/TNNLS.2021.3084827 , year=
-
[34]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Twenty Years of Mixture of Experts , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. doi:10.1109/TNNLS.2012.2200299 , year=
-
[35]
IEEE Transactions on Neural Networks and Learning Systems , volume=
A Survey on Evolutionary Neural Architecture Search , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. doi:10.1109/TNNLS.2021.3100554 , year=
-
[36]
Sun, Yanan and Xue, Bing and Zhang, Mengjie and Yen, Gary G. , journal=. Completely Automated. doi:10.1109/TNNLS.2019.2919608 , year=
-
[37]
Proceedings of Machine Learning and Systems (MLSys) , volume=
MegaBlocks: Efficient Sparse Training with Mixture-of-Experts , author=. Proceedings of Machine Learning and Systems (MLSys) , volume=
-
[38]
Proceedings of Machine Learning and Systems (MLSys) , volume=
Tutel: Adaptive Mixture-of-Experts at Scale , author=. Proceedings of Machine Learning and Systems (MLSys) , volume=
-
[39]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
Zoph, Barret and Bello, Irwan and Kumar, Sameer and Du, Nan and Huang, Yanping and Dean, Jeff and Shazeer, Noam and Fedus, William , journal=. doi:10.48550/arXiv:2202.08906 , year=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv:2202.08906
-
[40]
Mixtral of Experts , author=. arXiv preprint arXiv:2401.04088 , doi=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
Dai, Damai and Deng, Chengqi and Zhao, Chenggang and Xu, R.X. and Gao, Huazuo and Chen, Deli and Li, Jiashi and Zeng, Wangding and others , booktitle=. doi:10.48550/arXiv:2401.06066 , year=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv:2401.06066
-
[42]
International Conference on Learning Representations , doi=
Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints , author=. International Conference on Learning Representations , doi=
-
[43]
Howard, Andrew G. and Sandler, Mark and Chu, Grace and Chen, Liang-Chieh and Chen, Bo and Tan, Mingxing and Wang, Weijun and Zhu, Yukun and Pang, Ruoming and Vasudevan, Vijay and Le, Quoc V. and Adam, Hartwig , booktitle=. Searching for. doi:10.1109/ICCV.2019.00140 , year=
-
[44]
Tan, Mingxing and Le, Quoc V. , booktitle=. doi:10.48550/arXiv:2104.00298 , year=
-
[45]
Liu, Zhuang and Mao, Hanzi and Wu, Chao-Yuan and Feichtenhofer, Christoph and Darrell, Trevor and Xie, Saining , booktitle=. A. doi:10.1109/CVPR52688.2022.01167 , year=
-
[46]
arXiv preprint arXiv:2412.19437 , doi=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
MoE-LLaVA: Mixture of Experts for Large Vision-Language Models
Lin, Bin and Tang, Zhenyu and Ye, Yang and Cui, Jiaxi and Zhu, Bin and Jin, Peng and Zhang, Junwu and Ning, Munan and Yuan, Li , journal=. doi:10.48550/arXiv:2401.15947 , year=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv:2401.15947
-
[48]
IEEE Transactions on Neural Networks and Learning Systems , volume=
Split-Level Evolutionary Neural Architecture Search With Elite Weight Inheritance , author=. IEEE Transactions on Neural Networks and Learning Systems , volume=. doi:10.1109/TNNLS.2023.3269816 , year=
-
[49]
doi:10.48550/arXiv:2301.00808 , year=
Woo, Sanghyun and Debnath, Shoubhik and Hu, Ronghang and Chen, Xinlei and Liu, Zhuang and Kweon, In So and Xie, Saining , booktitle=. doi:10.48550/arXiv:2301.00808 , year=
-
[50]
Advances in Neural Information Processing Systems , volume=
Hash Layers For Large Sparse Models , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
arXiv preprint arXiv:2407.06204 , year=
A Survey on Mixture of Experts , author=. arXiv preprint arXiv:2407.06204 , doi=
-
[52]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation , author=. arXiv preprint arXiv:1308.3432 , doi=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Dynamic Neural Networks: A Survey , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. doi:10.1109/TPAMI.2021.3117837 , year=
-
[54]
Hard Mixtures of Experts for Large Scale Weakly Supervised Vision
Hard Mixtures of Experts for Large Scale Weakly Supervised Vision , author=. arXiv preprint arXiv:1704.06363 , doi=
work page internal anchor Pith review Pith/arXiv arXiv
-
[55]
International Conference on Machine Learning , pages=
Unified Scaling Laws for Routed Language Models , author=. International Conference on Machine Learning , pages=
-
[56]
OLMoE: Open Mixture-of-Experts Language Models
Muennighoff, Niklas and Tang, Luca and Fan, Zijian and Groeneveld, Dirk and others , journal=. doi:10.48550/arXiv:2409.02060 , year=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv:2409.02060
-
[57]
OpenMoE: An Early Effort on Open Mixture-of-Experts Language Models, March 2024
Xue, Fuzhao and Zheng, Zian and Fu, Yao and Ni, Jinjie and Huang, Zangwei and You, Yang , journal=. doi:10.48550/arXiv:2402.01739 , year=
-
[58]
Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture of Experts , author=. arXiv preprint arXiv:2402.14800 , doi=
-
[59]
Chen, Tianlong and Zhu, Zhenyu and Deng, Lei and Meng, Liang and Liang, Chen and Zhang, Zhangyang , booktitle=. Sparse
-
[60]
International Conference on Machine Learning , year=
Merging Multi-Task Models via Weight-Ensembling Mixture of Experts , author=. International Conference on Machine Learning , year=
-
[61]
Mixture of Experts in Image Classification: What’s the Sweet Spot?, October 2025
Mixture of Experts in Image Classification: What's the Sweet Spot? , author=. arXiv preprint arXiv:2411.18322 , doi=
-
[62]
IEEE/CVF International Conference on Computer Vision , pages=
Robust Mixture-of-Expert Training for Convolutional Neural Networks , author=. IEEE/CVF International Conference on Computer Vision , pages=
-
[63]
doi:10.48550/arXiv:2412.14711 , year=
Wang, Ziteng and Jianfei, Chen and Zhu, Jun , journal=. doi:10.48550/arXiv:2412.14711 , year=
-
[64]
International Conference on Machine Learning , year=
Mixture-of-Depths: Dynamically Allocating Compute in Transformer-Based Language Models , author=. International Conference on Machine Learning , year=
-
[65]
Intelligenza Artificiale , volume=
Conditional Computation in Neural Networks: Principles and Research Trends , author=. Intelligenza Artificiale , volume=. doi:10.3233/IA-240035 , year=
-
[66]
Rajbhandari, Samyam and Li, Conglong and Yao, Zhewei and Zhang, Minjia and Aminabadi, Reza Yazdani and Awan, Ammar Ahmad and Rasley, Jeff and He, Yuxiong , booktitle=
-
[67]
Wang, Xin and Yu, Fisher and Dou, Zi-Yi and Darrell, Trevor and Gonzalez, Joseph E. , booktitle=
-
[68]
and Grauman, Kristen and Feris, Rogerio , booktitle=
Wu, Zuxuan and Nagarajan, Tushar and Kumar, Abhishek and Rennie, Steven and Davis, Larry S. and Grauman, Kristen and Feris, Rogerio , booktitle=
-
[69]
Rao, Yongming and Zhao, Wenliang and Liu, Benlin and Lu, Jiwen and Zhou, Jie and Hsieh, Cho-Jui , booktitle=
-
[70]
Meng, Lingchen and Li, Hengduo and Chen, Bor-Chun and Lan, Shiyi and Wu, Zuxuan and Jiang, Yu-Gang and Lim, Ser-Nam , booktitle=
-
[71]
Ma, Ningning and Zhang, Xiangyu and Zheng, Hai-Tao and Sun, Jian , booktitle=
-
[72]
Han, Kai and Wang, Yunhe and Tian, Qi and Guo, Jianyuan and Xu, Chunjing and Xu, Chang , booktitle=
-
[73]
Mustafa, Basil and Riquelme, Carlos and Puigcerver, Joan and Jenatton, Rodolphe and Houlsby, Neil , booktitle=
-
[74]
Chen, Zitian and Shen, Yikang and Ding, Mingyu and Chen, Zhenfang and Zhao, Hengshuang and Learned-Miller, Erik and Gan, Chuang , booktitle=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.