Chehre: An Emoji-Prompted Video Dataset for Perceptually Diverse Facial Expression Recognition
Pith reviewed 2026-06-26 14:31 UTC · model grok-4.3
The pith
Emoji-prompted videos show current models reach only 32.5 percent top-1 accuracy on dominant facial expression recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
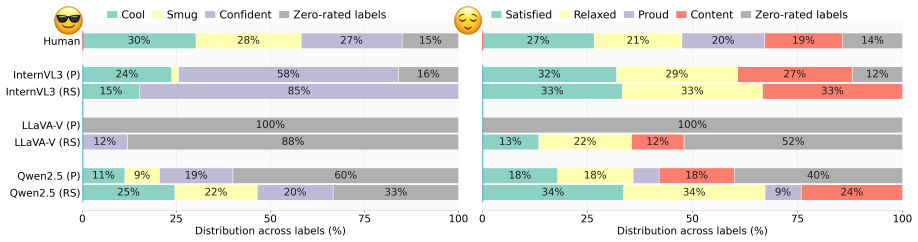
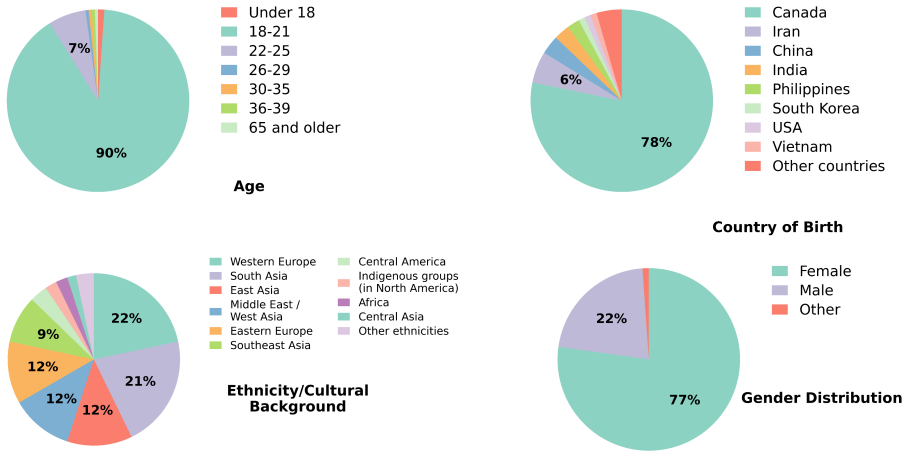
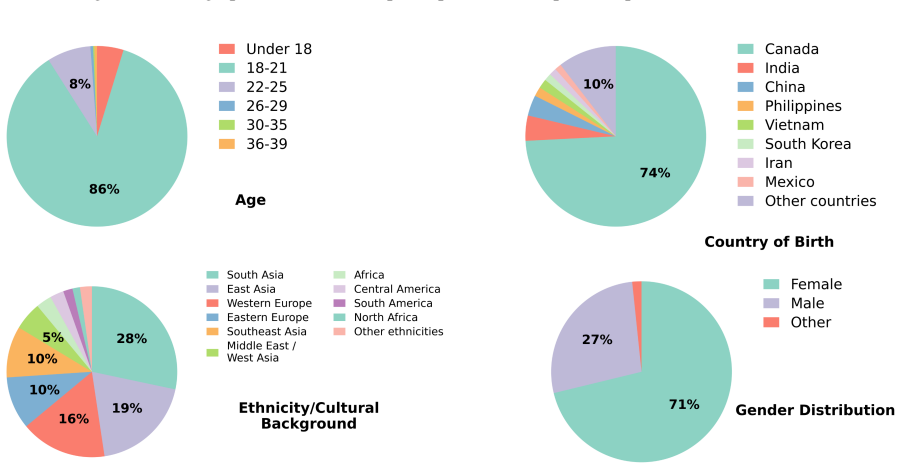
Chehre consists of 2,111 high-quality videos from 203 performers prompted with 40 facial emojis, anonymized via synthetic face transfer, and validated by 902 annotators. It establishes dominant expression recognition and distributional expression recognition as benchmark tasks and demonstrates that both remain challenging, with the best evaluated model achieving only 32.5 percent Top-1 accuracy on the first task and a Spread Ratio below the human reference on the second.
What carries the argument
The emoji-prompted video collection paired with dual benchmark tasks for dominant and distributional expression recognition.
If this is right
- Vision-language models using persona prompting fail to match human performance on both single dominant labels and full distributional responses.
- The dataset supplies a concrete benchmark for testing new methods on dynamic expressions that exhibit inter-individual perceptual variation.
- Synthetic face transfer enables privacy-safe collection and multi-annotator validation while preserving the expressions needed for the tasks.
- Human annotations on the videos exhibit substantial label spread, confirming that perceptual diversity is a measurable property of the data.
Where Pith is reading between the lines
- Models may need explicit mechanisms to output full distributions over labels rather than single predictions.
- The same prompting-plus-anonymization method could be applied to other perceptual domains where human agreement is low, such as gesture or vocal emotion.
- Expanding the emoji set or comparing synthetic versus real-face versions would test whether the observed performance gaps persist.
Load-bearing premise
That prompting performers with a fixed set of 40 emojis and transferring their motions to synthetic faces produces expressions whose perceptual properties and diversity match those in natural interactions.
What would settle it
A model that reaches top-1 accuracy near the level of human inter-annotator agreement or produces output distributions whose spread ratio matches the human reference on the Chehre test videos.
Figures





read the original abstract
Facial expressions are nonverbal social signals used in human interaction, but facial expression recognition datasets often focus on static images, basic emotion categories, or single deterministic annotations. We introduce Chehre, an emoji-prompted video dataset for analyzing dynamic facial expressions across a wide range of expressions for exploring inter-individual perceptual diversity. In Chehre, participants were prompted to express and record 40 facial emojis. Later, their facial motions were transferred onto synthetic faces to preserve privacy. A separate group of annotators analyzed the anonymized videos using emoji and label annotations, resulting in 2,111 high quality videos collected from 203 performers and validated by 902 annotators. We define two benchmark tasks: dominant expression recognition, which tests whether models recover the top human-rated labels, and distributional expression recognition, which tests whether models capture the diversity of human responses. We benchmark recent vision-language models using random sampling and persona prompting to generate multiple predictions per video. Results show that both tasks are challenging: among the models evaluated, the best-performing model achieves only 32.5% Top-1 accuracy on dominant expression recognition and a Spread Ratio well below the human reference on distributional recognition. Chehre provides a benchmark for evaluating diverse, dynamic, and distributional facial expression recognition
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Chehre, an emoji-prompted video dataset for dynamic facial expression recognition that targets inter-individual perceptual diversity. It describes collecting 2,111 videos from 203 performers prompted with 40 emojis, transferring motions to synthetic faces for privacy, and obtaining annotations from 902 annotators to support two tasks: dominant expression recognition (recovering top human labels) and distributional expression recognition (capturing response diversity). Vision-language models are benchmarked via random sampling and persona prompting, with the best model reported at 32.5% Top-1 accuracy on the dominant task and a Spread Ratio below the human reference on the distributional task. The paper positions Chehre as a challenging benchmark addressing limitations of prior static, categorical, or deterministic datasets.
Significance. If the construction process is shown to elicit and preserve natural perceptual diversity, the dataset would offer a meaningful advance by enabling evaluation of models on distributional rather than single-label expression recognition. This addresses a recognized gap in affective computing where most benchmarks do not capture annotator variability. The empirical demonstration that current VLMs fall well short of human performance on both tasks would help motivate research on more nuanced, multi-label approaches to dynamic expression understanding.
major comments (2)
- [Dataset Construction] The central claim that Chehre provides a benchmark for human-like perceptual diversity (and thus that the 32.5% Top-1 and sub-human Spread Ratio reflect model limitations) depends on the unvalidated assumptions that emoji prompts produce generalizable natural expressions and that synthetic motion transfer preserves the perceptual cues used by annotators. No fidelity metrics, real-vs-synthetic comparisons, emoji-conditioned diversity statistics, or ablation studies are described to support these steps.
- [Benchmarking Experiments] The abstract states specific performance figures (32.5% Top-1 accuracy, Spread Ratio results) without reporting the experimental protocol, model list, number of samples per video, train/test splits, or statistical significance tests. This information is required to assess whether the 'challenging' characterization is robust.
minor comments (1)
- The abstract refers to 'high quality videos' and 'validated by 902 annotators' but does not define the quality criteria or inter-annotator agreement metrics used during filtering.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Dataset Construction] The central claim that Chehre provides a benchmark for human-like perceptual diversity (and thus that the 32.5% Top-1 and sub-human Spread Ratio reflect model limitations) depends on the unvalidated assumptions that emoji prompts produce generalizable natural expressions and that synthetic motion transfer preserves the perceptual cues used by annotators. No fidelity metrics, real-vs-synthetic comparisons, emoji-conditioned diversity statistics, or ablation studies are described to support these steps.
Authors: We acknowledge that the original manuscript lacks explicit quantitative fidelity metrics or real-vs-synthetic perceptual comparisons. Emoji prompts were selected to cover a broad range of expressions based on established affective computing literature, and motion transfer follows standard privacy-preserving pipelines. To address the concern, the revision will include emoji-conditioned label diversity statistics and qualitative real-vs-synthetic frame comparisons. Comprehensive ablation studies on prompt generalizability would require new data collection and are noted as future work rather than added in this revision. revision: partial
-
Referee: [Benchmarking Experiments] The abstract states specific performance figures (32.5% Top-1 accuracy, Spread Ratio results) without reporting the experimental protocol, model list, number of samples per video, train/test splits, or statistical significance tests. This information is required to assess whether the 'challenging' characterization is robust.
Authors: Section 4 of the manuscript already details the model list, random and persona prompting protocols, number of samples generated per video, and the train/test split procedure. We will revise the abstract to include a concise reference to the benchmarking setup. Statistical significance tests and error bars will be added to the results tables in the revision. revision: yes
Circularity Check
No circularity; empirical dataset and benchmark paper
full rationale
The paper constructs a video dataset by prompting 203 performers with 40 emojis, transferring motions to synthetic faces, and collecting annotations from 902 raters to produce 2,111 videos with label distributions. It then defines two tasks (dominant and distributional expression recognition) and reports direct empirical model accuracies (e.g., 32.5% Top-1) against those human labels. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described methodology. All reported results are external measurements against independently collected human data, making the work self-contained with no load-bearing reductions to its own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Participants can reliably produce distinct facial expressions corresponding to given emoji prompts.
- domain assumption Multiple independent annotators provide valid and diverse labels reflecting perceptual differences.
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
arXiv preprint arXiv:1906.08172 , year=
Mediapipe: A framework for building perception pipelines , author=. arXiv preprint arXiv:1906.08172 , year=
Pith/arXiv arXiv 1906
-
[9]
arXiv preprint arXiv:2407.03168 , year=
Liveportrait: Efficient portrait animation with stitching and retargeting control , author=. arXiv preprint arXiv:2407.03168 , year=
-
[10]
2018 13th IEEE international conference on automatic face & gesture recognition (FG 2018) , pages=
Vggface2: A dataset for recognising faces across pose and age , author=. 2018 13th IEEE international conference on automatic face & gesture recognition (FG 2018) , pages=. 2018 , organization=
2018
-
[11]
Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
Emostyle: One-shot facial expression editing using continuous emotion parameters , author=. Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages=
-
[12]
Cowen, Alan S. and Brooks, Jeffrey A. and Prasad, Gautam and Tanaka, Misato and Kamitani, Yukiyasu and Kirilyuk, Vladimir and Somandepalli, Krishna and Jou, Brendan and Schroff, Florian and Adam, Hartwig and Sauter, Disa and Fang, Xia and Manokara, Kunalan and Tzirakis, Panagiotis and Oh, Moses and Keltner, Dacher , TITLE=. Frontiers in Psychology , VOLUM...
-
[13]
Proceedings of the IEEE conference on computer vision and pattern recognition workshops , pages=
Emotic: Emotions in context dataset , author=. Proceedings of the IEEE conference on computer vision and pattern recognition workshops , pages=
-
[14]
Behavior research methods , volume=
The Chicago face database: A free stimulus set of faces and norming data , author=. Behavior research methods , volume=. 2015 , publisher=
2015
-
[15]
ACM Transactions on Information Systems (TOIS) , volume=
Cumulated gain-based evaluation of IR techniques , author=. ACM Transactions on Information Systems (TOIS) , volume=. 2002 , publisher=
2002
-
[16]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[17]
arXiv preprint arXiv:2509.17765 , year=
Qwen3-omni technical report , author=. arXiv preprint arXiv:2509.17765 , year=
-
[18]
arXiv preprint arXiv:2504.10479 , year=
Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models , author=. arXiv preprint arXiv:2504.10479 , year=
-
[19]
2025 , eprint=
LLaVA-Video: Video Instruction Tuning With Synthetic Data , author=. 2025 , eprint=
2025
-
[20]
2004 , publisher=
Interpersonal diagnosis of personality: A functional theory and methodology for personality evaluation , author=. 2004 , publisher=
2004
-
[21]
Nature Reviews Psychology , volume=
Top-down influences on the perception of emotional stimuli , author=. Nature Reviews Psychology , volume=. 2025 , publisher=
2025
-
[22]
Psychological science , volume=
Deciphering the enigmatic face: The importance of facial dynamics in interpreting subtle facial expressions , author=. Psychological science , volume=. 2005 , publisher=
2005
-
[23]
, author=
What the face displays: Mapping 28 emotions conveyed by naturalistic expression. , author=. American Psychologist , volume=. 2020 , publisher=
2020
-
[24]
arXiv preprint arXiv:1811.07770 , year=
Aff-wild2: Extending the aff-wild database for affect recognition , author=. arXiv preprint arXiv:1811.07770 , year=
-
[25]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Veatic: Video-based emotion and affect tracking in context dataset , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[26]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Context-aware emotion recognition networks , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[27]
IEEE multimedia , volume=
Collecting large, richly annotated facial-expression databases from movies , author=. IEEE multimedia , volume=. 2012 , publisher=
2012
-
[28]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Meld: A multimodal multi-party dataset for emotion recognition in conversations , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[29]
Psychological science in the public interest , volume=
Emotional expressions reconsidered: Challenges to inferring emotion from human facial movements , author=. Psychological science in the public interest , volume=. 2019 , publisher=
2019
-
[30]
IEEE transactions on affective computing , volume=
Affectnet: A database for facial expression, valence, and arousal computing in the wild , author=. IEEE transactions on affective computing , volume=. 2017 , publisher=
2017
-
[31]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[32]
Information Fusion , volume=
Gpt-4v with emotion: A zero-shot benchmark for generalized emotion recognition , author=. Information Fusion , volume=. 2024 , publisher=
2024
-
[33]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Evaluating vision-language models for emotion recognition , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
2025
-
[34]
Advances in Neural Information Processing Systems , volume=
Emotion-llama: Multimodal emotion recognition and reasoning with instruction tuning , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Emobench: Evaluating the emotional intelligence of large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[36]
arXiv preprint arXiv:2506.11162 , year=
VIBE: Can a VLM Read the Room? , author=. arXiv preprint arXiv:2506.11162 , year=
-
[37]
VIBE : Can a VLM Read the Room?
Chakraborty, Tania and Caplan, Eylon and Goldwasser, Dan. VIBE : Can a VLM Read the Room?. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.1252
-
[38]
arXiv preprint arXiv:2508.09210 , year=
Mme-emotion: A holistic evaluation benchmark for emotional intelligence in multimodal large language models , author=. arXiv preprint arXiv:2508.09210 , year=
-
[39]
Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH) , pages=
Personas with attitudes: Controlling llms for diverse data annotation , author=. Proceedings of the The 9th Workshop on Online Abuse and Harms (WOAH) , pages=
-
[40]
arXiv preprint arXiv:2507.16076 , year=
The prompt makes the person (a): A systematic evaluation of sociodemographic persona prompting for large language models , author=. arXiv preprint arXiv:2507.16076 , year=
-
[41]
Journal of Artificial Intelligence Research , volume=
Learning from disagreement: A survey , author=. Journal of Artificial Intelligence Research , volume=
-
[42]
Proceedings of the 2022 conference on empirical methods in natural language processing , pages=
The “problem” of human label variation: On ground truth in data, modeling and evaluation , author=. Proceedings of the 2022 conference on empirical methods in natural language processing , pages=
2022
-
[43]
2021 , eprint=
Dealing with Disagreements: Looking Beyond the Majority Vote in Subjective Annotations , author=. 2021 , eprint=
2021
-
[44]
IEEE Transactions on Affective Computing , volume=
A wide evaluation of ChatGPT on affective computing tasks , author=. IEEE Transactions on Affective Computing , volume=. 2024 , publisher=
2024
-
[45]
2024 12th International Conference on Affective Computing and Intelligent Interaction (ACII) , pages=
EmojiHeroVR: a study on facial expression recognition under partial occlusion from head-mounted displays , author=. 2024 12th International Conference on Affective Computing and Intelligent Interaction (ACII) , pages=. 2024 , organization=
2024
-
[46]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Analyzing and improving the image quality of stylegan , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[47]
Gazi University Journal of Science , volume =
Boosted LightFace: A Hybrid DNN and GBM Model for Boosted Facial Recognition , author =. Gazi University Journal of Science , volume =. 2026 , doi =
2026
-
[48]
2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
Contextual emotion recognition using large vision language models , author=. 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2024 , organization=
2024
-
[49]
Journal of Experimental Social Psychology , volume=
Cultural differences in perceiving transitions in emotional facial expressions: Easterners show greater contrast effects than westerners , author=. Journal of Experimental Social Psychology , volume=. 2021 , publisher=
2021
-
[50]
Proceedings of the National Academy of Sciences , volume=
Facial expressions of emotion are not culturally universal , author=. Proceedings of the National Academy of Sciences , volume=. 2012 , publisher=
2012
-
[51]
, author=
Emojis as social information in digital communication. , author=. Emotion , volume=. 2022 , publisher=
2022
-
[52]
, author=
Essentials of consensual qualitative research. , author=. 2021 , publisher=
2021
-
[53]
Philosophical Transactions of the Royal Society B: Biological Sciences , volume=
Personality influences the neural responses to viewing facial expressions of emotion , author=. Philosophical Transactions of the Royal Society B: Biological Sciences , volume=. 2011 , publisher=
2011
-
[54]
Proceedings of the National Academy of Sciences , volume=
Genetic algorithms reveal profound individual differences in emotion recognition , author=. Proceedings of the National Academy of Sciences , volume=. 2022 , publisher=
2022
-
[55]
IEEE Transactions on Knowledge and Data Engineering , volume=
Label distribution learning , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2016 , publisher=
2016
-
[56]
Proceedings of the 23rd ACM international conference on Multimedia , pages=
Emotion distribution recognition from facial expressions , author=. Proceedings of the 23rd ACM international conference on Multimedia , pages=
-
[57]
Proceedings of the 28th ACM international conference on multimedia , pages=
Dfew: A large-scale database for recognizing dynamic facial expressions in the wild , author=. Proceedings of the 28th ACM international conference on multimedia , pages=
-
[58]
IEEE Transactions on Affective Computing , year=
Affectnet+: A database for enhancing facial expression recognition with soft-labels , author=. IEEE Transactions on Affective Computing , year=
-
[59]
Proceedings of third international conference on automatic face and gesture recognition , pages=
The Japanese female facial expression (JAFFE) database , author=. Proceedings of third international conference on automatic face and gesture recognition , pages=
-
[60]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[61]
2025 , eprint=
Qwen2.5-Omni Technical Report , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.