Confidence-Aware Tool Orchestration for Robust Video Understanding
Pith reviewed 2026-06-26 05:20 UTC · model grok-4.3
The pith
Robust-TO integrates per-frame reliability scores into every stage of tool orchestration so video reasoning models lose far less accuracy when inputs suffer blur, glare, or occlusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
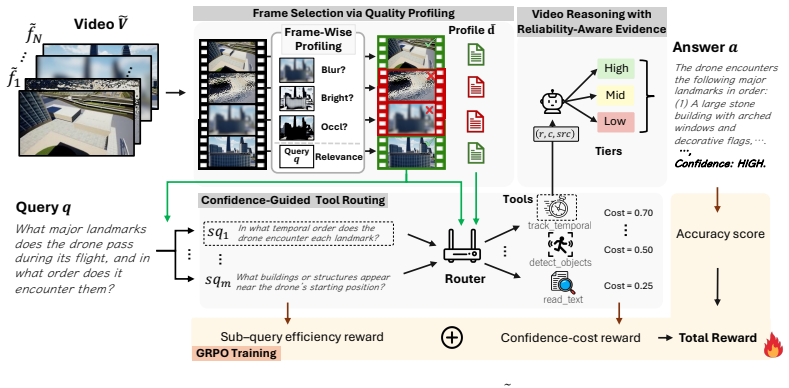
By organizing perception tools under a unified evidence interface and letting calibrated reliability scores guide both evidence weighting in three-tier synthesis and the optimization reward, Robust-TO achieves higher accuracy on clean video reasoning benchmarks and exhibits the smallest drop when the same inputs are subjected to five realistic corruption types.
What carries the argument
The reliability-relevance score that selects trustworthy frames together with the three-tier synthesis that weights tool evidence by its returned reliability score.
If this is right
- Video reasoning agents can maintain accuracy across clean and corrupted inputs by routing sub-queries only to frames judged trustworthy.
- Heterogeneous tools contribute comparable evidence because each returns its output in the shared format of prediction, temporal grounding, and reliability score.
- A single reward combining correctness, evidence reliability, and efficiency produces joint optimization of all three objectives.
- The same framework yields higher average accuracy than both open-source baselines and a closed frontier model on the eight-task benchmarks.
Where Pith is reading between the lines
- The same evidence interface could be reused for other modalities such as audio or 3-D sensor streams if tools are adapted to return comparable reliability scores.
- If the reliability scores prove stable across domains, the approach may reduce the amount of human verification needed for deployed video agents.
- The three-tier synthesis offers a lightweight way to incorporate uncertainty that could be combined with existing calibration methods without changing model architecture.
Load-bearing premise
The reliability-relevance score correctly identifies trustworthy frames and the tools return reliability scores that are well calibrated enough to weight evidence without adding new biases.
What would settle it
An ablation that removes the reliability-relevance score or the calibrated reliability weighting and measures whether accuracy on corrupted inputs then falls to the level of the strongest baseline would falsify the claim.
Figures


read the original abstract
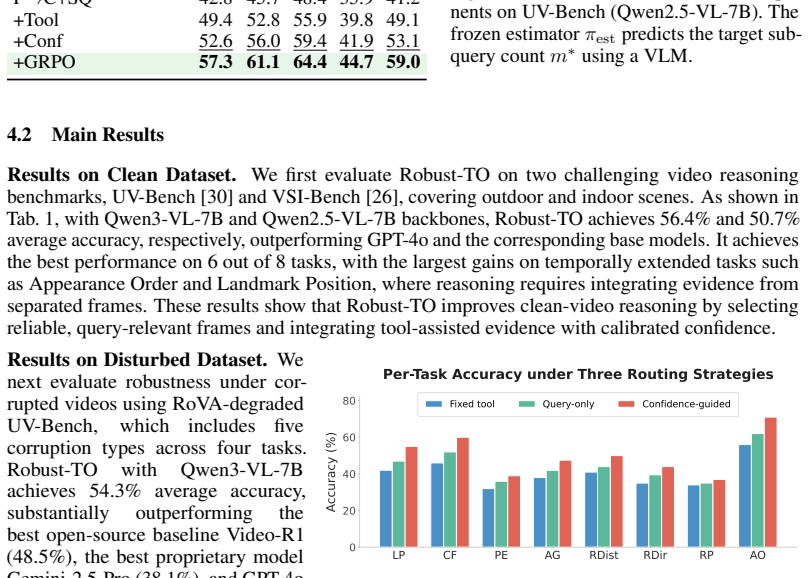
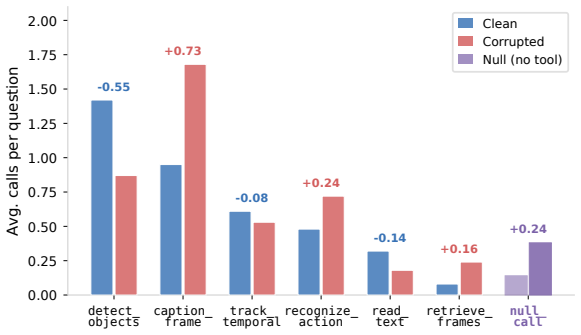
Video reasoning language models implicitly assume that every input frame is equally reliable. This leads to what we term the Blind Trust Problem: under realistic perturbations such as motion blur, glare, or occlusion, frontier video reasoning models can suffer 15-30%p accuracy drops on real-world embodied benchmarks, while remaining unaware that their visual evidence has been degraded. To address this challenge, we propose Robust-TO, an agentic video understanding framework that explicitly integrates per-frame trustworthiness into every stage of reasoning. Robust-TO organizes heterogeneous visual perception tools under a unified evidence interface. Each tool receives a sub-query derived from the original question and a set of trustworthy frames selected by the reliability-relevance score. It returns evidence in a shared format: a concrete prediction (e.g., a bounding box, motion trajectory, recognized text, or action label), temporal grounding, and a calibrated reliability score. During reasoning, these calibrated scores guide evidence weighting in a three-tier synthesis process (high/medium/low) and define a confidence-cost GRPO reward that jointly optimizes correctness, evidence reliability, and efficiency. On two video reasoning benchmarks spanning eight tasks, Robust-TO achieves 56.4% average accuracy on clean inputs, surpassing the strongest open-source baseline by 10.6%p and outperforming Gemini-2.5-Pro (46.2%). Under five realistic corruption types, Robust-TO maintains 54.3% average accuracy, 5.8%p above the strongest open-source baseline, while exhibiting the smallest clean-to-corrupted accuracy drop among all compared methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Robust-TO addresses the Blind Trust Problem in video reasoning models by integrating per-frame trustworthiness via a reliability-relevance score for frame selection, a three-tier (high/medium/low) synthesis process for evidence weighting, and a confidence-cost GRPO reward that jointly optimizes correctness, reliability, and efficiency. It reports 56.4% average accuracy on clean inputs (surpassing the strongest open-source baseline by 10.6%p and Gemini-2.5-Pro at 46.2%) and 54.3% under five realistic corruption types (5.8%p above the strongest baseline, with the smallest clean-to-corrupted drop) across two benchmarks spanning eight tasks.
Significance. If the methodological components can be shown to produce the claimed gains without circularity or uncalibrated scores, the work would be significant for improving robustness in video reasoning under real-world perturbations such as motion blur, glare, and occlusion. Explicit trustworthiness integration into tool orchestration and reward design offers a concrete path toward more reliable agentic systems in embodied AI.
major comments (2)
- [Abstract] Abstract: The performance numbers (56.4% clean, 54.3% corrupted) are stated without any description of how the reliability-relevance score is computed, how the three-tier synthesis boundaries or weighting are implemented, what terms the confidence-cost GRPO objective contains, or any ablation studies. This prevents verification that the gains arise from the proposed integration rather than other factors and is load-bearing for the central claim.
- [Abstract] Abstract: The claim that calibrated reliability scores guide evidence weighting and define the GRPO reward lacks any derivation or definition, leaving open the possibility that the reward reduces to a fitted quantity by construction (as flagged by the circularity concern) and that the reliability-relevance score may introduce new biases rather than accurately identifying trustworthy frames.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments on the abstract below, clarifying that methodological details reside in the main text while offering to strengthen the abstract for self-containment.
read point-by-point responses
-
Referee: [Abstract] Abstract: The performance numbers (56.4% clean, 54.3% corrupted) are stated without any description of how the reliability-relevance score is computed, how the three-tier synthesis boundaries or weighting are implemented, what terms the confidence-cost GRPO objective contains, or any ablation studies. This prevents verification that the gains arise from the proposed integration rather than other factors and is load-bearing for the central claim.
Authors: We agree the abstract is a high-level summary and omits implementation specifics. The reliability-relevance score computation, three-tier synthesis boundaries and weighting, confidence-cost GRPO objective terms, and supporting ablation studies are all provided in the main manuscript body. These sections show the performance gains are attributable to the proposed components. To address the verification concern, we will revise the abstract to incorporate brief descriptions of the key elements. revision: yes
-
Referee: [Abstract] Abstract: The claim that calibrated reliability scores guide evidence weighting and define the GRPO reward lacks any derivation or definition, leaving open the possibility that the reward reduces to a fitted quantity by construction (as flagged by the circularity concern) and that the reliability-relevance score may introduce new biases rather than accurately identifying trustworthy frames.
Authors: The abstract summarizes the approach; the full derivation, definitions, and calibration process appear in the main text. The reliability-relevance score is computed from independent per-frame estimates and calibrated on held-out data, separate from task performance. The GRPO reward treats the score as an explicit additive term distinct from the correctness signal. Ablations isolate the contribution of the reliability component and show it is not circular by construction. Experiments under corruption further confirm the score identifies trustworthy frames without introducing the claimed biases. We therefore disagree with the circularity interpretation but can add a clarifying clause to the abstract if requested. revision: no
Circularity Check
No significant circularity identified
full rationale
The provided abstract and description outline the Robust-TO framework, including the reliability-relevance score, three-tier synthesis, and confidence-cost GRPO reward, but contain no equations, parameter-fitting procedures, or derivation chains. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations are present. The reported accuracy gains are framed as empirical outcomes on benchmarks, with no visible steps that reduce by construction to the method's own inputs. This qualifies as a standard empirical paper without detectable circularity in the given text.
Axiom & Free-Parameter Ledger
free parameters (2)
- reliability-relevance score threshold
- high/medium/low synthesis boundaries
axioms (1)
- domain assumption Specialized perception tools can return calibrated reliability scores alongside predictions
invented entities (2)
-
reliability-relevance score
no independent evidence
-
confidence-cost GRPO reward
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mvtamperbench: Evaluating robustness of vision-language models
Amit Agarwal, Srikant Panda, Angeline Charles, Hitesh Laxmichand Patel, Bhargava Kumar, Priyaranjan Pattnayak, Taki Hasan Rafi, Tejaswini Kumar, Hansa Meghwani, Karan Gupta, et al. Mvtamperbench: Evaluating robustness of vision-language models. InFindings of the Association for Computational Linguistics: ACL 2025, pages 18804–18828, 2025
2025
-
[2]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report. a...
Pith/arXiv arXiv 2025
-
[4]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
2024
-
[5]
Videoagent: A memory-augmented multimodal agent for video understanding
Yue Fan, Xiaojian Ma, Rujie Wu, Yuntao Du, Jiaqi Li, Zhi Gao, and Qing Li. Videoagent: A memory-augmented multimodal agent for video understanding. InEuropean Conference on Computer Vision, pages 75–92. Springer, 2024
2024
-
[6]
Video-r1: Reinforcing video reasoning in mllms.Advances in Neural Information Processing Systems, 38:99114–99137, 2026
Kaituo Feng, Kaixiong Gong, Bohao Li, Zonghao Guo, Yibing Wang, Tianshuo Peng, Junfei Wu, Xiaoying Zhang, Benyou Wang, and Xiangyu Yue. Video-r1: Reinforcing video reasoning in mllms.Advances in Neural Information Processing Systems, 38:99114–99137, 2026
2026
-
[7]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025
2025
-
[8]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[9]
Are video reasoning models ready to go outside?arXiv preprint arXiv:2603.10652, 2026
Yangfan He, Changgyu Boo, and Jaehong Yoon. Are video reasoning models ready to go outside?arXiv preprint arXiv:2603.10652, 2026. 11
Pith/arXiv arXiv 2026
-
[10]
Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Yanwei Li, Ziwei Liu, and Chunyuan Li. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326, 2024
Pith/arXiv arXiv 2024
-
[11]
R-bench: Are your large multimodal model robust to real-world corruptions?IEEE Journal of Selected Topics in Signal Processing, 2025
Chunyi Li, Jianbo Zhang, Zicheng Zhang, Haoning Wu, Yuan Tian, Wei Sun, Guo Lu, Xiongkuo Min, Xiaohong Liu, Weisi Lin, et al. R-bench: Are your large multimodal model robust to real-world corruptions?IEEE Journal of Selected Topics in Signal Processing, 2025
2025
-
[12]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024
2024
-
[13]
Xinhao Li, Ziang Yan, Desen Meng, Lu Dong, Xiangyu Zeng, Yinan He, Yali Wang, Yu Qiao, Yi Wang, and Limin Wang. Videochat-r1: Enhancing spatio-temporal perception via reinforce- ment fine-tuning.arXiv preprint arXiv:2504.06958, 2025
Pith/arXiv arXiv 2025
-
[14]
Video-llava: Learning united visual representation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. InProceedings of the 2024 conference on empirical methods in natural language processing, pages 5971–5984, 2024
2024
-
[15]
Meng Liu, Mingda Wang, Xueyang Hu, Shengbo Wang, Yunchao Yin, Xiaolin Hu, Bing Zhao, and Cewu Lu. Understanding long videos via llm-powered entity relation graphs.arXiv preprint arXiv:2501.15953, 2025
arXiv 2025
-
[16]
Egoschema: A diagnostic benchmark for very long-form video language understanding.Advances in Neural Information Processing Systems, 36:46212–46244, 2023
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding.Advances in Neural Information Processing Systems, 36:46212–46244, 2023
2023
-
[17]
Deepvideo-r1: Video rein- forcement fine-tuning via difficulty-aware regressive grpo.Advances in Neural Information Processing Systems, 38:138605–138632, 2026
Jinyoung Park, Jeehye Na, Jinyoung Kim, and Hyunwoo J Kim. Deepvideo-r1: Video rein- forcement fine-tuning via difficulty-aware regressive grpo.Advances in Neural Information Processing Systems, 38:138605–138632, 2026
2026
-
[18]
Toolllm: Facilitating large language models to master 16000+ real-world apis
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. InInternational Conference on Learning Representations, volume 2024, pages 9695–9717, 2024
2024
-
[19]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[20]
Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools.Advances in neural information processing systems, 36:68539– 68551, 2023
2023
-
[21]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[22]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[23]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
Pith/arXiv arXiv 2024
-
[24]
Videoagent: Long-form video understanding with large language model as agent
Xiaohan Wang, Yuhui Zhang, Orr Zohar, and Serena Yeung-Levy. Videoagent: Long-form video understanding with large language model as agent. InEuropean Conference on Computer Vision, pages 58–76. Springer, 2024. 12
2024
-
[25]
Next-qa: Next phase of question- answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question- answering to explaining temporal actions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9777–9786, 2021
2021
-
[26]
Thinking in space: How multimodal large language models see, remember, and recall spaces
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025
2025
-
[27]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023
2023
-
[28]
Jiawei Zhang, Tianyu Pang, Chao Du, Yi Ren, Bo Li, and Min Lin. Benchmarking large multimodal models against common corruptions.arXiv preprint arXiv:2401.11943, 2024
arXiv 2024
-
[29]
Multitrust: A comprehensive benchmark towards trustworthy multimodal large language models.Advances in Neural Information Processing Systems, 37:49279–49383, 2024
Yichi Zhang, Yao Huang, Yitong Sun, Chang Liu, Zhe Zhao, Zhengwei Fang, Yifan Wang, Huanran Chen, Xiao Yang, Xingxing Wei, et al. Multitrust: A comprehensive benchmark towards trustworthy multimodal large language models.Advances in Neural Information Processing Systems, 37:49279–49383, 2024
2024
-
[30]
what the pedestrian does after the car stops
Baining Zhao, Jianjie Fang, Zichao Dai, Ziyou Wang, Jirong Zha, Weichen Zhang, Chen Gao, Yue Wang, Jinqiang Cui, Xinlei Chen, et al. Urbanvideo-bench: Benchmarking vision-language models on embodied intelligence with video data in urban spaces. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers...
2025
-
[31]
Identify the distinct perceptual demands implied by the question (e.g., object local- ization, action recognition, attribute comparison, text reading)
-
[32]
For each demand, formulate exactly one atomic sub-query targeting a single visual primitive
-
[33]
Assign a semantic type to each sub-query: one of [spatial, temporal, attribute, action, text]
-
[34]
sub_query
Minimize the total number of sub-queries — each must be strictly necessary. [Input] • Video context:{video_description} • Disturbance profile of selected frames: blur={avg_blur}, brightness={avg_bright}, occlusion={avg_occl} • Question:{original_query} [Output Format] Output a JSON list of atomic sub-queries. Only output the JSON — no explanations, no jus...
-
[35]
Group evidence into three reliability tiers: •HIGH: confidence≥0.7and disturbance<0.3 •MEDIUM: all other evidence •LOW: confidence<0.3or disturbance≥0.7
-
[36]
Build your answer primarily from HIGH-tier evidence
-
[37]
Use MEDIUM-tier evidence only if it is consistent with HIGH-tier conclusions; discard it if contradictory
-
[38]
Use LOW-tier evidence only when no HIGH-tier evidence exists, and explicitly note the uncertainty
-
[39]
If all evidence is LOW-tier, state that the answer is uncertain. [Input] • Question:{original_query} • Sub-queries and collected evidence: For each sub-query: –Sub-query:{sq_text} –Tool:{tool_name}, Result:{result}, Confidence:{c_j} –Source frames:{frame_ids}, Disturbance:{d_scores} [Output Format] Provide your step-by-step reasoning inside <think> tags, ...
-
[40]
Count how many distinct objects, actions, or spatial relations the question asks about
-
[41]
Determine whether temporal reasoning across multiple moments is needed (adds sub-queries)
-
[42]
Assess whether the question can be answered from a single frame or requires multi-frame evidence
-
[43]
Each sub-query should be strictly necessary — do not pad the count. [Input] • Question:{original_query} • Answer choices:{choices_if_multiple_choice} [Output Format] Output a single integer representing the estimated number of atomic sub-queries needed. No explanations, no extra text. <integer> 30
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.