When and Which Sensor to Observe? Timely Tracking of a Joint Markov Source
Pith reviewed 2026-06-30 03:11 UTC · model grok-4.3
The pith
A belief state capturing the joint distribution of age and process state turns sensor selection into a solvable belief-MDP whose model predictive control policies balance age of incorrect information against sampling costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The optimization of pull decisions reduces to a belief-MDP whose state is the joint distribution of the age of incorrect information and the current value of the observed Markov process; two model predictive control algorithms, one without terminal costs and one augmented by reinforcement learning, applied to this belief-MDP produce policies that minimize the long-run weighted sum of average age of incorrect information and sampling costs under erasure channels with one-slot delay.
What carries the argument
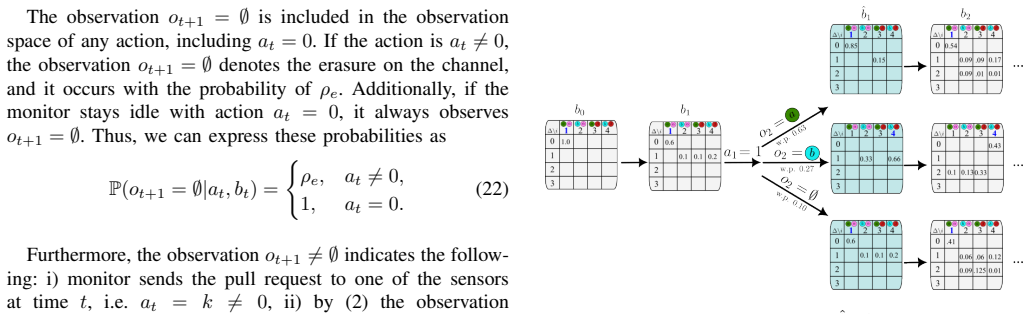
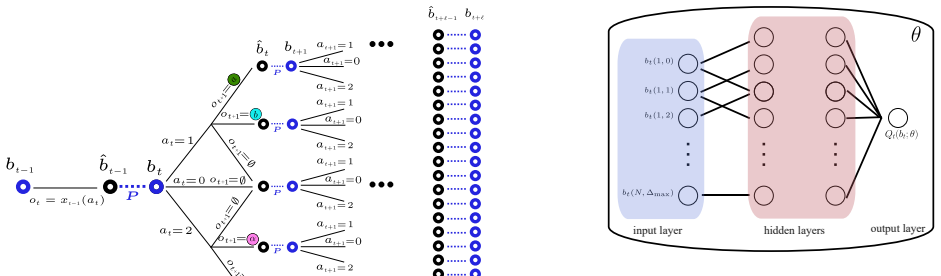
The belief, the joint probability distribution over age and current state, computed recursively from pull history and received observations; it serves as the sufficient statistic that converts the partially observed problem into a fully observed belief-MDP.
If this is right
- The monitor can compute pull decisions online using only the current belief without storing the full history.
- MPC without terminal costs and RL-MPC offer different computation-performance trade-offs that can be selected according to available processing power.
- The same belief construction applies whenever sensors have heterogeneous costs and observations suffer fixed-delay erasures.
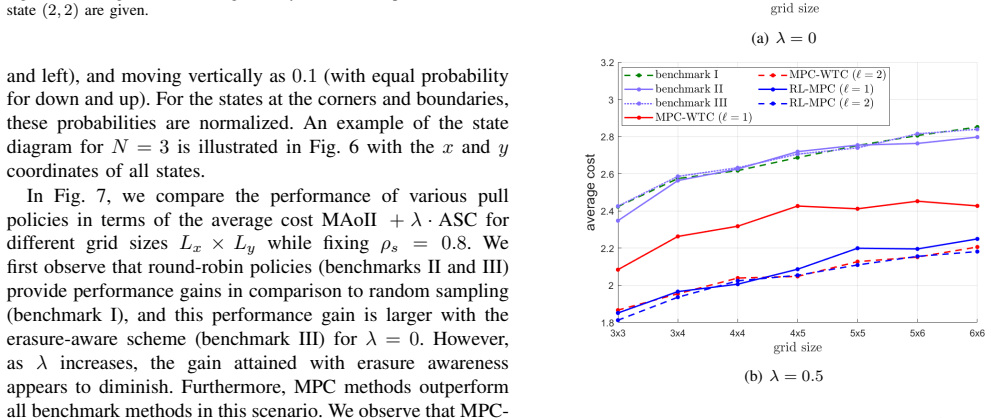
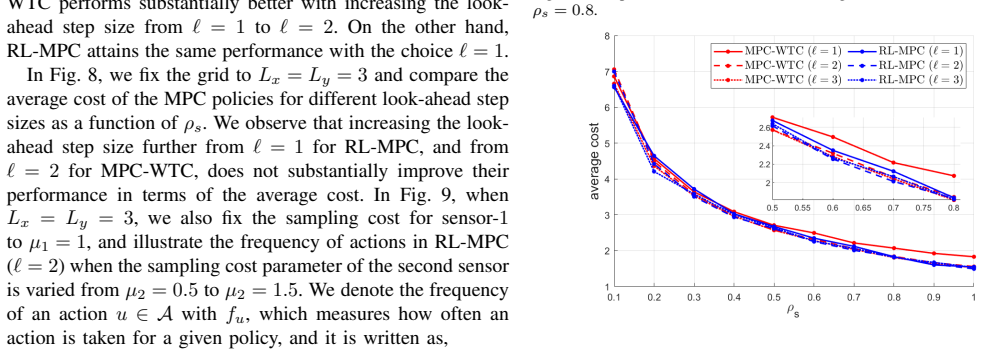
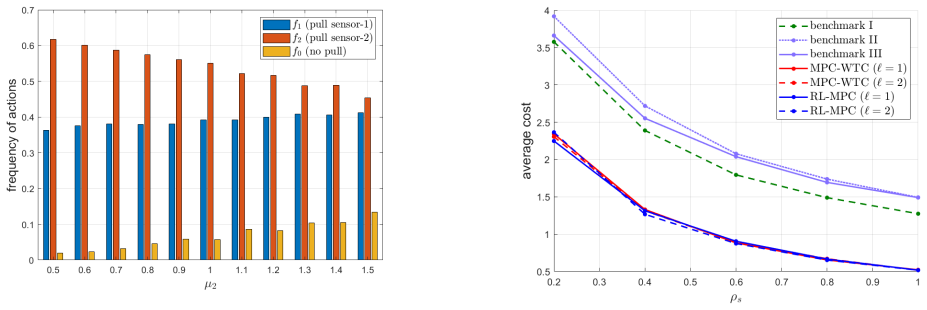
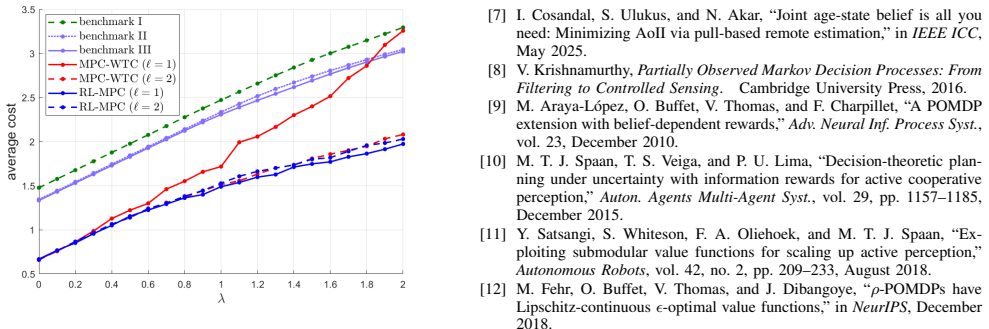
- Numerical examples confirm that the policies achieve lower weighted cost than naive alternatives for the tested Markov parameters.
Where Pith is reading between the lines
- The approach could be tested on continuous-time jump processes by discretizing time and checking whether the discrete belief still suffices.
- Similar belief updates might apply to networked control loops where the plant itself is Markov and actuators also have costs.
- One could replace the MPC horizon with a learned value function and measure whether the resulting policy remains stable under model mismatch.
Load-bearing premise
The underlying source is a discrete-time joint Markov process and every channel adds only a fixed one-slot delay with possible erasures, so that the belief can be updated from partial observations alone.
What would settle it
In the same numerical setups used by the paper, replace the MPC policies with a myopic policy that always pulls the cheapest sensor when the current belief entropy exceeds a fixed threshold; if the resulting weighted cost is lower, the claim that the belief-MDP plus MPC is needed would be contradicted.
Figures



read the original abstract
We investigate the problem of remote estimation (at a monitor) of a discrete-time joint Markov process with individual components which can be observed with dedicated sensors. At a given time slot, the monitor has the option of staying idle or sending a pull request to one of the sensors to obtain a partial state value, while the sensors are assumed to have heterogeneous sampling costs. Our goal is to develop a monitor pull policy, i.e., determining when and towards which sensor to send a pull request, in order to minimize a weighted sum of average age of incorrect information (AoII), or in short age, and sampling costs. As the communication model, we assume an erasure channel with a fixed one-slot delay from each sensor to the monitor. In this setting, the monitor does not perfectly know either the state of the process or the age, at any given time. We first obtain a sufficient statistic, namely belief, representing the joint distribution of the age and the current state of the observed process, by using the history of all pull requests and observations. Then, we formulate the optimization problem as a continuous state-space Markov decision process (MDP), namely belief-MDP, for the solution of which we propose two model predictive control (MPC) methods, namely MPC without terminal costs (MPC-WTC), and reinforcement learning MPC (RL-MPC). The effectiveness of the proposed methods is validated by numerical examples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies remote estimation of a discrete-time joint Markov process observed via dedicated sensors with heterogeneous costs over erasure channels with one-slot delay. The monitor decides at each slot whether to stay idle or pull one sensor to minimize a weighted sum of average AoII (age of incorrect information) and sampling costs. The authors derive a belief state as a sufficient statistic for the joint age-state distribution from the history of pulls and delayed/erased observations, reduce the problem to a continuous-state belief-MDP, and propose two MPC approximations (MPC-WTC and RL-MPC) whose performance is illustrated numerically.
Significance. If the belief derivation is correct and the MPC policies are effective, the work supplies a principled POMDP reduction and practical solvers for multi-sensor AoII minimization with costs, extending prior single-process or perfect-observation settings. The standard belief-MDP construction and reproducible numerical examples (if code were supplied) would be strengths.
minor comments (3)
- Abstract and §1 should explicitly state the dimension of the joint state space and the number of sensors, as these determine the size of the belief simplex and the computational feasibility of the MPC methods.
- The description of the belief update (mentioned in the abstract) would benefit from an explicit recursive formula or pseudocode in the main text, even if the derivation is standard, to allow readers to verify the joint age-state tracking under erasures and delay.
- Numerical examples section should report the exact parameter values (transition matrices, erasure probabilities, cost weights, horizon lengths) used for the two MPC variants so that the claimed effectiveness can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the careful summary of our work and the recommendation of minor revision. No specific major comments were provided in the report, so we have no individual points to address point-by-point. We are happy to make any minor editorial changes requested by the editor.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central steps derive a belief as the joint distribution over (age, state) from the observable history of pulls and delayed/erased observations, then reduce the problem to a belief-MDP and approximate its solution with MPC variants. This is the standard sufficient-statistic reduction for a POMDP with known transition and channel statistics; the belief is constructed directly from the model without being defined in terms of the objective value or any fitted parameter that is later called a prediction. No load-bearing self-citation, uniqueness theorem, or ansatz is invoked to close the argument, and the numerical validation is external to the derivation itself.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The underlying process is a discrete-time joint Markov process.
- domain assumption Each sensor-to-monitor link is an erasure channel with fixed one-slot delay.
Reference graph
Works this paper leans on
-
[1]
The age of incorrect in- formation: An enabler of semantics-empowered communication,
A. Maatouk, M. Assaad, and A. Ephremides, “The age of incorrect in- formation: An enabler of semantics-empowered communication,”IEEE Trans. Wireless Comm., vol. 22, no. 4, pp. 2621–2635, October 2022
2022
-
[2]
Semantics-empowered communication: A tutorial-cum-survey,
Z. Lu, R. Li, K. Lu, X. Chen, E. Hossain, Z. Zhao, and H. Zhang, “Semantics-empowered communication: A tutorial-cum-survey,”IEEE Commun. Surv. Tutor., November 2023
2023
-
[3]
Timely tracking of infection status of individuals in a population,
M. Bastopcu and S. Ulukus, “Timely tracking of infection status of individuals in a population,” inIEEE Infocom, May 2021
2021
-
[4]
Timely multi-goal transmissions with an intermittently failing sensor,
I. Cosandal and S. Ulukus, “Timely multi-goal transmissions with an intermittently failing sensor,” inIEEE MILCOM, October 2023
2023
-
[5]
Who should Google Scholar update more often?
M. Bastopcu and S. Ulukus, “Who should Google Scholar update more often?” inIEEE Infocom, July 2020
2020
-
[6]
Age-of- information vs. value-of-information scheduling for cellular networked control systems,
O. Ayan, M. Vilgelm, M. Kl ¨ugel, S. Hirche, and W. Kellerer, “Age-of- information vs. value-of-information scheduling for cellular networked control systems,” inACM/IEEE ICCPS, April 2019
2019
-
[7]
Joint age-state belief is all you need: Minimizing AoII via pull-based remote estimation,
I. Cosandal, S. Ulukus, and N. Akar, “Joint age-state belief is all you need: Minimizing AoII via pull-based remote estimation,” inIEEE ICC, May 2025
2025
-
[8]
Krishnamurthy,Partially Observed Markov Decision Processes: From Filtering to Controlled Sensing
V . Krishnamurthy,Partially Observed Markov Decision Processes: From Filtering to Controlled Sensing. Cambridge University Press, 2016
2016
-
[9]
A POMDP extension with belief-dependent rewards,
M. Araya-L ´opez, O. Buffet, V . Thomas, and F. Charpillet, “A POMDP extension with belief-dependent rewards,”Adv. Neural Inf. Process Syst., vol. 23, December 2010
2010
-
[10]
Decision-theoretic plan- ning under uncertainty with information rewards for active cooperative perception,
M. T. J. Spaan, T. S. Veiga, and P. U. Lima, “Decision-theoretic plan- ning under uncertainty with information rewards for active cooperative perception,”Auton. Agents Multi-Agent Syst., vol. 29, pp. 1157–1185, December 2015
2015
-
[11]
Ex- ploiting submodular value functions for scaling up active perception,
Y . Satsangi, S. Whiteson, F. A. Oliehoek, and M. T. J. Spaan, “Ex- ploiting submodular value functions for scaling up active perception,” Autonomous Robots, vol. 42, no. 2, pp. 209–233, August 2018
2018
-
[12]
ρ-POMDPs have Lipschitz-continuousϵ-optimal value functions,
M. Fehr, O. Buffet, V . Thomas, and J. Dibangoye, “ρ-POMDPs have Lipschitz-continuousϵ-optimal value functions,” inNeurIPS, December 2018
2018
-
[13]
Potential-based reward shaping for finite horizon online POMDP planning,
A. Eck, L. Soh, S. Devlin, and D. Kudenko, “Potential-based reward shaping for finite horizon online POMDP planning,”Agents Multi-Agent Syst., vol. 30, no. 3, pp. 403–445, May 2016
2016
-
[14]
Reinforcement learning for near- optimal design of zero-delay codes for Markov sources,
L. Cregg, T. Linder, and S. Y ¨uksel, “Reinforcement learning for near- optimal design of zero-delay codes for Markov sources,”IEEE Trans. Inf. Theory, vol. 70, no. 11, pp. 8399–8413, June 2024
2024
-
[15]
Linear program approximations for factored continuous-state Markov decision processes,
M. Hauskrecht and B. Kveton, “Linear program approximations for factored continuous-state Markov decision processes,”Adv. Neural Inf. Process Syst., vol. 16, June 2003
2003
-
[16]
Optimizing age of information in uplink multiuser MIMO networks with partial observations,
J. Liu, Q. Wang, and H. H. Chen, “Optimizing age of information in uplink multiuser MIMO networks with partial observations,” inIEEE WiOpt, August 2023
2023
-
[17]
Optimizing age of information in wireless uplink networks with partial observations,
J. Liu, R. Zhang, A. Gong, and H. Chen, “Optimizing age of information in wireless uplink networks with partial observations,”IEEE Trans. Comm., vol. 71, no. 7, pp. 4105–4118, July 2023
2023
-
[18]
Bertsekas,Dynamic programming and optimal control: Volume I
D. Bertsekas,Dynamic programming and optimal control: Volume I. Athena scientific, 2012
2012
-
[19]
Performance of model predictive control of POMDPs,
M. A. Sehr and R. R. Bitmead, “Performance of model predictive control of POMDPs,” inECC, June 2018
2018
-
[20]
On integrating POMDP and scenario MPC for planning under uncertainty–with applications to highway driving,
C. H. Ulfsj ¨o¨o and D. Axehill, “On integrating POMDP and scenario MPC for planning under uncertainty–with applications to highway driving,” inIEEE IV, June 2022
2022
-
[21]
Reinforcement learning based on MPC/MHE for unmodeled and partially observable dynamics,
H. N. Esfahani, A. B. Kordabad, and S. Gros, “Reinforcement learning based on MPC/MHE for unmodeled and partially observable dynamics,” inACC, May 2021
2021
-
[22]
Stability and feasibility of state constrained MPC without stabilizing terminal constraints,
A. Boccia, L. Gr ¨une, and K. Worthmann, “Stability and feasibility of state constrained MPC without stabilizing terminal constraints,”Systems & Control Letters, vol. 72, pp. 14–21, October 2014
2014
-
[23]
NMPC without terminal constraints,
L. Gr ¨une, “NMPC without terminal constraints,”IFAC Proc. Vol., vol. 45, no. 17, pp. 1–13, September 2012
2012
-
[24]
Reinforcement learning-based model predictive control for discrete-time systems,
M. Lin, Z. Sun, Y . Xia, and J. Zhang, “Reinforcement learning-based model predictive control for discrete-time systems,”IEEE Trans. Neural Netw. Learn. Syst., vol. 35, no. 3, pp. 3312–3324, March 2023
2023
-
[25]
Iteratively extending time horizon reinforcement learning,
D. Ernst, P. Geurts, and L. Wehenkel, “Iteratively extending time horizon reinforcement learning,” inECML, September 2003
2003
-
[26]
Learning-based model predictive control under value iteration with finite approximation errors,
M. Lin, Y . Xia, Z. Sun, and L. Dai, “Learning-based model predictive control under value iteration with finite approximation errors,”Int. J. Robust Nonlinear Control, vol. 34, no. 4, pp. 2946–2971, December 2024
2024
-
[27]
The optimal control of partially ob- servable Markov processes over a finite horizon,
R. D. Smallwood and E. J. Sondik, “The optimal control of partially ob- servable Markov processes over a finite horizon,”Operations Research, vol. 21, no. 5, pp. 1071–1088, September 1973
1973
-
[28]
Partially observable Markov decision processes,
M. T. J. Spaan, “Partially observable Markov decision processes,” in Reinforcement Learning: State-of-the-Art. Springer, 2012, pp. 387– 414
2012
-
[29]
Improving information freshness via multi-sensor parallel status updating,
Z. Chen, T. Yang, N. Pappas, H. H. Yang, Z. Tian, M. Wang, and T. Q. S. Quek, “Improving information freshness via multi-sensor parallel status updating,”IEEE Trans. Commun., July 2024
2024
-
[30]
Age of infor- mation optimization and state error analysis for correlated multi-process multi-sensor systems,
E. Erbayat, A. Maatouk, P. Zou, and S. Subramaniam, “Age of infor- mation optimization and state error analysis for correlated multi-process multi-sensor systems,” inMobiHoc, October 2024
2024
-
[31]
Minimizing age of correlated information for wireless camera networks,
Q. He, G. Dan, and V . Fodor, “Minimizing age of correlated information for wireless camera networks,” inIEEE Infocom, April 2018
2018
-
[32]
Optimizing age of information with correlated sources,
V . Tripathi and E. Modiano, “Optimizing age of information with correlated sources,” inMobiHoc, October 2022
2022
-
[33]
Modeling value of information in remote sensing from correlated sources,
A. Zancanaro, G. Cisotto, and L. Badia, “Modeling value of information in remote sensing from correlated sources,”Computer Communications, vol. 203, pp. 289–297, March 2023
2023
-
[34]
Updating strategies in the internet of things by taking advantage of correlated sources,
J. Hribar, M. Costa, N. Kaminski, and L. A. DaSilva, “Updating strategies in the internet of things by taking advantage of correlated sources,” inIEEE GLOBECOM, December 2017
2017
-
[35]
Optimizing age of information in random access networks with correlated sources,
L. Liang, S. Zhou, B. Tang, and G. Tan, “Optimizing age of information in random access networks with correlated sources,” inIEEE ICICSP, September 2024
2024
-
[36]
Age-of-information oriented scheduling for multichannel IoT systems with correlated sources,
J. Tong, L. Fu, and Z. Han, “Age-of-information oriented scheduling for multichannel IoT systems with correlated sources,”IEEE Trans. Wireless Comm., vol. 21, no. 11, pp. 9775–9790, June 2022
2022
-
[37]
Age analysis of correlated information in multi-source updating systems with MAP arrivals,
M. S. Kumar, A. Dadlani, O. Ardakanian, I. Nikolaidis, and J. J. Harms, “Age analysis of correlated information in multi-source updating systems with MAP arrivals,”IEEE Commun. Lett., July 2024
2024
-
[38]
Joint assignment and scheduling for minimizing age of correlated information,
Q. He, G. D ´an, and V . Fodor, “Joint assignment and scheduling for minimizing age of correlated information,”IEEE/ACM Transactions on Networking, vol. 27, no. 5, pp. 1887–1900, September 2019
1900
-
[39]
2D-AoI: Age-of- information of distributed sensors for spatio-temporal processes,
M. Fidler, F. Gallistl, J. P. Champati, and J. Widmer, “2D-AoI: Age-of- information of distributed sensors for spatio-temporal processes,” 2024, available online at arXiv:2412.12789
-
[40]
Remote Tracking with State-Dependent Sensing in Pull-Based Systems: A POMDP Framework
J. Tian, A. Zakeri, M. Codreanu, and D. Gundleg ˚ard, “Real-time remote tracking with state-dependent detection probability: A POMDP framework,” 2025, available online at arXiv:2509.09837
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Partially observable minimum-age scheduling: The greedy policy,
Y . Shao, Q. Cao, S. C. Liew, and H. Chen, “Partially observable minimum-age scheduling: The greedy policy,”IEEE Trans. Comm., vol. 70, no. 1, pp. 404–418, October 2021
2021
-
[42]
Collaborative optimization of the age of information under partial observability,
A. Tahir, K. Cui, B. Alt, A. Rizk, and H. Koeppl, “Collaborative optimization of the age of information under partial observability,” in IFIP Networking, August 2024
2024
-
[43]
Age-of-information-based scheduling in multiuser uplinks with stochastic arrivals: A POMDP approach,
A. Gong, T. Zhang, H. Chen, and Y . Zhang, “Age-of-information-based scheduling in multiuser uplinks with stochastic arrivals: A POMDP approach,” inIEEE Globecom, December 2020
2020
-
[44]
Uncertainty-of-information schedul- ing: A restless multiarmed bandit framework,
G. Chen, S. C. Liew, and Y . Shao, “Uncertainty-of-information schedul- ing: A restless multiarmed bandit framework,”IEEE Trans. Inf. Theory, vol. 68, no. 9, pp. 6151–6173, August 2022
2022
-
[45]
Au- tonomous maintenance in IoT networks via AoI-driven deep reinforce- ment learning,
G. Stamatakis, N. Pappas, A. Fragkiadakis, and A. Traganitis, “Au- tonomous maintenance in IoT networks via AoI-driven deep reinforce- ment learning,” inIEEE Infocom, May 2021
2021
-
[46]
Optimizing age of information without knowing the age of information,
Z. Zhao and I. Kadota, “Optimizing age of information without knowing the age of information,” 2025, available online at arXiv:2501.06688
-
[47]
Goal-oriented medium access with dis- tributed belief processing,
F. C., A. M., L. B., and P. P., “Goal-oriented medium access with dis- tributed belief processing,” 2024, available online at arXiv:2412.07503
-
[48]
Age of incorrect information-aware data dissemination for distributed multi-agent sys- tems,
G. He, S. Zhang, M. Feng, S. Li, and T. Jiang, “Age of incorrect information-aware data dissemination for distributed multi-agent sys- tems,”IEEE Trans. Wireless Comm., vol. 23, no. 10, pp. 15 705–15 718, July 2024
2024
-
[49]
Age of information minimization using multi-agent UA Vs based on AI- enhanced mean field resource allocation,
Y . Emami, H. Gao, K. Li, L. Almeida, E. Tovar, and Z. Han, “Age of information minimization using multi-agent UA Vs based on AI- enhanced mean field resource allocation,”IEEE Trans. Veh. Technol., April 2024
2024
-
[50]
The age of incorrect information: A new performance metric for status updates,
A. Maatouk, S. Kriouile, M. Assaad, and A. Ephremides, “The age of incorrect information: A new performance metric for status updates,” IEEE/ACM Trans. Netw., vol. 28, no. 5, pp. 2215–2228, October 2020
2020
-
[51]
Minimizing age of incorrect information for unreliable channel with power constraint,
Y . Chen and A. Ephremides, “Minimizing age of incorrect information for unreliable channel with power constraint,” inIEEE Globecom, December 2021
2021
-
[52]
When to pull data from sensors for minimum distance-based age of incorrect information metric,
S. Kriouile and M. Assaad, “When to pull data from sensors for minimum distance-based age of incorrect information metric,” inIEEE WiOpt, February 2022
2022
-
[53]
Modeling AoII in push- and pull- based sampling of continuous time Markov chains,
I. Cosandal, N. Akar, and S. Ulukus, “Modeling AoII in push- and pull- based sampling of continuous time Markov chains,” inIEEE Infocom, May 2024
2024
-
[54]
AoII-optimum sampling of CTMC information sources under sampling rate constraints,
——, “AoII-optimum sampling of CTMC information sources under sampling rate constraints,” inIEEE ISIT, July 2024
2024
-
[55]
Multi-threshold AoII-optimum sampling policies for CTMC information sources,
——, “Multi-threshold AoII-optimum sampling policies for CTMC information sources,”IEEE Trans. Inf. Theory, vol. 71, no. 9, pp. 6968– 6988, July 2025
2025
-
[56]
Query-based sampling of heterogeneous CTMCs: Modeling and optimization with binary freshness,
N. Akar and S. Ulukus, “Query-based sampling of heterogeneous CTMCs: Modeling and optimization with binary freshness,”IEEE Trans. Comm., vol. 72, no. 12, pp. 7705–7714, June 2024
2024
-
[57]
Minimizing the age of incorrect information for real-time tracking of Markov remote sources,
S. Kriouile and M. Assaad, “Minimizing the age of incorrect information for real-time tracking of Markov remote sources,” inIEEE ISIT, July 2021
2021
-
[58]
Age of incorrect information for remote estimation of a binary Markov source,
C. Kam, S. Kompella, and A. Ephremides, “Age of incorrect information for remote estimation of a binary Markov source,” inIEEE Infocom, July 2020
2020
-
[59]
Resolving multiple-dynamic model uncertainty in hypothesis-driven belief-MDPs,
O. Dagan, T. Becker, and Z. N. Sunberg, “Resolving multiple-dynamic model uncertainty in hypothesis-driven belief-MDPs,” inAAMAS, May 2025
2025
-
[60]
Optimality guarantees for particle belief approximation of POMDPs,
M. H. Lim, T. J. Becker, M. J. Kochenderfer, C. J. Tomlin, and Z. N. Sunberg, “Optimality guarantees for particle belief approximation of POMDPs,”Journal of Artificial Intelligence Research, vol. 77, pp. 1591– 1636, 2023
2023
-
[61]
Model predictive control and reinforcement learning: A unified framework based on dynamic programming,
D. P. Bertsekas, “Model predictive control and reinforcement learning: A unified framework based on dynamic programming,” inIFAC NMPC, August 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.