Structured Inference with Large Language Gibbs
Pith reviewed 2026-06-26 20:59 UTC · model grok-4.3
The pith
Iterative resampling of variables with LLM next-token conditionals produces a stationary distribution that compromises across all local conditionals without order bias.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
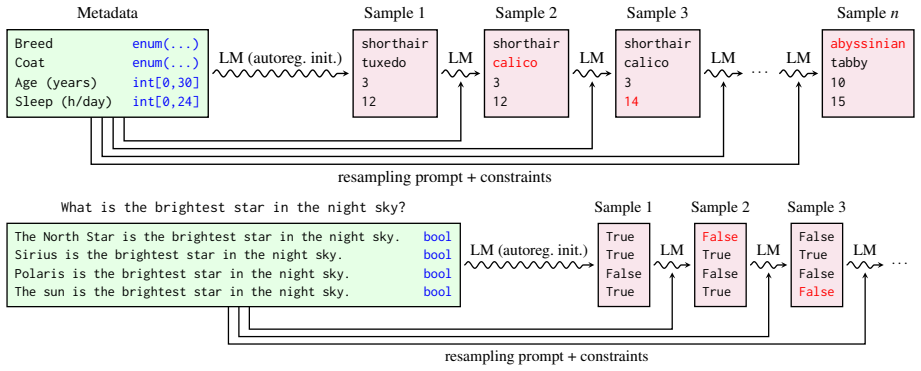
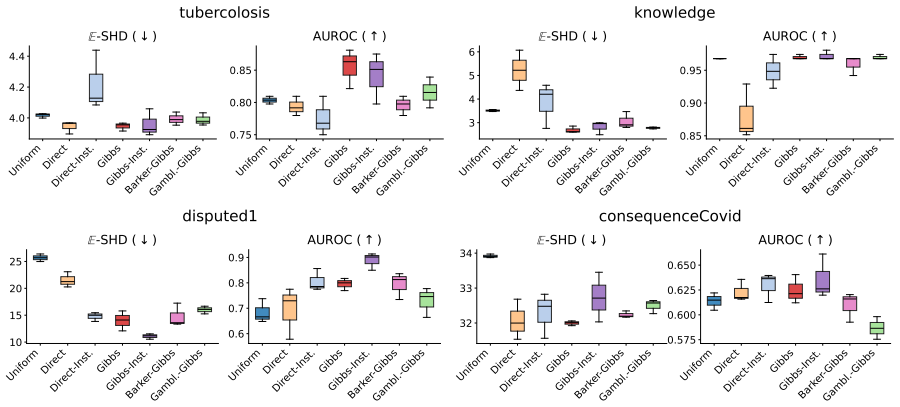
Large Language Gibbs iteratively resamples individual variables conditioned on others using an LLM's next-token conditionals as MCMC transition operators. This produces a stationary distribution that reflects a compromise between all local conditionals and avoids order-dependent biases of single-pass autoregressive generation. The method is applied to sampling from synthetic distributions, consistent reasoning tasks, and Bayesian structure learning, suggesting it serves as a practical alternative to one-pass generation for structured inference under a world prior accessible through noisy LLM conditionals.
What carries the argument
Large Language Gibbs, which deploys LLM next-token conditional distributions directly as MCMC transition operators for iterative per-variable resampling.
If this is right
- Sampling from synthetic distributions can proceed without dependence on variable ordering.
- Consistent reasoning tasks obtain outputs that average across conflicting local conditionals.
- Bayesian structure learning becomes feasible by treating LLM conditionals as a prior and running the chain to stationarity.
- Structured probabilistic inference under noisy LLM conditionals is achievable as an alternative to one-pass autoregressive generation.
Where Pith is reading between the lines
- The same iterative scheme could be tested on tasks requiring global consistency over many interdependent variables where single-pass generation commonly fails.
- Convergence diagnostics from standard MCMC might be applied to decide when the chain has reached a useful compromise distribution.
- The approach opens a route to combining multiple LLMs by mixing their conditionals within the same transition kernel.
Load-bearing premise
LLM next-token conditional distributions can function as valid MCMC transition operators whose repeated application converges to a stationary distribution that meaningfully compromises across the local conditionals.
What would settle it
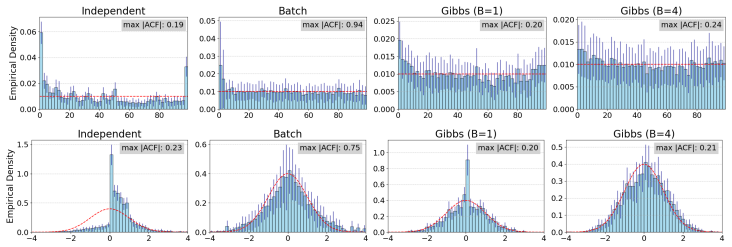
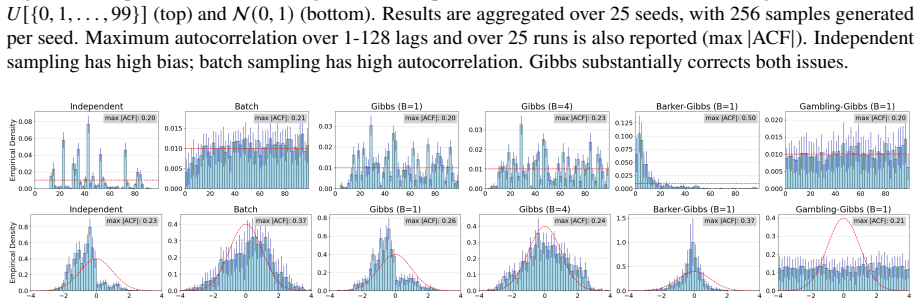
Apply the sampler to a known joint distribution whose marginal conditionals are supplied to the LLM and check whether the long-run empirical frequencies match the expected compromise distribution rather than any single conditional or an order-dependent product.
Figures


read the original abstract
The knowledge encoded in large language models (LLMs) can serve as a substrate for structured reasoning over variables describing a complex world, but accessing this knowledge in a probabilistically coherent manner poses a difficult inference problem. We propose Large Language Gibbs, a scheme for structured probabilistic inference that uses conditional distributions of an LLM as transition operators. Rather than sampling structured objects through single-pass autoregressive generation, we iteratively resample individual variables conditioned on others using an LLM's next-token conditionals. This approach avoids order-dependent biases and produces a stationary distribution that reflects a compromise between all local conditionals. We apply this approach to sampling from synthetic distributions, consistent reasoning tasks, and Bayesian structure learning. The results suggest that the use of LLM conditionals in MCMC is a practical alternative to one-pass generation for structured probabilistic inference under a world prior accessible through noisy LLM conditionals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Large Language Gibbs, an MCMC procedure that uses an LLM's next-token conditional distributions as transition kernels to iteratively resample individual variables in a structured object, conditioned on the current values of the others. The central claim is that this avoids the order-dependent biases of single-pass autoregressive generation and converges to a stationary distribution that represents a compromise across the local conditionals. The method is applied to sampling from synthetic distributions, consistent reasoning tasks, and Bayesian structure learning.
Significance. If the procedure can be shown to possess a well-defined stationary distribution despite the generic inconsistency of LLM conditionals, the approach would supply a practical alternative to direct generation for probabilistic inference under an LLM world model. The empirical sections indicate that the method is implementable and yields reasonable samples on the chosen tasks, but the absence of any convergence argument makes the significance conditional on resolving the theoretical gap.
major comments (2)
- [Abstract, paragraph 2] Abstract, paragraph 2: the claim that iterated application of the LLM next-token conditionals "produces a stationary distribution that reflects a compromise between all local conditionals" is stated without derivation, without conditions guaranteeing existence or uniqueness of the stationary measure, and without discussion of reversibility or ergodicity. Standard Gibbs sampling requires the family of conditionals to be compatible with a joint; no argument is supplied that LLM conditionals meet this requirement or that the induced kernel is ergodic.
- [Method] Method description (inferred from abstract): treating each LLM conditional p_θ(var_i | all others) as a valid MCMC transition operator is load-bearing for the entire proposal, yet no proof or even heuristic argument is given that the resulting Markov chain converges or that its stationary distribution is independent of initialization when the conditionals are inconsistent.
Simulated Author's Rebuttal
We thank the referee for identifying the central theoretical gap in our manuscript. The comments correctly note that we provide no derivation or convergence argument for the stationary distribution under inconsistent LLM conditionals. We respond point-by-point below and will revise the paper to qualify claims and add discussion of this limitation.
read point-by-point responses
-
Referee: [Abstract, paragraph 2] Abstract, paragraph 2: the claim that iterated application of the LLM next-token conditionals "produces a stationary distribution that reflects a compromise between all local conditionals" is stated without derivation, without conditions guaranteeing existence or uniqueness of the stationary measure, and without discussion of reversibility or ergodicity. Standard Gibbs sampling requires the family of conditionals to be compatible with a joint; no argument is supplied that LLM conditionals meet this requirement or that the induced kernel is ergodic.
Authors: We agree the claim is presented without formal derivation. The abstract statement reflects an empirical observation from our experiments rather than a proven result. In revision we will rephrase the abstract to describe the outcome as an observed compromise supported by the synthetic and reasoning tasks, and we will add a dedicated limitations paragraph in the method section acknowledging that LLM conditionals are generally incompatible and that standard Gibbs guarantees do not apply. A full proof of existence, uniqueness, or ergodicity is not supplied because none is currently available. revision: partial
-
Referee: [Method] Method description (inferred from abstract): treating each LLM conditional p_θ(var_i | all others) as a valid MCMC transition operator is load-bearing for the entire proposal, yet no proof or even heuristic argument is given that the resulting Markov chain converges or that its stationary distribution is independent of initialization when the conditionals are inconsistent.
Authors: The manuscript treats each next-token conditional as a valid transition kernel but supplies no convergence argument. We will insert a short heuristic discussion noting that each kernel is a proper conditional distribution and that the chain appears irreducible on the finite support used in our experiments; however, we will explicitly state that independence from initialization and uniqueness of the stationary measure are not guaranteed when conditionals are inconsistent. The revision will also reference the synthetic-distribution experiments as empirical evidence that mixing occurs in practice, while making clear this does not constitute a proof. revision: yes
- A rigorous proof or set of sufficient conditions establishing existence, uniqueness, and ergodicity of a stationary distribution for the induced Markov chain when the LLM conditionals are mutually inconsistent.
Circularity Check
No circularity: stationary distribution claim follows from MCMC construction without reduction to inputs
full rationale
The paper's abstract states that iterative resampling with LLM next-token conditionals 'produces a stationary distribution that reflects a compromise between all local conditionals.' This is presented as a direct consequence of applying MCMC transition operators, without any equations, fitted parameters, or self-citations that would make the result equivalent to its inputs by construction. No load-bearing step matches the enumerated circularity patterns; the claim relies on standard MCMC theory applied to the proposed kernels rather than redefining or fitting the target quantity from the paper's own data or prior outputs. The assumption that LLM conditionals form valid kernels is a substantive (and potentially falsifiable) modeling choice, not a definitional tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math MCMC transition operators defined by conditional distributions converge to a stationary distribution under standard regularity conditions
Reference graph
Works this paper leans on
-
[1]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[2]
Large language
Domke, Justin , journal=. Large language
-
[3]
Neural Information Processing Systems (NeurIPS) , year=
Structured denoising diffusion models in discrete state-spaces , author=. Neural Information Processing Systems (NeurIPS) , year=
-
[4]
Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles , year=
-
[5]
Neural Information Processing Systems (NeurIPS) , year=
Chain-of-thought prompting elicits reasoning in large language models , author=. Neural Information Processing Systems (NeurIPS) , year=
-
[6]
Neural Information Processing Systems (NeurIPS) , year=
Simplified and generalized masked diffusion for discrete data , author=. Neural Information Processing Systems (NeurIPS) , year=
-
[7]
Neural Information Processing Systems (NeurIPS) , year=
Simple and effective masked diffusion language models , author=. Neural Information Processing Systems (NeurIPS) , year=
-
[8]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[9]
arXiv preprint arXiv:2512.13961 , year=
Olmo 3 , author=. arXiv preprint arXiv:2512.13961 , year=
-
[10]
BERT has a Mouth, and It Must Speak: BERT as a M arkov Random Field Language Model
Wang, Alex and Cho, Kyunghyun. BERT has a Mouth, and It Must Speak: BERT as a M arkov Random Field Language Model. Proceedings of the Workshop on Methods for Optimizing and Evaluating Neural Language Generation. 2019. doi:10.18653/v1/W19-2304
-
[11]
Probing BERT ' s priors with serial reproduction chains
Yamakoshi, Takateru and Griffiths, Thomas and Hawkins, Robert. Probing BERT ' s priors with serial reproduction chains. Findings of the Association for Computational Linguistics: ACL 2022. 2022. doi:10.18653/v1/2022.findings-acl.314
-
[12]
International Conference on Learning Representations (ICLR) , year=
Exposing the Implicit Energy Networks behind Masked Language Models via Metropolis--Hastings , author=. International Conference on Learning Representations (ICLR) , year=
-
[13]
International Conference on Learning Representations (ICLR) , year=
Reasoning with sampling: Your base model is smarter than you think , author=. International Conference on Learning Representations (ICLR) , year=
-
[14]
Neural Information Processing Systems (NeurIPS) , year=
QUEST: Quality-aware metropolis-hastings sampling for machine translation , author=. Neural Information Processing Systems (NeurIPS) , year=
-
[15]
Flipping against all odds: Reducing
Xiao, Tim Z and Zenn, Johannes and Liu, Zhen and Liu, Weiyang and Bamler, Robert and Sch. Flipping against all odds: Reducing. arXiv preprint arXiv:2506.09998 , year=
-
[16]
Probabilistic inference in language models via twisted sequential
Zhao, Stephen and Brekelmans, Rob and Makhzani, Alireza and Grosse, Roger , journal=. Probabilistic inference in language models via twisted sequential
-
[17]
Test , volume=
Distributions most nearly compatible with given families of conditional distributions , author=. Test , volume=. 1998 , publisher=
1998
-
[18]
Australian Journal of Physics , volume=
Monte carlo calculations of the radial distribution functions for a proton? electron plasma , author=. Australian Journal of Physics , volume=. 1965 , publisher=
1965
-
[19]
arXiv preprint arXiv:2604.06543 , year=
The Illusion of Stochasticity in LLMs , author=. arXiv preprint arXiv:2604.06543 , year=
-
[20]
International Conference on Learning Representations (ICLR) , year=
Amortizing intractable inference in large language models , author=. International Conference on Learning Representations (ICLR) , year=
-
[21]
Aspen K Hopkins and Alex Renda and Michael Carbin , journal=. Can. 2023 , url=
2023
-
[22]
science , volume=
Optimization by simulated annealing , author=. science , volume=. 1983 , publisher=
1983
-
[23]
Uncertainty in Artificial Intelligence (UAI) , year=
Bayesian structure learning with generative flow networks , author=. Uncertainty in Artificial Intelligence (UAI) , year=
-
[24]
Machine learning , volume=
Learning Bayesian networks: The combination of knowledge and statistical data , author=. Machine learning , volume=. 1995 , publisher=
1995
-
[25]
2009 , publisher=
Probabilistic graphical models: principles and techniques , author=. 2009 , publisher=
2009
-
[26]
Neurocomputing , volume=
bnRep: A repository of Bayesian networks from the academic literature , author=. Neurocomputing , volume=. 2025 , publisher=
2025
-
[27]
Journal of statistical software , volume=
Learning Bayesian networks with the bnlearn R package , author=. Journal of statistical software , volume=
-
[28]
International Conference on Learning Representations (ICLR) , year=
Large (Vision) Language Models are Unsupervised In-Context Learners , author=. International Conference on Learning Representations (ICLR) , year=
-
[29]
arXiv preprint arXiv:2506.10139 , year=
Unsupervised elicitation of language models , author=. arXiv preprint arXiv:2506.10139 , year=
-
[30]
Neural Information Processing Systems (NeurIPS) , year=
Language models are few-shot learners , author=. Neural Information Processing Systems (NeurIPS) , year=
-
[31]
Deriving Language Models from Masked Language Models
Torroba Hennigen, Lucas and Kim, Yoon. Deriving Language Models from Masked Language Models. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2023. doi:10.18653/v1/2023.acl-short.99
-
[32]
Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity
Lu, Yao and Bartolo, Max and Moore, Alastair and Riedel, Sebastian and Stenetorp, Pontus. Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.556
-
[33]
Proceedings of the Annual Meeting of the Cognitive Science Society , volume=
Recovering Mental Representations from Large Language Models with Markov Chain Monte Carlo , author=. Proceedings of the Annual Meeting of the Cognitive Science Society , volume=
-
[34]
Proceedings of the Annual Meeting of the Cognitive Science Society , volume=
Eliciting the Priors of Large Language Models using Iterated In-Context Learning , author=. Proceedings of the Annual Meeting of the Cognitive Science Society , volume=
-
[35]
2023 , journal=
Language Models are Realistic Tabular Data Generators , author=. 2023 , journal=
2023
-
[36]
Lost in the Middle: How Language Models Use Long Contexts,
Liu, Nelson F. and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy. Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00638
-
[37]
Stochastic relaxation,
Geman, Stuart and Geman, Donald , journal=. Stochastic relaxation,. 1984 , publisher=
1984
-
[38]
2003 , publisher=
Information theory, inference and learning algorithms , author=. 2003 , publisher=
2003
-
[39]
International Conference on Learning Representations (ICLR) , year=
All Roads Lead to Likelihood: The Value of Reinforcement Learning in Fine-Tuning , author=. International Conference on Learning Representations (ICLR) , year=
-
[40]
Reprompting: Automated Chain-of-Thought Prompt Inference Through
Weijia Xu and Andrzej Banburski-Fahey and Nebojsa Jojic , year=. Reprompting: Automated Chain-of-Thought Prompt Inference Through
-
[41]
Journal of Machine Learning Research , month = 3, pages =
Chickering, David Maxwell , title =. Journal of Machine Learning Research , month = 3, pages =. 2003 , volume =
2003
-
[42]
arXiv preprint arXiv:2309.12032 , year=
Expert-Aided Causal Discovery of Ancestral Graphs , author=. arXiv preprint arXiv:2309.12032 , year=
-
[43]
arXiv preprint arXiv:2307.02390 , year=
Causal discovery with language models as imperfect experts , author=. arXiv preprint arXiv:2307.02390 , year=
-
[44]
International Conference on Learning Representations (ICLR) , year=
Causal Order: The Key to Leveraging Imperfect Experts in Causal Inference , author=. International Conference on Learning Representations (ICLR) , year=
-
[45]
Spirtes, Peter and Glymour, Clark and Scheines, Richard , year =
-
[46]
Lorch, Lars and Rothfuss, Jonas and Krause, Andreas and Scholkopf, Bernhard , journal=
-
[47]
Towards scalable
Viinikka, Jussi and Hyttinen, Antti and Pensar, Johan and Koivisto, Mikko , journal=. Towards scalable
-
[48]
International Statistical Review , year=
Bayesian graphical models for discrete data , author=. International Statistical Review , year=
-
[49]
Improving
Giudici, Paolo and Castelo, Robert , journal=. Improving
-
[50]
Journal of Machine Learning Research , volume=
Dependency networks for inference, collaborative filtering, and data visualization , author=. Journal of Machine Learning Research , volume=
-
[51]
International Conference on Machine Learning (ICML) , year=
Deep generative stochastic networks trainable by backprop , author=. International Conference on Machine Learning (ICML) , year=
-
[52]
Stat , volume=
Had enough of experts? quantitative knowledge retrieval from large language models , author=. Stat , volume=. 2025 , publisher=
2025
-
[53]
arXiv preprint arXiv:2405.13551 , year=
Large language models are effective priors for causal graph discovery , author=. arXiv preprint arXiv:2405.13551 , year=
-
[54]
Capstick, Alexander and Krishnan, Rahul G and Barnaghi, Payam , journal=
-
[55]
How many patients could we save with
Arai, Shota and Selby, David and Vargo, Andrew and Vollmer, Sebastian , journal=. How many patients could we save with
-
[56]
AutoML Conference 2024 (Workshop Track) , year=
Automated Prior Elicitation from Large Language Models for Bayesian Logistic Regression , author=. AutoML Conference 2024 (Workshop Track) , year=
2024
-
[57]
International Conference on Machine Learning (ICML) , year=
Principled Gradient-based Markov Chain Monte Carlo for Text Generation , author=. International Conference on Machine Learning (ICML) , year=
-
[58]
Ning Miao and Hao Zhou and Lili Mou and Rui Yan and Lei Li , journal=
-
[59]
Lianhui Qin and Sean Welleck and Daniel Khashabi and Yejin Choi , journal=
-
[60]
Gradient-based Constrained Sampling from Language Models
Kumar, Sachin and Paria, Biswajit and Tsvetkov, Yulia. Gradient-based Constrained Sampling from Language Models. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.144
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.