Narrative-UFET: Narrative Generation for Ultra-Fine Entity Typing
Pith reviewed 2026-06-29 01:12 UTC · model grok-4.3
The pith
Narrative context improves ultra-fine entity typing accuracy on long-tail types compared to sentence-only or natural contexts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
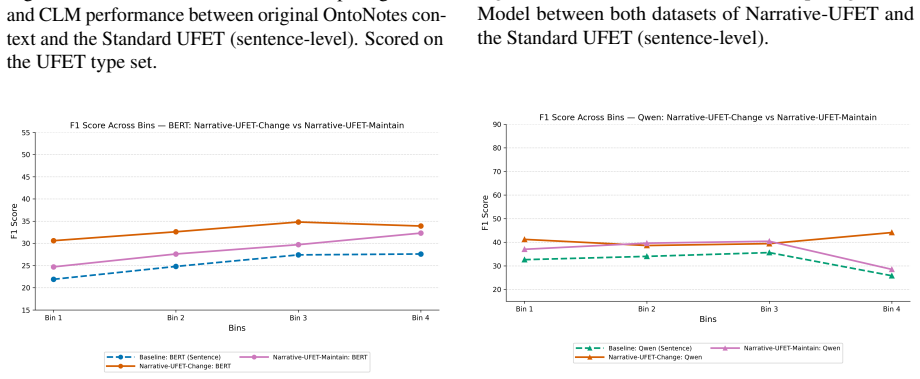
Narrative-UFET pairs each entity mention with an automatically generated short coherent narrative in two paired variants (Maintain, where the type remains constant, and Change, where it shifts), and demonstrates that these narrative contexts produce consistent accuracy gains on long-tail ultra-fine types over sentence-level baselines, with the Change variant stronger, while also outperforming naturally occurring contexts.
What carries the argument
Controlled narrative generation that isolates specific discourse properties (Maintain versus Change) to supply multi-sentence context beyond the original sentence.
If this is right
- Disambiguating evidence for rare ultra-fine types is often distributed across sentences rather than contained in one.
- The type-shift property in narrative context supplies a stronger training signal than type maintenance.
- Deliberately constructed synthetic text can reveal discourse signals that naturally occurring text leaves implicit.
- Substantial performance headroom remains after adding narrative context.
Where Pith is reading between the lines
- The same controlled-narrative technique could be tested on other span-level tasks such as fine-grained relation extraction or event argument linking.
- Hybrid architectures that jointly encode the original sentence and the generated narrative may capture both local and discourse-level cues.
- If narrative generation quality improves, the performance gap between synthetic and natural contexts could widen further.
Load-bearing premise
The automatically generated narratives remain coherent and free of artifacts that would confound the comparison between discourse variants and sentence-level or natural contexts.
What would settle it
No accuracy improvement on long-tail types when models are given the generated narratives instead of only the sentence, or no advantage for the Change variant over the Maintain variant.
Figures
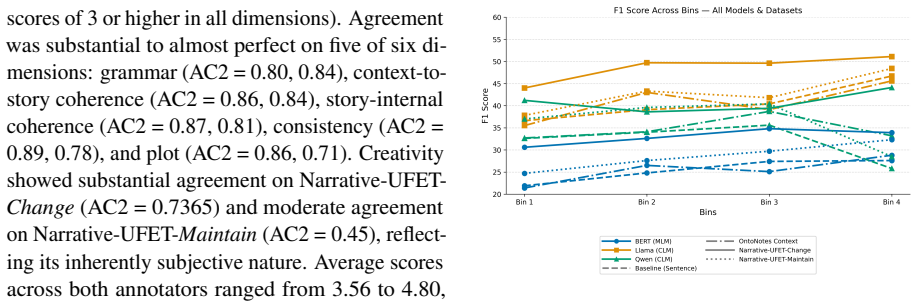
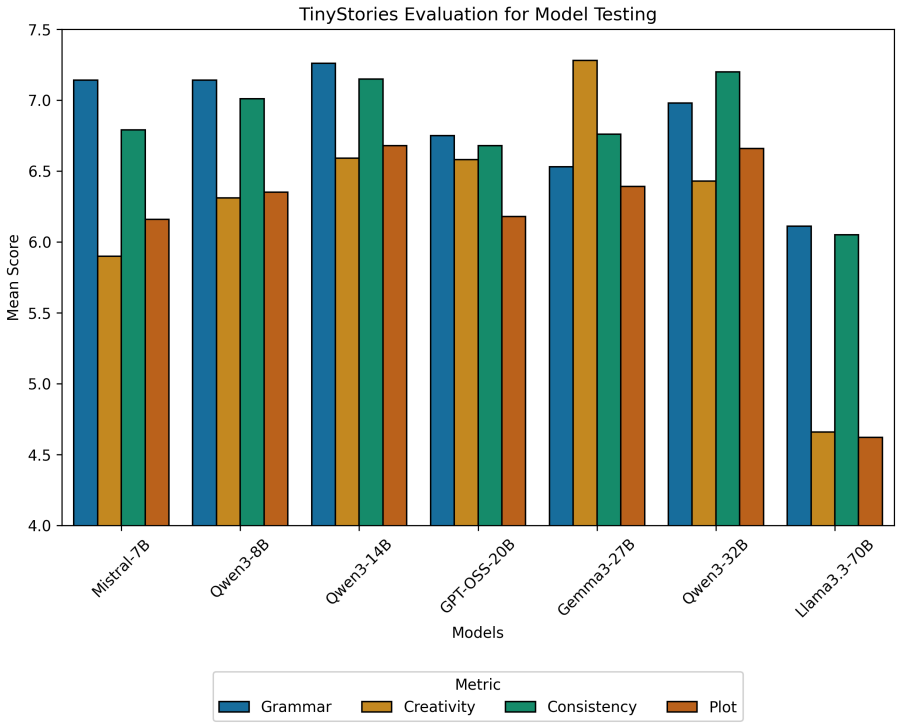
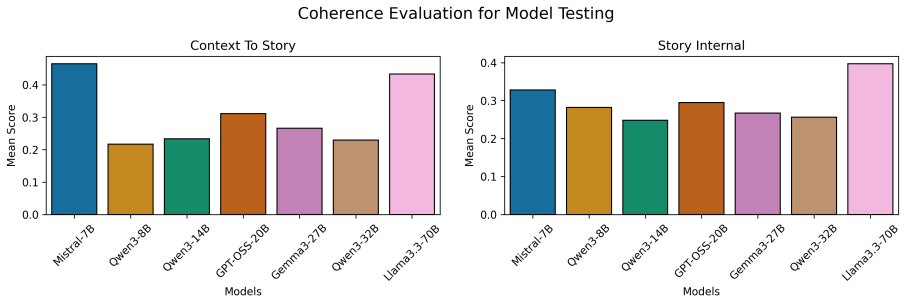
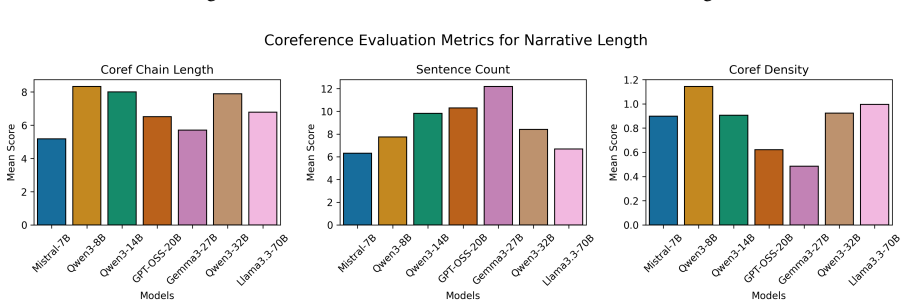

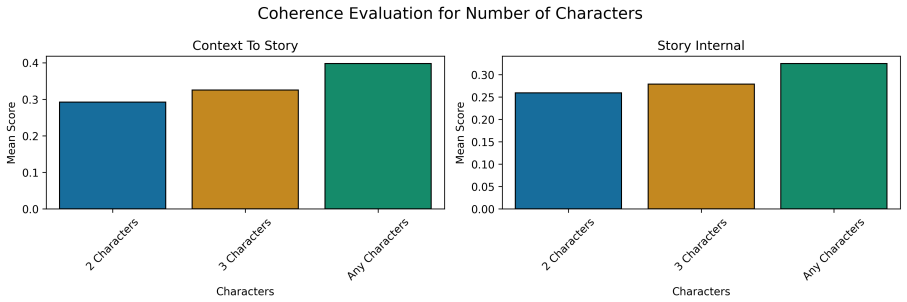
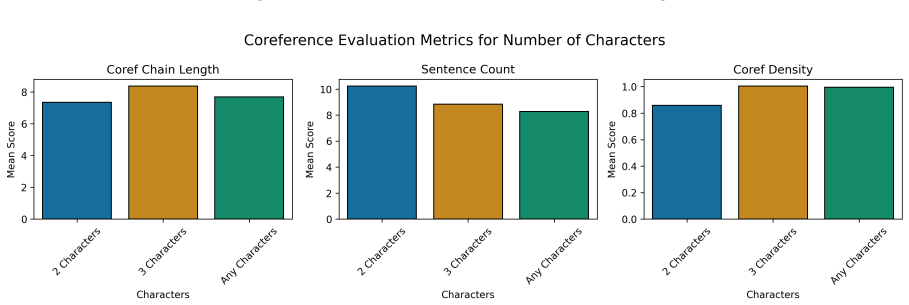
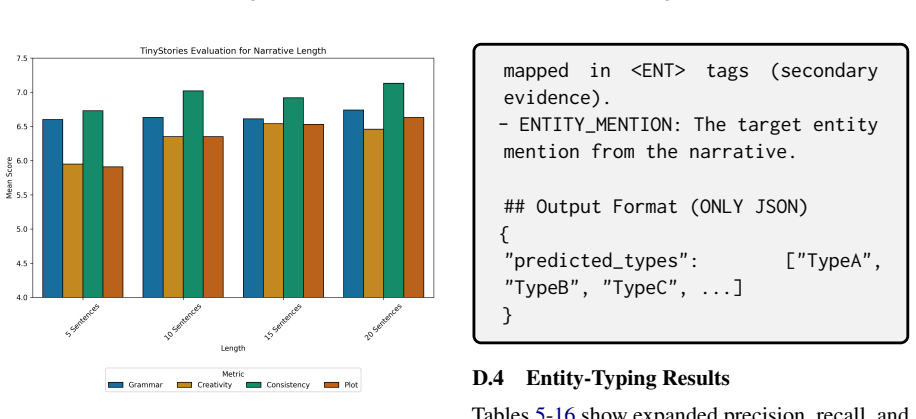
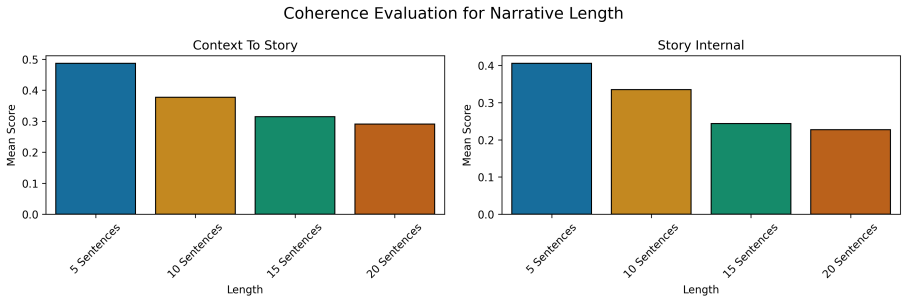
read the original abstract
Ultra-fine entity typing (UFET) assigns highly specific types to entity mentions, but current approaches struggle with types in the long tail. We hypothesize that a key limitation is the reliance on sentence-level context, since disambiguating evidence is often spread across multiple sentences. Testing this has been difficult because all existing UFET resources are sentence-level. We present Narrative-UFET, a controlled extension of UFET in which each entity mention is paired with an automatically generated short, coherent narrative. Synthesizing narratives lets us isolate the effect of specific discourse properties. We experiment with two paired variants: one in which the entity's type is held constant across the narrative (Maintain) and one in which it shifts (Change). We show that narrative context yields consistent improvements on long-tail types over sentence-level baselines, with the Change variant providing the stronger signal. A comparison against naturally occurring contexts shows that synthetic narratives yield stronger gains, indicating that controlled discourse construction can surface signals that real text leaves implicit. Substantial room for improvement remains, suggesting open directions in both discourse modeling and narrative construction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
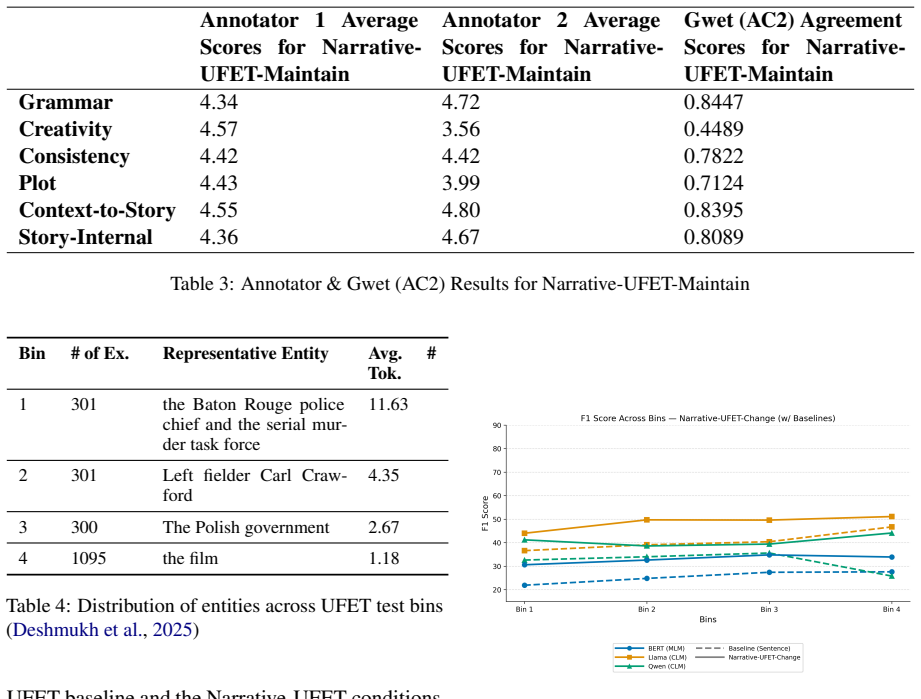
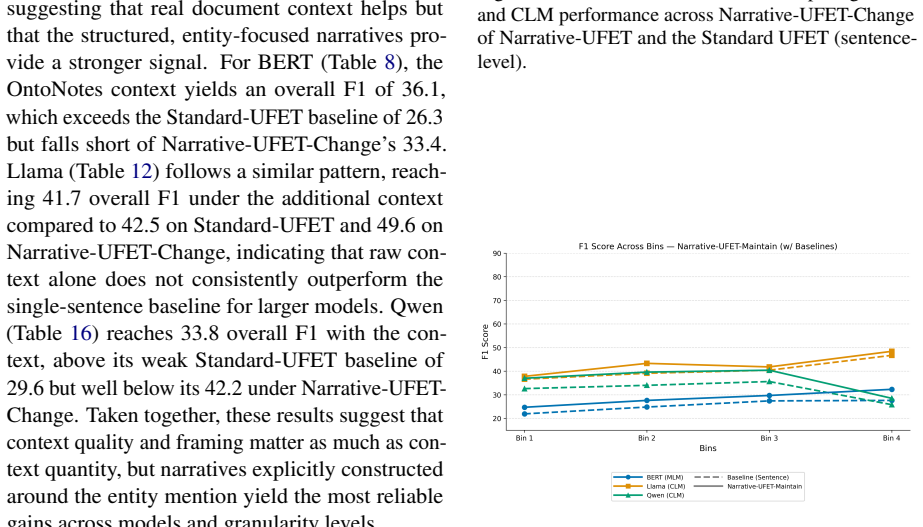
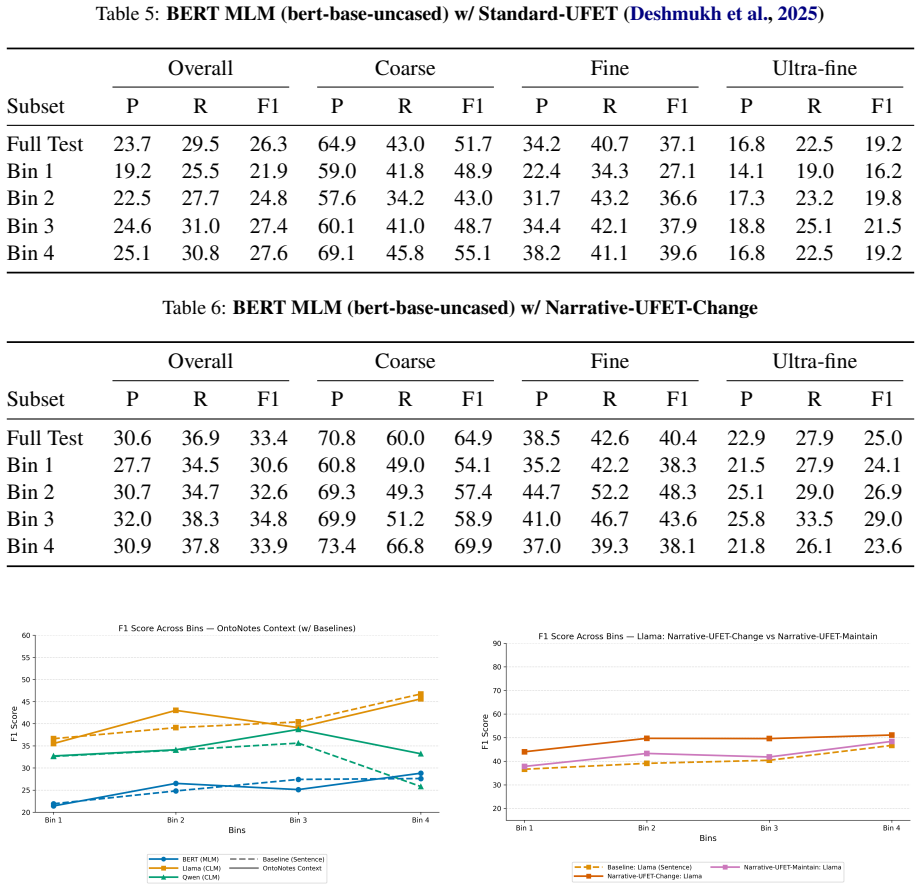
Summary. The manuscript introduces Narrative-UFET, a controlled extension of existing ultra-fine entity typing (UFET) resources. Each entity mention is paired with an automatically generated short coherent narrative, with two paired variants: Maintain (entity type held constant across the narrative) and Change (type shifts). Experiments claim that narrative context yields consistent gains on long-tail types over sentence-level baselines (stronger for Change), and that synthetic narratives outperform naturally occurring contexts.
Significance. If the experimental results hold after controlling for generation artifacts, the work would establish that discourse-level context can surface disambiguating evidence for long-tail UFET types and that deliberate narrative construction can outperform natural text. It would also motivate further research on discourse modeling and controlled synthetic data for entity typing tasks.
major comments (2)
- [Narrative generation and experimental setup sections] The central attribution of long-tail gains to the Maintain/Change discourse manipulation and to synthetic construction requires explicit verification that the narrative generator introduces no differential type leakage, coherence artifacts, or stylistic regularities that correlate with the Change condition or with long-tail performance. Without such controls or post-hoc analyses, the sentence-level baseline comparison and the synthetic-vs-natural contrast cannot be cleanly interpreted.
- [Results and discussion sections] The comparison to naturally occurring contexts must include matched statistics on narrative length, coherence, and entity-type distribution to ensure the reported stronger gains for synthetic narratives are not driven by uncontrolled differences in the natural-context baseline.
minor comments (3)
- [Abstract] The abstract should name the base UFET dataset(s) being extended and report the number of narratives generated per variant.
- [Throughout] Notation for the two variants (Maintain vs. Change) should be introduced once with a clear definition and used consistently in all tables and figures.
- [Evaluation section] Any human evaluation of narrative coherence or quality should be described with inter-annotator agreement and sample size.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of experimental controls needed to support our claims about narrative context in ultra-fine entity typing. We address each major comment below and will revise the manuscript accordingly to include the requested verifications and matched statistics.
read point-by-point responses
-
Referee: [Narrative generation and experimental setup sections] The central attribution of long-tail gains to the Maintain/Change discourse manipulation and to synthetic construction requires explicit verification that the narrative generator introduces no differential type leakage, coherence artifacts, or stylistic regularities that correlate with the Change condition or with long-tail performance. Without such controls or post-hoc analyses, the sentence-level baseline comparison and the synthetic-vs-natural contrast cannot be cleanly interpreted.
Authors: We agree that explicit verification is required to rule out generation artifacts as alternative explanations for the observed gains. The manuscript's generation process uses a controlled prompt template that conditions only on the target entity mention, sentence context, and desired type behavior (Maintain vs. Change), with no direct type leakage in the prompt itself. However, we did not include post-hoc checks in the original submission. In the revision we will add: (i) type-mention frequency analysis across conditions to quantify leakage, (ii) automated coherence metrics (e.g., entity-grid coherence and perplexity under a held-out language model) stratified by Maintain/Change and by tail vs. head types, and (iii) stylistic regularity checks via n-gram overlap and sentence-length distributions. These analyses will be reported in a new subsection of the experimental setup. If any differential artifacts are detected, we will discuss their magnitude and potential impact on the long-tail gains. revision: yes
-
Referee: [Results and discussion sections] The comparison to naturally occurring contexts must include matched statistics on narrative length, coherence, and entity-type distribution to ensure the reported stronger gains for synthetic narratives are not driven by uncontrolled differences in the natural-context baseline.
Authors: We acknowledge that the current synthetic-vs-natural comparison lacks explicit matching statistics, which limits interpretability of why synthetic narratives yield stronger gains. The natural contexts were drawn from the same underlying documents as the original UFET sentences, while synthetic narratives were generated to a target length of approximately 3–5 sentences. In the revised manuscript we will add a table in the results section reporting: average narrative length (in tokens and sentences), coherence scores, and the distribution of ultra-fine types for both the synthetic Maintain/Change sets and the natural-context baseline. We will also report whether any imbalances exist and, if so, whether they correlate with performance differences. This will allow readers to evaluate the fairness of the contrast. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper is an empirical contribution that introduces a new dataset (Narrative-UFET) via automatic narrative generation and reports experimental gains on long-tail UFET types for Maintain/Change variants versus sentence-level and natural-context baselines. No equations, parameter-fitting steps, or first-principles derivations are present in the provided text. Claims rest on direct comparisons of model performance rather than any self-definitional mapping, fitted-input-as-prediction, or load-bearing self-citation chain. The central result (narrative context improves long-tail typing) is externally falsifiable against held-out data and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Suchanek, and Chlo \'e Clavel
Cyril Chhun, Pierre Colombo, Fabian M. Suchanek, and Chlo \'e Clavel. 2022. https://aclanthology.org/2022.coling-1.509/ Of human criteria and automatic metrics: A benchmark of the evaluation of story generation . In Proceedings of the 29th International Conference on Computational Linguistics, pages 5794--5836, Gyeongju, Republic of Korea. International C...
2022
-
[2]
Eunsol Choi, Omer Levy, Yejin Choi, and Luke Zettlemoyer. 2018. https://doi.org/10.18653/v1/P18-1009 Ultra-fine entity typing . In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 87--96, Melbourne, Australia. Association for Computational Linguistics
-
[3]
Hongliang Dai, Yangqiu Song, and Haixun Wang. 2021. https://doi.org/10.18653/v1/2021.acl-long.141 Ultra-fine entity typing with weak supervision from a masked language model . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long...
-
[4]
Advait Deshmukh, Ashwin Umadi, Dananjay Srinivas, and Maria Leonor Pacheco. 2025. https://doi.org/10.18653/v1/2025.starsem-1.15 All entities are not created equal: Examining the long tail for ultra-fine entity typing . In Proceedings of the 14th Joint Conference on Lexical and Computational Semantics (*SEM 2025), pages 189--201, Suzhou, China. Association...
-
[5]
Ning Ding, Guangwei Xu, Yulin Chen, Xiaobin Wang, Xu Han, Pengjun Xie, Haitao Zheng, and Zhiyuan Liu. 2021. https://doi.org/10.18653/v1/2021.acl-long.248 Few- NERD : A few-shot named entity recognition dataset . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural...
-
[6]
Ronen Eldan and Yuanzhi Li. 2023. https://arxiv.org/abs/2305.07759 Tinystories: How small can language models be and still speak coherent english? Preprint, arXiv:2305.07759
Pith/arXiv arXiv 2023
-
[9]
Seraphina Goldfarb-Tarrant, Tuhin Chakrabarty, Ralph Weischedel, and Nanyun Peng. 2020. https://doi.org/10.18653/v1/2020.emnlp-main.351 Content planning for neural story generation with aristotelian rescoring . In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4319--4338, Online. Association for Compu...
-
[10]
K.L. Gwet. 2014. https://books.google.com/books?id=fac9BQAAQBAJ Handbook of Inter-Rater Reliability, 4th Edition: The Definitive Guide to Measuring The Extent of Agreement Among Raters . Advanced Analytics, LLC
2014
-
[11]
Fabrice Y Harel-Canada, Hanyu Zhou, Sreya Muppalla, Zeynep Senahan Yildiz, Miryung Kim, Amit Sahai, and Nanyun Peng. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.953 Measuring psychological depth in language models . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17162--17196, Miami, Florida, USA. Ass...
-
[12]
Mitchell Koch, John Gilmer, Stephen Soderland, and Daniel S. Weld. 2014. https://doi.org/10.3115/v1/D14-1203 Type-aware distantly supervised relation extraction with linked arguments . In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing ( EMNLP ) , pages 1891--1901, Doha, Qatar. Association for Computational Linguistics
-
[13]
Jinyuan Li, Han Li, Di Sun, Jiahao Wang, Wenkun Zhang, Zan Wang, and Gang Pan. 2024 a . https://doi.org/10.18653/v1/2024.findings-acl.76 LLM s as bridges: Reformulating grounded multimodal named entity recognition . In Findings of the Association for Computational Linguistics: ACL 2024, pages 1302--1318, Bangkok, Thailand. Association for Computational Li...
-
[14]
Muzhi Li, Minda Hu, Irwin King, and Ho-fung Leung. 2024 b . https://doi.org/10.18653/v1/2024.naacl-long.369 The integration of semantic and structural knowledge in knowledge graph entity typing . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long...
-
[15]
Na Li, Zied Bouraoui, and Steven Schockaert. 2023. https://doi.org/10.18653/v1/2023.findings-emnlp.786 Ultra-fine entity typing with prior knowledge about labels: A simple clustering based strategy . In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 11744--11756, Singapore. Association for Computational Linguistics
-
[16]
Xiao Ling, Sameer Singh, and Daniel S. Weld. 2015. https://doi.org/10.1162/tacl_a_00141 Design challenges for entity linking . Transactions of the Association for Computational Linguistics, 3:315--328
-
[18]
Ben Naismith, Phoebe Mulcaire, and Jill Burstein. 2023. https://doi.org/10.18653/v1/2023.bea-1.32 Automated evaluation of written discourse coherence using GPT -4 . In Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023), pages 394--403, Toronto, Canada. Association for Computational Linguistics
-
[19]
Yasumasa Onoe and Greg Durrett. 2020. https://doi.org/10.18653/v1/2020.findings-emnlp.54 Interpretable entity representations through large-scale typing . In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 612--624, Online. Association for Computational Linguistics
-
[21]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. http://jmlr.org/papers/v21/20-074.html Exploring the limits of transfer learning with a unified text-to-text transformer . Journal of Machine Learning Research, 21(140):1--67
2020
-
[22]
Sebastian Riedel, Limin Yao, and Andrew McCallum. 2010. https://api.semanticscholar.org/CorpusID:2386383 Modeling relations and their mentions without labeled text . In ECML/PKDD
2010
-
[24]
Yufei Tian, Tenghao Huang, Miri Liu, Derek Jiang, Alexander Spangher, Muhao Chen, Jonathan May, and Nanyun Peng. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.978 Are large language models capable of generating human-level narratives? In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 17659--17681, Miami, ...
-
[25]
Ziqi Wang, Chen Zhu, Zhi Zheng, Xinhang Li, Tong Xu, Yongyi He, Qi Liu, Ying Yu, and Enhong Chen. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.183 Granular entity mapper: Advancing fine-grained multimodal named entity recognition and grounding . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 3211--3226, Miami, Flo...
-
[26]
Maurice Weber, Daniel Fu, Quentin Anthony, Yonatan Oren, Shane Adams, Anton Alexandrov, Xiaozhong Lyu, Huu Nguyen, Xiaozhe Yao, Virginia Adams, Ben Athiwaratkun, Rahul Chalamala, Kezhen Chen, Max Ryabinin, Tri Dao, Percy Liang, Christopher Ré, Irina Rish, and Ce Zhang. 2024. https://arxiv.org/abs/2411.12372 Redpajama: an open dataset for training large la...
arXiv 2024
-
[27]
Kevin Yang, Yuandong Tian, Nanyun Peng, and Dan Klein. 2022. https://doi.org/10.18653/v1/2022.emnlp-main.296 Re3: Generating longer stories with recursive reprompting and revision . In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 4393--4479, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics
-
[29]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[30]
Publications Manual , year = "1983", publisher =
1983
-
[31]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[32]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[33]
Dan Gusfield , title =. 1997
1997
-
[34]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[35]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[36]
Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence,
Automatic Noisy Label Correction for Fine-Grained Entity Typing , author =. Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence,. 2022 , month =. doi:10.24963/ijcai.2022/599 , url =
-
[37]
2023 , eprint=
TinyStories: How Small Can Language Models Be and Still Speak Coherent English? , author=. 2023 , eprint=
2023
-
[38]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Fine-Grained Entity Recognition , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2021 , month=. doi:10.1609/aaai.v26i1.8122 , abstractNote=
-
[39]
2016 , eprint=
Context-Dependent Fine-Grained Entity Type Tagging , author=. 2016 , eprint=
2016
-
[40]
2025 , eprint=
Evaluating Creative Short Story Generation in Humans and Large Language Models , author=. 2025 , eprint=
2025
-
[41]
ArXiv , year=
Context-Dependent Fine-Grained Entity Type Tagging , author=. ArXiv , year=
-
[42]
doi:10.1016/j.heliyon.2024.e34262 Pamela Tierney and Steven M
Xiaoyi Tang and Hongwei Chen and Daoyu Lin and Kexin Li , keywords =. Harnessing LLMs for multi-dimensional writing assessment: Reliability and alignment with human judgments , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.heliyon.2024.e34262 , url =
-
[43]
2014 , publisher=
Handbook of Inter-Rater Reliability, 4th Edition: The Definitive Guide to Measuring The Extent of Agreement Among Raters , author=. 2014 , publisher=
2014
-
[44]
ECML/PKDD , year=
Modeling Relations and Their Mentions without Labeled Text , author=. ECML/PKDD , year=
-
[45]
Dan Gillick and Nevena Lazic and Kuzman Ganchev and Jesse Kirchner and David Huynh , title =. CoRR , volume =. 2014 , url =. 1412.1820 , timestamp =
Pith/arXiv arXiv 2014
-
[46]
Zemel and Ruslan Salakhutdinov and Raquel Urtasun and Antonio Torralba and Sanja Fidler , title =
Yukun Zhu and Ryan Kiros and Richard S. Zemel and Ruslan Salakhutdinov and Raquel Urtasun and Antonio Torralba and Sanja Fidler , title =. CoRR , volume =. 2015 , url =. 1506.06724 , timestamp =
Pith/arXiv arXiv 2015
-
[47]
Liu , title =
Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu , title =. Journal of Machine Learning Research , year =
-
[48]
2024 , eprint=
RedPajama: an Open Dataset for Training Large Language Models , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.