DOA: Training-Free Decoder-Only Attention Policy for Long-Form Simultaneous Translation with SpeechLLMs
Pith reviewed 2026-06-28 22:14 UTC · model grok-4.3
The pith
Decoder self-attention in SpeechLLMs supplies stable alignment signals for training-free long-form simultaneous translation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
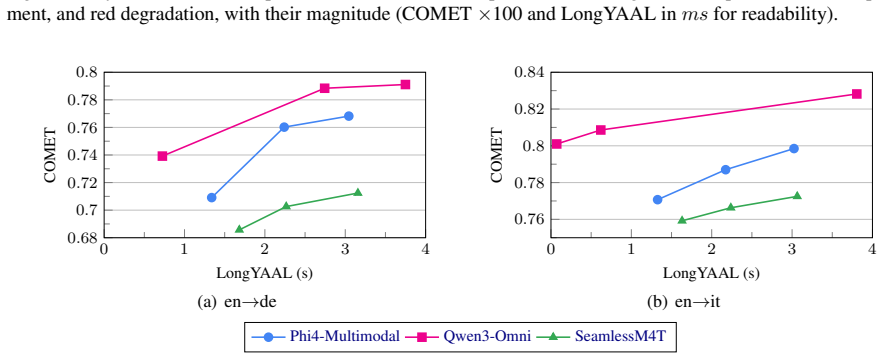
Decoder self-attention in off-the-shelf SpeechLLMs contains alignment signals stable enough to guide a streaming policy, so the Decoder-Only Attention (DOA) method enables effective long-form simultaneous speech-to-text translation at quality close to offline decoding without any retraining or architectural changes.
What carries the argument
Decoder-Only Attention (DOA), a training-free policy that derives a proxy alignment signal from decoder self-attention to inform read/write streaming decisions.
If this is right
- Off-the-shelf SpeechLLMs can be applied to simultaneous translation without any model adaptation.
- Long-form inputs can be handled with low latency while translation quality stays close to offline results.
- Separate training for streaming policies or reliance on wait-k heuristics becomes unnecessary.
- The same self-attention patterns support streaming decisions across different tested SpeechLLM architectures.
Where Pith is reading between the lines
- If the alignment signal holds across more models, DOA could apply to other decoder-only language models for streaming tasks beyond translation.
- Testing on audio longer than the evaluated cases would show where self-attention stability begins to degrade.
- The policy might integrate into existing speech pipelines to lower the barrier for real-time multilingual applications.
Load-bearing premise
Decoder self-attention in off-the-shelf SpeechLLMs contains sufficiently stable alignment signals to guide the streaming policy in long-form settings.
What would settle it
An experiment showing that self-attention alignments become inconsistent or produce high-latency or low-quality outputs on long-form audio would falsify the claim that DOA supplies an effective alignment signal.
Figures
read the original abstract
Simultaneous speech-to-text translation (SimulST) generates translations while speech is still unfolding, requiring a streaming policy that decides when to read and when to write. State-of-the-art approaches rely on attention-based encoder-decoder models where cross-attention provides explicit alignment signals. In contrast, Speech Large Language Models (SpeechLLMs) are decoder-only architectures relying solely on self-attention. This raises a central question: whether decoder self-attention contains sufficiently stable alignment signals to guide the streaming policy. Moreover, existing approaches typically rely on training-based adaptations or heuristic wait-$k$ policies and have not been validated in long-form settings. To fill these gaps, we propose Decoder-Only Attention (DOA), a training-free policy that enables long-form simultaneous translation with off-the-shelf SpeechLLMs by deriving a proxy alignment from self-attention. Experiments on Phi4-Multimodal and Qwen3-Omni show that DOA provides an effective alignment signal for supporting streaming decisions, enabling low-latency long-form SimulST with quality close to offline decoding without retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Decoder-Only Attention (DOA), a training-free streaming policy for long-form simultaneous speech-to-text translation (SimulST) with decoder-only SpeechLLMs. It extracts a proxy alignment signal directly from the model's self-attention weights to decide read/write actions during streaming, addressing the absence of explicit cross-attention in these architectures. Experiments on Phi4-Multimodal and Qwen3-Omni are reported to show that DOA supports low-latency long-form SimulST with quality approaching offline decoding, without any model retraining or adaptation.
Significance. If the central result holds, the work would be significant for enabling practical simultaneous translation with existing decoder-only SpeechLLMs in long-form settings. The training-free derivation from internal self-attention avoids the cost of training-based policies or encoder-decoder retraining, and the focus on long-form validation fills a noted gap in prior SimulST literature. Explicit credit is due for the parameter-free construction and the use of off-the-shelf models.
major comments (2)
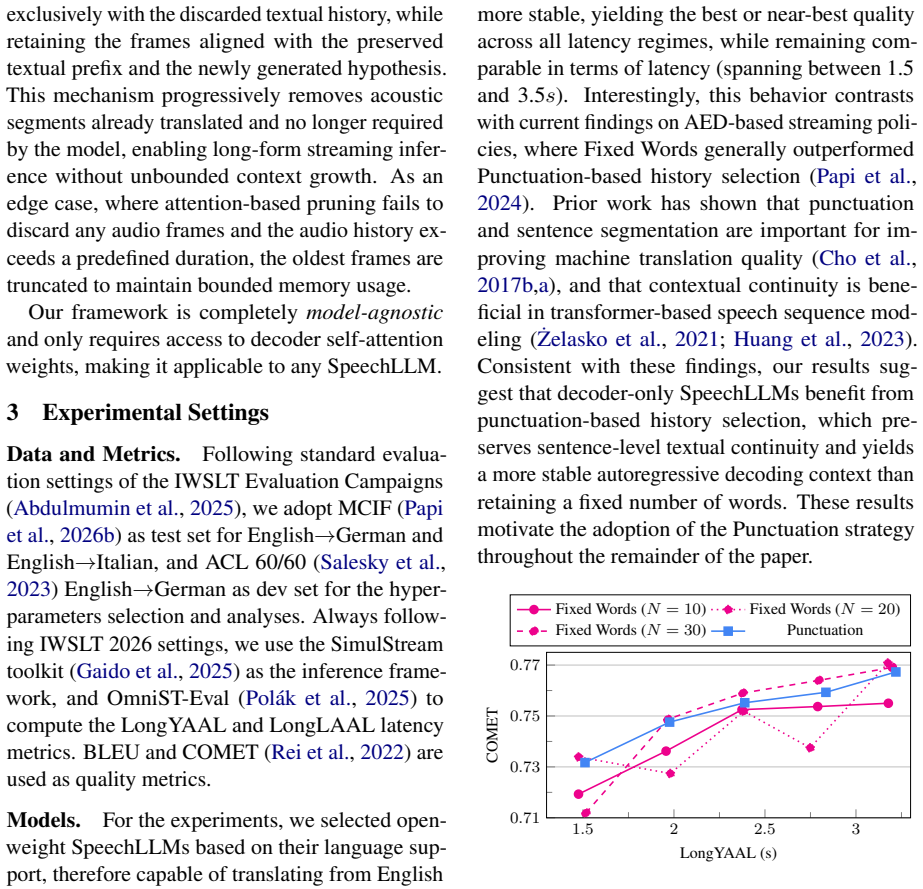
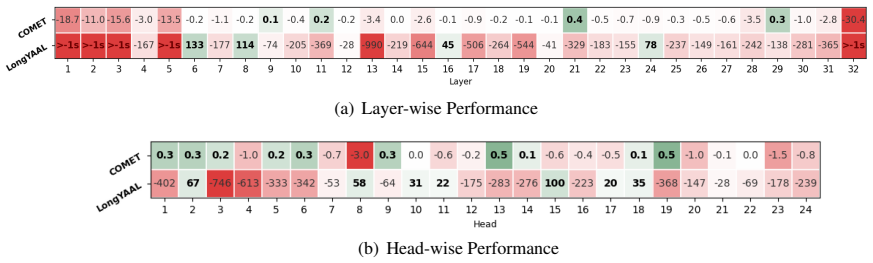
- [Abstract / method] Abstract and method description: the headline claim that DOA yields quality close to offline decoding rests on the assumption that decoder self-attention supplies a sufficiently stable alignment proxy as speech input length grows. No quantitative evidence (e.g., attention entropy, focus metrics, or position-bias analysis over increasing context lengths) is referenced to confirm that the weights remain cross-modally focused rather than diffuse or position-biased, which directly risks the reported latency-quality trade-off.
- [Experiments] Experiments: the results on Phi4-Multimodal and Qwen3-Omni are presented as validating the policy, yet without reported ablations isolating the contribution of the self-attention-derived signal versus heuristic baselines or without length-stratified quality/latency curves, it is impossible to confirm that the alignment signal remains load-bearing for the long-form claim rather than an artifact of shorter contexts.
minor comments (2)
- [Method] The exact extraction formula for the proxy alignment from self-attention weights should be stated as an equation rather than described at high level to allow reproduction.
- [Related work] Add explicit comparison to recent training-free or wait-k baselines in the related-work section to situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract / method] Abstract and method description: the headline claim that DOA yields quality close to offline decoding rests on the assumption that decoder self-attention supplies a sufficiently stable alignment proxy as speech input length grows. No quantitative evidence (e.g., attention entropy, focus metrics, or position-bias analysis over increasing context lengths) is referenced to confirm that the weights remain cross-modally focused rather than diffuse or position-biased, which directly risks the reported latency-quality trade-off.
Authors: We agree that explicit quantitative metrics on attention stability would strengthen the central claim. In the revised manuscript we will add attention entropy, focus, and position-bias analyses computed over increasing context lengths on the evaluated models to demonstrate that self-attention remains cross-modally focused rather than diffuse. revision: yes
-
Referee: [Experiments] Experiments: the results on Phi4-Multimodal and Qwen3-Omni are presented as validating the policy, yet without reported ablations isolating the contribution of the self-attention-derived signal versus heuristic baselines or without length-stratified quality/latency curves, it is impossible to confirm that the alignment signal remains load-bearing for the long-form claim rather than an artifact of shorter contexts.
Authors: We concur that isolating the contribution of the DOA signal and providing length-stratified results are necessary to support the long-form claims. We will add ablations against standard heuristic baselines (including wait-k) together with quality and latency curves stratified by input length in the revised experiments section. revision: yes
Circularity Check
No circularity: training-free extraction from existing model internals
full rationale
The paper's core contribution is a training-free policy (DOA) that derives a proxy alignment signal directly from the self-attention weights already present in off-the-shelf decoder-only SpeechLLMs. No parameters are fitted to target data, no predictions are made from subsets of the same data, and no load-bearing uniqueness theorem or ansatz is imported via self-citation. The central assumption (that self-attention yields usable alignment) is stated explicitly as the open question the experiments address rather than being smuggled in by definition or prior author work. The derivation chain therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
From simultaneous to streaming machine translation by leveraging streaming history. InPro- ceedings of the 60th Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 6972–6985, Dublin, Ireland. Associa- tion for Computational Linguistics. Javier Iranzo-Sánchez, Jorge Iranzo-Sánchez, Adrià Giménez, Jorge Civera, a...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Siqi Ouyang, Xi Xu, and Lei Li
Fasst: Fast llm-based simultaneous speech translation.arXiv preprint arXiv:2408.09430. Siqi Ouyang, Xi Xu, and Lei Li. 2025. InfiniSST: Si- multaneous translation of unbounded speech with large language model. InFindings of the Associa- tion for Computational Linguistics: ACL 2025, pages 3032–3046, Vienna, Austria. Association for Compu- tational Linguist...
-
[3]
arXiv preprint arXiv:2308.11596 , year=
COMET-22: Unbabel-IST 2022 submission for the metrics shared task. InProceedings of the Seventh Conference on Machine Translation (WMT), pages 578–585, Abu Dhabi, United Arab Emirates (Hybrid). Association for Computational Linguistics. Elizabeth Salesky, Kareem Darwish, Mohamed Al- Badrashiny, Mona Diab, and Jan Niehues. 2023. Evaluating multilingual spe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.