RESOURCE2SKILL: Distilling Executable Agent Skills from Human-Created Multimodal Resources
Pith reviewed 2026-06-30 02:11 UTC · model grok-4.3
The pith
RESOURCE2SKILL turns multimodal human resources into a Skill Wiki that agents retrieve and compose to raise task scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
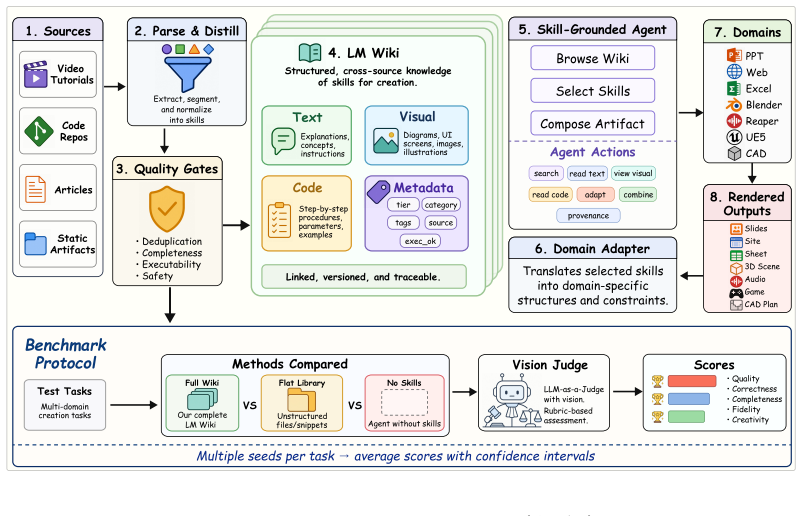
RESOURCE2SKILL distills multimodal resources into a hierarchical multimodal Skill Wiki in which each entry combines structured text, code, visual examples, metadata, and provenance. Videos supply temporal operations and visual effects, code supplies executable tool patterns, and articles or artifacts supply conceptual and stylistic grounding. At inference time agents retrieve and compose relevant entries; when coverage is insufficient the same operator acquires new skills online. Across seven practical authoring domains this yields an average overall score gain of 11.9 percentage points over no-skill agents and outperforms strong harness baselines in 26 of 28 main-aggregate model-domain cell
What carries the argument
The hierarchical multimodal Skill Wiki, which stores distilled skills so agents can retrieve, compose, and extend them while preserving signals from videos, code, and articles.
If this is right
- Agents gain access to procedural knowledge already present in public tutorials rather than requiring new hand-written libraries.
- Multimodal skill entries outperform single-modality versions because they retain temporal, executable, and conceptual information together.
- Hierarchical organization plus online acquisition lets the skill collection grow dynamically without manual curation.
- Performance gains appear consistently across multiple models and domains, indicating the method is not limited to one task type.
- Ablations isolate the contribution of each design choice: multimodal format, hierarchy, source diversity, selection, and online acquisition.
Where Pith is reading between the lines
- The same distillation pipeline could be applied to non-authoring domains such as web navigation or scientific workflow construction.
- Because each skill carries provenance, downstream systems could audit or update individual entries when source resources change.
- If retrieval quality scales with wiki size, larger public corpora of tutorials would produce proportionally larger agent gains.
- The online acquisition step suggests a hybrid loop in which agents both use and expand the wiki during deployment.
Load-bearing premise
Complementary signals from videos, code, and articles survive the conversion into Skill Wiki entries and agents can reliably select and combine the right skills at runtime, including successful online acquisition.
What would settle it
An experiment in which agents equipped with the Skill Wiki show no improvement over no-skill agents or text-only baselines on the same seven authoring domains would falsify the central claim.
Figures

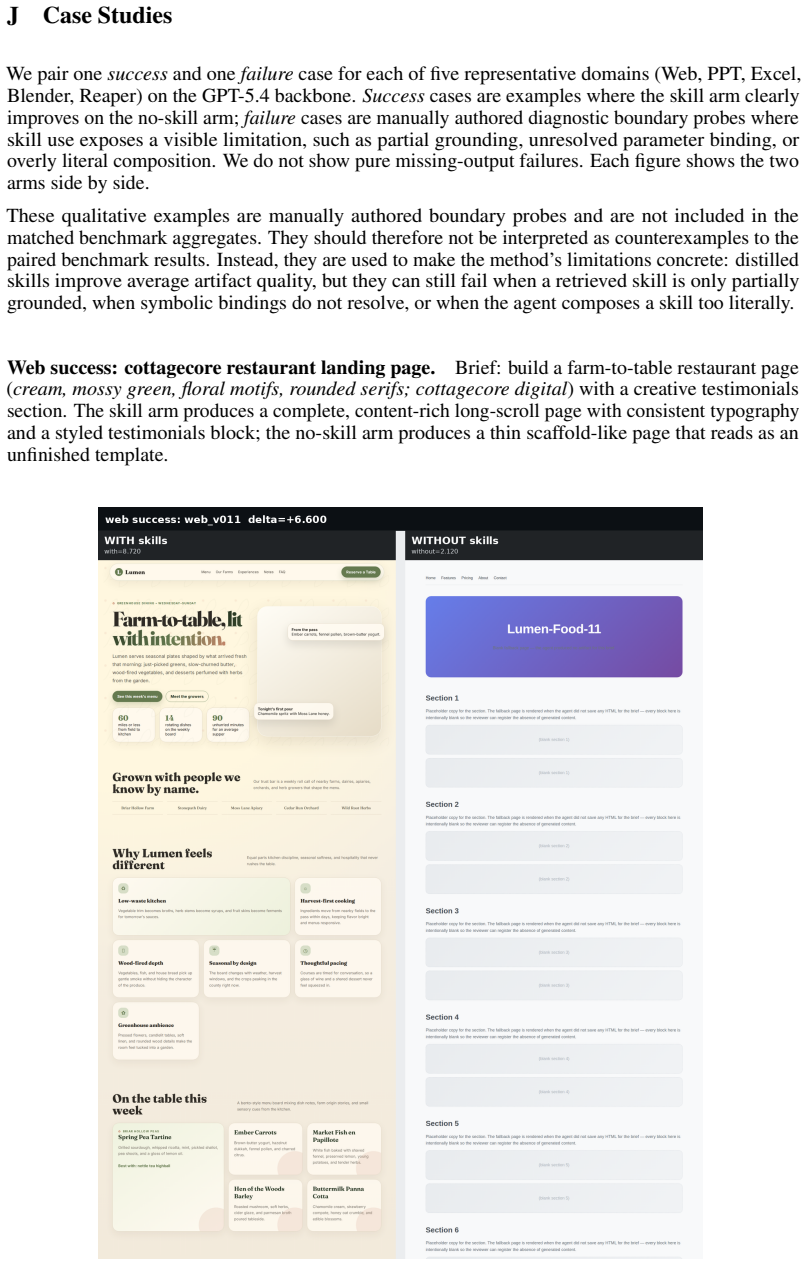
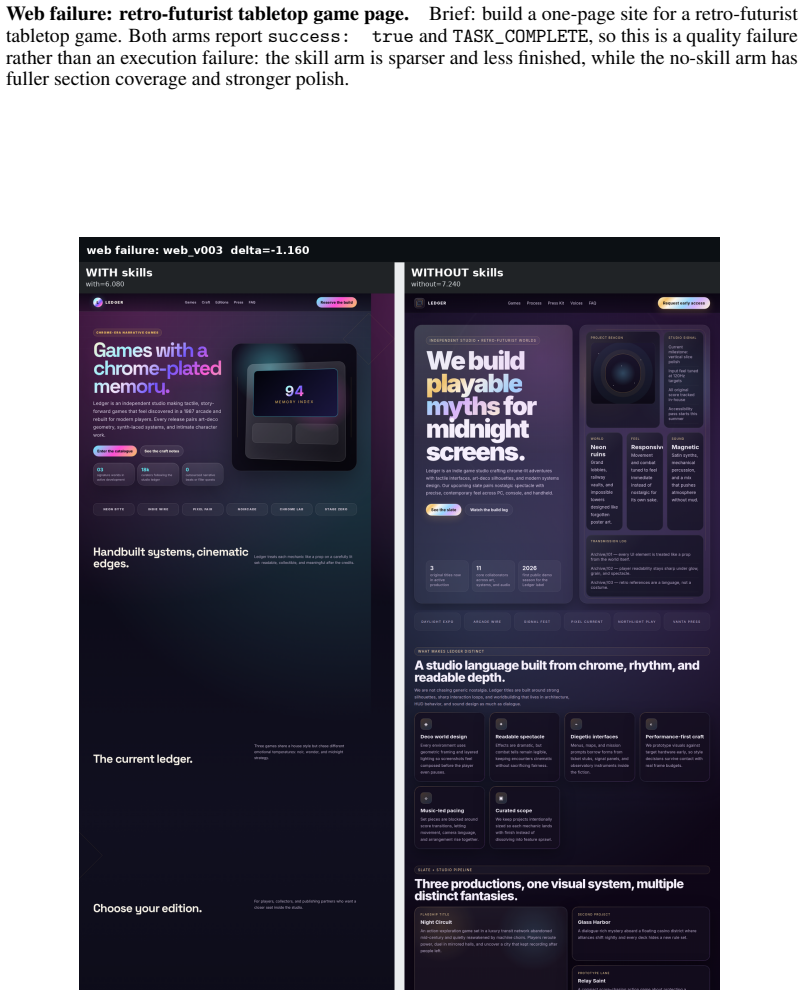
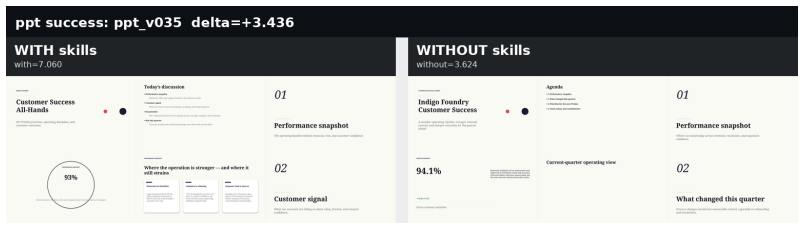





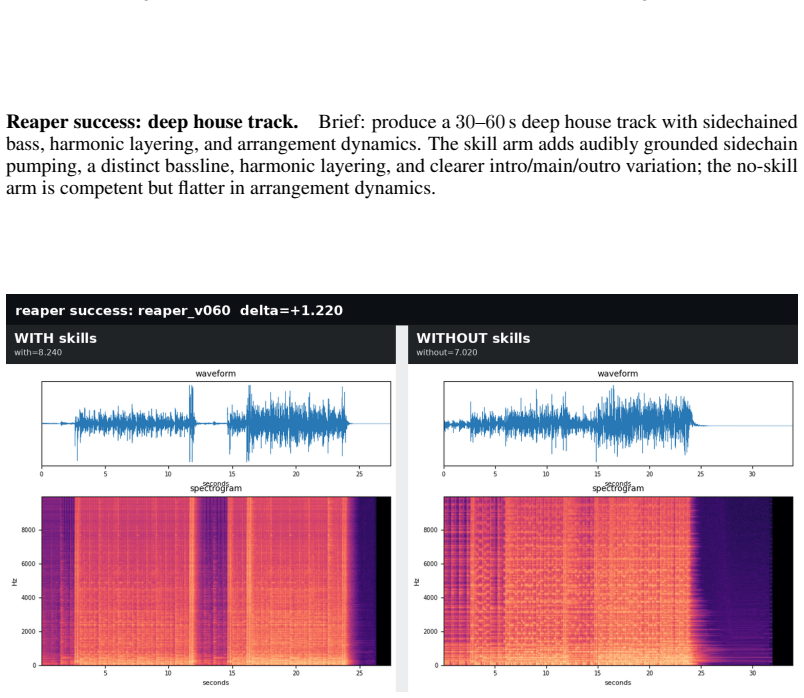
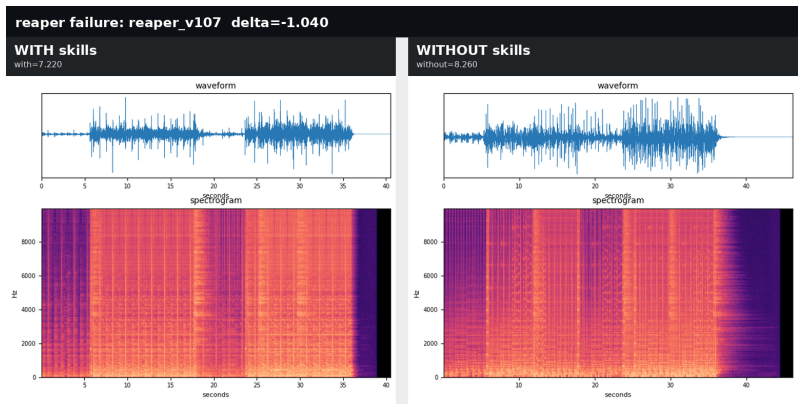
read the original abstract
Skills are a useful abstraction for software agents, turning human and agent experience into reusable procedural knowledge. Yet existing skill libraries are mostly hand-written, text-centric, or derived from agent traces, leaving tutorial videos and other multimodal human resources largely underused. We present RESOURCE2SKILL, a framework that distills multimodal resources, including tutorial videos, repositories, articles, and reference artifacts, into executable skills for software agents. RESOURCE2SKILL organizes these skills as a hierarchical multimodal Skill Wiki, where each entry combines structured text, code, visual examples, metadata, and provenance. This design preserves complementary signals from different resources: videos capture temporal operations and visual effects, code captures executable tool patterns, and articles or artifacts provide conceptual and stylistic grounding. At inference time, agents retrieve and compose relevant skills from the wiki; when coverage is insufficient, the same construction operator can acquire new skills online. Across seven practical authoring domains, RESOURCE2SKILL improves average overall score by +11.9 percentage points over no-skill agents and outperforms strong harness baselines in 26 of 28 main-aggregate model-domain cells. Ablations confirm the value of multimodal skill format, hierarchical organization, source diversity, selection strategy, and online acquisition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RESOURCE2SKILL, a framework for distilling multimodal human resources (tutorial videos, repositories, articles, reference artifacts) into executable skills stored in a hierarchical multimodal Skill Wiki. At inference, agents retrieve and compose skills from the wiki, with an online acquisition operator for uncovered cases. The central empirical claim is an average +11.9 percentage point improvement in overall score over no-skill agents across seven authoring domains, plus outperformance of strong harness baselines in 26 of 28 model-domain cells, supported by ablations on multimodal format, hierarchy, source diversity, selection, and online acquisition.
Significance. If the reported gains and ablations prove reproducible, the work would be significant for agent skill libraries by showing how to systematically exploit underused multimodal human resources rather than relying on hand-written text or agent traces alone. The hierarchical wiki plus online acquisition mechanism offers a concrete path toward more scalable procedural knowledge for software agents.
major comments (2)
- [Experimental Evaluation] Experimental Evaluation section: the manuscript reports concrete aggregate numbers (+11.9 pp, 26/28 cells) and five ablations, yet supplies no description of the seven authoring domains, the precise definition and computation of the 'overall score', the implementation of the 'strong harness baselines', the models and prompting setups, the number of trials per cell, or any statistical tests. Without these details the central performance claim cannot be evaluated or replicated.
- [Skill Wiki Construction and Inference] § on Skill Wiki and inference-time retrieval: the framework's utility rests on the assumption that complementary signals from video, code, and text are preserved in the wiki entries and that retrieval/composition (plus online acquisition) succeeds reliably. The paper provides no failure-case analysis, coverage statistics, or retrieval-error breakdown showing when this assumption holds or breaks, which is load-bearing for the practical claim.
minor comments (1)
- [Abstract] Abstract: the phrase 'strong harness baselines' is undefined; a one-sentence gloss would improve readability even at the abstract level.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of RESOURCE2SKILL. We address each major comment below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental Evaluation section: the manuscript reports concrete aggregate numbers (+11.9 pp, 26/28 cells) and five ablations, yet supplies no description of the seven authoring domains, the precise definition and computation of the 'overall score', the implementation of the 'strong harness baselines', the models and prompting setups, the number of trials per cell, or any statistical tests. Without these details the central performance claim cannot be evaluated or replicated.
Authors: We agree that additional detail is required for reproducibility. In the revised manuscript we will expand the Experimental Evaluation section to describe the seven authoring domains, provide the precise definition and computation of the overall score, detail the implementation of the strong harness baselines, specify the models and prompting setups, report the number of trials per cell, and include any statistical tests performed. revision: yes
-
Referee: [Skill Wiki Construction and Inference] § on Skill Wiki and inference-time retrieval: the framework's utility rests on the assumption that complementary signals from video, code, and text are preserved in the wiki entries and that retrieval/composition (plus online acquisition) succeeds reliably. The paper provides no failure-case analysis, coverage statistics, or retrieval-error breakdown showing when this assumption holds or breaks, which is load-bearing for the practical claim.
Authors: We acknowledge the absence of dedicated failure-case analysis and retrieval-error statistics. In the revision we will add a new subsection that reports coverage statistics, provides a retrieval-error breakdown drawn from our experiments, and discusses cases where the multimodal preservation and retrieval assumptions hold or break, including how the online acquisition operator addresses uncovered instances. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical framework for distilling multimodal resources into a hierarchical Skill Wiki and reports concrete experimental gains (+11.9 pp average improvement, 26/28 cells) across domains, supported by ablations on format, hierarchy, diversity, selection, and online acquisition. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the provided text; the central claims rest on external experimental outcomes rather than any derivation that reduces to its own inputs by construction. The work is self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. CodeSearchNet challenge: Evaluating the state of semantic code search.arXiv preprint arXiv:1909.09436,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[3]
Eyal Karpas, Omri Abend, Yonatan Belinkov, Barak Lenz, Opher Lieber, Nir Ratner, Yoav Shoham, Heureux Bata, Yoav Levine, Kevin Leyton-Brown, Dor Muhlgay, Paul Roit, David Schwartz, Gal Shachaf, Shai Shalev-Shwartz, Amnon Shashua, and Moshe Tenenholtz. MRKL systems: A modular, neuro-symbolic architecture that combines large language models, external knowle...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 6769–6781,
2020
-
[5]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianhua Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. AgentBench: Evaluating LLMs as agents.arXiv preprint arXiv:2308.03688,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
URL https://arxiv.org/abs/2503.21460. Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Sean Welleck, Bodhisattwa Prasad Majumder, Shashank Gupta, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback. InAdvances in Neural Informa...
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. WebGPT: Browser-assisted question-answering with human feedback.arXiv preprint arXiv...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Vivian Fang, Shishir G. Patil, Kevin Lin, Sarah Wooders, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. Gorilla: Large language model connected with massive APIs.arXiv preprint arXiv:2305.15334,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
SKILLFOUNDRY: Building Self-Evolving Agent Skill Libraries from Heterogeneous Scientific Resources
Shuaike Shen, Wenduo Cheng, Mingqian Ma, Alistair Turcan, Martin Jinye Zhang, and Jian Ma. SkillFoundry: Building self-evolving agent skill libraries from heterogeneous scientific resources. arXiv preprint arXiv:2604.03964,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. Transactions on Machine Learning Research (TMLR), 2024a. Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory.arXiv preprint arXiv:2409.07429, 202...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
URLhttps://arxiv.org/abs/2602.12430. John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent–computer interfaces enable automated software engineering. InAdvances in Neural Information Processing Systems (NeurIPS),
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
SkillFlow:Benchmarking Lifelong Skill Discovery and Evolution for Autonomous Agents
Ziao Zhang, Kou Shi, Shiting Huang, Avery Nie, Yu Zeng, Yiming Zhao, Zhen Fang, Qisheng Su, et al. SkillFlow: Benchmarking lifelong skill discovery and evolution for autonomous agents. arXiv preprint arXiv:2604.17308,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.