CrypFormBench: Benchmarking Formal Analysis Capability of Large Language Models for Cryptographic Schemes
Pith reviewed 2026-06-25 20:49 UTC · model grok-4.3
The pith
Large language models have limited capability for formal analysis of cryptographic schemes, performing well on interpretation but struggling with generation, transformation, and correction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
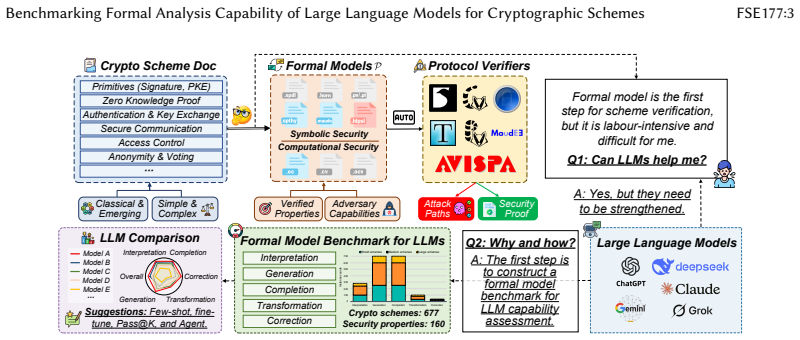
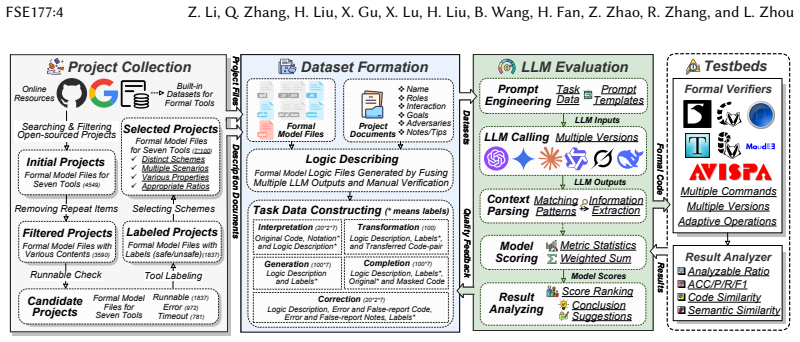
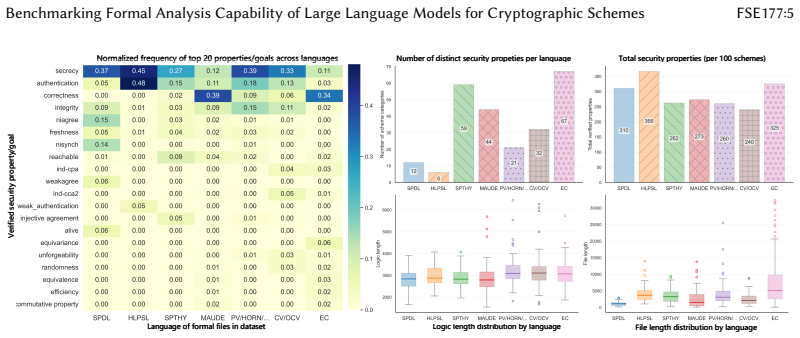
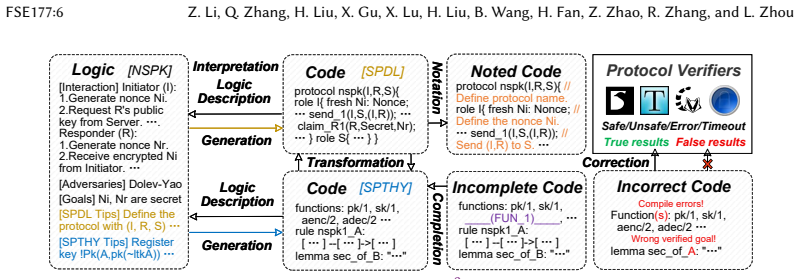
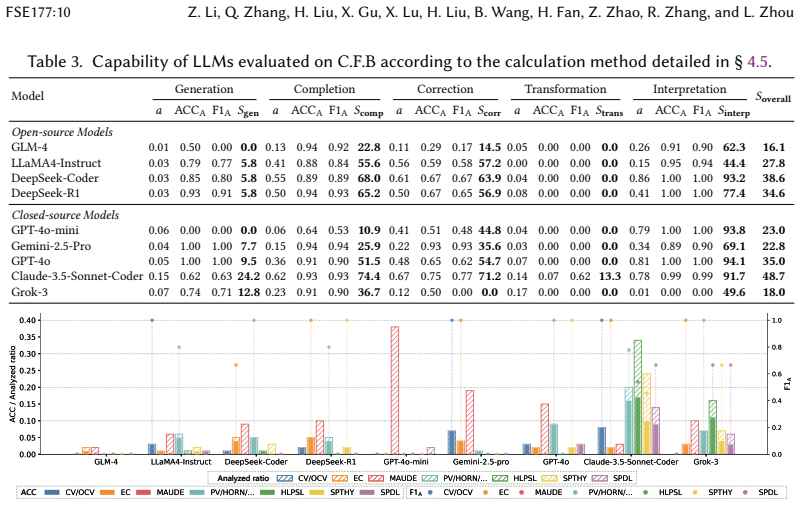
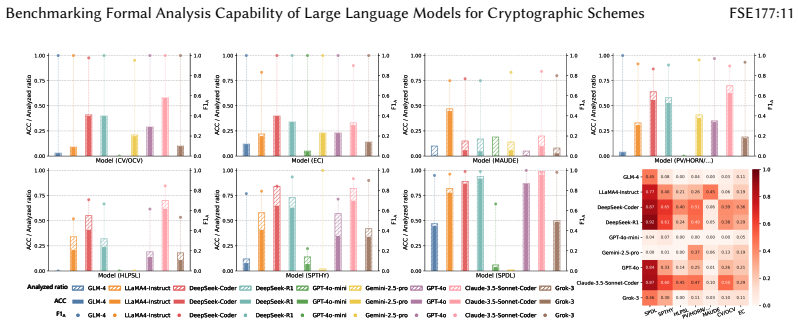
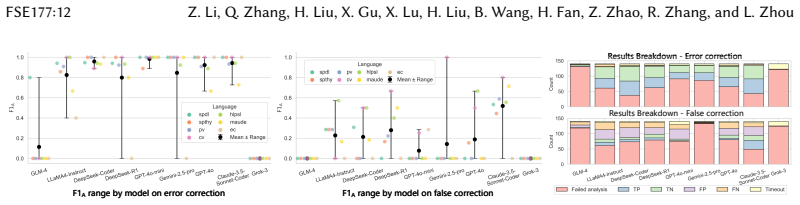
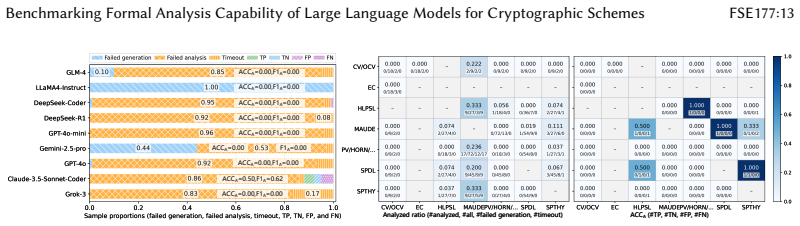
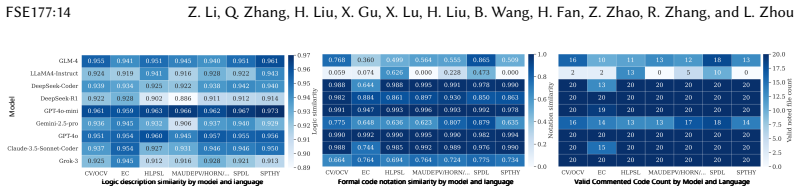
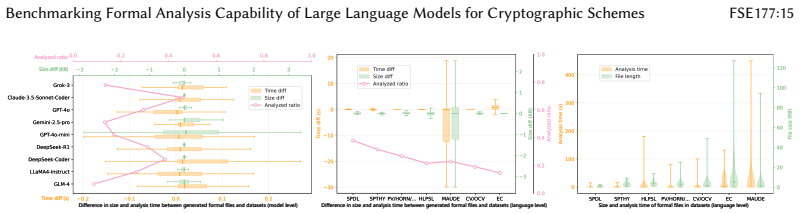
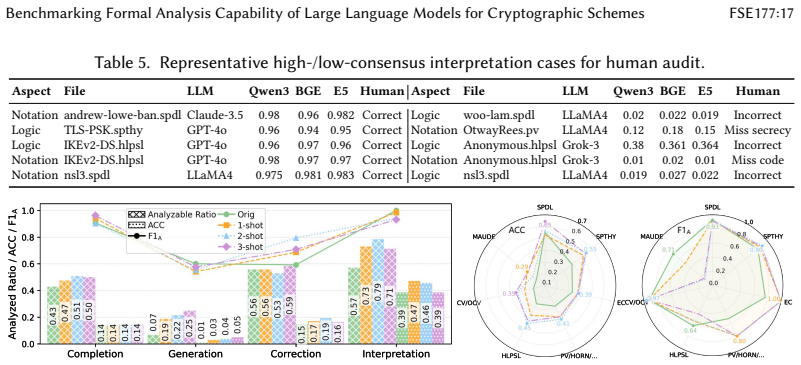
CrypFormBench is introduced as a comprehensive benchmark with 700 instances from 677 schemes in 7 formal languages and 160 security properties to measure LLM performance on formal cryptographic analysis tasks. The evaluation demonstrates that LLMs' effectiveness remains limited, with particular difficulties in generation, transformation, and correction despite strengths in interpretation and completion.
What carries the argument
CrypFormBench, a benchmark jointly covering symbolic and computational security to evaluate five core LLM capabilities in formal analysis of cryptographic schemes.
If this is right
- LLMs can be used to assist experts in interpreting and completing formal specifications of cryptographic schemes.
- Few-shot prompting, Pass@K sampling, and lightweight fine-tuning can help mitigate issues with producing executable formal outputs.
- The benchmark enables standardized tracking of improvements in LLM capabilities for this domain.
- Overall performance limitations indicate that full automation of formal analysis is not yet achievable.
Where Pith is reading between the lines
- Improved LLM performance on these tasks could reduce the expertise required for formal verification of crypto protocols.
- The benchmark could serve as a foundation for developing specialized models or tools for security analysis.
- Connections to other formal methods domains might reveal similar capability patterns in LLMs.
Load-bearing premise
The 700 instances in the benchmark form a representative sample of the labor-intensive manual formal analysis tasks performed by experts.
What would settle it
A follow-up evaluation using a new set of formal analysis instances outside the benchmark that yields markedly different performance results for the tested LLMs.
Figures

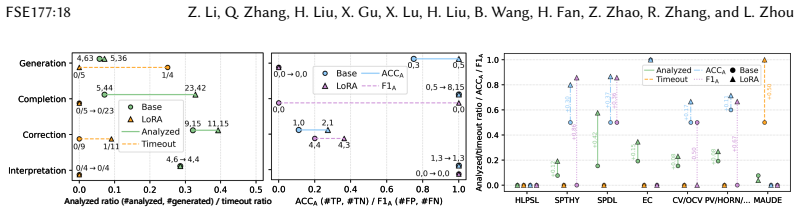
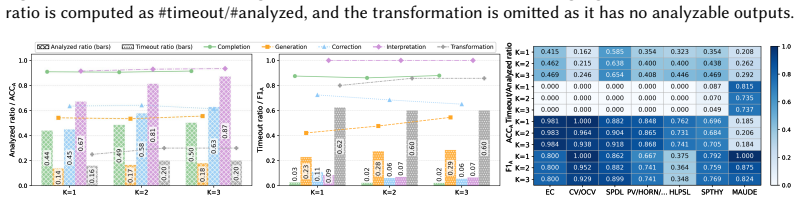
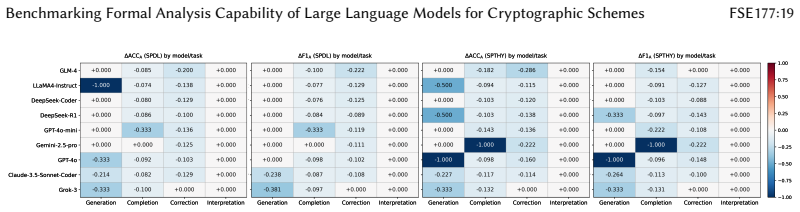
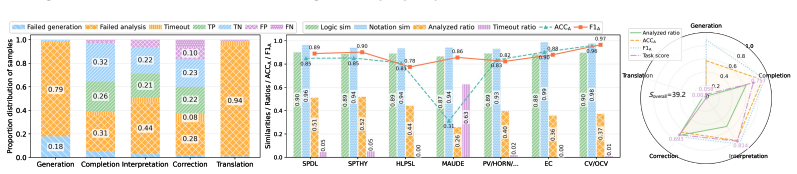
read the original abstract
Manual formal analysis of cryptographic schemes is labor-intensive and requires substantial expertise. While model-checking tools (e.g., Scyther and Tamarin) and computational-security tools (e.g., CryptoVerif and EasyCrypt) improve the automation of security proofs, they still rely on experts to abstract schemes and write tool-specific formal descriptions. Large language models (LLMs) are a promising alternative, but their effectiveness in this domain remains unexplored due to the absence of standardized evaluation methodologies. To fill this gap, we introduce CrypFormBench (C.F.B for short), a comprehensive benchmark jointly covering symbolic and computational security to evaluate five core LLM capabilities: interpretation, generation, completion, transformation, and correction. It comprises 700 instances spanning 677 schemes, 7 mainstream formal verifier languages, and 160 security properties. The evaluation of 9 state-of-the-art LLMs reveals that most of them perform well on interpretation and completion, given their code-awareness advantages, but struggle with generation, transformation, and correction. Overall, their performance remains limited, with Claude-3.5 achieving the highest score at 48.7 out of 100. We further provide practical guidance, e.g., few-shot prompting, Pass@K sampling, and lightweight fine-tuning, to mitigate the executability bottleneck and improve tool-usable outputs. Taken together, our benchmark and analyses offer a grounded view of current progress and concrete directions toward reliable LLM-assisted formal cryptographic analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
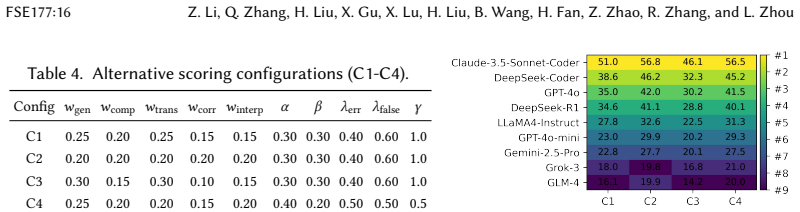
Summary. The paper introduces CrypFormBench, a benchmark with 700 instances spanning 677 cryptographic schemes, 7 formal verifier languages, and 160 security properties, to evaluate LLMs on five core capabilities (interpretation, generation, completion, transformation, correction) for formal analysis of cryptographic schemes. It reports an evaluation of 9 state-of-the-art LLMs, finding stronger performance on interpretation and completion but struggles on generation, transformation, and correction, with Claude-3.5 achieving the highest overall score of 48.7/100, and provides guidance on prompting and fine-tuning to improve outputs.
Significance. If the benchmark construction and evaluation are shown to be rigorous and representative, the work would offer the first standardized methodology for assessing LLM assistance in labor-intensive cryptographic formal analysis tasks, bridging symbolic and computational security approaches and identifying concrete limitations and mitigation strategies.
major comments (2)
- [Benchmark construction] Benchmark construction (likely §3): The manuscript provides no details on instance curation process, expert validation of ground truth, sampling strategy across scheme classes or security properties, or inter-rater agreement on task difficulty or correctness. This directly undermines the central claim that the observed performance gaps (e.g., struggles with generation/transformation/correction) reflect intrinsic model limitations rather than benchmark artifacts, as the representativeness of the 700 instances as a sample of expert tasks remains unverified.
- [Evaluation methodology] Evaluation methodology (likely §4): No information is supplied on scoring rubrics for the five capabilities, controls for prompt sensitivity, inter-annotator agreement for automated or manual scoring, or how executability of outputs was assessed against the 7 verifier languages. Without these, the headline scores (including 48.7/100) cannot be independently verified or reproduced, making the performance comparison across models load-bearing but unsupported.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater transparency in benchmark construction and evaluation methodology. We agree these details are essential for supporting our claims and will revise the manuscript to address both points.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction (likely §3): The manuscript provides no details on instance curation process, expert validation of ground truth, sampling strategy across scheme classes or security properties, or inter-rater agreement on task difficulty or correctness. This directly undermines the central claim that the observed performance gaps (e.g., struggles with generation/transformation/correction) reflect intrinsic model limitations rather than benchmark artifacts, as the representativeness of the 700 instances as a sample of expert tasks remains unverified.
Authors: We acknowledge that the current manuscript omits explicit details on these aspects of benchmark construction. In the revised version, we will add a new subsection to §3 describing the curation process: instances were drawn from published cryptographic literature and public formal verification repositories; ground truth was validated by domain experts in cryptography and formal methods; sampling was stratified to ensure coverage across scheme classes (encryption, signatures, key exchange, protocols) and the 160 security properties; and inter-rater agreement was measured on a 10% subset using Cohen's kappa for both correctness and difficulty ratings. These additions will directly support the representativeness of the benchmark. revision: yes
-
Referee: [Evaluation methodology] Evaluation methodology (likely §4): No information is supplied on scoring rubrics for the five capabilities, controls for prompt sensitivity, inter-annotator agreement for automated or manual scoring, or how executability of outputs was assessed against the 7 verifier languages. Without these, the headline scores (including 48.7/100) cannot be independently verified or reproduced, making the performance comparison across models load-bearing but unsupported.
Authors: We agree the evaluation methodology section lacks necessary detail. The revised §4 will include: explicit scoring rubrics for each capability with examples of full, partial, and zero credit; controls for prompt sensitivity via fixed templates and temperature settings with results from multiple prompt variants; inter-annotator agreement statistics (Cohen's kappa) for the manual scoring component performed by two independent annotators; and the precise executability assessment procedure, including automated compilation and verification commands used for each of the 7 languages together with success/failure criteria. These changes will make the reported scores reproducible. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation is self-contained
full rationale
The paper constructs CrypFormBench and reports measured LLM performance scores on its 700 instances. No equations, fitted parameters, predictions, or derivations appear in the abstract or described content. The central results (e.g., Claude-3.5 at 48.7/100, relative strengths on interpretation vs. generation) are direct empirical measurements on externally defined tasks, not reductions to the authors' inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the benchmark or scores. Representativeness concerns affect validity but do not create circularity under the specified criteria.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 700 instances across 677 schemes and 160 properties are representative of real manual formal analysis work.
invented entities (1)
-
CrypFormBench
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Nada AlMarwani and Mona T. Diab. 2021. Discrete Cosine Transform as Universal Sentence Encoder. In ACL/IJCNLP (2). Association for Computational Linguistics, 419–426. doi:10.18653/V1/2021.ACL-SHORT.53
-
[2]
Uri Alon, Shaked Brody, Omer Levy, and Eran Yahav. 2019. code2seq: Generating Sequences from Structured Repre- sentations of Code. In ICLR (Poster). OpenReview.net
2019
-
[3]
Anthropic. 2024. Claude 3.5 Sonnet. https://www.anthropic.com/news/claude-3-5-sonnet
2024
-
[4]
Alessandro Armando, David A. Basin, Yohan Boichut, Yannick Chevalier, Luca Compagna, Jorge Cuéllar, Paul Hankes Drielsma, Pierre-Cyrille Héam, Olga Kouchnarenko, Jacopo Mantovani, Sebastian Mödersheim, David von Oheimb, Michaël Rusinowitch, Judson Santiago, Mathieu Turuani, Luca Viganò, and Laurent Vigneron. 2005. The AVISPA Tool for the Automated Validat...
-
[5]
Matteo Avalle, Alfredo Pironti, and Riccardo Sisto. 2014. Formal verification of security protocol implementations: a survey. Formal Aspects Comput. 26, 1 (2014), 99–123. doi:10.1007/S00165-012-0269-9
-
[6]
Ayers, Dragomir Radev, and Jeremy Avigad
Zhangir Azerbayev, Bartosz Piotrowski, Hailey Schoelkopf, Edward W. Ayers, Dragomir Radev, and Jeremy Avigad
-
[7]
ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics. CoRR abs/2302.12433 (2023). doi:10.48550/ARXIV.2302.12433
-
[8]
Manuel Barbosa, Gilles Barthe, Karthik Bhargavan, Bruno Blanchet, Cas Cremers, Kevin Liao, and Bryan Parno. 2021. SoK: Computer-Aided Cryptography. In SP. IEEE, 777–795. doi:10.1109/SP40001.2021.00008
-
[9]
Gilles Barthe, Benjamin Grégoire, Sylvain Heraud, and Santiago Zanella-Béguelin. 2011. Computer-Aided Security Proofs for the Working Cryptographer. In CRYPTO (Lecture Notes in Computer Science, Vol. 6841) . Springer, 71–90. doi:10.1007/978-3-642-22792-9_5
-
[10]
Basin, Jannik Dreier, Lucca Hirschi, Sasa Radomirovic, Ralf Sasse, and Vincent Stettler
David A. Basin, Jannik Dreier, Lucca Hirschi, Sasa Radomirovic, Ralf Sasse, and Vincent Stettler. 2018. A Formal Analysis of 5G Authentication. In CCS. ACM, 1383–1396. doi:10.1145/3243734.3243846
-
[11]
Yves Bertot and Pierre Castéran. 2004. Interactive Theorem Proving and Program Development - Coq’Art: The Calculus of Inductive Constructions. Springer
2004
-
[12]
Bruno Blanchet. 2001. An Efficient Cryptographic Protocol Verifier Based on Prolog Rules. In CSFW. IEEE Computer Society, 82–96. doi:10.1109/CSFW.2001.930138
-
[13]
Bruno Blanchet. 2006. A Computationally Sound Mechanized Prover for Security Protocols. In S&P. IEEE Computer Society, 140–154. doi:10.1109/SP.2006.1
-
[14]
Tom Brown, Benjamin Mann, et al. 2020. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems, Vol. 33. 1877–1901
2020
-
[15]
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, et al. 2023. Sparks of Artificial General Intelligence: Early experiments with GPT-4. CoRR abs/2303.12712 (2023). doi:10.48550/ARXIV.2303.12712
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.12712 2023
-
[16]
Mark Chen, Jerry Tworek, Heewoo Jun, et al . 2021. Evaluating Large Language Models Trained on Code. CoRR abs/2107.03374 (2021)
Pith/arXiv arXiv 2021
-
[17]
Yongchao Chen, Rujul Gandhi, Yang Zhang, and Chuchu Fan. 2023. NL2TL: Transforming Natural Languages to Temporal Logics using Large Language Models. In EMNLP. Association for Computational Linguistics, 15880–15903. doi:10.18653/V1/2023.EMNLP-MAIN.985
-
[18]
Vincent Cheval, Charlie Jacomme, Steve Kremer, and Robert Künnemann. 2022. SAPIC+: protocol verifiers of the world, unite!. In USENIX Security Symposium. USENIX Association, 3935–3952
2022
-
[19]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, et al. 2023. PaLM: Scaling Language Modeling with Pathways. J. Mach. Learn. Res. 24 (2023), 240:1–240:113
2023
-
[20]
Véronique Cortier, Steve Kremer, and Bogdan Warinschi. 2011. A Survey of Symbolic Methods in Computational Analysis of Cryptographic Systems. J. Autom. Reason. 46, 3-4 (2011), 225–259. doi:10.1007/S10817-010-9187-9
-
[21]
Matthias Cosler, Christopher Hahn, Daniel Mendoza, Frederik Schmitt, and Caroline Trippel. 2023. nl2spec: Interactively Translating Unstructured Natural Language to Temporal Logics with Large Language Models. In CA V (2) (Lecture Notes in Computer Science, Vol. 13965) . Springer, 383–396. doi:10.1007/978-3-031-37703-7_18
-
[22]
Cas J. F. Cremers. 2008. The Scyther Tool: Verification, Falsification, and Analysis of Security Protocols. InCA V (Lecture Notes in Computer Science, Vol. 5123) . Springer, 414–418. doi:10.1007/978-3-540-70545-1_38
-
[23]
Tim Dierks and Eric Rescorla. 2008. The Transport Layer Security (TLS) Protocol Version 1.2. RFC 5246 (2008), 1–104. doi:10.17487/RFC5246
-
[24]
Santiago Escobar, Catherine Meadows, and José Meseguer. 2007. Maude-NPA: Cryptographic Protocol Analysis Modulo Equational Properties. In FOSAD (Lecture Notes in Computer Science, Vol. 5705) . Springer, 1–50. doi:10.1007/978-3-642- 03829-7_1
-
[25]
Eval4LLMs. 2025. The code and experiment results of CrypFormBench. [EB/OL]. https://github.com/Eval4LLMs/ CrypFormBench/tree/main
2025
-
[26]
Hugging Face. 2025. BAAI/bge-large-en-v1.5. https://huggingface.co/BAAI/bge-large-en-v1.5 Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE177. Publication date: July 2026. FSE177:22 Z. Li, Q. Zhang, H. Liu, X. Gu, X. Lu, H. Liu, B. Wang, H. Fan, Z. Zhao, R. Zhang, and L. Zhou
2025
-
[27]
Hugging Face. 2025. intfloat/e5-large-v2. https://huggingface.co/intfloat/e5-large-v2
2025
-
[28]
Hugging Face. 2025. Qwen/Qwen2.5-Coder-3B. https://huggingface.co/Qwen/Qwen2.5-Coder-3B
2025
-
[29]
Hugging Face. 2025. Qwen/Qwen3-Embedding-8B. https://huggingface.co/Qwen/Qwen3-Embedding-8B
2025
-
[30]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. In EMNLP (Findings) (Findings of ACL, Vol. EMNLP 2020) . Association for Computational Linguistics, 1536–1547. doi:10.18653/V1/2020.FINDINGS-EMNLP.139
-
[31]
Luyu Gao, Aman Madaan, Shuyan Zhou, et al. 2023. PAL: Program-aided Language Models. In ICML (Proceedings of Machine Learning Research, Vol. 202). PMLR, 10764–10799
2023
-
[32]
Ivan Gavran, Eva Darulova, and Rupak Majumdar. 2020. Interactive synthesis of temporal specifications from examples and natural language. Proc. ACM Program. Lang. 4, OOPSLA (2020), 201:1–201:26. doi:10.1145/3428269
-
[33]
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, et al. 2024. Chatglm: A family of large language models from glm-130b to glm-4 all tools. arXiv preprint arXiv:2406.12793 (2024). doi:10.48550/ARXIV.2406.12793
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.12793 2024
-
[34]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025). doi:10.48550/ARXIV.2501.12948
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[35]
Jiaqi Guo, Zecheng Zhan, Yan Gao, Yan Xiao, Jian-Guang Lou, Ting Liu, and Dongmei Zhang. 2019. Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation. In ACL (1). Association for Computational Linguistics, 4524–4535. doi:10.18653/V1/P19-1444
-
[36]
Dick Hardt. 2012. The OAuth 2.0 Authorization Framework. RFC 6749 (2012), 1–76. doi:10.17487/RFC6749
-
[37]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring Massive Multitask Language Understanding. In ICLR. OpenReview.net
2021
-
[38]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024). doi:10.48550/ARXIV. 2410.21276
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2024
-
[39]
Nadim Kobeissi, Georgio Nicolas, and Mukesh Tiwari. 2020. Verifpal: Cryptographic Protocol Analysis for the Real World. In INDOCRYPT (Lecture Notes in Computer Science, Vol. 12578) . Springer, 151–202. doi:10.1007/978-3-030-65277- 7_8
-
[40]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, et al. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In NeurIPS. 1–16
2020
-
[41]
Tingting Li, Ziming Zhao, Zhaoxuan Li, Xiaofei Yue, and Jiongchi Yu. 2026. Fair and Carbon-Aware LLM Routing for Web Services. In WWW. ACM, 9563–9571. doi:10.1145/3774904.3793001
-
[42]
Yujia Li, David Choi, Junyoung Chung, et al. 2022. Competition-level code generation with alphacode. Science 378, 6624 (2022), 1092–1097. doi:10.48550/ARXIV.2203.07814
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2203.07814 2022
-
[43]
Yixuan Li, Julian Parsert, and Elizabeth Polgreen. 2024. Guiding Enumerative Program Synthesis with Large Language Models. In CA V (2) (Lecture Notes in Computer Science, Vol. 14682). Springer, 280–301. doi:10.1007/978-3-031-65630-9_15
-
[44]
Zhaoxuan Li, Rui Zhang, and Pengchao Li. 2020. A Secure and Efficient Smart Contract Execution Scheme. In ICWS (Lecture Notes in Computer Science) . Springer, 17–32. doi:10.1007/978-3-030-59618-7_2
-
[45]
Xi Victoria Lin, Chenglong Wang, Deric Pang, Kevin Vu, and Michael D Ernst. 2017. Program synthesis from natural language using recurrent neural networks. University of Washington Department of Computer Science and Engineering, Seattle, W A, USA, Tech. Rep. UW-CSE-17-031 (2017), 1–12
2017
-
[46]
Liu, Kevin Lin, John Hewitt, et al
Nelson F. Liu, Kevin Lin, John Hewitt, et al. 2024. Lost in the Middle: How Language Models Use Long Contexts. Trans. Assoc. Comput. Linguistics 12 (2024), 157–173. doi:10.1162/TACL_A_00638
-
[47]
Gavin Lowe. 1995. An Attack on the Needham-Schroeder Public-Key Authentication Protocol. Inf. Process. Lett. 56, 3 (1995), 131–133. doi:10.1016/0020-0190(95)00144-2
-
[48]
Siqi Lu, Hanjie Dong, Zhaoxuan Li, and Laurence T. Yang. 2024. Not Just Summing: The Identifier Leakage of Private-Join-and-Compute and its Improvement. IEEE Trans. Dependable Secur. Comput. 21, 6 (2024), 5143–5155. doi:10.1109/TDSC.2024.3371569
-
[49]
Siqi Lu, Zhaoxuan Li, Xuyang Miao, Qingdi Han, and Jianhua Zheng. 2023. PIWS: Private Intersection Weighted Sum Protocol for Privacy-Preserving Score-Based Voting With Perfect Ballot Secrecy. IEEE Trans. Comput. Soc. Syst. 10, 3 (2023), 1039–1056. doi:10.1109/TCSS.2022.3162869
-
[51]
Ziyu Mao, Jingyi Wang, Jun Sun, Shengchao Qin, and Jiawen Xiong. 2025. LLM-aided Automatic Modeling for Security Protocol Verification. In ICSE. doi:10.1109/ICSE55347.2025.00197 Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE177. Publication date: July 2026. Benchmarking Formal Analysis Capability of Large Language Models for Cryptographic Schemes FSE177:23
-
[53]
Meta. 2025. Llama 4. https://www.llama.com/models/llama-4/
2025
-
[54]
Roger M. Needham and Michael D. Schroeder. 1978. Using Encryption for Authentication in Large Networks of Computers. Commun. ACM 21, 12 (1978), 993–999. doi:10.1145/359657.359659
-
[55]
Erik Nijkamp, Bo Pang, Hiroaki Hayashi, et al . 2023. CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis. In ICLR. OpenReview.net
2023
-
[56]
OpenAI. 2025. GPT-5.1: A smarter, more conversational ChatGPT. https://openai.com/index/gpt-5-1/
2025
-
[57]
Stanislas Polu and Ilya Sutskever. 2020. Generative Language Modeling for Automated Theorem Proving. CoRR abs/2009.03393 (2020)
Pith/arXiv arXiv 2020
-
[58]
Colin Raffel, Noam Shazeer, Adam Roberts, et al . 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.J. Mach. Learn. Res. 21 (2020), 140:1–140:67
2020
-
[59]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In EMNLP/IJCNLP (1). Association for Computational Linguistics, 3980–3990. doi:10.18653/V1/D19-1410
-
[60]
Raúl Rojas. 2015. A Tutorial Introduction to the Lambda Calculus. CoRR abs/1503.09060 (2015)
Pith/arXiv arXiv 2015
-
[61]
Gemini Team. 2025. Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities. CoRR abs/2507.06261 (2025). doi:10.48550/ARXIV.2507.06261
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.06261 2025
-
[62]
Haiming Wang, Ye Yuan, Zhengying Liu, et al. 2023. DT-Solver: Automated Theorem Proving with Dynamic-Tree Sampling Guided by Proof-level Value Function. In ACL (1). Association for Computational Linguistics, 12632–12646. doi:10.18653/V1/2023.ACL-LONG.706
-
[63]
Jason Wei, Yi Tay, Rishi Bommasani, et al. 2022. Emergent Abilities of Large Language Models. Trans. Mach. Learn. Res. 2022 (2022)
2022
-
[64]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In NeurIPS
2022
-
[65]
xAI. 2025. Grok 3. https://x.ai/grok
2025
-
[66]
Swope, Alex Gu, et al
Kaiyu Yang, Aidan M. Swope, Alex Gu, et al. 2023. LeanDojo: Theorem Proving with Retrieval-Augmented Language Models. In NeurIPS
2023
-
[67]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. In NeurIPS
2023
-
[68]
Tatu Ylönen and Chris Lonvick. 2006. The Secure Shell (SSH) Authentication Protocol. RFC 4252 (2006), 1–17. doi:10.17487/RFC4252
-
[69]
Xiaofei Yue, Fangming Zhao, Fulun Ye, Jiongchi Yu, Zhaoxuan Li, Tingting Li, Ziming Zhao, and Jianwei Yin. 2026. HeteroSim: Towards High-Fidelity Heterogeneous LLM Training Simulation on GPUs. In WWW. ACM, 5189–5197. doi:10.1145/3774904.3792254
-
[70]
Jiyang Zhang, Pengyu Nie, Junyi Jessy Li, and Milos Gligoric. 2023. Multilingual Code Co-evolution using Large Language Models. In ESEC/SIGSOFT FSE. ACM, 695–707. doi:10.1145/3611643.3616350
-
[71]
Rui Zhang, Zhaoxuan Li, and Lijuan Zheng. 2021. Secure and Efficient Key Hierarchical Management and Collaborative Signature Schemes of Blockchain. In ICAIS (2) (Lecture Notes in Computer Science) . Springer, 332–345. doi:10.1007/978- 3-030-78612-0_27
-
[72]
Ziming Zhao, Zhaoxuan Li, Tingting Li, and Fan Zhang. 2025. CyberLLM: Enable Mapping CVE to Tactics and Techniques of Cyber Threats via LLM. In DASFAA (5) (Lecture Notes in Computer Science) . Springer, 473–488. doi:10. 1007/978-981-95-4155-3_33
2025
-
[73]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. In NeurIPS
2023
-
[74]
Qihao Zhu, Daya Guo, Zhihong Shao, Dejian Yang, Peiyi Wang, Runxin Xu, Y Wu, Yukun Li, Huazuo Gao, Shirong Ma, et al. 2024. Deepseek-coder-v2: Breaking the barrier of closed-source models in code intelligence. arXiv preprint arXiv:2406.11931 (2024). doi:10.48550/ARXIV.2406.11931 Received 2025-09-12; accepted 2026-03-24 Proc. ACM Softw. Eng., Vol. 3, No. F...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.11931 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.