A Reproducible Log-Driven AutoML Framework for Interpretable Pipeline Optimization in Healthcare Risk Prediction
Pith reviewed 2026-05-22 01:28 UTC · model grok-4.3
The pith
A log-driven AutoML framework reveals that healthcare risk prediction pipelines depend on a small set of interacting components.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
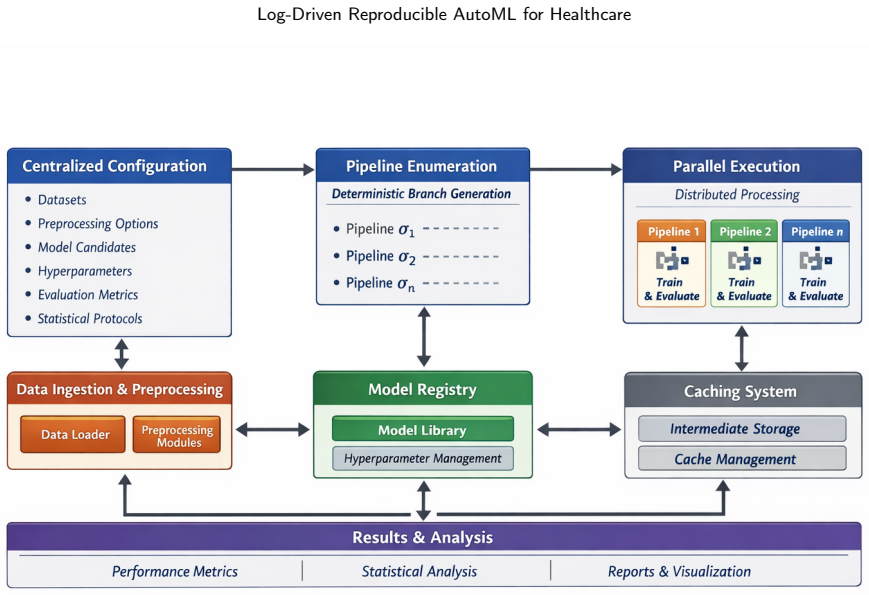
By treating each pipeline as a traceable log entity inside the yvsoucom-iterkit framework, analysis of over 18,000 configurations on the Pima Indians Diabetes and Stroke datasets shows a structured and partially redundant search space in which performance is governed by a small subset of interacting components; Random Forest importance ranks augmentation at 0.454 and model choice at 0.198 on Pima while imbalance handling reaches 0.406 on Stroke, and similarity metrics quantify redundancies such as biMax-biMean feature selection (RMS distance 0.0252) and mixup versus no augmentation (0.0279).
What carries the argument
The traceable log entity that records every pipeline configuration, enabling attribution of performance to individual components, measurement of their interactions and similarities, and assessment of cross-seed robustness.
If this is right
- Effective AutoML optimization can concentrate on a reduced set of high-impact components instead of exploring the full space.
- Ensemble models deliver stable high Weighted-F1 scores (0.89 on Pima, 0.94 on Stroke) with lower cross-seed variability than alternatives such as SVM.
- Many component variants exhibit strong redundancy, including specific augmentation methods that perform nearly identically to no augmentation.
- Macro-F1 remains limited on severely imbalanced data like Stroke even when Weighted-F1 is high.
Where Pith is reading between the lines
- Similar log-based redundancy analysis could be applied to other clinical prediction tasks to discover domain-specific shortcuts.
- The framework's built-in traceability may help meet regulatory demands for documented model construction in healthcare.
- The observed performance-robustness trade-off suggests ensembles as a default choice when reproducibility across random seeds matters.
- Future experiments could deliberately prune the redundant components identified here and measure any drop in final accuracy.
Load-bearing premise
The two chosen datasets together with the 18,000 sampled configurations represent the broader space of healthcare risk prediction tasks well enough for the observed component importance rankings to generalize.
What would settle it
Re-running the identical log-driven framework on a new healthcare dataset such as heart-disease prediction and finding that the top-ranked components shift away from augmentation and imbalance handling.
Figures





read the original abstract
Accurate and reproducible disease risk prediction remains challenging due to heterogeneous features, limited samples, and severe class imbalance. This study introduces yvsoucom-iterkit, a deterministic and log-driven automated machine learning framework that formulates pipeline optimization as a fully reproducible, configuration-level system. Each pipeline is encoded as a traceable log entity, enabling analysis of component attribution, interactions, similarity, and cross-seed robustness. Experiments on the Pima Indians Diabetes and Stroke datasets across more than 18,000 pipeline configurations reveal a structured and partially redundant search space, where performance is governed by a small subset of interacting components. Random Forest importance analysis identifies augmentation (0.454), model choice (0.198), and imbalance handling (0.101) as key drivers on Pima, while imbalance handling dominates Stroke (0.406). Component similarity analysis shows strong redundancy, with feature selection variants (biMax-biMean) exhibiting low RMS distance (0.0252), mixup closely matching no augmentation (0.0279), and TomekLinks aligning with no imbalance handling (0.0325), whereas Gaussian noise shows greater divergence from no augmentation (0.10). The framework achieves strong and stable performance using ensemble models (Weighted-F1 0.89, Macro-F1 0.88 on Pima; Weighted-F1 0.94 on Stroke), while Macro-F1 remains lower on Stroke (0.67) due to class imbalance. Cross-seed analysis reveals a performance-robustness trade-off, with ensembles showing lower variability (0.023-0.026) than SVM. These results indicate that effective AutoML optimization can focus on a reduced set of high-impact components.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces yvsoucom-iterkit, a deterministic log-driven AutoML framework that encodes each pipeline as a traceable log entity to support reproducible optimization and post-hoc interpretability analysis (component attribution, interactions, similarity, and cross-seed robustness). Experiments across more than 18,000 configurations on the Pima Indians Diabetes and Stroke datasets are used to argue that the pipeline search space is structured and partially redundant, with performance governed by a small subset of interacting components; Random Forest importance identifies augmentation (0.454) and model choice (0.198) as top drivers on Pima while imbalance handling (0.406) dominates on Stroke, and RMS-distance similarity analysis quantifies redundancies such as biMax-biMean (0.0252) and mixup vs. none (0.0279). Ensemble models achieve stable Weighted-F1 scores of 0.89–0.94.
Significance. If the central empirical claims hold, the work provides a concrete, log-centric methodology for making AutoML pipelines both reproducible and interpretable in healthcare settings, where the ability to trace and reduce the effective search space to a small set of high-impact components could be practically useful. The explicit quantification of component redundancy via RMS distances and the reporting of cross-seed variability constitute strengths that go beyond typical black-box AutoML results.
major comments (2)
- [Abstract] Abstract: the central claim that 'performance is governed by a small subset of interacting components' rests on experiments performed on only two binary, imbalanced classification datasets whose top importance rankings already diverge (augmentation 0.454 on Pima vs. imbalance handling 0.406 on Stroke); this divergence indicates that the identified high-impact subset may be an artifact of the chosen data distributions rather than a general property of healthcare risk pipelines.
- [Abstract] Abstract: the manuscript provides no description of the sampling strategy used to generate the 18,000 pipeline configurations or of any post-hoc filtering; without this information the Random Forest importance scores and the RMS-distance redundancy results cannot be reliably interpreted as evidence of an intrinsically structured search space.
minor comments (2)
- [Abstract] Abstract: the framework name 'yvsoucom-iterkit' is introduced without explanation of its construction or intended meaning.
- [Abstract] Abstract: the reported cross-seed variability (0.023–0.026) should explicitly state the underlying performance metric (e.g., standard deviation of Weighted-F1 across seeds).
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each major comment below, indicating where revisions will be made to improve clarity and completeness without altering the core claims or experimental results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'performance is governed by a small subset of interacting components' rests on experiments performed on only two binary, imbalanced classification datasets whose top importance rankings already diverge (augmentation 0.454 on Pima vs. imbalance handling 0.406 on Stroke); this divergence indicates that the identified high-impact subset may be an artifact of the chosen data distributions rather than a general property of healthcare risk pipelines.
Authors: The manuscript already reports the dataset-specific rankings (augmentation highest on Pima, imbalance handling highest on Stroke) to illustrate that the governing components can vary while still forming a small subset. This supports the claim of a structured search space rather than contradicting it. We acknowledge the limitation of using only two datasets and will revise the abstract and add a paragraph in the discussion to explicitly state that the findings apply to the evaluated healthcare risk prediction tasks on these datasets. The framework itself is presented as a general tool for identifying such subsets per task. No new experiments are feasible at this stage, but the scope will be clarified. revision: partial
-
Referee: [Abstract] Abstract: the manuscript provides no description of the sampling strategy used to generate the 18,000 pipeline configurations or of any post-hoc filtering; without this information the Random Forest importance scores and the RMS-distance redundancy results cannot be reliably interpreted as evidence of an intrinsically structured search space.
Authors: We agree that a description of how the configurations were generated is necessary for interpreting the importance and redundancy analyses. We will add a dedicated subsection to the Methods section detailing the sampling strategy: the 18,000+ configurations were produced by systematically enumerating all valid combinations of the pipeline components (augmentation variants, imbalance handlers, feature selectors, and models) within the framework's defined search space, with no post-hoc filtering applied. This revision will allow readers to assess the results as evidence of structure in the explored space. revision: yes
Circularity Check
No significant circularity; empirical results from independent pipeline runs
full rationale
The paper introduces a logging framework for AutoML pipelines and then executes >18,000 configurations on two fixed datasets, recording performance metrics. Component importances and redundancy are computed post-hoc via Random Forest fits and RMS distances on those observed outcomes. No step reduces a claimed result to a fitted parameter by construction, nor does any self-citation or definitional loop carry the central claim about search-space structure. The findings rest on externally generated experimental data rather than on the framework's own definitions being re-used as both input and output. This is a standard reproducible empirical study whose derivation chain remains self-contained against the reported runs.
Axiom & Free-Parameter Ledger
free parameters (1)
- Pipeline configuration choices
axioms (1)
- domain assumption Random Forest feature importance reliably ranks the contribution of pipeline components to final performance
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Experiments on the Pima Indians Diabetes and Stroke datasets across more than 18,000 pipeline configurations reveal a structured and partially redundant search space, where performance is governed by a small subset of interacting components. Random Forest importance analysis identifies augmentation (0.454), model choice (0.198), and imbalance handling (0.101) as key drivers on Pima.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Component similarity analysis shows strong redundancy, with feature selection variants (biMax-biMean) exhibiting low RMS distance (0.0252), mixup closely matching no augmentation (0.0279).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Gustavo E. A. P. A. Batista, Ronaldo C. Prati, and Maria Carolina Monard. A study of the behavior of several methods for balancing machinelearningtrainingdata.ACMSIGKDDexplorationsnewsletter, 6(1):20–29, 2004
work page 2004
-
[2]
Bernd Bischl, Martin Binder, Michel Lang, Tobias Pielok, Jakob Richter, Stefan Coors, Janek Thomas, Theresa Ullmann, Marc Becker, Anne-Laure Boulesteix, et al. Hyperparameter optimization: Foun- dations, algorithms, best practices, and open challenges.Wiley InterdisciplinaryReviews:DataMiningandKnowledgeDiscovery,13 (2):e1484, 2023. R. Huang et al.:Prepri...
work page 2023
-
[3]
Random forests.Machine Learning, 45(1):5–32, 2001
Leo Breiman. Random forests.Machine Learning, 45(1):5–32, 2001
work page 2001
-
[4]
A survey on feature selection methods.Computers & Electrical Engineering, 40(1):16–28, 2014
Girish Chandrashekar and Ferat Sahin. A survey on feature selection methods.Computers & Electrical Engineering, 40(1):16–28, 2014. ISSN 0045-7906. doi: 10.1016/j.compeleceng.2013.11.024. URL https://www.sciencedirect.com/science/article/pii/S0045790613003
-
[5]
40th-year commemorative issue
-
[6]
Nitesh V. Chawla, Kevin W. Bowyer, Lawrence O. Hall, and W. Philip Kegelmeyer. Smote: Synthetic minority over-sampling technique. Journal of Artificial Intelligence Research, 16:321–357, 2002
work page 2002
-
[7]
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system.Proceedings of the 22nd ACM SIGKDD International ConferenceonKnowledgeDiscoveryandDataMining,pages785–794, 2016
work page 2016
-
[8]
AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
Nick Erickson, Jonas Mueller, Alexander Shirkov, Hang Zhang, Pierre Larroy, Mu Li, and Alex Smola. Autogluon-tabular: Robust and accurate automl for structured data.arXiv preprint arXiv:2003.06505, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[9]
Matthias Feurer, Aaron Klein, Katharina Eggensperger, Jost Springen- berg, Manuel Blum, and Frank Hutter. Efficient and robust automated machine learning.Advances in neural information processing systems, 28, 2015
work page 2015
-
[10]
Matthias Feurer, Katharina Eggensperger, Stefan Falkner, Marius Lindauer, and Frank Hutter. Auto-sklearn 2.0: Hands-free automl via meta-learning.Journal of Machine Learning Research, 23(261): 1–61, 2022
work page 2022
-
[11]
Léo Grinsztajn, Edouard Oyallon, and Gaël Varoquaux. Why do tree-based models still outperform deep learning on typical tabular data?Advancesinneuralinformationprocessingsystems,35:507–520, 2022
work page 2022
-
[12]
Springer Berlin Heidelberg, Berlin, Heidelberg, 2006
Isabelle Guyon and André Elisseeff.An Introduction to Feature Ex- traction, pages 1–25. Springer Berlin Heidelberg, Berlin, Heidelberg, 2006
work page 2006
-
[13]
Transparency and reproducibility in artificial intelligence.Nature, 586(7829):E14– E16, 2020
Benjamin Haibe-Kains, George Alexandru Adam, et al. Transparency and reproducibility in artificial intelligence.Nature, 586(7829):E14– E16, 2020
work page 2020
-
[14]
Adasyn: Adaptive synthetic sampling approach for imbalanced learning
Haibo He, Yang Bai, Edwardo A Garcia, and Shutao Li. Adasyn: Adaptive synthetic sampling approach for imbalanced learning. In 2008 IEEE international joint conference on neural networks (IEEE worldcongressoncomputationalintelligence),pages1322–1328.Ieee, 2008
work page 2008
-
[15]
Knowledge- based systems212, 106622 (2021)
Xin He, Kaiyong Zhao, and Xiaowen Chu. Automl: A survey of the state-of-the-art.Knowledge-Based Systems, 212:106622, 2021. ISSN 0950-7051. doi: https://doi.org/10.1016/j.knosys.2020.106622. URL https://www.sciencedirect.com/science/article/pii/S0950705120307 516
-
[16]
RuiHuangandLicanHuang. Anautomlsystemforimprovingdiabetes predictionbyauto-optimizationofpreprocessingandmachinelearning models. SSRN preprint, 2026. Available athttps://ssrn.com/abstrac t=5898268orhttp://dx.doi.org/10.2139/ssrn.5898268
-
[17]
Frank Hutter, Lars Kotthoff, and Joaquin Vanschoren.Automated machine learning: methods, systems, challenges. Springer Nature, 2019
work page 2019
-
[18]
H2o automl: Scalable automatic machine learning
Erin LeDell and Sebastien Poirier. H2o automl: Scalable automatic machine learning. InProceedings of the AutoML Workshop at ICML, 2020
work page 2020
-
[19]
Feature selection: A data perspective.ACM computing surveys (CSUR), 50(6):1–45, 2017
Jundong Li, Kewei Cheng, Suhang Wang, Fred Morstatter, Robert P Trevino, Jiliang Tang, and Huan Liu. Feature selection: A data perspective.ACM computing surveys (CSUR), 50(6):1–45, 2017
work page 2017
-
[20]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. InProceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017
work page 2017
-
[21]
Automatingbiomedical data science through tree-based pipeline optimization
Randal S Olson, Ryan J Urbanowicz, Peter C Andrews, Nicole A Lavender,LaCreisKidd,andJasonHMoore. Automatingbiomedical data science through tree-based pipeline optimization. InEuropean conference on the applications of evolutionary computation, pages 123–137. Springer, 2016
work page 2016
-
[22]
Abhilash Pati, Manoranjan Parhi, and Binod Kumar Pattanayak. A review on prediction of diabetes using machine learning and data mining classification techniques.International Journal of Biomedical Engineering and Technology, 41(1):83–109, 2023
work page 2023
-
[23]
Performance analysis of naive bayes and j48 classification algorithm for data classification
Tina R Patil and Swati Sunil Sherekar. Performance analysis of naive bayes and j48 classification algorithm for data classification. International journal of computer science and applications, 6(2):256– 261, 2013
work page 2013
-
[24]
Joelle Pineau, Philippe Vincent-Lamarre, Koustuv Sinha, Vincent Larivière, Alina Beygelzimer, Florence d’Alché Buc, Emily Fox, and Hugo Larochelle. Improving reproducibility in machine learning research (a report from the neurips 2019 reproducibility program). Journal of machine learning research, 22(164):1–20, 2021
work page 2019
-
[25]
A review of feature selection techniques in bioinformatics.bioinformatics, 23(19):2507– 2517, 2007
Yvan Saeys, Inaki Inza, and Pedro Larranaga. A review of feature selection techniques in bioinformatics.bioinformatics, 23(19):2507– 2517, 2007
work page 2007
-
[26]
Abid Sarwar, Mehbob Ali, Jatinder Manhas, and Vinod Sharma. Diagnosis of diabetes type-ii using hybrid machine learning based ensemble model.International Journal of Information Technology, 12(2):419–428, 2020
work page 2020
-
[27]
Benjamin Shickel, Patrick James Tighe, Azra Bihorac, and Parisa Rashidi. Deep ehr: a survey of recent advances in deep learning techniques for electronic health record (ehr) analysis.IEEE journal of biomedical and health informatics, 22(5):1589–1604, 2017
work page 2017
-
[28]
M. S. Singh, K. Thongam, P. Choudhary, et al. Stroke risk prediction and prevention: Traditional versus machine learning approaches. Archives of Computational Methods in Engineering, 2025. doi: 10.1007/s11831-025-10406-5
-
[29]
Auto-weka: Combined selection and hyperparameter opti- mization of classification algorithms
Chris Thornton, Frank Hutter, Holger H Hoos, and Kevin Leyton- Brown. Auto-weka: Combined selection and hyperparameter opti- mization of classification algorithms. InProceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 847–855, 2013
work page 2013
-
[30]
Twomodificationsofcnn.IEEETransactionsonSystems, Man, and Cybernetics, SMC-6(11):769–772, 1976
IvanTomek. Twomodificationsofcnn.IEEETransactionsonSystems, Man, and Cybernetics, SMC-6(11):769–772, 1976
work page 1976
-
[31]
mixup: Beyond empirical risk minimization
HongyiZhang,MoustaphaCisse,YannN.Dauphin,andDavidLopez- Paz. mixup: Beyond empirical risk minimization. InInternational Conference on Learning Representations (ICLR), pages 1–13, 2018
work page 2018
-
[32]
Marc-André Zöller and Marco F. Huber. Benchmark and survey of automated machine learning frameworks.Journal of Artificial Intelligence Research, 70:409–472, 2021. R. Huang et al.:Preprint submitted to ElsevierPage 20 of 41 Log-Driven Reproducible AutoML for Healthcare Supplementary Materials Overview This document presents thecomprehensive set of experime...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.