Event-Aware Instructed Assistant for Referring Video Segmentation
Pith reviewed 2026-06-26 05:11 UTC · model grok-4.3
The pith
Text-guided event queries partition videos into simple segments to improve referring video segmentation accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
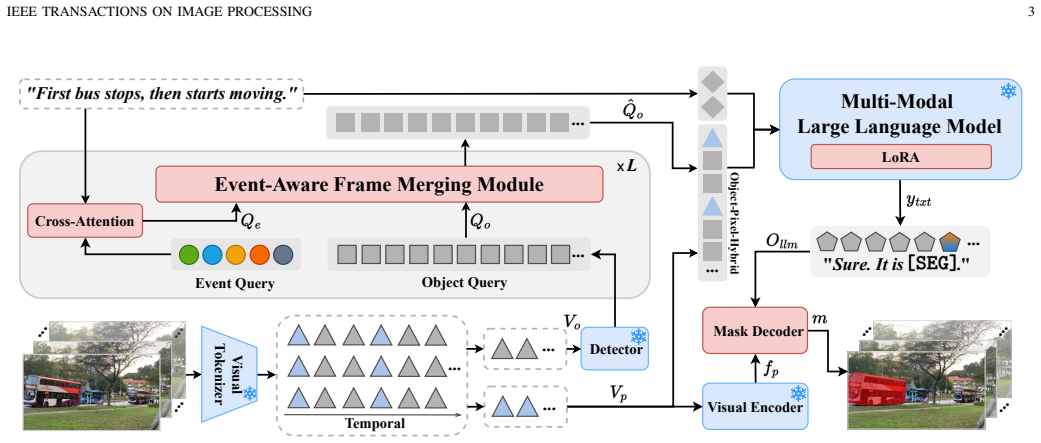
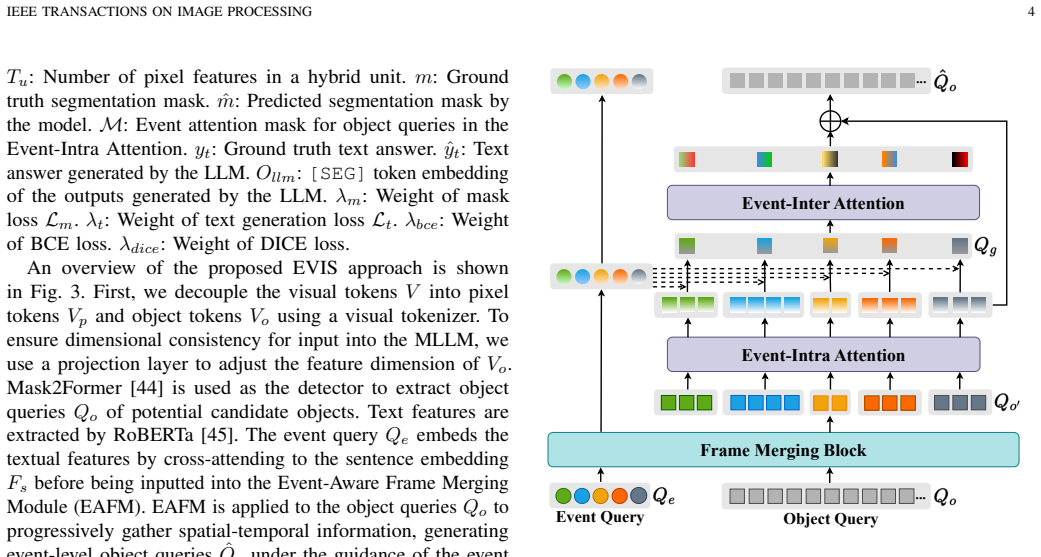
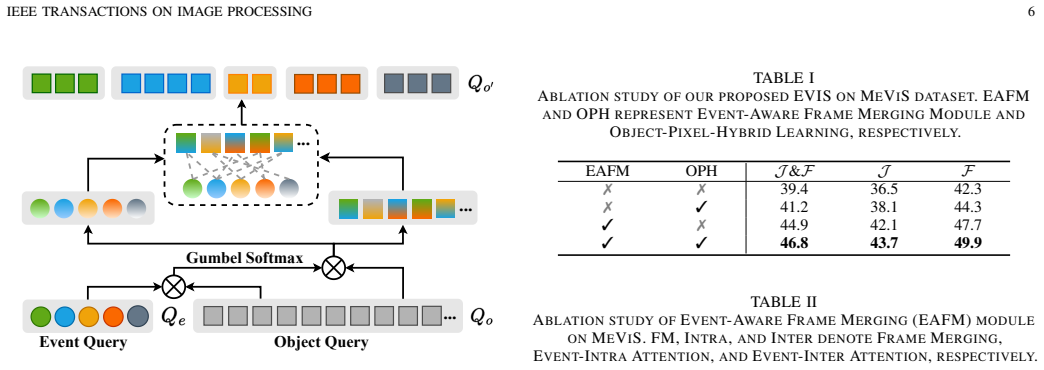
EVIS utilizes text-guided Event Queries to partition a video into simple events, extracting event-aware visual-text features to achieve a hierarchical understanding of the video. Object-Pixel-Hybrid Learning enables the model to track targets in long-term videos by integrating fine-grained pixel features with prior object queries, resulting in stronger performance on referring video segmentation benchmarks.
What carries the argument
Text-guided Event Queries that partition the video into events for sequential processing, paired with Object-Pixel-Hybrid Learning to merge pixel and object information.
If this is right
- Video content is understood event by event rather than all at once, lowering the chance of hallucinations.
- Hierarchical event-aware features improve matching between text references and visual content.
- Object-Pixel-Hybrid Learning supports consistent target tracking across extended video durations.
- Results improve across five public referring video segmentation benchmarks.
Where Pith is reading between the lines
- The event decomposition approach could be tested on related tasks such as video question answering where references span multiple actions.
- Performance may drop on videos whose events lack strong alignment with the accompanying text descriptions.
Load-bearing premise
Natural language expressions divide a video into distinct text-related segments each representing a separate event.
What would settle it
A test set of videos where referring expressions cross event boundaries without clear divisions, on which the event-query model shows no accuracy gain over standard single-event baselines.
Figures



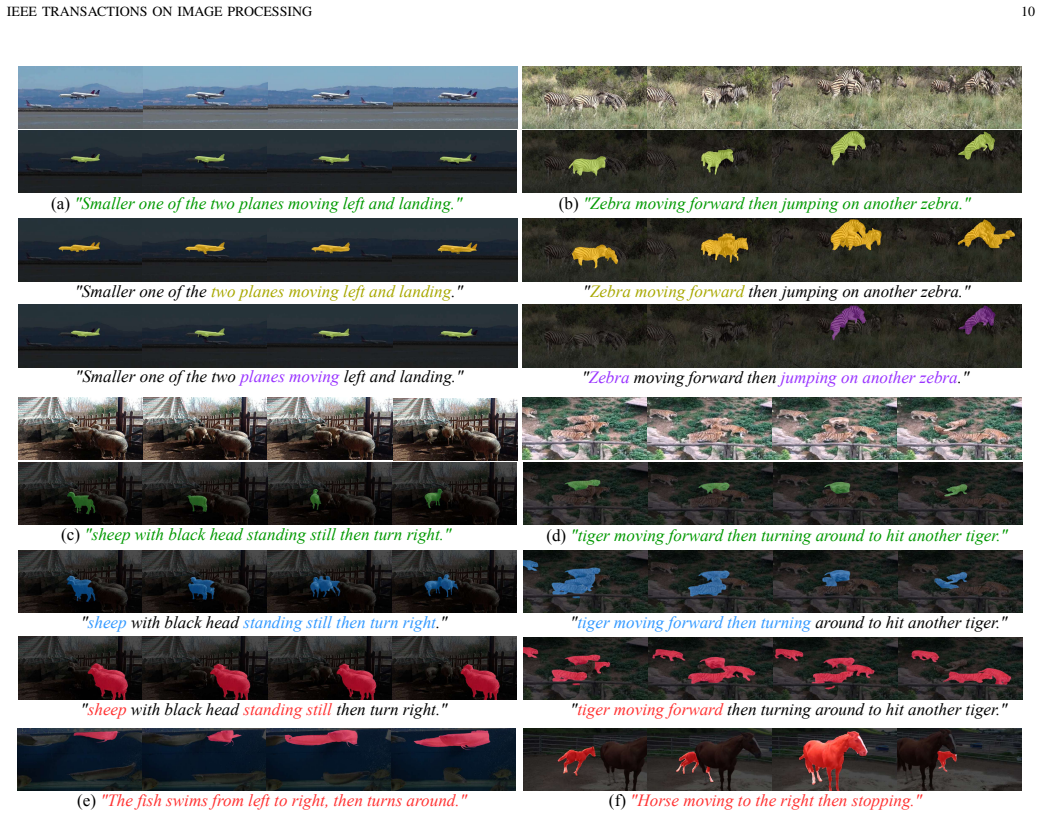

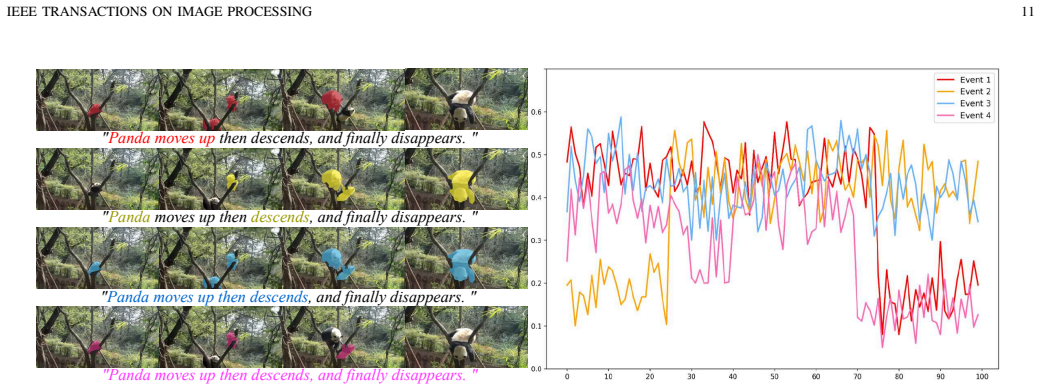
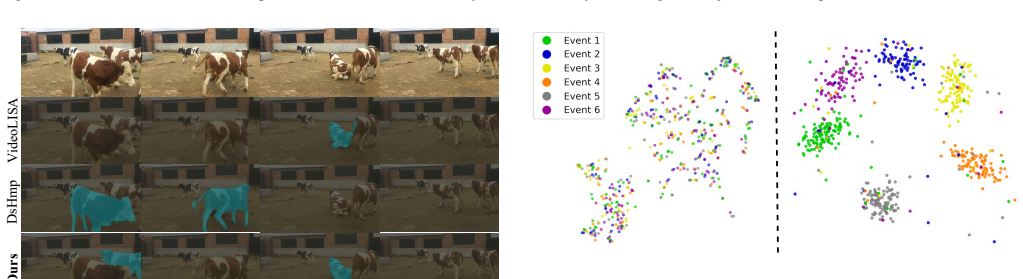
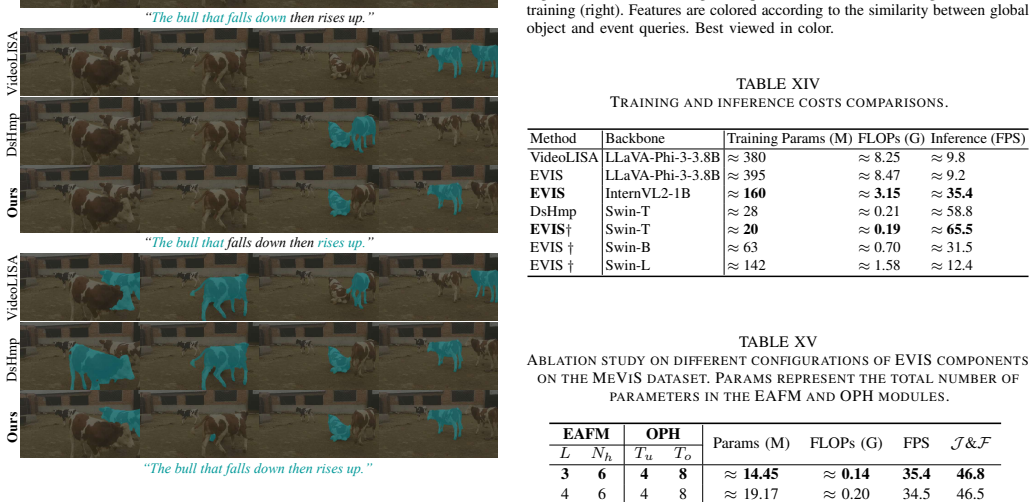
read the original abstract
Existing referring video segmentation methods often treat a video as a single event consisting of multiple images, overlooking the fact that a video typically contains multiple distinct events. Under such a mechanism, the model needs to directly understand all the complex content in the video and text, which can easily lead to confusion and hallucinations. To address this issue, we propose to decompose a video to a set of simple events by learnable Event Query, and understand complex video content in an event-by-event, easy-to-understand manner. This is based on the observation that natural language expressions often divide a video into distinct, text-related segments, each representing a separate event within a compound event. We introduce EVIS, an Event-Aware Video Instructed Segmentation Assistant, which utilizes text-guided Event Queries to partition a video into simple events, extracting event-aware visual-text features to achieve a hierarchical understanding of the video. Additionally, we propose Object-Pixel-Hybrid Learning, which enables the MLLMs to track targets in long-term videos by integrating fine-grained pixel features with prior object queries. Extensive experimental results on 5 public benchmarks demonstrate EVIS's strong performance in addressing the referring video segmentation task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EVIS, an Event-Aware Video Instructed Segmentation Assistant for referring video segmentation. It decomposes input videos into simple events via text-guided learnable Event Queries (motivated by the observation that natural language expressions divide videos into distinct text-related segments), extracts event-aware visual-text features for hierarchical understanding, and introduces Object-Pixel-Hybrid Learning to integrate pixel features with object queries for long-term target tracking. The abstract states that extensive experiments on five public benchmarks demonstrate strong performance.
Significance. If the central architectural claims hold and are validated by rigorous experiments, the event-decomposition approach could address a plausible limitation of treating entire videos as single events, potentially reducing hallucinations in complex referring segmentation scenarios. The Object-Pixel-Hybrid Learning component might offer a practical mechanism for long-video tracking. However, with only the abstract available and no equations, architecture diagrams, training details, ablation studies, or quantitative results, the significance cannot be assessed beyond the high-level motivation.
major comments (2)
- Abstract: The central performance claim ('strong performance' on 5 public benchmarks) is stated without any supporting numbers, tables, baselines, or error analysis, rendering the claim unevaluable and load-bearing for the paper's contribution.
- Abstract: No equations, pseudocode, or architectural details are supplied for the Event Query mechanism or Object-Pixel-Hybrid Learning, so it is impossible to determine whether these components are independent innovations or reduce to standard query-based attention with minor modifications.
Simulated Author's Rebuttal
We thank the referee for the comments on our manuscript. The full paper contains the architectural details, equations, and experimental results referenced in the abstract. We address the two major comments point by point below.
read point-by-point responses
-
Referee: Abstract: The central performance claim ('strong performance' on 5 public benchmarks) is stated without any supporting numbers, tables, baselines, or error analysis, rendering the claim unevaluable and load-bearing for the paper's contribution.
Authors: We agree that including concrete metrics would make the abstract's claim more immediately evaluable. In the revised manuscript we will update the abstract to report key quantitative results (e.g., mIoU gains on the five benchmarks versus recent baselines) while keeping the abstract concise. revision: yes
-
Referee: Abstract: No equations, pseudocode, or architectural details are supplied for the Event Query mechanism or Object-Pixel-Hybrid Learning, so it is impossible to determine whether these components are independent innovations or reduce to standard query-based attention with minor modifications.
Authors: The abstract is a high-level summary; the full manuscript supplies the requested details. Section 3.2 defines the text-guided Event Queries with the decomposition objective and associated equations. Section 3.3 presents the Object-Pixel-Hybrid Learning formulation, including the integration of pixel features with object queries, architecture diagrams, and ablations that isolate the contribution beyond standard query attention. These sections demonstrate the design choices motivated by the event-decomposition observation. revision: no
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes EVIS as an architectural innovation using learnable text-guided Event Queries to decompose videos and Object-Pixel-Hybrid Learning for tracking, motivated by the observational claim that natural language divides videos into events. No equations, parameter-fitting steps, or self-citations are present in the supplied text that would reduce any claimed prediction or result to a quantity defined by the authors' own prior inputs or fits. The performance claims rest on external benchmark evaluations rather than internal self-definition, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- Event Query parameters
axioms (1)
- domain assumption Natural language expressions often divide a video into distinct, text-related segments, each representing a separate event within a compound event.
invented entities (2)
-
Event Query
no independent evidence
-
Object-Pixel-Hybrid Learning
no independent evidence
Reference graph
Works this paper leans on
-
[1]
MeViS: A large-scale benchmark for video segmentation with motion expressions,
H. Ding, C. Liu, S. He, X. Jiang, and C. C. Loy, “MeViS: A large-scale benchmark for video segmentation with motion expressions,” inInt. Conf. Comput. Vis., 2023, pp. 2694–2703
2023
-
[2]
Decoupling static and hierarchical motion perception for referring video segmentation,
S. He and H. Ding, “Decoupling static and hierarchical motion perception for referring video segmentation,” inIEEE Conf. Comput. Vis. Pattern Recog., 2024, pp. 13 332–13 341
2024
-
[3]
URVOS: unified referring video object segmentation network with a large-scale benchmark,
S. Seo, J. Lee, and B. Han, “URVOS: unified referring video object segmentation network with a large-scale benchmark,” inEur . Conf. Comput. Vis., 2020, pp. 208–223
2020
-
[4]
Video object segmentation with language referring expressions,
A. Khoreva, A. Rohrbach, and B. Schiele, “Video object segmentation with language referring expressions,” inACCV, 2018, pp. 123–141
2018
-
[5]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks,
Z. Chen, J. Wu, W. Wang, W. Su, G. Chen, S. Xing, M. Zhong, Q. Zhang, X. Zhu, L. Lu, B. Li, P. Luo, T. Lu, Y . Qiao, and J. Dai, “Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks,”arXiv preprint arXiv:2312.14238, 2023
Pith/arXiv arXiv 2023
-
[6]
Minigpt-4: Enhancing vision-language understanding with advanced large language models,
D. Zhu, J. Chen, X. Shen, X. Li, and M. Elhoseiny, “Minigpt-4: Enhancing vision-language understanding with advanced large language models,” in Int. Conf. Learn. Represent., 2024, pp. 18 378–18 394
2024
-
[7]
Lisa: Reasoning segmentation via large language model,
X. Lai, Z. Tian, Y . Chen, Y . Li, Y . Yuan, S. Liu, and J. Jia, “Lisa: Reasoning segmentation via large language model,” inIEEE Conf. Comput. Vis. Pattern Recog., 2024, pp. 9579–9589
2024
-
[8]
GSV A: generalized segmentation via multimodal large language models,
Z. Xia, D. Han, Y . Han, X. Pan, S. Song, and G. Huang, “GSV A: generalized segmentation via multimodal large language models,” in IEEE Conf. Comput. Vis. Pattern Recog., 2024, pp. 3858–3869
2024
-
[9]
Visa: Reasoning video object segmentation via large language models,
C. Yan, H. Wang, S. Yan, X. Jiang, Y . Hu, G. Kang, W. Xie, and E. Gavves, “Visa: Reasoning video object segmentation via large language models,” inEur . Conf. Comput. Vis., 2024, pp. 98–115
2024
-
[10]
One token to seg them all: Language instructed reasoning segmentation in videos,
Z. Bai, T. He, H. Mei, P. Wang, Z. Gao, J. Chen, L. Liu, Z. Zhang, and M. Z. Shou, “One token to seg them all: Language instructed reasoning segmentation in videos,” inAdv. Neural Inform. Process. Syst., 2024, pp. 6833–6859
2024
-
[11]
T. F. Shipley and J. M. Zacks,Understanding events: From perception to action. Oxford University Press, 2008
2008
-
[12]
Language as queries for referring video object segmentation,
J. Wu, Y . Jiang, P. Sun, Z. Yuan, and P. Luo, “Language as queries for referring video object segmentation,” inIEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 4964–4974
2022
-
[14]
Losh: Long-short text joint prediction network for referring video object segmentation,
L. Yuan, M. Shi, Z. Yue, and Q. Chen, “Losh: Long-short text joint prediction network for referring video object segmentation,” inIEEE Conf. Comput. Vis. Pattern Recog., 2024, pp. 14 001–14 010
2024
-
[15]
Koffka,Principles of Gestalt psychology
K. Koffka,Principles of Gestalt psychology. routledge, 2013
2013
-
[16]
Human memory: A proposed system and its control processes,
R. C. Atkinson, “Human memory: A proposed system and its control processes,”The psychology of learning and motivation, vol. 2, 1968
1968
-
[17]
Actor and action video segmentation from a sentence,
K. Gavrilyuk, A. Ghodrati, Z. Li, and C. G. M. Snoek, “Actor and action video segmentation from a sentence,” inIEEE Conf. Comput. Vis. Pattern Recog., 2018, pp. 5958–5966
2018
-
[18]
Mattnet: Modular attention network for referring expression comprehension,
L. Yu, Z. Lin, X. Shen, J. Yang, X. Lu, M. Bansal, and T. L. Berg, “Mattnet: Modular attention network for referring expression comprehension,” inIEEE Conf. Comput. Vis. Pattern Recog., 2018, pp. 1307–1315
2018
-
[19]
MOSE: A new dataset for video object segmentation in complex scenes,
H. Ding, C. Liu, S. He, X. Jiang, P. H. S. Torr, and S. Bai, “MOSE: A new dataset for video object segmentation in complex scenes,” inInt. Conf. Comput. Vis., 2023, pp. 20 167–20 177
2023
-
[20]
Xmem: Long-term video object segmentation with an atkinson-shiffrin memory model,
H. K. Cheng and A. G. Schwing, “Xmem: Long-term video object segmentation with an atkinson-shiffrin memory model,” inEur . Conf. Comput. Vis., 2022, pp. 640–658
2022
-
[21]
Glus: Global-local reasoning unified into a single large language model for video segmentation,
L. Lin, X. Yu, Z. Pang, and Y .-X. Wang, “Glus: Global-local reasoning unified into a single large language model for video segmentation,” in CVPR, 2025, pp. 8658–8667
2025
-
[22]
Reinforcing video reasoning segmentation to think before it segments,
S. Gong, L. Zhang, Y . Zhuge, X. Jia, P. Zhang, and H. Lu, “Reinforcing video reasoning segmentation to think before it segments,”arXiv preprint arXiv:2508.11538, 2025
arXiv 2025
-
[23]
Deepseekmath: Pushing the limits of mathematical reasoning in open language models,
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wuet al., “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[24]
Vision-language transformer and query generation for referring segmentation,
H. Ding, C. Liu, S. Wang, and X. Jiang, “Vision-language transformer and query generation for referring segmentation,” inInt. Conf. Comput. Vis., 2021, pp. 16 301–16 310
2021
-
[25]
Segmentation from natural language expressions,
R. Hu, M. Rohrbach, and T. Darrell, “Segmentation from natural language expressions,” inEur . Conf. Comput. Vis., 2016, pp. 108–124
2016
-
[26]
VLT: vision-language transformer and query generation for referring segmentation,
H. Ding, C. Liu, S. Wang, and X. Jiang, “VLT: vision-language transformer and query generation for referring segmentation,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 6, pp. 7900–7916, 2023
2023
-
[27]
Lavt: Language-aware vision transformer for referring image segmentation,
Z. Yang, J. Wang, Y . Tang, K. Chen, H. Zhao, and P. H. Torr, “Lavt: Language-aware vision transformer for referring image segmentation,” inIEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 18 155–18 165
2022
-
[28]
Instance-specific feature propagation for referring segmentation,
C. Liu, X. Jiang, and H. Ding, “Instance-specific feature propagation for referring segmentation,”IEEE Trans. Multimedia, vol. 25, pp. 3657–3667, 2022
2022
-
[29]
Referring expression object segmentation with caption-aware consistency,
Y .-W. Chen, Y .-H. Tsai, T. Wang, Y .-Y . Lin, and M.-H. Yang, “Referring expression object segmentation with caption-aware consistency,” inBrit. Mach. Vis. Conf., 2019
2019
-
[30]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdv. Neural Inform. Process. Syst., 2017
2017
-
[31]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, P. Doll ´ar, and R. Girshick, “Segment anything,”arXiv preprint arXiv:2304.02643, 2023
Pith/arXiv arXiv 2023
-
[32]
GRES: Generalized referring expression segmentation,
C. Liu, H. Ding, and X. Jiang, “GRES: Generalized referring expression segmentation,” inIEEE Conf. Comput. Vis. Pattern Recog., 2023, pp. 23 592–23 601
2023
-
[33]
The devil is in temporal token: High quality video reasoning segmentation,
S. Gong, Y . Zhuge, L. Zhang, Z. Yang, P. Zhang, and H. Lu, “The devil is in temporal token: High quality video reasoning segmentation,” in CVPR, 2025, pp. 29 183–29 192
2025
-
[34]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” inAdv. Neural Inform. Process. Syst., 2023, pp. 34 892–34 916
2023
-
[35]
BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. C. H. Hoi, “BLIP-2: bootstrapping language-image pre-training with frozen image encoders and large language models,” inICML, 2023, pp. 19 730–19 742. IEEE TRANSACTIONS ON IMAGE PROCESSING 13
2023
-
[36]
Dualfocus: Integrating macro and micro perspectives in multi-modal large language models,
Y . Cao, P. Zhang, X. Dong, D. Lin, and J. Wang, “Dualfocus: Integrating macro and micro perspectives in multi-modal large language models,” arXiv preprint arXiv:2402.14767, 2024
arXiv 2024
-
[37]
Qwen-vl: A frontier large vision-language model with versatile abilities,
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A frontier large vision-language model with versatile abilities,”arXiv preprint arXiv:2308.12966, 2023
Pith/arXiv arXiv 2023
-
[38]
Improved baselines with visual instruction tuning,
H. Liu, C. Li, Y . Li, and Y . J. Lee, “Improved baselines with visual instruction tuning,” inIEEE Conf. Comput. Vis. Pattern Recog., 2024, pp. 26 286–26 296
2024
-
[39]
BLIV A: A simple multimodal LLM for better handling of text-rich visual questions,
W. Hu, Y . Xu, Y . Li, W. Li, Z. Chen, and Z. Tu, “BLIV A: A simple multimodal LLM for better handling of text-rich visual questions,” in AAAI, 2024, pp. 2256–2264
2024
-
[40]
Chat-univi: Unified visual representation empowers large language models with image and video understanding,
P. Jin, R. Takanobu, W. Zhang, X. Cao, and L. Yuan, “Chat-univi: Unified visual representation empowers large language models with image and video understanding,” inIEEE Conf. Comput. Vis. Pattern Recog., 2024, pp. 13 700–13 710
2024
-
[41]
Image as set of points,
X. Ma, Y . Zhou, H. Wang, C. Qin, B. Sun, C. Liu, and Y . Fu, “Image as set of points,” inInt. Conf. Learn. Represent., 2023
2023
-
[42]
Dynamicvit: Efficient vision transformers with dynamic token sparsification,
Y . Rao, W. Zhao, B. Liu, J. Lu, J. Zhou, and C. Hsieh, “Dynamicvit: Efficient vision transformers with dynamic token sparsification,” inAdv. Neural Inform. Process. Syst., 2021, pp. 13 937–13 949
2021
-
[43]
TESTA: temporal- spatial token aggregation for long-form video-language understanding,
S. Ren, S. Chen, S. Li, X. Sun, and L. Hou, “TESTA: temporal- spatial token aggregation for long-form video-language understanding,” inEMNLP, 2023, pp. 932–947
2023
-
[44]
Masked- attention mask transformer for universal image segmentation,
B. Cheng, I. Misra, A. G. Schwing, A. Kirillov, and R. Girdhar, “Masked- attention mask transformer for universal image segmentation,” inIEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 1280–1289
2022
-
[45]
Roberta: A robustly optimized BERT pretraining approach,
Y . Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V . Stoyanov, “Roberta: A robustly optimized BERT pretraining approach,”arXiv preprint arXiv:1907.11692, 2019
Pith/arXiv arXiv 1907
-
[46]
Groupvit: Semantic segmentation emerges from text supervision,
J. Xu, S. D. Mello, S. Liu, W. Byeon, T. M. Breuel, J. Kautz, and X. Wang, “Groupvit: Semantic segmentation emerges from text supervision,” in IEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 18 113–18 123
2022
-
[47]
Categorical reparameterization with gumbel-softmax,
E. Jang, S. Gu, and B. Poole, “Categorical reparameterization with gumbel-softmax,” inInt. Conf. Learn. Represent., 2017
2017
-
[48]
Neural discrete representation learning,
A. van den Oord, O. Vinyals, and K. Kavukcuoglu, “Neural discrete representation learning,” inAdv. Neural Inform. Process. Syst., 2017
2017
-
[49]
V-net: Fully convolutional neural networks for volumetric medical image segmentation,
F. Milletari, N. Navab, and S. Ahmadi, “V-net: Fully convolutional neural networks for volumetric medical image segmentation,” in3DV, 2016
2016
-
[50]
Towards understanding action recognition,
H. Jhuang, J. Gall, S. Zuffi, C. Schmid, and M. J. Black, “Towards understanding action recognition,” inInt. Conf. Comput. Vis., 2013, pp. 3192–3199
2013
-
[51]
The 2017 DA VIS challenge on video object segmentation,
J. Pont-Tuset, F. Perazzi, S. Caelles, P. Arbel´aez, A. Sorkine-Hornung, and L. V . Gool, “The 2017 DA VIS challenge on video object segmentation,” arXiv preprint arXiv:1704.00675, 2017
Pith/arXiv arXiv 2017
-
[52]
How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites,
Z. Chen, W. Wang, H. Tian, S. Ye, Z. Gao, E. Cui, W. Tong, K. Hu, and et al, “How far are we to gpt-4v? closing the gap to commercial multimodal models with open-source suites,”arXiv preprint arXiv:2404.16821, 2024
Pith/arXiv arXiv 2024
-
[53]
A. Yang, B. Yang, B. Hui, B. Zheng, and et al, “Qwen2 technical report,” arXiv preprint arXiv:2407.10671, 2024
Pith/arXiv arXiv 2024
-
[54]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” in Int. Conf. Learn. Represent., 2019
2019
-
[55]
Language-bridged spatial-temporal interaction for referring video object segmentation,
Z. Ding, T. Hui, J. Huang, X. Wei, J. Han, and S. Liu, “Language-bridged spatial-temporal interaction for referring video object segmentation,” in IEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 4954–4963
2022
-
[56]
Multi-level representation learning with semantic alignment for referring video object segmentation,
D. Wu, X. Dong, L. Shao, and J. Shen, “Multi-level representation learning with semantic alignment for referring video object segmentation,” inIEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 4986–4995
2022
-
[57]
HTML: hybrid temporal-scale multimodal learning framework for referring video object segmentation,
M. Han, Y . Wang, Z. Li, L. Yao, X. Chang, and Y . Qiao, “HTML: hybrid temporal-scale multimodal learning framework for referring video object segmentation,” inInt. Conf. Comput. Vis., 2023, pp. 13 368–13 377
2023
-
[58]
Robust referring video object segmentation with cyclic structural consensus,
X. Li, J. Wang, X. Xu, X. Li, B. Raj, and Y . Lu, “Robust referring video object segmentation with cyclic structural consensus,” inICCV, 2023, pp. 22 179–22 188
2023
-
[59]
Spectrum-guided multi- granularity referring video object segmentation,
B. Miao, M. Bennamoun, Y . Gao, and A. Mian, “Spectrum-guided multi- granularity referring video object segmentation,” inInt. Conf. Comput. Vis., 2023, pp. 920–930
2023
-
[60]
Onlinerefer: A simple online baseline for referring video object segmentation,
D. Wu, T. Wang, Y . Zhang, X. Zhang, and J. Shen, “Onlinerefer: A simple online baseline for referring video object segmentation,” inInt. Conf. Comput. Vis., 2023, pp. 2749–2758
2023
-
[61]
Temporal collection and distribution for referring video object segmentation,
J. Tang, G. Zheng, and S. Yang, “Temporal collection and distribution for referring video object segmentation,” inInt. Conf. Comput. Vis., 2023, pp. 15 420–15 430
2023
-
[62]
SOC: semantic-assisted object cluster for referring video object segmentation,
Z. Luo, Y . Xiao, Y . Liu, S. Li, Y . Wang, Y . Tang, X. Li, and Y . Yang, “SOC: semantic-assisted object cluster for referring video object segmentation,” inAdv. Neural Inform. Process. Syst., 2023, pp. 26 425–26 437
2023
-
[63]
Tracking with human-intent reasoning,
J. Zhu, Z. Cheng, J. He, C. Li, B. Luo, H. Lu, Y . Geng, and X. Xie, “Tracking with human-intent reasoning,”arXiv preprint arXiv:2312.17448, 2023
arXiv 2023
-
[64]
Open-vocabulary semantic segmentation with mask- adapted CLIP,
F. Liang, B. Wu, X. Dai, K. Li, Y . Zhao, H. Zhang, P. Zhang, P. Vajda, and D. Marculescu, “Open-vocabulary semantic segmentation with mask- adapted CLIP,” inIEEE Conf. Comput. Vis. Pattern Recog., 2023, pp. 7061–7070
2023
-
[65]
Generalized decoding for pixel, image, and language,
X. Zou, Z. Dou, J. Yang, Z. Gan, L. Li, C. Li, X. Dai, H. Behl, J. Wang, L. Yuan, N. Peng, L. Wang, Y . J. Lee, and J. Gao, “Generalized decoding for pixel, image, and language,” inIEEE Conf. Comput. Vis. Pattern Recog., 2023, pp. 15 116–15 127
2023
-
[66]
Segment everything everywhere all at once,
X. Zou, J. Yang, H. Zhang, F. Li, L. Li, J. Wang, L. Wang, J. Gao, and Y . J. Lee, “Segment everything everywhere all at once,” inAdv. Neural Inform. Process. Syst., 2023, pp. 19 769–19 782
2023
-
[67]
Grounded SAM: assembling open-world models for diverse visual tasks,
T. Ren, S. Liu, A. Zeng, J. Lin, K. Li, H. Cao, J. Chen, X. Huang, Y . Chen, F. Yan, Z. Zeng, H. Zhang, F. Li, J. Yang, H. Li, Q. Jiang, and L. Zhang, “Grounded SAM: assembling open-world models for diverse visual tasks,”arXiv preprint arXiv:2401.14159, 2024
Pith/arXiv arXiv 2024
-
[68]
Referitgame: Referring to objects in photographs of natural scenes,
S. Kazemzadeh, V . Ordonez, M. Matten, and T. L. Berg, “Referitgame: Referring to objects in photographs of natural scenes,” inEMNLP, 2014, pp. 787–798
2014
-
[69]
Generation and comprehension of unambiguous object descriptions,
J. Mao, J. Huang, A. Toshev, O. Camburu, A. L. Yuille, and K. Murphy, “Generation and comprehension of unambiguous object descriptions,” in IEEE Conf. Comput. Vis. Pattern Recog., 2016, pp. 11–20
2016
-
[70]
Multi-task collaborative network for joint referring expression comprehension and segmentation,
G. Luo, Y . Zhou, X. Sun, L. Cao, C. Wu, C. Deng, and R. Ji, “Multi-task collaborative network for joint referring expression comprehension and segmentation,” inIEEE Conf. Comput. Vis. Pattern Recog., 2020, pp. 10 031–10 040
2020
-
[71]
CRIS: clip-driven referring image segmentation,
Z. Wang, Y . Lu, Q. Li, X. Tao, Y . Guo, M. Gong, and T. Liu, “CRIS: clip-driven referring image segmentation,” inIEEE Conf. Comput. Vis. Pattern Recog., 2022, pp. 11 676–11 685. Jinyu Liureceived the M.S. degree from Fudan University, Shanghai, China, in 2023. He is currently a Ph.D. student at College of Computer Science and Artificial Intelligence, Fud...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.