SFL-MTSC: Leveraging Semantic Frame-Level Multi-Task Self-Consistency for Robust Multi-Intent Spoken Language Understanding
Pith reviewed 2026-06-25 21:04 UTC · model grok-4.3
The pith
Semantic frame-level self-consistency improves slot accuracy in multi-intent spoken language understanding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
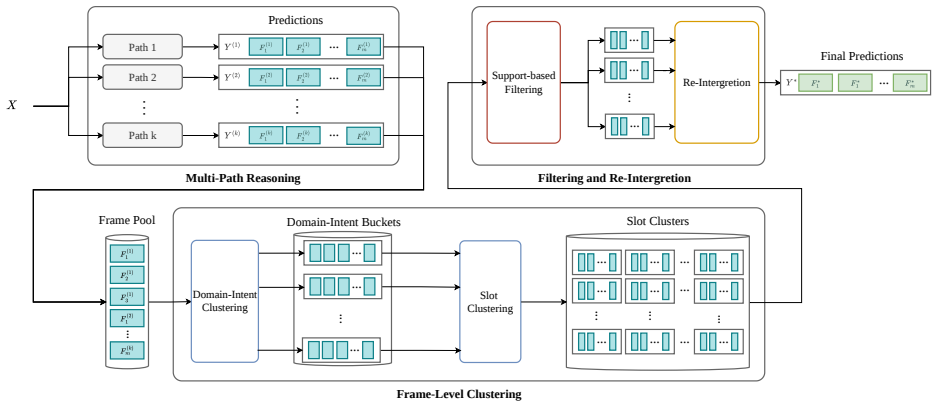
SFL-MTSC decomposes predictions into intent-specific frames, performs domain-intent grouping and slot-level clustering, evaluates reliability with path support scoring, and retains reliable frames for re-integration, yielding higher slot F1 and overall accuracy than single-path inference on the MAC-SLU benchmark.
What carries the argument
Semantic Frame-Level Multi-Task Self-Consistency (SFL-MTSC), a framework that aggregates at the semantic frame level through decomposition, grouping, clustering, and path support scoring instead of output-level majority voting.
If this is right
- Slot F1 and overall accuracy rise over single-path inference in zero-shot multi-intent settings.
- Intent accuracy remains largely stable across most experimental conditions.
- Reliable frames identified by path support scoring can be retained and re-integrated into a final structured prediction.
- The approach targets decoding stochasticity specifically in multi-intent scenarios.
Where Pith is reading between the lines
- Similar frame-level decomposition and support scoring could be tested on other structured prediction tasks where whole-output voting loses internal consistency.
- The method implies that component-level consistency checks may be more effective than output-level voting when semantic structures contain multiple independent elements.
- If the grouping and clustering steps depend on domain knowledge, performance could vary when that knowledge is incomplete or noisy.
Load-bearing premise
Decomposing predictions into intent-specific frames and then grouping, clustering, and scoring them will reliably identify and keep correct structures without introducing selection bias or missing valid combinations.
What would settle it
Running SFL-MTSC on the MAC-SLU benchmark and finding no gain in slot F1 or overall accuracy relative to single-path inference, or finding that valid multi-intent structures are dropped.
Figures

read the original abstract
Prompt-based spoken language understanding (SLU) with large language models (LLMs) often suffers from inconsistent intent--slot structures due to decoding stochasticity, particularly in multi-intent scenarios. In view of this, we propose Semantic Frame-Level Multi-Task Self-Consistency (SFL-MTSC), a novel structured aggregation framework operating at the semantic frame level. Instead of output-level majority voting, SFL-MTSC decomposes predictions into intent-specific frames, applies domain--intent grouping and slot-level clustering, and evaluates cluster reliability using path support scoring. Reliable frames are retained and re-integrated to form the final prediction. Zero-shot experiments on the MAC-SLU benchmark dataset show improved slot F1 and overall accuracy over single-path inference, while intent accuracy remains largely stable across most settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Semantic Frame-Level Multi-Task Self-Consistency (SFL-MTSC), a structured aggregation framework for prompt-based multi-intent spoken language understanding with LLMs. It decomposes LLM predictions into intent-specific semantic frames, applies domain-intent grouping and slot-level clustering, evaluates reliability via path support scoring, and retains reliable frames for re-integration into the final output. This is positioned as an alternative to output-level majority voting. Zero-shot experiments on the MAC-SLU benchmark report improved slot F1 and overall accuracy over single-path inference, with intent accuracy largely stable.
Significance. If the empirical gains hold after proper baseline controls, the work could offer a more structured approach to mitigating decoding inconsistencies in multi-intent SLU scenarios. The method explicitly builds on multiple sampled paths but its added machinery (frame decomposition, clustering, and scoring) would need to demonstrate value beyond simpler aggregation to establish broader impact.
major comments (2)
- [Abstract] Abstract: the positioning of SFL-MTSC as an alternative to output-level majority voting is not supported by any reported comparison to that baseline (or other consistency methods) on the same generated paths; experiments compare only to single-path inference, leaving open whether the frame-level operations are required or if majority voting already captures most gains.
- [Abstract and Experiments] Experiments (and abstract): no details are provided on the implementation of slot-level clustering, path support scoring thresholds, statistical significance testing, error bars, or controls for multiple comparisons, which undermines verification of the reported slot F1 and accuracy improvements on MAC-SLU.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the empirical support for SFL-MTSC.
read point-by-point responses
-
Referee: [Abstract] Abstract: the positioning of SFL-MTSC as an alternative to output-level majority voting is not supported by any reported comparison to that baseline (or other consistency methods) on the same generated paths; experiments compare only to single-path inference, leaving open whether the frame-level operations are required or if majority voting already captures most gains.
Authors: We agree that the abstract's positioning would be better supported by a direct comparison to output-level majority voting (and related consistency methods) performed on the exact same set of sampled paths. The current experiments emphasize gains relative to single-path inference, but adding the requested baseline will clarify whether the frame-level decomposition, grouping, clustering, and scoring provide benefits beyond simpler aggregation. We will include this comparison in the revised version. revision: yes
-
Referee: [Abstract and Experiments] Experiments (and abstract): no details are provided on the implementation of slot-level clustering, path support scoring thresholds, statistical significance testing, error bars, or controls for multiple comparisons, which undermines verification of the reported slot F1 and accuracy improvements on MAC-SLU.
Authors: We acknowledge that the manuscript lacks these reproducibility and statistical details. In the revision we will add: complete specifications of the slot-level clustering procedure and its hyperparameters; the exact definition, formula, and threshold(s) for path support scoring; results with error bars across multiple independent sampling runs; appropriate statistical significance tests with p-values; and any adjustments applied for multiple comparisons. These additions will enable verification of the reported improvements. revision: yes
Circularity Check
No circularity: SFL-MTSC is a new procedural aggregation method with independent empirical claims
full rationale
The paper presents SFL-MTSC as a novel decomposition into intent-specific frames followed by domain-intent grouping, slot-level clustering, and path support scoring to form final predictions, explicitly contrasting it with output-level majority voting. No equations, fitted parameters, or self-citations are described that would cause any prediction or result to reduce by construction to its own inputs. The performance claims rest on zero-shot experiments versus single-path inference on MAC-SLU rather than any tautological derivation. This is a standard case of a self-contained empirical proposal without load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
I want to know the weather in Taipei
Introduction Spoken Language Understanding (SLU) is a fundamental paradigm for task-oriented spoken semantics extraction, widely applied in scenarios such as smart homes and in-vehicle systems to interpret user spoken commands for executing downstream tasks [1]. It typically consists of two core subtasks: intent de- tection and slot filling [2]. For examp...
-
[2]
Proposed Approach In this section, we illustrate the workflow of SFL-MTSC as Figure 1. Unlike standard majority voting, which operates on the final output level, SFL-MTSC decomposes each reasoning path into intent-specific semantic frames and evaluates struc- tural consistency at the frame level. This allows the framework to selectively retain stable fram...
Pith/arXiv arXiv 2026
-
[3]
Experiments 3.1. Experiment Setting 3.1.1. Datasets We evaluate on MAC-SLU [12], a Chinese multi-intent SLU dataset for automotive cabin scenarios, spanning 8 domains, 81 intents, and 192 slot types with up to 4 simultaneous intents per utterance. Semantic annotations are structured as semantic frames, consistent with the frame-level design of SFL-MTSC. 3...
-
[4]
It decom- poses predictions into intent-specific frames, applies Hybrid Jaccard slot clustering, and filters unreliable frames via path support scoring
Conclusion We proposed SFL-MTSC, a semantic frame-level self- consistency framework for robust multi-intent SLU. It decom- poses predictions into intent-specific frames, applies Hybrid Jaccard slot clustering, and filters unreliable frames via path support scoring. Zero-shot experiments on MAC-SLU show consistent improvements in Overall Acc. and Slot F1, ...
-
[5]
Any findings and implications in the paper do not necessarily reflect those of the sponsors
Acknowledgments This work was supported in part by Realtek Semiconductor Cor- poration under Grant Numbers 113KK01103 and 114KK01005. Any findings and implications in the paper do not necessarily reflect those of the sponsors
-
[6]
We also used AI tools to assist with code de- velopment, with strict human review and verification to ensure correctness
Generative AI Use Disclosure We used Claude Sonnet 4.6 to assist with editing and polishing the manuscript. We also used AI tools to assist with code de- velopment, with strict human review and verification to ensure correctness
-
[7]
Tur and R
G. Tur and R. De Mori,Spoken Language Understanding: Sys- tems for Extracting Semantic Information from Speech. John Wiley & Sons, 2011
2011
-
[8]
A survey on spoken language understanding: Recent advances and new frontiers,
L. Qin, T. Xie, W. Che, and T. Liu, “A survey on spoken language understanding: Recent advances and new frontiers,” inProceed- ings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, Z.-H. Zhou, Ed. International Joint Con- ferences on Artificial Intelligence Organization, Aug. 2021, pp. 4577–4584
2021
-
[9]
A preliminary evaluation of chatgpt for zero-shot dialogue understanding,
W. Pan, Q. Chen, X. Xu, W. Che, and L. Qin, “A preliminary evaluation of chatgpt for zero-shot dialogue understanding,”arXiv preprint arXiv:2304.04256, 2023
arXiv 2023
-
[10]
Zero-shot spoken language understanding via large language models: A preliminary study,
Z. Zhu, X. Cheng, H. An, Z. Wang, D. Chen, and Z. Huang, “Zero-shot spoken language understanding via large language models: A preliminary study,” inProceedings of the 2024 Joint In- ternational Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). Torino, Italia: ELRA and ICCL, May 2024, pp. 17 877–17 883
2024
-
[11]
CroPrompt: Cross-task Interactive Prompting for Zero- Shot Spoken Language Understanding,
L. Qin, F. Wei, Q. Chen, J. Zhou, S. Huang, J. Si, W. Lu, and W. Che, “CroPrompt: Cross-task Interactive Prompting for Zero- Shot Spoken Language Understanding,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Hyderabad, India: IEEE, Apr. 2025, pp. 1–5
2025
-
[12]
DXA-Net: Dual- Task Cross-Lingual Alignment Network for Zero-Shot Cross- Lingual Spoken Language Understanding,
B. Xing, L. Qin, Z. Zhu, Z. Yu, and I. W. Tsang, “DXA-Net: Dual- Task Cross-Lingual Alignment Network for Zero-Shot Cross- Lingual Spoken Language Understanding,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 2, pp. 1052–1062, Feb. 2026
2026
-
[13]
How ChatGPT is Robust for Spoken Language Understanding?
G. Li, L. Chen, and K. Yu, “How ChatGPT is Robust for Spoken Language Understanding?” inInterspeech 2023, 2023, pp. 2163– 2167
2023
-
[14]
A unified framework for multi-intent spoken language understanding with prompting,
F. Song, L. Huang, and H. Wang, “A unified framework for multi-intent spoken language understanding with prompting,” in ICASSP 2024 - 2024 IEEE International Conference on Acous- tics, Speech and Signal Processing (ICASSP), 2024, pp. 9966– 9970
2024
-
[15]
Intent detection in the age of LLMs,
G. Arora, S. Jain, and S. Merugu, “Intent detection in the age of LLMs,” inProceedings of the 2024 Conference on Empiri- cal Methods in Natural Language Processing: Industry Track. Miami, Florida, US: Association for Computational Linguistics, Nov. 2024, pp. 1559–1570
2024
-
[16]
WavPrompt: Towards Few-Shot Spoken Language Un- derstanding with Frozen Language Models,
H. Gao, J. Ni, K. Qian, Y . Zhang, S. Chang, and M. Hasegawa- Johnson, “WavPrompt: Towards Few-Shot Spoken Language Un- derstanding with Frozen Language Models,” inInterspeech 2022, 2022, pp. 2738–2742
2022
-
[17]
Prompting Whisper for QA- driven Zero-shot End-to-end Spoken Language Understanding,
M. Li, S. Keizer, and R. Doddipatla, “Prompting Whisper for QA- driven Zero-shot End-to-end Spoken Language Understanding,” inInterspeech 2024, 2024, pp. 1330–1334
2024
-
[18]
MAC-SLU: Multi-Intent Automotive Cabin Spoken Language Understanding Benchmark,
Y . Peng, C. Cai, Z. Liu, S. Fan, S. Jiang, H. Xu, Y . Liu, Q. Chen, K. Xu, Y . Li, S. Wang, L. Qin, and X. Chen, “MAC-SLU: Multi-Intent Automotive Cabin Spoken Language Understanding Benchmark,”arXiv preprint arXiv:2512.01603, Dec. 2025
arXiv 2025
-
[19]
Self-Consistency Improves Chain of Thought Reasoning in Language Models,
X. Wang, J. Wei, D. Schuurmans, Q. V . Le, E. H. Chi, S. Narang, A. Chowdhery, and D. Zhou, “Self-Consistency Improves Chain of Thought Reasoning in Language Models,” inThe Eleventh International Conference on Learning Representations (ICLR 2023), May 2023
2023
-
[20]
Confidence Improves Self- Consistency in LLMs,
A. Taubenfeld, T. Sheffer, E. Ofek, A. Feder, A. Gold- stein, Z. Gekhman, and G. Yona, “Confidence Improves Self- Consistency in LLMs,” inFindings of the Association for Com- putational Linguistics: ACL 2025. Vienna, Austria: Association for Computational Linguistics, Jul. 2025, pp. 20 090–20 111
2025
-
[21]
Universal Self-Consistency for Large Language Models,
X. Chen, R. Aksitov, U. Alon, J. Ren, K. Xiao, P. Yin, S. Prakash, C. Sutton, X. Wang, and D. Zhou, “Universal Self-Consistency for Large Language Models,” inICML 2024 Workshop on In-Context Learning, Jul. 2024
2024
-
[22]
Better patching using llm prompting, via self-consistency,
T. Ahmed and P. Devanbu, “Better patching using llm prompting, via self-consistency,” in2023 38th IEEE/ACM International Con- ference on Automated Software Engineering (ASE), Sep. 2023, pp. 1742–1746
2023
-
[23]
Estimating the self-consistency of LLMs,
R. Nowak, “Estimating the self-consistency of LLMs,”arXiv preprint arXiv:2509.19489, 2025
arXiv 2025
-
[24]
HIT- SCIR at MMNLU-22: Consistency Regularization for Multilin- gual Spoken Language Understanding,
B. Zheng, Z. Li, F. Wei, Q. Chen, L. Qin, and W. Che, “HIT- SCIR at MMNLU-22: Consistency Regularization for Multilin- gual Spoken Language Understanding,” inProceedings of the Massively Multilingual Natural Language Understanding Work- shop (MMNLU-22). Abu Dhabi, United Arab Emirates: Associ- ation for Computational Linguistics, Dec. 2022, pp. 35–41
2022
-
[25]
A survey on LLM-as-a-judge,
J. Gu, X. Jiang, Z. Shi, H. Tan, X. Zhai, C. Xu, W. Li, Y . Shen, S. Ma, H. Liu, S. Wang, K. Zhang, Z. Lin, B. Zhang, L. Ni, W. Gao, Y . Wang, and J. Guo, “A survey on LLM-as-a-judge,” The Innovation, vol. 7, no. 6, p. 101253, 2026
2026
-
[26]
From generation to judgment: Opportunities and chal- lenges of LLM-as-a-judge,
D. Li, B. Jiang, L. Huang, A. Beigi, C. Zhao, Z. Tan, A. Bhat- tacharjee, Y . Jiang, C. Chen, T. Wu, K. Shu, L. Cheng, and H. Liu, “From generation to judgment: Opportunities and chal- lenges of LLM-as-a-judge,” inProceedings of the 2025 Con- ference on Empirical Methods in Natural Language Processing. Suzhou, China: Association for Computational Linguist...
2025
-
[27]
Limitations of the LLM-as-a-Judge approach for evaluating LLM outputs in expert knowledge tasks,
A. Szymanski, N. Ziems, H. A. Eicher-Miller, T. J.-J. Li, M. Jiang, and R. A. Metoyer, “Limitations of the LLM-as-a-Judge approach for evaluating LLM outputs in expert knowledge tasks,” inPro- ceedings of the 30th International Conference on Intelligent User Interfaces, ser. IUI ’25. New York, NY , USA: Association for Computing Machinery, 2025, pp. 952–966
2025
-
[28]
Association rule mining: A sur- vey,
Q. Zhao and S. S. Bhowmick, “Association rule mining: A sur- vey,” CAIS, Nanyang Technological University, Singapore, Tech. Rep. 2003116, 2003
2003
-
[29]
Negative association rule,
“Negative association rule,” inAssociation Rule Mining: Models and Algorithms, C. Zhang and S. Zhang, Eds. Berlin, Heidelberg: Springer Berlin Heidelberg, 2002, pp. 47–84
2002
-
[30]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lvet al., “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
Pith/arXiv arXiv 2025
-
[31]
Robust speech recognition via large-scale weak su- pervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak su- pervision,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[32]
Qwen2.5-omni technical report,
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y . Fan, K. Dang, B. Zhang, X. Wang, Y . Chu, and J. Lin, “Qwen2.5-omni technical report,”arXiv preprint arXiv:2503.20215, 2025
Pith/arXiv arXiv 2025
-
[33]
A Graph Model for Unsupervised Lexical Acquisition,
D. Widdows and B. Dorow, “A Graph Model for Unsupervised Lexical Acquisition,” inCOLING 2002: The 19th International Conference on Computational Linguistics, 2002
2002
-
[34]
´Etude comparative de la distribution florale dans une portion des alpes et des jura,
P. Jaccard, “ ´Etude comparative de la distribution florale dans une portion des alpes et des jura,”Bull Soc Vaudoise Sci Nat, vol. 37, pp. 547–579, 1901
1901
-
[35]
Reasoning aware self- consistency: Leveraging reasoning paths for efficient LLM sam- pling,
G. Wan, Y . Wu, J. Chen, and S. Li, “Reasoning aware self- consistency: Leveraging reasoning paths for efficient LLM sam- pling,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Lin- guistics: Human Language Technologies (Volume 1: Long Pa- pers). Albuquerque, New Mexico: Association for Com...
2025
-
[36]
Efficient memory management for large language model serving with PagedAttention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gon- zalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with PagedAttention,” inPro- ceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23). New York, NY , USA: Association for Computing Machinery, 2023, pp. 611–626
2023
-
[37]
vLLM-Omni: Fully Disaggregated Serving for Any-to-Any Multimodal Models,
P. Yin, J. Zhu, H. Gao, C. Zheng, Y . Huang, T. Zhou, R. Yang, W. Liu, W. Chen, C. Guo, D. Deng, Z. Mo, C. Wang, J. Cheng, R. Wang, and H. Liu, “vLLM-Omni: Fully Disaggregated Serving for Any-to-Any Multimodal Models,”arXiv preprint arXiv:2602.02204, Feb. 2026
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.