Critic-Driven Voronoi-Quantization for Distilling Deep RL Policies to Explainable Models
Pith reviewed 2026-06-30 21:12 UTC · model grok-4.3
The pith
Critic-driven Voronoi partitioning distills deep RL policies into a small set of linear functions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
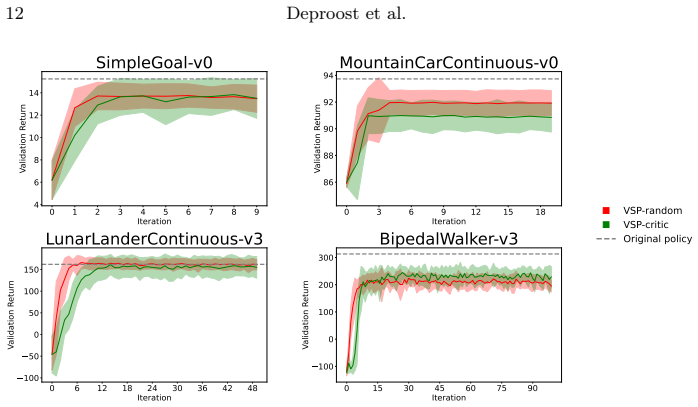
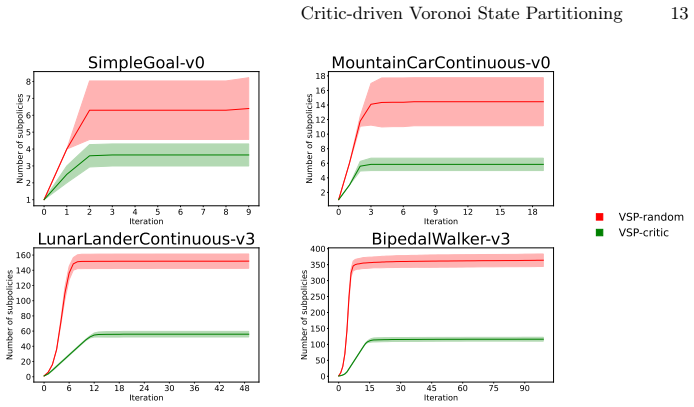
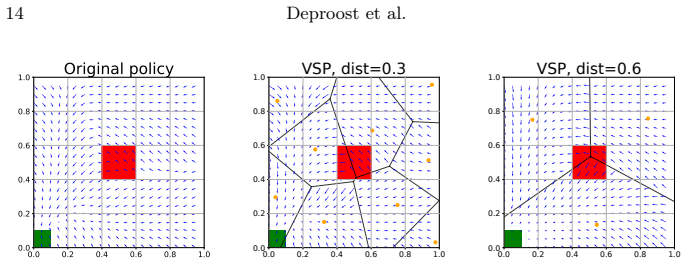
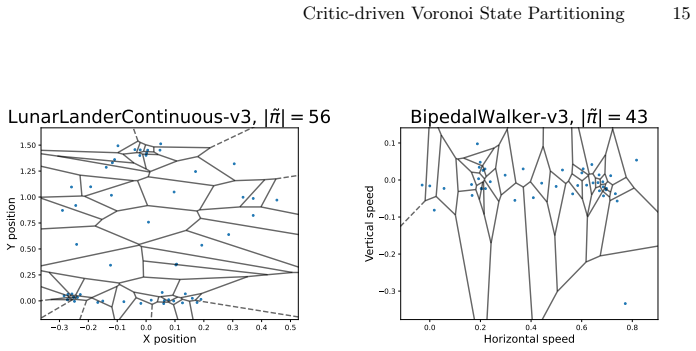
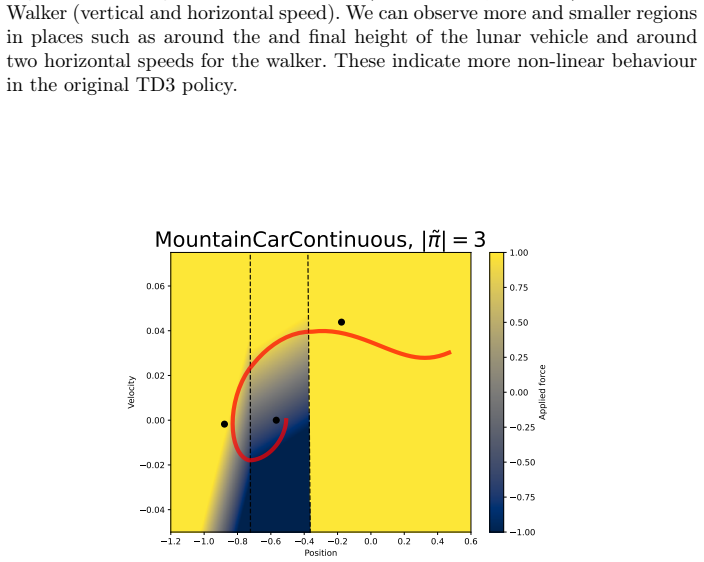
The paper claims that Critic-Driven Voronoi State Partitioning can turn a black-box deep RL policy into a collection of linear subpolicies. The method iteratively places new linear functions in state-space regions where the critic reports insufficient value, then uses a Voronoi quantizer with nearest-neighbor assignment to map every state to its nearest linear piece. Gradient descent optimizes each linear function inside its cell. On standard benchmarks the resulting model approximates the original policy's behavior with a reasonable number of such pieces.
What carries the argument
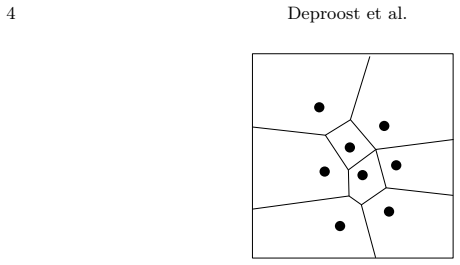
Critic-Driven Voronoi State Partitioning: a Voronoi quantizer that assigns linear functions to state-space regions via nearest-neighbor lookup, with the critic value network used to iteratively introduce new subpolicies where value is insufficient.
If this is right
- A modest number of linear functions suffices to approach the original policy's returns.
- The method incorporates critic value information rather than minimizing only behavioral distance.
- The resulting cell diagram assigns every state to exactly one linear subpolicy through nearest-neighbor lookup.
- Gradient descent can optimize the parameters of each linear function inside its assigned region.
- The approach applies to multiple standard RL benchmark environments.
Where Pith is reading between the lines
- The cell diagram might allow direct inspection of which linear piece is active in any given region, aiding manual verification.
- The same critic-guided placement rule could be tested with other simple surrogate classes such as shallow trees.
- If the number of pieces stays small across more domains, the method could reduce memory needed to store or transmit the policy.
Load-bearing premise
The critic value network supplies a reliable, non-circular signal for where additional linear subpolicies are needed to reduce overall policy complexity.
What would settle it
On the same benchmarks, the method either requires dozens of linear functions to reach the reported performance level or the distilled policy's returns fall substantially below the original policy's returns.
Figures
read the original abstract
Despite many successful attempts at explaining Deep Reinforcement Learning policies using distillation, it remains difficult to balance the performance-interpretability trade-off and select a fitting surrogate model. In addition to this, traditional distillation only minimizes the distance between the behavior of the original and the surrogate policy while other RL-specific components such as action value are disregarded. To solve this, we introduce a new model-agnostic method called Critic-Driven Voronoi State Partitioning, which partitions a black box control policy into regions where a simple class of model can be optimized using gradient descent. By exploiting the critic value network of the original policy, we iteratively introduce new subpolicies in regions with insufficient value, standing in for a measure of policy complexity. The partitioning, a Voronoi quantizer, uses nearest neighbor lookups to assign a linear function to each point in the state space resulting in a cell-like diagram. We validate our approach on several well known benchmarks and proof that this distillation approaches the original policy using a reasonable sized set of linear functions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Critic-Driven Voronoi State Partitioning, a model-agnostic distillation technique that partitions the state space of a black-box deep RL policy into Voronoi cells, each assigned an optimized linear subpolicy. It iteratively adds new subpolicies in regions flagged by the original policy's critic value network as having insufficient value (serving as a proxy for complexity), with nearest-neighbor assignment yielding the final surrogate. The central claim is that this produces an explainable linear model that approaches the original policy's performance using a reasonable number of components, validated on standard RL benchmarks.
Significance. If the empirical results hold and the critic-based partitioning is shown to be reliable, the method would provide a concrete advance in explainable RL by moving beyond pure behavior cloning to incorporate value information, potentially yielding more compact and interpretable surrogates than existing distillation approaches.
major comments (2)
- [Abstract / iterative introduction of subpolicies] Abstract and method description of the iterative procedure: the fixed critic value network is used to identify regions needing additional linear subpolicies, yet no mechanism is described for re-evaluating or correcting the critic under the evolving surrogate's state distribution; this directly risks misalignment and must be addressed to support the claim that the approach 'approaches the original policy'.
- [Validation / benchmarks] Validation section (benchmarks and results): the manuscript asserts that the distillation 'approaches the original policy using a reasonable sized set of linear functions' but provides no quantitative details on performance gaps, number of cells used, baselines, or statistical significance in the visible description, leaving the central empirical claim unsupported.
minor comments (2)
- [Abstract] Abstract uses 'proof' for what appears to be empirical validation; rephrase to 'demonstrate' or 'show empirically'.
- The Voronoi quantizer and linear function assignment lack explicit equations or pseudocode in the high-level description; adding these would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / iterative introduction of subpolicies] Abstract and method description of the iterative procedure: the fixed critic value network is used to identify regions needing additional linear subpolicies, yet no mechanism is described for re-evaluating or correcting the critic under the evolving surrogate's state distribution; this directly risks misalignment and must be addressed to support the claim that the approach 'approaches the original policy'.
Authors: We acknowledge that the manuscript describes the critic as fixed from the original policy and does not detail any re-evaluation step under the surrogate's state distribution. This is a valid concern regarding potential misalignment. In revision we will expand the method section with an explicit discussion of this design choice (the critic serves as a static proxy for the target policy's value landscape) together with a short analysis of the resulting distribution shift; if the analysis indicates material risk we will also add an optional re-evaluation procedure. revision: yes
-
Referee: [Validation / benchmarks] Validation section (benchmarks and results): the manuscript asserts that the distillation 'approaches the original policy using a reasonable sized set of linear functions' but provides no quantitative details on performance gaps, number of cells used, baselines, or statistical significance in the visible description, leaving the central empirical claim unsupported.
Authors: The full manuscript contains benchmark results and figures, yet we agree that the quantitative support for the central claim is not presented with sufficient clarity or detail. We will revise the validation section to include a summary table reporting performance gaps to the original policy, the number of Voronoi cells, comparisons against behavior-cloning baselines, and statistical significance (means and standard errors over multiple random seeds). revision: yes
Circularity Check
No circularity detected; derivation uses external critic signal
full rationale
The paper's core construction iteratively adds linear subpolicies in regions flagged by the original policy's fixed critic value network. This critic is an input taken from the pretrained deep RL agent and is not defined in terms of, fitted to, or updated from the surrogate Voronoi-quantized model. No equations or steps reduce a claimed prediction to a fitted parameter by construction, and the provided text invokes no self-citations, uniqueness theorems, or ansatzes from prior author work. The method therefore remains self-contained against an independent external benchmark (the original policy's critic) rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The critic value network accurately indicates regions where the current linear approximation is insufficient.
Reference graph
Works this paper leans on
-
[1]
and Veness, Joel and Bellemare, Marc G
Volodymyr Mnih et al. “Human-Level Control through Deep Reinforce- ment Learning”. In:Nature518.7540 (Feb. 2015), pp. 529–533.issn: 0028- 0836, 1476-4687.doi:10.1038/nature14236
-
[2]
Continuous control with deep reinforcement learning
Timothy P. Lillicrap et al.Continuous Control with Deep Reinforcement Learning. https://arxiv.org/abs/1509.02971v6. Sept. 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[3]
A Survey of Reinforcement Learning Algorithms for Dynamically Varying Environments
Sindhu Padakandla. “A Survey of Reinforcement Learning Algorithms for Dynamically Varying Environments”. In:ACM Computing Surveys54.6 (July 2022), pp. 1–25.issn: 0360-0300, 1557-7341.doi:10.1145/3459991
-
[4]
A Tour of Reinforcement Learning: The View from Con- tinuous Control
Benjamin Recht. “A Tour of Reinforcement Learning: The View from Con- tinuous Control”. In:Annual Review of Control, Robotics, and Autonomous Systems2.1 (May 2019), pp. 253–279.issn: 2573-5144, 2573-5144.doi: 10.1146/annurev-control-053018-023825
-
[5]
Explanation in Artificial Intelligence:
Tim Miller. “Explanation in Artificial Intelligence: Insights from the Social Sciences”. In:Artificial Intelligence267 (Feb. 2019), pp. 1–38.issn: 0004- 3702.doi:10.1016/j.artint.2018.07.007
-
[6]
Daniel Hein, Steffen Udluft, and Thomas A. Runkler. “Generating Inter- pretable Fuzzy Controllers Using Particle Swarm Optimization and Ge- neticProgramming”.In:Proceedings of the Genetic and Evolutionary Com- putation Conference Companion. Kyoto Japan: ACM, July 2018, pp. 1268– 1275.isbn: 978-1-4503-5764-7.doi:10.1145/3205651.3208277
-
[7]
Imitation-Projected Programmatic Reinforcement Learning
Abhinav Verma et al. “Imitation-Projected Programmatic Reinforcement Learning”.In:Advances in Neural Information Processing Systems.Vol.32. Curran Associates, Inc., 2019
2019
-
[8]
Explainable Reinforcement Learning (XRL): A Sys- tematic Literature Review and Taxonomy
Yanzhe Bekkemoen. “Explainable Reinforcement Learning (XRL): A Sys- tematic Literature Review and Taxonomy”. In:Machine Learning(Nov. 2023).issn: 0885-6125, 1573-0565.doi:10.1007/s10994-023-06479-7
-
[9]
Nicholas Frosst and Geoffrey Hinton.Distilling a Neural Network Into a Soft Decision Tree. Nov. 2017. arXiv:1711.09784 [cs, stat]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
Andrei A. Rusu et al. “Policy Distillation”. In:International Conference on Learning Representations. Vol. abs/1511.06295. San Diego, CA, USA, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[11]
Sutton and Andrew Barto.Reinforcement Learning: An Intro- duction
Richard S. Sutton and Andrew Barto.Reinforcement Learning: An Intro- duction. Nachdruck. Adaptive Computation and Machine Learning. Cam- bridge, Massachusetts: The MIT Press, 2014.isbn: 978-0-262-19398-6
2014
-
[12]
A Markovian Decision Process
Richard Bellman. “A Markovian Decision Process”. In:Indiana University Mathematics Journal6 (1957), pp. 679–684
1957
-
[13]
A Natural Policy Gradient
Sham M Kakade. “A Natural Policy Gradient”. In:Advances in Neural Information Processing Systems. Vol. 14. MIT Press, 2001
2001
-
[14]
Q-Learning
Christopher J. C. H. Watkins and Peter Dayan. “Q-Learning”. In:Machine Learning8.3 (May 1992), pp. 279–292.issn: 1573-0565.doi:10.1007/ BF00992698
1992
-
[15]
Actor-Critic Algorithms
Vijay Konda and John Tsitsiklis. “Actor-Critic Algorithms”. In:Advances in Neural Information Processing Systems. Vol. 12. MIT Press, 1999. 18 Deproost et al
1999
-
[16]
Soft Actor-Critic: Off-policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Tuomas Haarnoja et al. “Soft Actor-Critic: Off-policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor”. In:Proceedings of the 35th International Conference on Machine Learning. Ed. by Jen- nifer Dy and Andreas Krause. Vol. 80. Proceedings of Machine Learning Research. PMLR, July 2018, pp. 1861–1870
2018
-
[17]
John Schulman et al.Proximal Policy Optimization Algorithms. Aug. 2017. doi:10.48550/arXiv.1707.06347. arXiv:1707.06347 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1707.06347 2017
-
[18]
UjjwalDasGupta,ErikTalvitie,andMichaelBowling.“PolicyTree: Adap- tive Representation for Policy Gradient”. In:Proceedings of the AAAI Con- ference on Artificial Intelligence29.1 (Feb. 2015).doi:10.1609/aaai. v29i1.9613
-
[19]
Finding and Visualizing Weaknesses of Deep Reinforcement Learning Agents
Christian Rupprecht, Cyril Ibrahim, and Christopher J Pal. “Finding and Visualizing Weaknesses of Deep Reinforcement Learning Agents”. In:In- ternational Conference on Learning Representations. 2020
2020
-
[20]
Explaining Deep Adaptive Programs via Reward De- composition
Martin Erwig et al. “Explaining Deep Adaptive Programs via Reward De- composition”. In:IJCAI/ECAI Workshop on Explainable Artificial Intel- ligence. 2018
2018
-
[21]
Toward a Psychology of Deep Reinforce- ment Learning Agents Using a Cognitive Architecture
Konstantinos Mitsopoulos et al. “Toward a Psychology of Deep Reinforce- ment Learning Agents Using a Cognitive Architecture”. In:Topics in cog- nitive science(2021)
2021
-
[22]
Understanding Individual Agent Importance in Multi-Agent System via Counterfactual Reasoning
Jianming Chen et al. “Understanding Individual Agent Importance in Multi-Agent System via Counterfactual Reasoning”. In:Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty- Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intelli- gence....
-
[23]
R. Gray. “Vector Quantization”. In:IEEE ASSP Magazine1.2 (Apr. 1984), pp. 4–29.issn: 1558-1284.doi:10.1109/MASSP.1984.1162229
-
[24]
Communications of the ACM , issue_date =
Jon Louis Bentley. “Multidimensional Binary Search Trees Used for As- sociative Searching”. In:Communications of the ACM18.9 (Sept. 1975), pp. 509–517.issn: 0001-0782, 1557-7317.doi:10.1145/361002.361007
-
[25]
Some Methods for Classification and Analysis of Multi- Variate Observations
J. B. MacQueen. “Some Methods for Classification and Analysis of Multi- Variate Observations”. In:Proc. of the Fifth Berkeley Symposium on Math- ematical Statistics and Probability. Ed. by L. M. Le Cam and J. Neyman. Vol. 1. University of California Press, 1967, pp. 281–297
1967
-
[26]
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. “"Why Should I Trust You?": Explaining the Predictions of Any Classifier”. In:Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Dis- covery and Data Mining. Kdd ’16. San Francisco, California, USA and New York, NY, USA: Association for Computing Machinery, 2016, pp. 1135– 1144....
-
[27]
Alejandro Barredo Arrieta et al. “Explainable Artificial Intelligence (XAI): Concepts, Taxonomies, Opportunities and Challenges toward Responsible Critic-driven Voronoi State Partitioning 19 AI”. In:Information Fusion58 (June 2020), pp. 82–115.issn: 15662535. doi:10.1016/j.inffus.2019.12.012
-
[28]
Vilde B. Gjærum et al. “Explaining a Deep Reinforcement Learning Dock- ing Agent Using Linear Model Trees with User Adapted Visualization”. In:Journal of Marine Science and Engineering9.11 (Oct. 2021), p. 1178. issn: 2077-1312.doi:10.3390/jmse9111178. arXiv:2203.00368 [cs]
-
[29]
Toward Interpretable Deep Reinforcement Learning with Linear Model U-Trees
Guiliang Liu et al. “Toward Interpretable Deep Reinforcement Learning with Linear Model U-Trees”. In:Machine Learning and Knowledge Dis- covery in Databases. Ed. by Michele Berlingerio et al. Vol. 11052. Cham: Springer International Publishing, 2019, pp. 414–429.isbn: 978-3-030- 10927-1 978-3-030-10928-8.doi:10.1007/978-3-030-10928-8_25
-
[30]
On the Performance and Ro- bustness of Linear Model U-Trees in Mimic Learning
Matthew Green and John W. Sheppard. “On the Performance and Ro- bustness of Linear Model U-Trees in Mimic Learning”. In:2024 Interna- tional Conference on Machine Learning and Applications (ICMLA). Mi- ami, FL, USA: IEEE, Dec. 2024, pp. 152–159.isbn: 979-8-3503-7488-9. doi:10.1109/ICMLA61862.2024.00027
-
[31]
Interpretable and Editable Programmatic Tree Poli- cies for Reinforcement Learning
Hector Kohler et al. “Interpretable and Editable Programmatic Tree Poli- cies for Reinforcement Learning”. In:17th European Workshop on Rein- forcement Learning. Toulouse, Oct. 2024
2024
-
[32]
Distilling Deep Reinforcement Learning Policies in Soft Decision Trees
Youri Coppens et al. “Distilling Deep Reinforcement Learning Policies in Soft Decision Trees”. In:ProceedingsoftheIJCAI2019Workshop onExplain- ableArtificialIntelligence. 2019, pp. 1–6
2019
-
[33]
Adaptive State Space Partitioning for Reinforcement Learning
Ivan S.K. Lee and Henry Y.K. Lau. “Adaptive State Space Partitioning for Reinforcement Learning”. In:Engineering Applications of Artificial In- telligence17.6 (Sept. 2004), pp. 577–588.issn: 09521976.doi:10.1016/ j.engappai.2004.08.005
2004
-
[34]
In: 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems
Riad Akrour et al. “Regularizing Reinforcement Learning with State Ab- straction”. In:2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Oct. 2018, pp. 534–539.doi:10.1109/IROS. 2018.8594201
-
[35]
Mark Towers et al.Gymnasium: A Standard Interface for Reinforcement Learning Environments. Nov. 2024.doi:10.48550/arXiv.2407.17032. arXiv:2407.17032 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.17032 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.