Reinforcing Dual-Path Reasoning in Spatial Vision Language Models
Pith reviewed 2026-06-27 01:39 UTC · model grok-4.3
The pith
Reinforcement learning trains one spatial VLM to use both language deduction and 3D detection paths
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
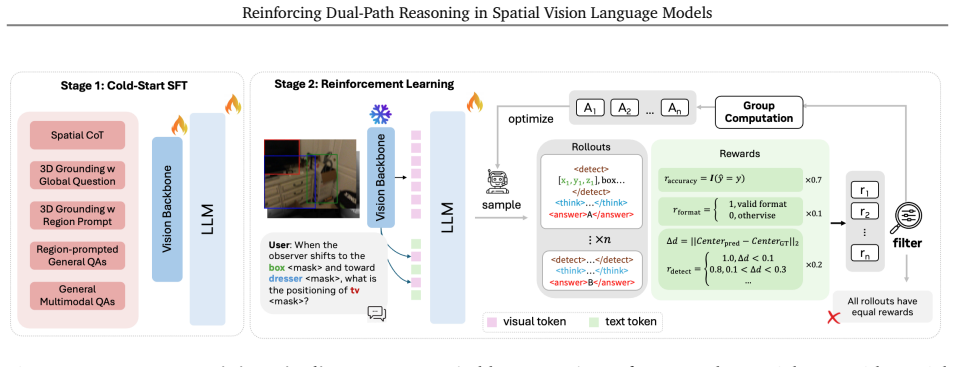
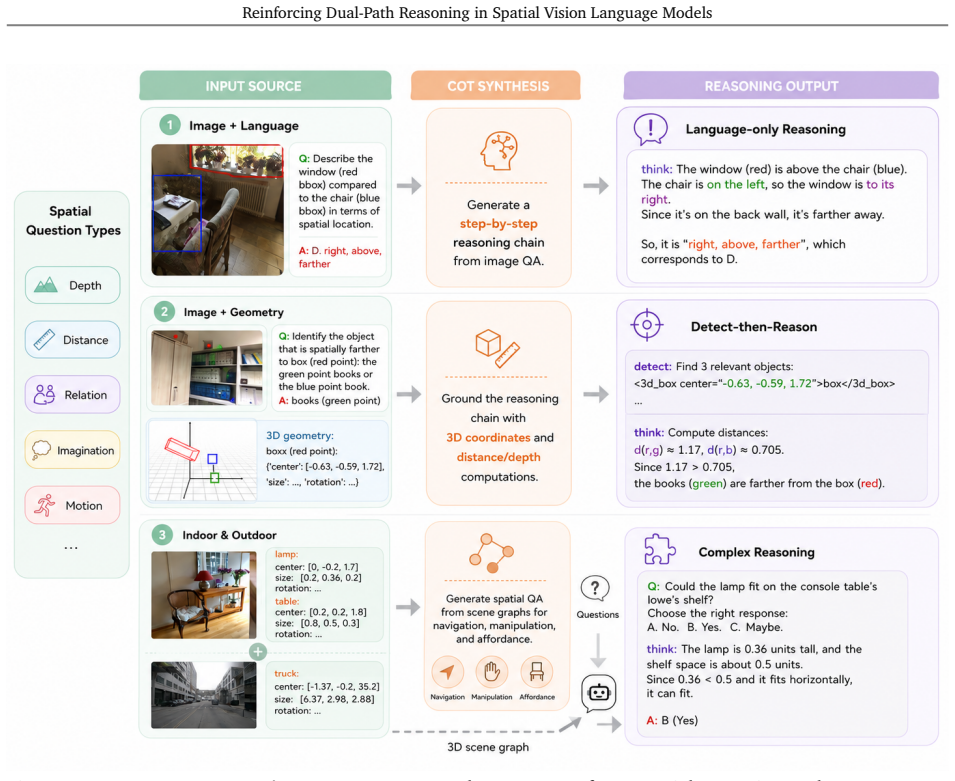
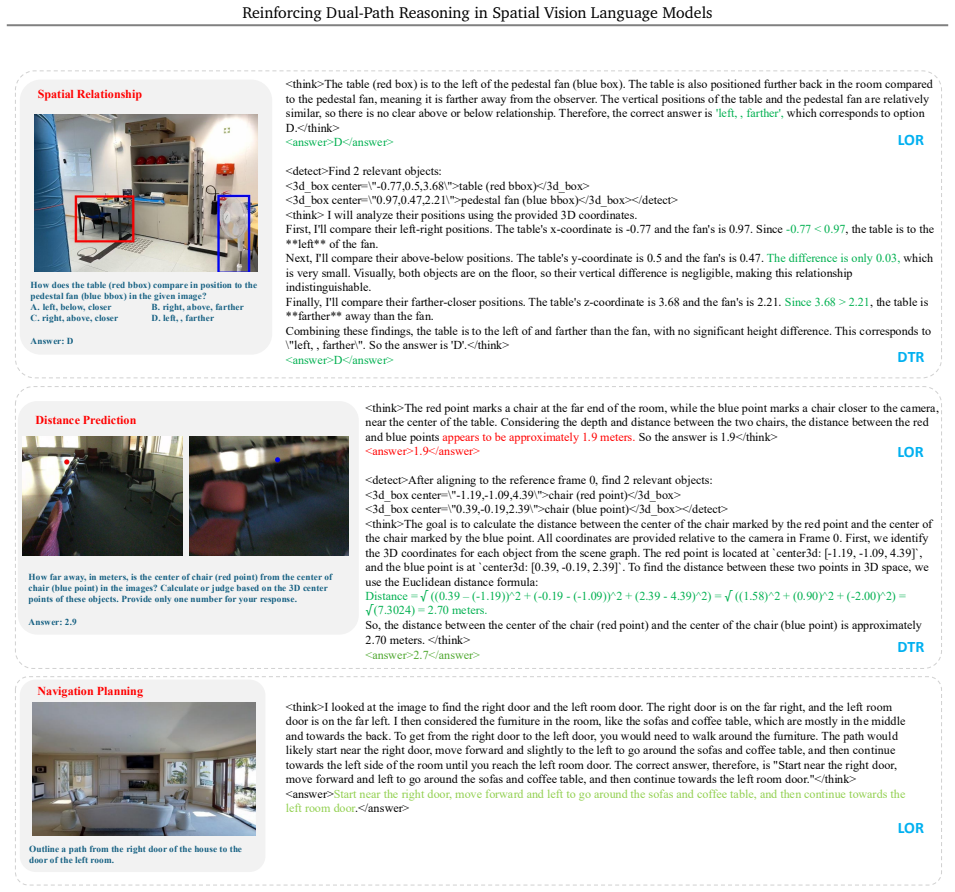
SR-REAL equips a spatial VLM with Language-Only Reasoning for pure linguistic deduction and Detect-Then-Reason for first locating 3D cues like centers or boxes then performing geometric inference. After blended cold-start supervision and RL with accuracy, format, and discrete center-based detection rewards, the model supports both paths in one policy. DTR excels at region-aware tasks through precise 3D localization while LOR strengthens general spatial reasoning, joint training produces mutual reinforcement and positive transfer, and the model generalizes across datasets and domains without per-task tuning.
What carries the argument
Dual-path framework with Language-Only Reasoning (LOR) for step-by-step linguistic deduction and Detect-Then-Reason (DTR) for 3D geometric cue detection via region tokens before explicit inference, optimized by RL after blended cold-start SFT
Load-bearing premise
High-quality blended cold-start data for LOR and DTR chain-of-thought supervision can be reliably constructed and the accuracy, format, and detection rewards will produce stable RL optimization without interference between paths or need for per-task tuning.
What would settle it
An experiment showing that a model trained with this dual-path RL procedure fails to outperform single-path spatial VLM baselines on held-out benchmarks or cannot stably support both LOR and DTR without interference would falsify the central claim.
Figures

read the original abstract
Spatial VLMs have made substantial progress in geometric perception, yet complex spatial reasoning requiring multi-step inference over depth, distance, and scene relations remains challenging. Moreover, different spatial queries call for fundamentally different strategies: some are best addressed through purely linguistic, step-by-step deduction, while others require explicit 3D grounding before quantitative inference. We present Dual-Path Spatial Reasoning via Reinforcement Learning for Spatial VLMs (SR-REAL), a unified framework that equips a spatial VLM with two complementary reasoning paths: Language-Only Reasoning (LOR), which performs step-by-step linguistic deduction, and Detect-Then-Reason (DTR), which detects 3D geometric cues (e.g., centers or bounding boxes) via region tokens before explicit geometric inference. SR-REAL begins with a cold-start supervised fine-tuning stage that constructs LOR and DTR chain-of-thought supervision and exposes a region-to-3D interface, followed by RL that optimizes the policy model with accuracy and format rewards; for DTR, a discrete center-based detection reward further refines geometric alignment. Across diverse spatial benchmarks, SR-REAL significantly outperforms spatial VLM baselines: (i) a single RL-trained model supports both reasoning paths, with DTR excelling in region-aware tasks through precise 3D localization and LOR enhancing general spatial reasoning; (ii) jointly training both paths fosters mutual reinforcement; (iii) high-quality, blended cold-start data is crucial for stable RL optimization; and (iv) the model generalizes across datasets and domains without per-task tuning, demonstrating positive transfer between LOR and DTR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SR-REAL, a framework for spatial vision-language models that equips a single policy with two complementary reasoning paths—Language-Only Reasoning (LOR) via step-by-step linguistic deduction and Detect-Then-Reason (DTR) via region-token-based 3D localization—trained first with blended cold-start SFT supervision and then with RL using accuracy, format, and discrete center-based detection rewards. It claims that the resulting model outperforms spatial VLM baselines across benchmarks, that joint training produces mutual reinforcement between paths, that high-quality blended cold-start data is essential for stable optimization, and that the model generalizes across datasets without per-task tuning.
Significance. If the empirical results and ablations hold, the work would demonstrate a practical route to flexible spatial reasoning in VLMs by showing that a single RL-trained model can maintain both linguistic and grounded paths with positive transfer, addressing the limitation that different spatial queries require qualitatively different inference strategies.
major comments (2)
- [Abstract] Abstract: the central claim that 'a single RL-trained model supports both reasoning paths' with 'mutual reinforcement' and 'no per-task tuning' rests on the unshown construction of blended LOR/DTR chain-of-thought traces and the choice of reward weights; without equations or pseudocode describing the mixing procedure, region-token exposure, or reward combination, it is impossible to evaluate whether path interference was avoided or whether the reported positive transfer is reproducible.
- [Abstract] Abstract: the statement that 'high-quality, blended cold-start data is crucial for stable RL optimization' is presented as a key finding, yet the manuscript provides no ablation on data quality, blending ratios, or the accuracy/format/detection reward formulation; this directly underpins claims (ii) and (iii) and must be substantiated with concrete construction details and sensitivity results.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater methodological transparency. We agree that explicit details on data construction, mixing procedures, and reward formulations are required for reproducibility and will incorporate them in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'a single RL-trained model supports both reasoning paths' with 'mutual reinforcement' and 'no per-task tuning' rests on the unshown construction of blended LOR/DTR chain-of-thought traces and the choice of reward weights; without equations or pseudocode describing the mixing procedure, region-token exposure, or reward combination, it is impossible to evaluate whether path interference was avoided or whether the reported positive transfer is reproducible.
Authors: We acknowledge the concern. The current manuscript describes the overall pipeline at a high level but does not provide the requested equations or pseudocode. In the revised version we will add a new subsection (and appendix) containing: (1) the exact procedure and ratio used to blend LOR and DTR CoT traces during cold-start SFT, (2) the region-token exposure mechanism and its integration with the vision encoder, and (3) the full reward function with explicit weights for accuracy, format, and discrete center-based detection terms. These additions will allow direct assessment of path interference and reproducibility of the reported transfer effects. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'high-quality, blended cold-start data is crucial for stable RL optimization' is presented as a key finding, yet the manuscript provides no ablation on data quality, blending ratios, or the accuracy/format/detection reward formulation; this directly underpins claims (ii) and (iii) and must be substantiated with concrete construction details and sensitivity results.
Authors: We agree that the claim requires empirical support. The present version reports only the final performance after using the blended data and does not contain the requested ablations. We will add a new experimental subsection with: (a) sensitivity results across different blending ratios, (b) comparisons of high- versus lower-quality cold-start data, and (c) ablations on the individual reward components and their relative weights. These results will be used to substantiate claims (ii) and (iii) regarding mutual reinforcement and the necessity of high-quality blended supervision. revision: yes
Circularity Check
No circularity: empirical RL outcomes with independent benchmark results
full rationale
The paper describes an RL training pipeline (cold-start SFT followed by accuracy/format/detection rewards) and reports empirical gains on spatial benchmarks. No equations, uniqueness theorems, or derivations are invoked that reduce any claimed result to a fitted parameter or self-citation by construction. The construction of blended LOR/DTR supervision and choice of rewards are presented as methodological inputs whose effectiveness is measured externally on held-out benchmarks; they do not constitute a self-definitional loop or renamed known result. The work is therefore self-contained against external evaluation and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Ming - Hsuan Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical repo...
Pith/arXiv arXiv 2025
-
[3]
Omni3d: A large benchmark and model for 3d object detection in the wild
Garrick Brazil, Abhinav Kumar, Julian Straub, Nikhila Ravi, Justin Johnson, and Georgia Gkioxari. Omni3d: A large benchmark and model for 3d object detection in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. URL https://github.com/facebookresearch/omni3d. Code and dataset release: facebookresea...
arXiv 2023
-
[9]
Rynnbrain: Open embodied foundation models
Ronghao Dang, Jiayan Guo, Bohan Hou, Sicong Leng, Kehan Li, Xin Li, Jiangpin Liu, Yunxuan Mao, Zhikai Wang, Yuqian Yuan, Minghao Zhu, Xiao Lin, Yang Bai, Qian Jiang, Yaxi Zhao, Minghua Zeng, Junlong Gao, Yuming Jiang, Jun Cen, Siteng Huang, Liuyi Wang, Wenqiao Zhang, Chengju Liu, Jianfei Yang, Shijian Lu, and Deli Zhao. Rynnbrain: Open embodied foundation...
arXiv 2026
-
[11]
Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models
Mengfei Du, Binhao Wu, Zejun Li, Xuanjing Huang, and Zhongyu Wei. Embspatial-bench: Benchmarking spatial understanding for embodied tasks with large vision-language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), 2024
2024
-
[13]
Gemini: A family of highly capable multimodal models, 2023
Google DeepMind . Gemini: A family of highly capable multimodal models, 2023. URL https://deepmind.google/gemini/
2023
-
[16]
Seeing what you miss: Vision-language pre-training with semantic completion learning
Yatai Ji, Rongcheng Tu, Jie Jiang, Weijie Kong, Chengfei Cai, Wenzhe Zhao, Hongfa Wang, Yujiu Yang, and Wei Liu. Seeing what you miss: Vision-language pre-training with semantic completion learning. In CVPR , pages 6789--6798. IEEE , 2023
2023
-
[17]
IDA-VLM: towards movie understanding via id-aware large vision-language model
Yatai Ji, Shilong Zhang, Jie Wu, Peize Sun, Weifeng Chen, Xuefeng Xiao, Sidi Yang, Yujiu Yang, and Ping Luo. IDA-VLM: towards movie understanding via id-aware large vision-language model. In ICLR . OpenReview.net, 2025
2025
-
[18]
What’s "up" with vision-language models? investigating their struggle with spatial reasoning
Amita Kamath, Jack Hessel, and Kai-Wei Chang. What’s "up" with vision-language models? investigating their struggle with spatial reasoning. In EMNLP, 2023
2023
-
[19]
Referitgame: Referring to objects in photographs of natural scenes
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. Referitgame: Referring to objects in photographs of natural scenes. GitHub repository: https://github.com/lichengunc/refer, 2014
2014
-
[20]
Omninocs: A unified NOCS dataset and model for 3d lifting of 2d objects
Akshay Krishnan, Abhijit Kundu, Kevis - Kokitsi Maninis, James Hays, and Matthew Brown. Omninocs: A unified NOCS dataset and model for 3d lifting of 2d objects. In ECCV (75) , volume 15133 of Lecture Notes in Computer Science, pages 127--145. Springer, 2024 a
2024
-
[21]
Omninocs: A unified nocs dataset and model for 3d lifting of 2d objects
Akshay Krishnan, Abhijit Kundu, Kevis-Kokitsi Maninis, James Hays, and Matthew Brown. Omninocs: A unified nocs dataset and model for 3d lifting of 2d objects. In European Conference on Computer Vision, pages 127--145. Springer, 2024 b
2024
-
[26]
Vila: On pre-training for visual language models
Ji Lin, Hongxu Yin, Wei Ping, Pavlo Molchanov, Mohammad Shoeybi, and Song Han. Vila: On pre-training for visual language models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26689--26699, 2024
2024
-
[28]
Visual spatial reasoning
Fangyu Liu, Guy Emerson, and Nigel Collier. Visual spatial reasoning. Transactions of the Association for Computational Linguistics, 11: 0 635--651, 2023
2023
-
[31]
Yuecheng Liu, Dafeng Chi, Shiguang Wu, Zhanguang Zhang, Yaochen Hu, Lingfeng Zhang, Yingxue Zhang, Shuang Wu, Tongtong Cao, Guowei Huang, Helong Huang, Guangjian Tian, Weichao Qiu, Xingyue Quan, Jianye Hao, and Yuzheng Zhuang. Spatialcot: Advancing spatial reasoning through coordinate alignment and chain-of-thought for embodied task planning, 2025 b . URL...
arXiv 2025
-
[32]
Nvila: Efficient frontier visual language models
Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yuxian Gu, Dacheng Li, et al. Nvila: Efficient frontier visual language models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 4122--4134, 2025 c
2025
-
[34]
Spatialllm: A compound 3d-informed design towards spatially-intelligent large multimodal models
Wufei Ma, Luoxin Ye, Celso de Melo, Alan L Yuille, and Jieneng Chen. Spatialllm: A compound 3d-informed design towards spatially-intelligent large multimodal models. In CVPR, 2025 b
2025
-
[37]
Gpt-4o, 2024
OpenAI . Gpt-4o, 2024. URL https://openai.com
2024
-
[40]
Learning to localize objects improves spatial reasoning in visual-llms
Kanchana Ranasinghe, Satya Narayan Shukla, Omid Poursaeed, Michael S Ryoo, and Tsung-Yu Lin. Learning to localize objects improves spatial reasoning in visual-llms. In CVPR, pages 12977--12987, 2024
2024
-
[41]
Plummer, Ranjay Krishna, Kuo-Hao Zeng, and Kate Saenko
Arijit Ray, Jiafei Duan, Ellis Brown, Reuben Tan, Dina Bashkirova, Rose Hendrix, Kiana Ehsani, Aniruddha Kembhavi, Bryan A. Plummer, Ranjay Krishna, Kuo-Hao Zeng, and Kate Saenko. Sat: Spatial aptitude training for multimodal language models, 2025
2025
-
[43]
An empirical analysis on spatial reasoning capabilities of large multimodal models
Fatemeh Shiri, Xiao-Yu Guo, Mona Far, Xin Yu, Reza Haf, and Yuan-Fang Li. An empirical analysis on spatial reasoning capabilities of large multimodal models. In EMNLP, 2024
2024
-
[44]
Yihong Tang, Ao Qu, Zhaokai Wang, Dingyi Zhuang, Zhaofeng Wu, Wei Ma, Shenhao Wang, Yunhan Zheng, Zhan Zhao, and Jinhua Zhao. Sparkle: Mastering basic spatial capabilities in vision language models elicits generalization to spatial reasoning, 2025. URL https://arxiv.org/abs/2410.16162
arXiv 2025
-
[45]
Qwen Team. Qwen3-vl technical report. CoRR, abs/2511.21631, 2025
Pith/arXiv arXiv 2025
-
[47]
Cambrian-1: A fully open, vision-centric exploration of multimodal llms
Peter Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Adithya Jairam Vedagiri IYER, Sai Charitha Akula, Shusheng Yang, Jihan Yang, Manoj Middepogu, Ziteng Wang, et al. Cambrian-1: A fully open, vision-centric exploration of multimodal llms. Advances in Neural Information Processing Systems, 37: 0 87310--87356, 2024
2024
-
[50]
Is a picture worth a thousand words? delving into spatial reasoning for vision language models
Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Sharon Li, and Neel Joshi. Is a picture worth a thousand words? delving into spatial reasoning for vision language models. Advances in Neural Information Processing Systems, 37: 0 75392--75421, 2024 a
2024
-
[51]
Embodiedscan: A holistic multi-modal 3d perception suite towards embodied AI
Tai Wang, Xiaohan Mao, Chenming Zhu, Runsen Xu, Ruiyuan Lyu, Peisen Li, Xiao Chen, Wenwei Zhang, Kai Chen, Tianfan Xue, Xihui Liu, Cewu Lu, Dahua Lin, and Jiangmiao Pang. Embodiedscan: A holistic multi-modal 3d perception suite towards embodied AI . In CVPR , pages 19757--19767. IEEE , 2024 b
2024
-
[52]
Wu et al
Q. Wu et al. Visual spatial tuning: Bootstrapping spatial intelligence in vlms via 3d-aware perception and reinforcement learning. arXiv preprint arXiv:25xx.xxxxx, 2025
2025
-
[53]
Realworldqa: A benchmark for real-world spatial understanding
xAI . Realworldqa: A benchmark for real-world spatial understanding. https://huggingface.co/datasets/xai-org/RealworldQA, 2024. Accessed: 2025-11-13
2024
-
[54]
Rui Yang, Ziyu Zhu, Yanwei Li, Jingjia Huang, Shen Yan, Siyuan Zhou, Zhe Liu, Xiangtai Li, Shuangye Li, Wenqian Wang, Yi Lin, and Hengshuang Zhao. Visual spatial tuning. CoRR, abs/2511.05491, 2025 a
arXiv 2025
-
[59]
Video-3d llm: Learning position-aware video representation for 3d scene understanding
Duo Zheng, Shijia Huang, and Liwei Wang. Video-3d llm: Learning position-aware video representation for 3d scene understanding. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 8995--9006, 2025
2025
-
[61]
FirstName LastName , title =
-
[62]
FirstName Alpher , title =
-
[63]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[64]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[65]
FirstName Alpher and FirstName Gamow , title =
-
[66]
EMNLP , year=
What’s "up" with vision-language models? Investigating their struggle with spatial reasoning , author=. EMNLP , year=
-
[67]
CoRR , volume =
Rui Yang and Ziyu Zhu and Yanwei Li and Jingjia Huang and Shen Yan and Siyuan Zhou and Zhe Liu and Xiangtai Li and Shuangye Li and Wenqian Wang and Yi Lin and Hengshuang Zhao , title =. CoRR , volume =
-
[68]
CoRR , volume =
Gemini Team , title =. CoRR , volume =
-
[69]
CoRR , volume =
Ronghao Dang and Jiayan Guo and Bohan Hou and Sicong Leng and Kehan Li and Xin Li and Jiangpin Liu and Yunxuan Mao and Zhikai Wang and Yuqian Yuan and Minghao Zhu and Xiao Lin and Yang Bai and Qian Jiang and Yaxi Zhao and Minghua Zeng and Junlong Gao and Yuming Jiang and Jun Cen and Siteng Huang and Liuyi Wang and Wenqiao Zhang and Chengju Liu and Jianfei...
-
[70]
Qwen2.5-VL Technical Report , journal =
Shuai Bai and Keqin Chen and Xuejing Liu and Jialin Wang and Wenbin Ge and Sibo Song and Kai Dang and Peng Wang and Shijie Wang and Jun Tang and Humen Zhong and Yuanzhi Zhu and Ming. Qwen2.5-VL Technical Report , journal =
-
[71]
CoRR , volume =
Qwen Team , title =. CoRR , volume =
-
[72]
Transactions of the Association for Computational Linguistics , volume=
Visual spatial reasoning , author=. Transactions of the Association for Computational Linguistics , volume=. 2023 , publisher=
2023
-
[73]
arXiv preprint arXiv:2308.09778 , year=
Towards grounded visual spatial reasoning in multi-modal vision language models , author=. arXiv preprint arXiv:2308.09778 , year=
-
[74]
CVPR , pages=
Learning to localize objects improves spatial reasoning in visual-LLMs , author=. CVPR , pages=
-
[75]
EMNLP , year=
An empirical analysis on spatial reasoning capabilities of large multimodal models , author=. EMNLP , year=
-
[76]
arXiv preprint arXiv:2504.17207 , year=
Perspective-aware reasoning in vision-language models via mental imagery simulation , author=. arXiv preprint arXiv:2504.17207 , year=
-
[77]
Advances in Neural Information Processing Systems , volume=
Is a picture worth a thousand words? delving into spatial reasoning for vision language models , author=. Advances in Neural Information Processing Systems , volume=
-
[78]
2025 , eprint=
Sparkle: Mastering Basic Spatial Capabilities in Vision Language Models Elicits Generalization to Spatial Reasoning , author=. 2025 , eprint=
2025
-
[79]
2025 , eprint=
SpatialCoT: Advancing Spatial Reasoning through Coordinate Alignment and Chain-of-Thought for Embodied Task Planning , author=. 2025 , eprint=
2025
-
[80]
arXiv preprint arXiv:2505.12448 , year=
SSR: Enhancing depth perception in vision-language models via rationale-guided spatial reasoning , author=. arXiv preprint arXiv:2505.12448 , year=
-
[81]
CVPR , year=
SpatialLLM: A compound 3D-informed design towards spatially-intelligent large multimodal models , author=. CVPR , year=
-
[82]
arXiv preprint arXiv:2504.20024 , year=
SpatialReasoner: Towards explicit and generalizable 3D spatial reasoning , author=. arXiv preprint arXiv:2504.20024 , year=
-
[83]
arXiv preprint arXiv:2401.12168 , year =
SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities , author =. arXiv preprint arXiv:2401.12168 , year =
-
[84]
arXiv preprint arXiv:2403.02330 , year =
RegionGPT: Towards Region Understanding Vision Language Model , author =. arXiv preprint arXiv:2403.02330 , year =
-
[85]
arXiv preprint arXiv:2406.01584 , year =
SpatialRGPT: Grounded Spatial Reasoning in Vision Language Models , author =. arXiv preprint arXiv:2406.01584 , year =
-
[86]
arXiv preprint arXiv:2409.18125 , year =
LLaVA-3D: A Simple yet Effective Pathway to Empowering LMMs with 3D-awareness , author =. arXiv preprint arXiv:2409.18125 , year =
-
[87]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Video-3d llm: Learning position-aware video representation for 3d scene understanding , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[88]
arXiv preprint arXiv:2509.13317 , year =
3D Aware Region Prompted Vision Language Model , author =. arXiv preprint arXiv:2509.13317 , year =
-
[89]
arXiv preprint arXiv:2501.19393 , year =
s1: Simple Test-Time Scaling , author =. arXiv preprint arXiv:2501.19393 , year =
-
[90]
arXiv preprint arXiv:2501.06186 , year =
LlamaV-o1: Rethinking Step-by-step Visual Reasoning in LLMs , author =. arXiv preprint arXiv:2501.06186 , year =
-
[91]
arXiv preprint arXiv:2501.12948 , year =
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author =. arXiv preprint arXiv:2501.12948 , year =
-
[92]
arXiv preprint arXiv:2503.06749 , year =
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models , author =. arXiv preprint arXiv:2503.06749 , year =
-
[93]
arXiv preprint arXiv:2503.07365 , year =
MM-Eureka: Exploring Visual Aha Moment with Rule-based Large-scale Reinforcement Learning , author =. arXiv preprint arXiv:2503.07365 , year =
-
[94]
arXiv preprint arXiv:2503.10615 , year =
R1-OneVision: Advancing Generalized Multimodal Reasoning through Cross-Modal Formalization , author =. arXiv preprint arXiv:2503.10615 , year =
-
[95]
arXiv preprint arXiv:2503.12937 , year =
R1-VL: Learning to Reason with Multimodal Large Language Models via Step-wise Group Relative Policy Optimization , author =. arXiv preprint arXiv:2503.12937 , year =
-
[96]
arXiv preprint arXiv:2504.08837 , year =
VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning , author =. arXiv preprint arXiv:2504.08837 , year =
-
[97]
arXiv preprint arXiv:2506.12322 , year =
3D-R1: Reinforcing 3D Spatial Reasoning and Understanding in Large Multimodal Models , author =. arXiv preprint arXiv:2506.12322 , year =
-
[98]
arXiv preprint arXiv:25xx.xxxxx , year =
Visual Spatial Tuning: Bootstrapping Spatial Intelligence in VLMs via 3D-Aware Perception and Reinforcement Learning , author =. arXiv preprint arXiv:25xx.xxxxx , year =
-
[99]
arXiv preprint arXiv:2510.08531 , year =
SpatialLadder: Progressive Training for Spatial Reasoning in Vision--Language Models , author =. arXiv preprint arXiv:2510.08531 , year =
-
[100]
arXiv preprint arXiv:2505.23678 , year =
Grounded Reinforcement Learning for Visual Reasoning , author =. arXiv preprint arXiv:2505.23678 , year =
-
[101]
arXiv preprint arXiv:2308.12966 , year =
Qwen-VL: A Frontier Large Vision-Language Model with Versatile Abilities , author =. arXiv preprint arXiv:2308.12966 , year =
-
[102]
arXiv preprint arXiv:2305.05662 , year =
InternVL: Scaling up Vision Foundation Models and Aligning for Generic Vision-Language Understanding , author =. arXiv preprint arXiv:2305.05662 , year =
-
[103]
arXiv preprint arXiv:2402.16835 , year =
LLaVA-1.5: Improved Reasoning, Grounding, and Chart Understanding , author =. arXiv preprint arXiv:2402.16835 , year =
-
[104]
arXiv preprint arXiv:2312.07533 , year =
VILA: Large-Scale Vision-Language Pre-Training with Region-Based Supervision , author =. arXiv preprint arXiv:2312.07533 , year =
-
[105]
2024 , url =
GPT-4o , author =. 2024 , url =
2024
-
[106]
2023 , url =
Gemini: A Family of Highly Capable Multimodal Models , author =. 2023 , url =
2023
-
[107]
arXiv preprint arXiv:2510.15870 , year=
OmniVinci: Enhancing Architecture and Data for Omni-Modal Understanding LLM , author=. arXiv preprint arXiv:2510.15870 , year=
-
[108]
OmniNOCS:
Akshay Krishnan and Abhijit Kundu and Kevis. OmniNOCS:
-
[109]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Vila: On pre-training for visual language models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[110]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Nvila: Efficient frontier visual language models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[111]
arXiv preprint arXiv:2503.15558 , year =
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning , author =. arXiv preprint arXiv:2503.15558 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.