WorldReasoner: Evaluating Whether Language Model Agents Forecast Events with Valid Reasoning
Pith reviewed 2026-06-27 09:45 UTC · model grok-4.3
The pith
Language model agents forecast events more accurately with time-bounded evidence and causal graphs, but still fail to produce calibrated probabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
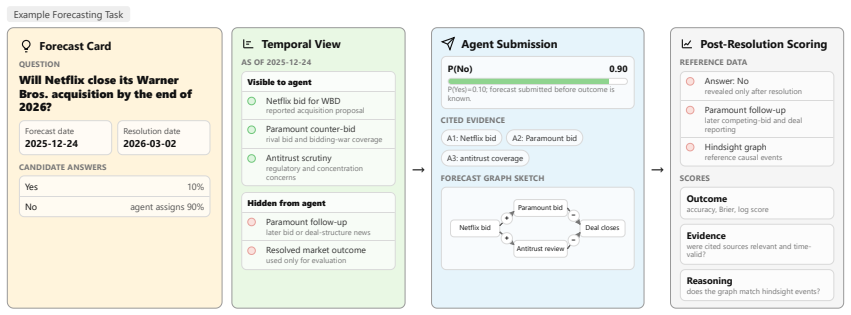
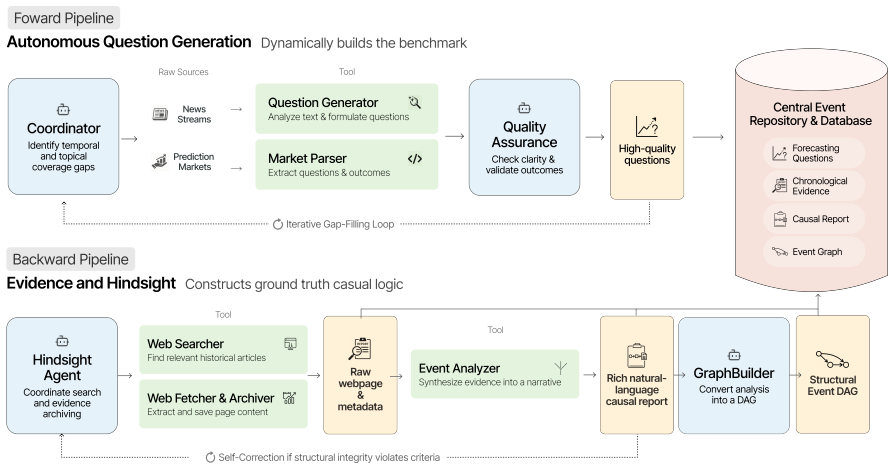
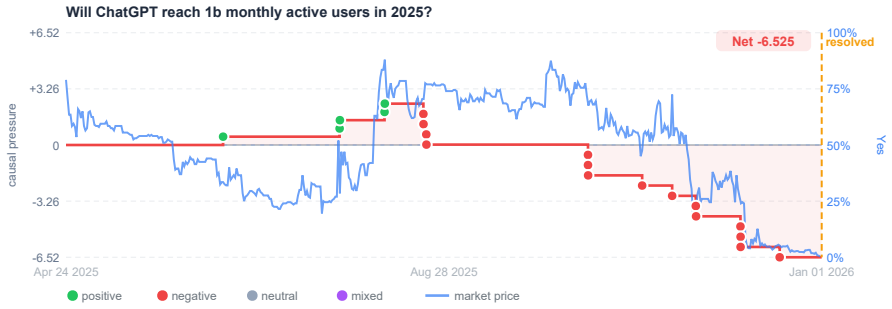
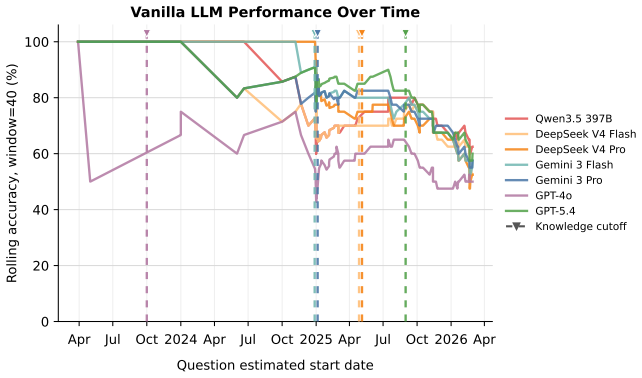
WorldReasoner evaluates forecasting agents on outcome quality against resolved answers, evidence quality over cited sources, and reasoning quality against hindsight graphs, using 345 resolved tasks built from 14,141 articles with graphs covering 8,087 events. Across controlled settings, temporally valid retrieval emerges as the strongest driver of outcome accuracy, causal graph construction improves key-event recovery, and correct graph-enabled forecasts show stronger grounding in key events and relevant sources, yet agents continue to struggle converting that grounding into calibrated probabilities.
What carries the argument
The WorldReasoner framework, which supplies time-bounded evidence and scores agent outputs against hindsight reference graphs on three axes of outcome, evidence, and reasoning quality.
If this is right
- Temporally valid retrieval is the strongest driver of outcome accuracy across agent settings.
- Causal graph construction improves recovery of key events from the evidence.
- Correct graph-enabled forecasts are more strongly grounded in key events and relevant sources.
- Agents struggle to convert grounded evidence into calibrated probability estimates.
Where Pith is reading between the lines
- The three-axis scoring could be extended to non-forecasting tasks that require time-ordered causal reasoning.
- Persistent miscalibration despite strong grounding suggests models need explicit training on uncertainty estimation from retrieved evidence.
- If the hindsight graphs prove reliable, they could serve as supervision signals to train agents that build causal structures before forecasting.
- Deploying the same tasks without simulated dates would test whether real-time agents can maintain temporal validity at scale.
Load-bearing premise
The agentic construction pipeline produces forecasting questions, time-stamped evidence collections, and hindsight reference graphs that faithfully represent real temporal constraints and causal structures without systematic artifacts or selection biases.
What would settle it
A controlled run in which agents receive identical accuracy and grounding scores when allowed post-resolution evidence as when restricted to pre-forecast evidence would falsify the claim that temporal validity drives performance.
Figures
read the original abstract
Forecasting real-world events requires language-model agents to reason under uncertainty from incomplete, time-bounded information. Yet evaluating whether agents genuinely forecast requires more than final-answer accuracy: a model may be correct by recalling memorized training facts, citing fabricated evidence, or producing an unsupported causal story. We present WorldReasoner, an evaluation framework for temporally valid event forecasting. Each task gives an agent a resolved forecasting question, a simulated forecast date, and access only to evidence available before that date; after resolution, the framework scores the submitted probability, cited evidence, and optional causal event graph. WorldReasoner reports three complementary axes: outcome quality against resolved answers, evidence quality over cited sources, and reasoning quality against post-resolution hindsight graphs. The benchmark is built by an agentic construction pipeline that generates forecasting questions, collects time-stamped evidence, and builds hindsight reference graphs at scale, yielding 345 resolved tasks derived from 14,141 articles with graphs covering 8,087 extracted events. Across six controlled agent settings, temporally valid retrieval is the strongest driver of outcome accuracy; causal graph construction improves key-event recovery; and correct graph-enabled forecasts are more strongly grounded in key events and relevant sources, yet agents still struggle to convert grounded evidence into calibrated probabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WorldReasoner, an evaluation framework for assessing whether language-model agents perform temporally valid forecasting of real-world events. Tasks provide a resolved question, a simulated forecast date, and access only to pre-date evidence; post-resolution scoring covers outcome accuracy against ground truth, evidence quality on cited sources, and reasoning quality against hindsight causal graphs. The benchmark is constructed via an agentic pipeline yielding 345 tasks from 14,141 articles and graphs over 8,087 events. Across six controlled agent settings the main empirical claims are that temporally valid retrieval is the strongest driver of accuracy, causal graph construction improves key-event recovery, and correct graph-enabled forecasts are more grounded in key events and sources, although agents struggle to produce calibrated probabilities from grounded evidence.
Significance. If the central empirical claims hold, the framework supplies a scalable, multi-axis benchmark that moves beyond final-answer accuracy to evaluate evidence use and causal reasoning under temporal constraints. The construction of 345 tasks with explicit hindsight graphs and time-stamped evidence collections is a concrete strength that enables controlled ablation of retrieval and graph components. The work could inform agent design for forecasting applications, provided the construction pipeline itself is shown to be free of systematic artifacts.
major comments (2)
- [Abstract] Abstract: All reported results (temporally valid retrieval as strongest driver; graph construction improving key-event recovery; grounded forecasts) rest on the 345 tasks generated by the agentic construction pipeline. The abstract supplies no quantitative validation (human agreement on temporal ordering, causal fidelity of hindsight graphs, or checks against selection bias in event choice) that would rule out systematic artifacts introduced by the same LLM-based pipeline used to create the benchmark. This is load-bearing for the central claims.
- [Abstract] Abstract (and § on benchmark construction, wherever detailed): The weakest assumption identified in the reader report—that the pipeline faithfully represents real temporal constraints and causal structures without artifacts—is not addressed with any reported inter-annotator agreement, human validation subset, or comparison to independently curated events. Without such checks the controlled agent settings cannot isolate the claimed benefits of retrieval and graphs from pipeline-induced regularities.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need to validate the benchmark construction pipeline. We agree that this is essential to support the central empirical claims and will revise the manuscript to address these points directly.
read point-by-point responses
-
Referee: [Abstract] Abstract: All reported results (temporally valid retrieval as strongest driver; graph construction improving key-event recovery; grounded forecasts) rest on the 345 tasks generated by the agentic construction pipeline. The abstract supplies no quantitative validation (human agreement on temporal ordering, causal fidelity of hindsight graphs, or checks against selection bias in event choice) that would rule out systematic artifacts introduced by the same LLM-based pipeline used to create the benchmark. This is load-bearing for the central claims.
Authors: We agree that the current manuscript does not report quantitative human validation of the pipeline outputs. While the construction process is fully described and the agentic pipeline is transparent, the absence of metrics such as inter-annotator agreement leaves open the possibility of artifacts. In the revised manuscript we will add a dedicated validation subsection reporting human agreement on temporal ordering and causal fidelity for a random sample of 50 tasks, plus an analysis of event selection characteristics relative to the source corpus. These results will also be summarized in the abstract. revision: yes
-
Referee: [Abstract] Abstract (and § on benchmark construction, wherever detailed): The weakest assumption identified in the reader report—that the pipeline faithfully represents real temporal constraints and causal structures without artifacts—is not addressed with any reported inter-annotator agreement, human validation subset, or comparison to independently curated events. Without such checks the controlled agent settings cannot isolate the claimed benefits of retrieval and graphs from pipeline-induced regularities.
Authors: We concur that explicit checks are required to strengthen the isolation of retrieval and graph effects. The revised version will include (1) inter-annotator agreement statistics on a human-validated subset, (2) a comparison of a sample of generated events against independently curated forecasting datasets where overlap exists, and (3) explicit discussion of how these checks mitigate concerns about pipeline regularities. These additions will appear in both the abstract and the benchmark construction section. revision: yes
Circularity Check
No circularity: empirical results anchored to external resolutions and hindsight graphs
full rationale
The paper constructs a benchmark via an agentic pipeline but evaluates agent performance against resolved ground-truth answers and post-resolution hindsight graphs that are independent of the tested agents' outputs. Reported drivers of accuracy (temporally valid retrieval, graph construction) emerge from controlled comparisons across six agent settings on 345 tasks, with no self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations that reduce claims to inputs by construction. The derivation chain consists of empirical measurements rather than tautological reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Post-resolution hindsight graphs accurately capture causal event structures for scoring reasoning quality.
Reference graph
Works this paper leans on
-
[1]
2022 , booktitle=
Forecasting Future World Events with Neural Networks , author=. 2022 , booktitle=
2022
-
[2]
2025 , eprint=
FOReCAst: The Future Outcome Reasoning and Confidence Assessment Benchmark , author=. 2025 , eprint=
2025
-
[3]
2023 , booktitle=
RealTime QA: What's the Answer Right Now? , author=. 2023 , booktitle=
2023
-
[4]
2025 , eprint=
Are LLMs Prescient? A Continuous Evaluation using Daily News as the Oracle , author=. 2025 , eprint=
2025
-
[5]
2025 , eprint=
FutureX: An Advanced Live Benchmark for LLM Agents in Future Prediction , author=. 2025 , eprint=
2025
-
[6]
2025 , eprint=
LLM-as-a-Prophet: Understanding Predictive Intelligence with Prophet Arena , author=. 2025 , eprint=
2025
-
[7]
2024 , eprint=
MIRAI: Evaluating LLM Agents for Event Forecasting , author=. 2024 , eprint=
2024
-
[8]
2025 , eprint=
Bench to the Future: A Pastcasting Benchmark for Forecasting Agents , author=. 2025 , eprint=
2025
-
[9]
2024 , booktitle=
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models , author=. 2024 , booktitle=
2024
-
[10]
2024 , booktitle=
Large Language Models Are Zero-Shot Time Series Forecasters , author=. 2024 , booktitle=
2024
-
[11]
2024 , booktitle=
Back to the Future: Towards Explainable Temporal Reasoning with Large Language Models , author=. 2024 , booktitle=
2024
-
[12]
2025 , eprint=
Time Series Forecasting as Reasoning: A Slow-Thinking Approach with Reinforced LLMs , author=. 2025 , eprint=
2025
-
[14]
2024 , eprint=
Dated Data: Tracing Knowledge Cutoffs in Large Language Models , author=. 2024 , eprint=
2024
-
[15]
Journal of Behavioral Decision Making , volume=
Back to the future: Temporal perspective in the explanation of events , author=. Journal of Behavioral Decision Making , volume=. 1989 , publisher=
1989
-
[16]
Ramnani and Mayuresh Anand and Shubhashis Sengupta and Andrew E
Vivek Khetan and Roshni R. Ramnani and Mayuresh Anand and Shubhashis Sengupta and Andrew E. Fano , title =. CoRR , volume =
-
[17]
2023 , booktitle=
ECHo: A Visio-Linguistic Dataset for Event Causality Inference via Human-Centric Reasoning , author=. 2023 , booktitle=
2023
-
[19]
2022 , eprint=
Measuring Attribution in Natural Language Generation Models , author=. 2022 , eprint=
2022
-
[21]
Shiqi Chen and Yiran Zhao and Jinghan Zhang and I. Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023 , year =
2023
-
[22]
2025 , eprint=
The FACTS Grounding Leaderboard: Benchmarking LLMs' Ability to Ground Responses to Long-Form Input , author=. 2025 , eprint=
2025
-
[23]
, booktitle =
Karger, Ezra and Bastani, Houtan and Yueh-Han, Chen and Jacobs, Zachary and Halawi, Danny and Zhang, Fred and Tetlock, Philip E. , booktitle =. ForecastBench: A Dynamic Benchmark of AI Forecasting Capabilities , url =
-
[24]
ForecastTKGQuestions: A Benchmark for Temporal Question Answering and Forecasting over Temporal Knowledge Graphs
Ding, Zifeng and Li, Zongyue and Qi, Ruoxia and Wu, Jingpei and He, Bailan and Ma, Yunpu and Meng, Zhao and Chen, Shuo and Liao, Ruotong and Han, Zhen and Tresp, Volker. ForecastTKGQuestions: A Benchmark for Temporal Question Answering and Forecasting over Temporal Knowledge Graphs. The Semantic Web -- ISWC 2023. 2023
2023
-
[25]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[26]
Shiqi Chen, Yiran Zhao, Jinghan Zhang, I - Chun Chern, Siyang Gao, Pengfei Liu, and Junxian He. 2023. http://papers.nips.cc/paper\_files/paper/2023/hash/8b8a7960d343e023a6a0afe37eee6022-Abstract-Datasets\_and\_Benchmarks.html FELM: benchmarking factuality evaluation of large language models . In Advances in Neural Information Processing Systems 36: Annual...
2023
-
[27]
Hui Dai, Ryan Teehan, and Mengye Ren. 2025. https://arxiv.org/abs/2411.08324 Are llms prescient? a continuous evaluation using daily news as the oracle . Preprint, arXiv:2411.08324
arXiv 2025
-
[28]
Zifeng Ding, Zongyue Li, Ruoxia Qi, Jingpei Wu, Bailan He, Yunpu Ma, Zhao Meng, Shuo Chen, Ruotong Liao, Zhen Han, and Volker Tresp. 2023. Forecasttkgquestions: A benchmark for temporal question answering and forecasting over temporal knowledge graphs. In The Semantic Web -- ISWC 2023, pages 541--560, Cham. Springer Nature Switzerland
2023
-
[29]
Nate Gruver, Marc Finzi, Shikai Qiu, and Andrew Gordon Wilson. 2024. https://arxiv.org/abs/2310.07820 Large language models are zero-shot time series forecasters . In Advances in Neural Information Processing Systems
arXiv 2024
-
[30]
Alon Jacovi, Andrew Wang, Chris Alberti, Connie Tao, Jon Lipovetz, Kate Olszewska, Lukas Haas, Michelle Liu, Nate Keating, Adam Bloniarz, Carl Saroufim, Corey Fry, Dror Marcus, Doron Kukliansky, Gaurav Singh Tomar, James Swirhun, Jinwei Xing, Lily Wang, Madhu Gurumurthy, and 7 others. 2025. https://arxiv.org/abs/2501.03200 The facts grounding leaderboard:...
arXiv 2025
-
[31]
Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, and Qingsong Wen
Ming Jin, Shiyu Wang, Lintao Ma, Zhixuan Chu, James Y. Zhang, Xiaoming Shi, Pin-Yu Chen, Yuxuan Liang, Yuan-Fang Li, Shirui Pan, and Qingsong Wen. 2024. https://arxiv.org/abs/2310.01728 Time-llm: Time series forecasting by reprogramming large language models . In The Twelfth International Conference on Learning Representations
Pith/arXiv arXiv 2024
-
[32]
Ezra Karger, Houtan Bastani, Chen Yueh-Han, Zachary Jacobs, Danny Halawi, Fred Zhang, and Philip E. Tetlock. 2025. https://proceedings.iclr.cc/paper_files/paper/2025/file/ea74e45a229dac70b5b63b28d8934db6-Paper-Conference.pdf Forecastbench: A dynamic benchmark of ai forecasting capabilities . In International Conference on Learning Representations, volume ...
2025
-
[33]
Smith, Yejin Choi, and Kentaro Inui
Jungo Kasai, Keisuke Sakaguchi, Yoichi Takahashi, Ronan Le Bras, Akari Asai, Xinyan Yu, Dragomir Radev, Noah A. Smith, Yejin Choi, and Kentaro Inui. 2023. https://arxiv.org/abs/2207.13332 Realtime qa: What's the answer right now? In Advances in Neural Information Processing Systems
arXiv 2023
-
[34]
Ramnani, Mayuresh Anand, Shubhashis Sengupta, and Andrew E
Vivek Khetan, Roshni R. Ramnani, Mayuresh Anand, Shubhashis Sengupta, and Andrew E. Fano. 2020. Causal-bert : Language models for causality detection between events expressed in text
2020
-
[35]
Yucong Luo, Yitong Zhou, Mingyue Cheng, Jiahao Wang, Daoyu Wang, Tingyue Pan, and Jintao Zhang. 2025. https://arxiv.org/abs/2506.10630 Time series forecasting as reasoning: A slow-thinking approach with reinforced llms . Preprint, arXiv:2506.10630
Pith/arXiv arXiv 2025
-
[36]
Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.741 FA ct S core: Fine-grained atomic evaluation of factual precision in long form text generation . In Proceedings of the 2023 Conference on Empirical Methods in Natural Langua...
-
[37]
Hannah Rashkin, Vitaly Nikolaev, Matthew Lamm, Lora Aroyo, Michael Collins, Dipanjan Das, Slav Petrov, Gaurav Singh Tomar, Iulia Turc, and David Reitter. 2022. https://arxiv.org/abs/2112.12870 Measuring attribution in natural language generation models . Preprint, arXiv:2112.12870
arXiv 2022
-
[38]
Angelika Romanou, Syrielle Montariol, Debjit Paul, Leo Laugier, Karl Aberer, and Antoine Bosselut. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.940 CRAB : Assessing the strength of causal relationships between real-world events . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 15198--15216, Singapore. ...
-
[39]
Bosse, Daniel Hnyk, Peter Mühlbacher, Finn Hambly, Jon Evans, Dan Schwarz, and Lawrence Phillips
Jack Wildman, Nikos I. Bosse, Daniel Hnyk, Peter Mühlbacher, Finn Hambly, Jon Evans, Dan Schwarz, and Lawrence Phillips. 2025. https://arxiv.org/abs/2506.21558 Bench to the future: A pastcasting benchmark for forecasting agents . Preprint, arXiv:2506.21558
arXiv 2025
-
[40]
Yuxi Xie, Guanzhen Li, and Min-Yen Kan. 2023. https://arxiv.org/abs/2305.14740 Echo: A visio-linguistic dataset for event causality inference via human-centric reasoning . In Findings of the Association for Computational Linguistics: EMNLP 2023
arXiv 2023
-
[41]
Qingchuan Yang, Simon Mahns, Sida Li, Anri Gu, Jibang Wu, and Haifeng Xu. 2025. https://arxiv.org/abs/2510.17638 Llm-as-a-prophet: Understanding predictive intelligence with prophet arena . Preprint, arXiv:2510.17638
arXiv 2025
-
[42]
Chenchen Ye, Ziniu Hu, Yihe Deng, Zijie Huang, Mingyu Derek Ma, Yanqiao Zhu, and Wei Wang. 2024. https://arxiv.org/abs/2407.01231 Mirai: Evaluating llm agents for event forecasting . Preprint, arXiv:2407.01231
arXiv 2024
-
[43]
Chenhan Yuan, Qianqian Xie, Jimin Huang, and Sophia Ananiadou. 2024. https://doi.org/10.1145/3589334.3645376 Back to the future: Towards explainable temporal reasoning with large language models . In Proceedings of the ACM Web Conference 2024, pages 1963--1974. ACM
-
[44]
Zhangdie Yuan, Zifeng Ding, and Andreas Vlachos. 2025. https://arxiv.org/abs/2502.19676 Forecast: The future outcome reasoning and confidence assessment benchmark . Preprint, arXiv:2502.19676
arXiv 2025
-
[45]
Zhiyuan Zeng, Jiashuo Liu, Siyuan Chen, Tianci He, Yali Liao, Yixiao Tian, Jinpeng Wang, Zaiyuan Wang, Yang Yang, Lingyue Yin, Mingren Yin, Zhenwei Zhu, Tianle Cai, Zehui Chen, Jiecao Chen, Yantao Du, Xiang Gao, Jiacheng Guo, Liang Hu, and 12 others. 2025. https://arxiv.org/abs/2508.11987 Futurex: An advanced live benchmark for llm agents in future predic...
arXiv 2025
-
[46]
Chenghao Zhu, Nuo Chen, Yufei Gao, Yunyi Zhang, Prayag Tiwari, and Benyou Wang. 2025. https://doi.org/10.18653/v1/2025.naacl-long.381 Is your llm outdated? a deep look at temporal generalization . In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volu...
-
[47]
Andy Zou, Tristan Xiao, Ryan Jia, Joe Kwon, Mantas Mazeika, Richard Li, Dawn Song, Jacob Steinhardt, Owain Evans, and Dan Hendrycks. 2022. https://arxiv.org/abs/2206.15474 Forecasting future world events with neural networks . In Advances in Neural Information Processing Systems
arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.