Markov Chain Decoders Overcome the Heavy-Tail Limitations of Lipschitz Generative Models
Pith reviewed 2026-05-20 08:29 UTC · model grok-4.3
The pith
Replacing Gaussian decoders with Phase-Type Markov chain distributions allows Lipschitz VAEs to generate heavy-tailed outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
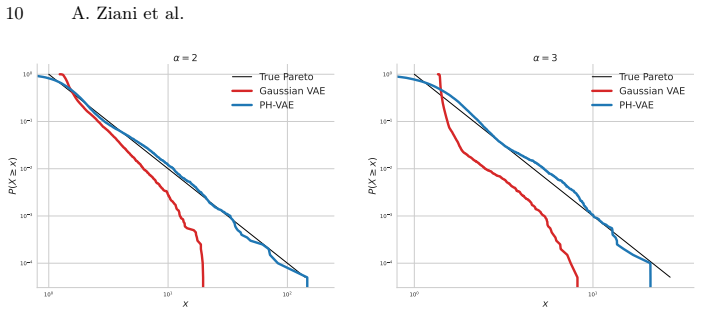
Heavy-tailed distributions pose a fundamental challenge for modern deep generative models because Gaussian tails decay exponentially and Lipschitz continuity prevents the decoder from amplifying rare latent events sufficiently. Replacing the Gaussian decoder with a Phase-Type distribution based on Markov chains, while keeping the encoder, latent space, and training identical, overcomes this structural limitation since Phase-Type distributions approximate any positive-valued distribution, including heavy-tailed families, to arbitrary precision. On synthetic Pareto data across tail indices alpha in {2, 3, 5, 30} and dimensions d in {1, 5, 10}, the Phase-Type decoder reduces tail Kolmogorov-Sm,
What carries the argument
Phase-Type distribution modeled by a continuous-time Markov chain that serves as the decoder likelihood for positive outputs.
If this is right
- Generative models can now produce accurate samples from heavy-tailed distributions common in performance evaluation and risk modeling.
- The same encoder and latent space can be reused for both light- and heavy-tailed data by swapping only the decoder distribution.
- Training remains end-to-end differentiable without additional constraints or changes to the optimization procedure.
- The approach directly addresses the structural mismatch between Lipschitz networks and heavy tails without sacrificing model capacity.
Where Pith is reading between the lines
- The same decoder substitution could be tested in other Lipschitz-constrained architectures such as Wasserstein GANs to check whether the heavy-tail limitation is decoder-specific.
- Multivariate extensions of Phase-Type distributions might enable joint heavy-tail modeling in higher-dimensional settings where marginal approximations alone are insufficient.
- Because the Markov chain representation is explicit, one could inspect the inferred chain parameters to diagnose which phases capture the heavy-tail behavior.
Load-bearing premise
Phase-Type distributions can approximate any positive-valued distribution including heavy-tailed families to arbitrary precision and can be integrated as the decoder likelihood while leaving the encoder, latent space, and training procedure unchanged.
What would settle it
Running the Phase-Type decoder model on real heavy-tailed datasets such as network traffic traces or financial returns and finding that tail Kolmogorov-Smirnov distance or extreme quantile error shows no reduction or an increase relative to the Gaussian baseline would falsify the practical effectiveness claim.
Figures







read the original abstract
Heavy-tailed distributions are prevalent in performance evaluation, network traffic, and risk modeling. This behavior poses a fundamental challenge for modern deep generative models. Standard Variational Autoencoders (VAEs) employ Gaussian decoder likelihoods and Lipschitz-constrained neural networks, a combination that is structurally incapable of producing heavy-tailed outputs: the Gaussian tail decays exponentially, and Lipschitz continuity prevents the decoder from amplifying rare events from the latent space input to sufficiently overcome this decay. We provide both a theoretical characterization of this limitation and a controlled empirical demonstration using synthetic Pareto data across a grid of tail indices $\alpha$ $\in$ {2, 3, 5, 30} and dimensions d $\in$ {1, 5, 10}. As a solution, we replace the Gaussian decoder with a Phase-Type (PH) distribution based on Markov chains, while keeping the encoder, latent space, and training procedure identical. PH distributions allow for arbitrarily precise approximations of any positive-valued distributions, including heavy-tailed families. Experiments showed that the PH-based model reduces tail Kolmogorov-Smirnov distance by up to x6 and extreme quantile error by up to x10 compared to the Gaussian baseline for heavy-tailed data. These results demonstrate that integrating Markov chain-based distributions into the decoder of a generative model institutes a principled and practically effective solution to the heavy-tail generation problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that standard VAEs with Gaussian decoders and Lipschitz-constrained networks cannot generate heavy-tailed outputs, as Gaussian tails decay exponentially and Lipschitz continuity bounds the amplification of rare latent events. It provides a theoretical characterization of this limitation and proposes replacing the Gaussian decoder with a Phase-Type (PH) distribution parameterized via continuous-time Markov chains, while keeping the encoder, latent space, and training procedure identical. PH distributions are argued to approximate any positive-valued distribution arbitrarily well. Controlled experiments on synthetic Pareto data across tail indices α ∈ {2, 3, 5, 30} and dimensions d ∈ {1, 5, 10} report that the PH-based model reduces tail Kolmogorov-Smirnov distance by up to a factor of 6 and extreme quantile error by up to a factor of 10 relative to the Gaussian baseline.
Significance. If the central claims hold, the work offers a principled approach to heavy-tailed generation in deep models, relevant to performance evaluation, network traffic, and risk modeling. Strengths include the controlled synthetic experimental grid, direct baseline comparison, and the flexibility of PH approximations for positive support. The theoretical characterization of the Lipschitz-Gaussian limitation is a useful contribution if rigorously derived.
major comments (2)
- [§3 (Decoder Architecture)] §3 (Decoder Architecture): The assertion that the encoder, latent space, and training procedure remain identical is undermined by the algebraic constraints required for a valid continuous PH distribution. The decoder must output a subgenerator matrix T (negative diagonals, non-negative off-diagonals, non-positive row sums) and initial vector α (non-negative, sums to 1). This necessitates specialized activations (e.g., softplus on rates), output reshaping, or projection steps absent from standard Gaussian decoders, which only require unconstrained mean and positive variance. These changes alter the decoder head, gradient computation, and numerical stability (via matrix exponential), weakening the 'drop-in replacement' claim.
- [Experiments section] Experiments section: The quantitative claims of up to ×6 reduction in tail KS distance and ×10 in extreme quantile error lack supporting details on the number of phases used for the PH approximation, variance across random seeds, or statistical significance tests. Without these, it is difficult to evaluate robustness, especially for the heaviest tails (α=2) where approximation quality depends critically on phase count and parameterization.
minor comments (2)
- [Abstract] Abstract: The 'up to ×6' and 'up to ×10' improvements should specify the exact (α, d) pair at which the maxima occur, rather than leaving the range implicit.
- [Notation] Notation: Define explicitly how the neural network outputs the Markov chain parameters (rates, initial probabilities) and any normalization or constraint enforcement applied during forward passes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment point by point below, outlining planned changes to improve clarity and completeness while preserving the core contributions of the work.
read point-by-point responses
-
Referee: [§3 (Decoder Architecture)] The assertion that the encoder, latent space, and training procedure remain identical is undermined by the algebraic constraints required for a valid continuous PH distribution. The decoder must output a subgenerator matrix T (negative diagonals, non-negative off-diagonals, non-positive row sums) and initial vector α (non-negative, sums to 1). This necessitates specialized activations (e.g., softplus on rates), output reshaping, or projection steps absent from standard Gaussian decoders, which only require unconstrained mean and positive variance. These changes alter the decoder head, gradient computation, and numerical stability (via matrix exponential), weakening the 'drop-in replacement' claim.
Authors: We appreciate the referee's careful reading of the implementation requirements. The manuscript's statement that the encoder, latent space, and training procedure remain identical is accurate in the sense that these components are unchanged from the Gaussian baseline; only the decoder likelihood is replaced. However, we agree that the PH decoder requires specific output constraints and activations to produce a valid subgenerator matrix T and probability vector α. In the revised manuscript we will expand §3 with an explicit description of the decoder head, including the use of softplus on the diagonal and off-diagonal entries of T (to enforce sign constraints) and softmax on α (to ensure non-negativity and summation to one). We will also briefly discuss the matrix-exponential computation and its effect on gradient propagation. These additions clarify the localized nature of the decoder changes without altering the experimental protocol or the central claim. revision: partial
-
Referee: [Experiments section] The quantitative claims of up to ×6 reduction in tail KS distance and ×10 in extreme quantile error lack supporting details on the number of phases used for the PH approximation, variance across random seeds, or statistical significance tests. Without these, it is difficult to evaluate robustness, especially for the heaviest tails (α=2) where approximation quality depends critically on phase count and parameterization.
Authors: We concur that additional experimental details are required for reproducibility and to demonstrate robustness. In the revised version we will state that a fixed number of 10 phases was employed for all PH approximations. We will augment the reported metrics with means and standard deviations computed over five independent random seeds and will include paired t-test p-values comparing the PH and Gaussian models on the tail KS and extreme-quantile errors. These updates will appear in the Experiments section and in revised tables and figures, directly addressing concerns about the heaviest tails (α=2). revision: yes
Circularity Check
No circularity: modeling substitution and empirical comparison are independent of fitted inputs.
full rationale
The paper advances a modeling substitution (Gaussian decoder to Phase-Type/Markov-chain decoder) plus a theoretical characterization of Lipschitz+Gaussian limitations, followed by controlled experiments on synthetic Pareto data. No derivation step reduces a claimed prediction or result to a fitted parameter or self-citation by construction. The 'identical training procedure' statement is an empirical claim about implementation, not a definitional equivalence. External benchmarks (KS distance, quantile error) are measured against a separate baseline, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
free parameters (1)
- Phase-Type distribution parameters
axioms (1)
- domain assumption Phase-Type distributions can approximate any positive-valued distribution to arbitrary precision
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
replace the Gaussian decoder with a Phase-Type (PH) distribution based on Markov chains... PH distributions allow for arbitrarily precise approximations of any positive-valued distributions, including heavy-tailed families
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lipschitz continuity prevents the decoder from amplifying rare events... tail collapse
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Adam: A Method for Stochastic Optimization , author=. 2017 , primaryClass=
work page 2017
-
[2]
Gábor Horváth and Miklós Telek , title =. Proceedings of the 10th EAI International Conference on Performance Evaluation Methodologies and Tools , year =
-
[3]
Computer Performance Evaluation: Modelling Techniques and Tools (TOOLS 2002) , series =
András Horváth and Miklós Telek , title =. Computer Performance Evaluation: Modelling Techniques and Tools (TOOLS 2002) , series =. 2002 , doi =
work page 2002
-
[4]
International Workshop on Timed Petri Nets , pages =
Cumani, Aldo , title =. International Workshop on Timed Petri Nets , pages =. 1985 , isbn =
work page 1985
-
[5]
Matrix-Geometric Solutions in Stochastic Models: An Algorithmic Approach , author=. 1981 , publisher=
work page 1981
-
[6]
Introduction to Matrix Analytic Methods in Stochastic Modeling , author=. 1999 , publisher=
work page 1999
- [7]
-
[8]
Fitting phase-type distributions via the
Asmussen, S. Fitting phase-type distributions via the. Scandinavian Journal of Statistics , volume=. 1996 , publisher=
work page 1996
-
[9]
Okamura, Hiroyuki and Dohi, Tadashi and Trivedi, Kishor S. , journal=. A refined. 2011 , publisher=
work page 2011
-
[10]
Phase Type Distributions: Theory and Application , author=. 2024 , publisher=
work page 2024
-
[11]
Johnson, Mark A. and Taaffe, Michael R. , journal=. Matching moments to phase distributions: Mixtures of. 1989 , publisher=
work page 1989
-
[12]
Buchholz, Peter and Kriege, Jan. , title =. Proceedings of the 2009 Sixth International Conference on the Quantitative Evaluation of Systems , pages =. 2009 , isbn =. doi:10.1109/QEST.2009.36 , abstract =
-
[13]
An Unconstrained Optimization Approach to Moment Fitting with Phase Type Distributions , author=. 2025 , eprint=
work page 2025
-
[14]
Matching three moments with minimal acyclic phase type distributions , author=. Stochastic Models , volume=. 2005 , publisher=
work page 2005
-
[15]
Matching more than three moments with acyclic phase type distributions , author=. Stochastic Models , volume=. 2007 , publisher=
work page 2007
-
[16]
Application and Theory of Petri Nets 1997 , editor =
Serge Haddad and Patrice Moreaux and Giovanni Chiola , title =. Application and Theory of Petri Nets 1997 , editor =. 1997 , doi =
work page 1997
-
[17]
Introduction to the Numerical Solution of Markov Chains , author =. 1994 , publisher =
work page 1994
-
[18]
A. Horv\'ath AND M. Telek , title =. Proc. of 3rd International Conference on Matrix-Analytic Methods in Stochastic models , year = 2000, pages=
work page 2000
-
[19]
D. Aldous and L. Shepp. The least variable phase type distribution is E rlang. Stochastic Models. 1987
work page 1987
-
[20]
Approximation of Cumulative Distribution Functions by Bernstein Phase-Type Distributions
Horv \'a th, Andr \'a s and Horv \'a th, Ill \'e s and Paolieri, Marco and Telek, Mikl \'o s and Vicario, Enrico. Approximation of Cumulative Distribution Functions by Bernstein Phase-Type Distributions. Quantitative Evaluation of Systems and Formal Modeling and Analysis of Timed Systems. 2024
work page 2024
-
[21]
M. Neuts. Probability distributions of phase type. Liber Amicorum Prof. Emeritus H. Florin. 1975
work page 1975
-
[22]
Approximation of cumulative distribution functions by Bernstein phase-type distributions , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.peva.2025.102480 , author =
-
[23]
Construction of Phase Type Distributions by
Andr. Construction of Phase Type Distributions by. Proceedings of
-
[24]
A. Feldman and W. Whitt. Fitting mixtures of exponentials to long-tail distributions to analyze network performance models. Performance Evaluation. 1998
work page 1998
-
[25]
An introduction to heavy-tailed and subexponential distributions , author=. 2011 , publisher=
work page 2011
-
[26]
Wiley StatsRef: Statistics Reference Online , pages=
Pareto distribution , author=. Wiley StatsRef: Statistics Reference Online , pages=. 2014 , publisher=
work page 2014
-
[27]
Queuing theory with heavy tails and network traffic modeling , author=. , year=
-
[28]
Extended Entropy Maximisation and Queueing Systems with Heavy-Tailed Distributions , author=. 2022 , school=
work page 2022
-
[29]
Handbook of heavy tailed distributions in finance: Handbooks in finance, Book 1 , author=. 2003 , publisher=
work page 2003
-
[30]
New Journal of Physics , volume=
Scaling laws and fluctuations in the statistics of word frequencies , author=. New Journal of Physics , volume=. 2014 , publisher=
work page 2014
-
[31]
arXiv preprint arXiv:2410.11985 , year=
The fair language model paradox , author=. arXiv preprint arXiv:2410.11985 , year=
-
[32]
Adam: A method for stochastic optimization , author=. (No Title) , year=
-
[33]
A short review on queuing theory as a deterministic tool in sustainable telecommunication system , journal =. 2021 , note =. doi:https://doi.org/10.1016/j.matpr.2021.01.092 , author =
-
[34]
Mor Harchol-Balter , title =. Queueing Systems , year =. doi:10.1007/s11134-020-09684-6 , issn =
-
[35]
Heavy-tailed Distributions and Risk Management of Equity Market Tail Events , journal=
Zi-Yi,Guo , year=. Heavy-tailed Distributions and Risk Management of Equity Market Tail Events , journal=
-
[36]
Steven T. Piantadosi , title =. Psychonomic Bulletin & Review , year =. doi:https://doi.org/10.3758/s13423-014-0585-6 , issn =
-
[37]
Evaluating Large Language Models on Twitter Based on Hashtag Dynamics and Scaling Properties
Su, Shilan and Zhang, Hongzhong and Wang, Ziye. Evaluating Large Language Models on Twitter Based on Hashtag Dynamics and Scaling Properties. Intelligent Multilingual Information Processing. 2025
work page 2025
-
[38]
Computer Communication Review , volume=
Fitting heavy tailed distributions to internet traffic data , author=. Computer Communication Review , volume=. 1998 , publisher=
work page 1998
- [39]
-
[40]
William J. Stewart , publisher =. Introduction to the Numerical Solution of Markov Chains , urldate =
-
[41]
Matrix-Geometric Solutions in Stochastic Models: An Algorithmic Approach , author =. 1981 , publisher =
work page 1981
- [42]
-
[43]
Superconductivity in Tetragonal LaPt_{2-x}Ge_{2+x}
Vogel, Richard M and Papalexiou, Simon Michael and Lamontagne, Jonathan R and Dolan, Flannery C , title =. The American … , publisher =. 2025 , abstract =. doi:10.1080/00031305.2024.2402898 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1080/00031305.2024.2402898 2025
-
[44]
Journal of Statistical Computation and Simulation , publisher =
Wu, Shuli and Peng, Zuoxiang and Hu, Shuang , title =. Journal of Statistical Computation and Simulation , publisher =. 2025 , abstract =. doi:10.1080/00949655.2025.2566415 , url =
-
[45]
2024 35th Irish Signals … , publisher =
Dunne, Jonathan and Leech, Sonya and Muller, Markus and Manotas, Irene and Swift, Mary , title =. 2024 35th Irish Signals … , publisher =. 2024 , abstract =
work page 2024
-
[46]
arXiv preprint arXiv:2410.14171 , year=
Heavy-tailed diffusion models , author=. arXiv preprint arXiv:2410.14171 , year=
- [47]
-
[48]
Estimation of extreme quantiles from heavy-tailed distributions with neural networks , journal =
M Allouche and S Girard and E Gobet , type =. Estimation of extreme quantiles from heavy-tailed distributions with neural networks , journal =. 2024 , abstract =. doi:10.1007/s11222-023-10331-2 , url =
-
[49]
Heavy-tailed phase-type distributions: a unified approach , journal =
M Bladt and J Yslas , type =. Heavy-tailed phase-type distributions: a unified approach , journal =. 2022 , abstract =. doi:10.1007/s10687-022-00436-8 , url =
-
[50]
Quantitative Science Studies , publisher =
R Delabays and M Tyloo , title =. Quantitative Science Studies , publisher =. 2022 , abstract =
work page 2022
-
[51]
Wiley Interdisciplinary Reviews: Computational Statistics , volume=
Financial modeling with heavy-tailed stable distributions , author=. Wiley Interdisciplinary Reviews: Computational Statistics , volume=. 2014 , publisher=
work page 2014
-
[52]
Powerlaw: a Python package for analysis of heavy-tailed distributions , journal =
J Alstott and E Bullmore and D Plenz , type =. Powerlaw: a Python package for analysis of heavy-tailed distributions , journal =. 2014 , abstract =
work page 2014
-
[53]
Heavy-tailed phenomena and tail index inference , publisher =
M Jia , type =. Heavy-tailed phenomena and tail index inference , publisher =. 2014 , abstract =
work page 2014
-
[54]
Papalexiou, SM and Koutsoyiannis, D and Makropoulos, C , journal=. How extreme is extreme?. 2013 , publisher=
work page 2013
-
[55]
Modeling heavy tails in traffic sources for network performance evaluation , author=. Computational Intelligence, Cyber Security and Computational Models: Proceedings of ICC3, 2013 , pages=. 2013 , publisher=
work page 2013
-
[56]
An introduction to heavy-tailed and subexponential distributions , publisher =
S Foss and D Korshunov and S Zachary , type =. An introduction to heavy-tailed and subexponential distributions , publisher =. 2011 , abstract =. doi:10.1007/978-1-4614-7101-1 , url =
-
[57]
Heavy-tailed distributions in disaster analysis , publisher =
V Pisarenko and M Rodkin , type =. Heavy-tailed distributions in disaster analysis , publisher =
-
[58]
Heavy-tail phenomena: probabilistic and statistical modeling , publisher =
SI Resnick , type =. Heavy-tail phenomena: probabilistic and statistical modeling , publisher =. 2007 , abstract =. doi:10.1007/978-0-387-45024-7_9 , url =
-
[59]
A practical guide to heavy tails: statistical techniques and applications , publisher =
R Adler and R Feldman and M Taqqu , type =. A practical guide to heavy tails: statistical techniques and applications , publisher =
-
[60]
R. Dean Malmgren and Daniel B. Stouffer and Adilson E. Motter and Luís A. N. Amaral , title =. Proceedings of the National Academy of Sciences , volume =. 2008 , doi =
work page 2008
-
[61]
Journal of Quantitative Linguistics , publisher =
R Feng and C Yang and Y Qu , title =. Journal of Quantitative Linguistics , publisher =. 2022 , abstract =. doi:10.1080/09296174.2020.1767481 , url =
-
[62]
Searching for heavy-tailed probability distributions for modeling real-world complex networks , author=. IEEE Access , volume=. 2022 , publisher=
work page 2022
-
[63]
arXiv preprint arXiv:2511.21060 , publisher =
V Berman , title =. arXiv preprint arXiv:2511.21060 , publisher =. 2025 , abstract =
-
[64]
2023 IEEE MIT Undergraduate Research Technology Conference (URTC) , pages=
From bits to insights: Exploring network traffic, traffic matrices, and heavy-tailed data , author=. 2023 IEEE MIT Undergraduate Research Technology Conference (URTC) , pages=. 2023 , organization=
work page 2023
-
[65]
Internet traffic volumes are not
Alasmar, Mohammed and Clegg, Richard and Zakhleniuk, Nickolay and Parisis, George , journal=. Internet traffic volumes are not. 2021 , publisher=
work page 2021
- [66]
- [67]
-
[68]
The Eleventh International Conference on Learning Representations , year=
The Tilted Variational Autoencoder: Improving Out-of-Distribution Detection , author=. The Eleventh International Conference on Learning Representations , year=
-
[69]
NeurIPS 2024 Workshop on Bayesian Decision-making and Uncertainty , year=
Capturing Extreme Events in Turbulence using an Extreme Variational Autoencoder , author=. NeurIPS 2024 Workshop on Bayesian Decision-making and Uncertainty , year=
work page 2024
-
[70]
Autoencoder and Its Various Variants , year=
Zhai, Junhai and Zhang, Sufang and Chen, Junfen and He, Qiang , booktitle=. Autoencoder and Its Various Variants , year=
-
[71]
arXiv preprint arXiv:1606.05908
C Doersch , title =. arXiv preprint arXiv:1606.05908 , publisher =. 2016 , abstract =
-
[72]
2018 IEEE international conference on systems, man, and cybernetics (SMC) , pages=
Autoencoder and its various variants , author=. 2018 IEEE international conference on systems, man, and cybernetics (SMC) , pages=. 2018 , organization=
work page 2018
-
[73]
ACM Computing Surveys , publisher =
S Liang and Z Pan and W Liu and J Yin and M De Rijke , title =. ACM Computing Surveys , publisher =. 2024 , abstract =. doi:10.1145/3663364 , url =
-
[74]
t3-Variational Autoencoder: Learning Heavy-tailed Data with Student's t and Power Divergence , author=. ArXiv , year=
-
[75]
Conditional-t3VAE: Equitable Latent Space Allocation for Fair Generation , author=. ArXiv , year=
-
[76]
Capturing Extreme Events in Turbulence using an Extreme Variational Autoencoder (xVAE) , author=. 2025 , eprint=
work page 2025
-
[77]
Modeling Spatio-temporal Extremes via Conditional Variational Autoencoders , author=. 2025 , eprint=
work page 2025
-
[78]
A VAE Approach to Sample Multivariate Extremes , author=. 2023 , eprint=
work page 2023
-
[79]
Physical Review E , publisher =
S Sormunen and L Leskelä and J Saramäki , title =. Physical Review E , publisher =. 2024 , abstract =. doi:10.1103/PhysRevE.109.054308 , url =
-
[80]
Physical Review E , publisher =
J Del Castillo and P Puig , title =. Physical Review E , publisher =. 2023 , abstract =. doi:10.1103/PhysRevE.107.064113 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.