α-TCAV: A Unified Framework for Testing with Concept Activation Vectors
Pith reviewed 2026-05-19 19:44 UTC · model grok-4.3
The pith
The standard TCAV score has non-decaying variance from its discontinuous indicator, which α-TCAV fixes by substituting a parameterized smooth function for a unified probabilistic framework.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
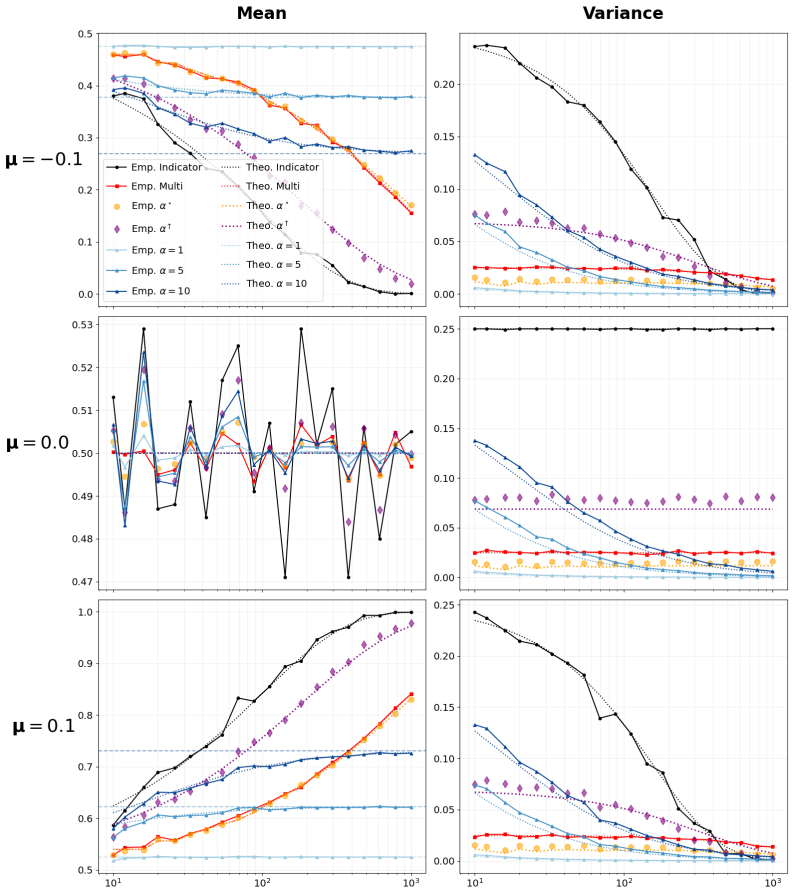
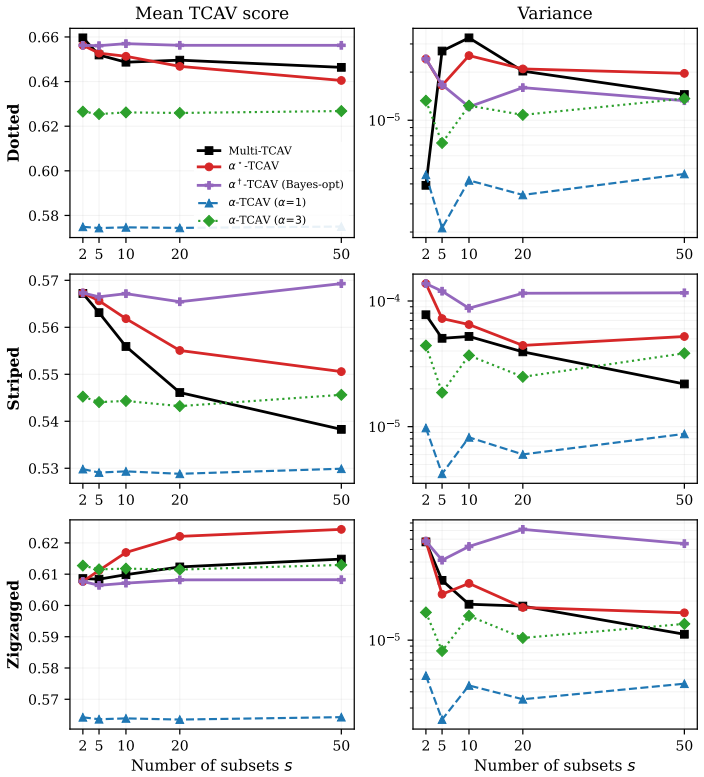
The central claim is that the discontinuous indicator inside the standard TCAV score induces non-decaying variance in critical regimes. Replacing that indicator with a parameterized smooth function produces α-TCAV, a unified probabilistic formulation that subsumes both TCAV and Multi-TCAV, admits closed-form distributions for the resulting sensitivity scores, and supplies principled tuning rules for the smoothing parameter.
What carries the argument
The parameterized smooth function that replaces the discontinuous indicator inside the TCAV sensitivity score.
If this is right
- Established choices for TCAV variants lack theoretical justification once the distributions are derived.
- Tuning the smoothing parameter lets users imitate Multi-TCAV at substantially lower computational cost.
- Alternative tuning yields a calibrated Bayes-optimal probabilistic measure of a concept's influence.
- Allocating the full sampling budget to a single CAV produces better results than splitting the budget across several CAVs.
Where Pith is reading between the lines
- Adopting α-TCAV could reduce the number of unstable explanations encountered when auditing real deployed models.
- The same smoothing idea may transfer to other gradient-based attribution methods that currently rely on hard thresholds.
- Empirical checks on large vision models would test whether the predicted variance reduction appears at practical sample sizes.
Load-bearing premise
The smooth function can be tuned to imitate Multi-TCAV or to recover a calibrated Bayes-optimal measure without introducing additional bias.
What would settle it
Measure the empirical variance of the α-TCAV sensitivity score as the number of samples grows in the regime where standard TCAV variance remains constant; the claim is settled if the new variance decays while the old one does not.
Figures











read the original abstract
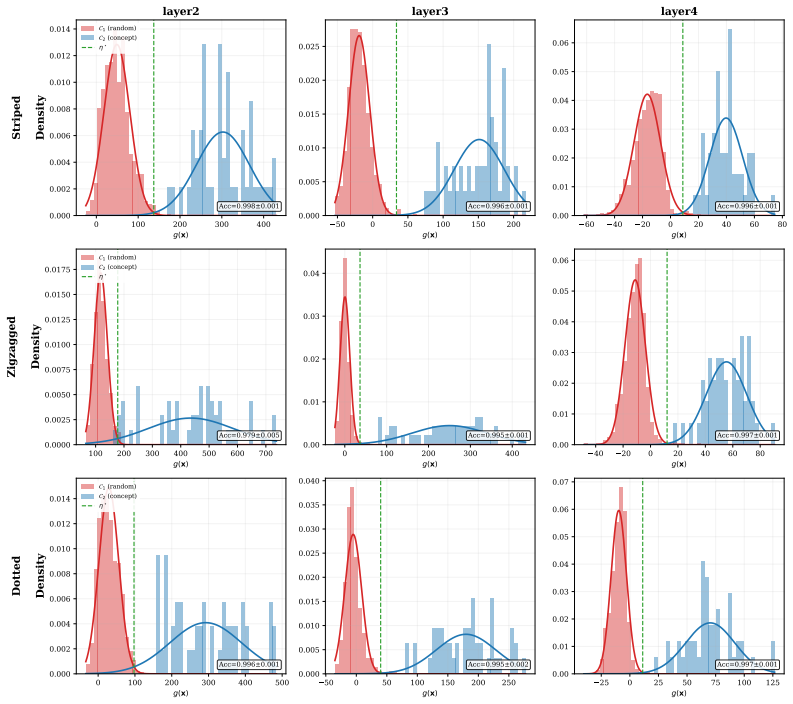
Concept Activation Vectors (CAVs) are a fundamental tool for concept-based explainability in deep learning, yet their practical utility is limited by statistical instability. We analyze the stochastic nature of CAVs and the Testing with CAVs (TCAV) method, deriving the distributions of major CAV classes including PatternCAV, FastCAV, and ridge regression-based CAVs. We then identify a fundamental flaw in the standard TCAV score: its reliance on a discontinuous indicator function induces non-decaying variance in critical regimes. To address this, we introduce $\alpha$-TCAV, a generalized framework that replaces the indicator with a parameterized smooth function, yielding a unified probabilistic formulation that subsumes both TCAV and Multi-TCAV. We characterize the induced distributions of sensitivity scores and different TCAV variants, showing that established state-of-the-art choices lack theoretical justification. We provide principled guidance on tuning the parameter in $\alpha$-TCAV -- either to imitate Multi-TCAV at substantially lower computational cost, or to obtain a calibrated Bayes-optimal probabilistic measure of a concept's influence. Finally, our analysis yields practical recommendations that challenge established routines: most notably, allocating the full sampling budget to a single CAV rather than splitting it across several.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes the stochastic properties of Concept Activation Vectors (CAVs) including PatternCAV, FastCAV, and ridge-regression variants, derives their distributions, and identifies a fundamental flaw in standard TCAV: the discontinuous indicator function produces non-decaying variance near decision boundaries or in low-signal regimes. It introduces α-TCAV, which replaces the indicator with a parameterized smooth function to obtain a unified probabilistic formulation subsuming TCAV and Multi-TCAV, characterizes the resulting sensitivity-score distributions, supplies tuning guidance for the α parameter (to imitate Multi-TCAV at lower cost or to achieve a calibrated Bayes-optimal measure), and recommends allocating the full sampling budget to a single CAV rather than splitting it.
Significance. If the analytic derivations of the CAV distributions and the claim that the smooth-function replacement introduces no new finite-sample bias both hold, the work supplies the first rigorous probabilistic account of TCAV instability and a principled way to stabilize it. The explicit variance-flaw diagnosis and the practical recommendation to use a single CAV constitute concrete, falsifiable advances that could improve reliability of concept-based explanations; the unified framework also offers a route to lower-cost Multi-TCAV emulation.
major comments (2)
- [stochastic analysis section] Stochastic analysis section: the central claim that the distributions for PatternCAV, FastCAV, and ridge-regression CAVs are analytically tractable (and therefore permit exact tuning guidance for α) rests on regularity conditions that are not fully stated; any hidden approximation or unverified moment condition would propagate directly into the assertion that established routines lack justification and into the Bayes-optimal calibration claim.
- [α-TCAV framework section] α-TCAV framework section: the replacement of the discontinuous indicator by the parameterized smooth function is asserted to preserve the exact sensitivity distribution without introducing new bias, yet the specific functional form chosen for the smooth surrogate may implicitly encode earlier empirical choices; explicit error bounds or a finite-sample bias analysis is required to support the claim that α can be tuned to a calibrated posterior without distortion.
minor comments (2)
- The abstract states that α-TCAV yields “substantially lower computational cost” than Multi-TCAV, but no quantitative runtime or sample-complexity comparison appears in the main text or experiments.
- Notation for the sensitivity score under different CAV estimators is introduced without a consolidated table; a single reference table would improve readability when comparing the derived distributions.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments correctly identify areas where greater explicitness is needed to support the central claims. We respond to each major comment below and commit to revisions that strengthen the rigor of the stochastic analysis and the α-TCAV framework without altering the manuscript's core contributions.
read point-by-point responses
-
Referee: [stochastic analysis section] Stochastic analysis section: the central claim that the distributions for PatternCAV, FastCAV, and ridge-regression CAVs are analytically tractable (and therefore permit exact tuning guidance for α) rests on regularity conditions that are not fully stated; any hidden approximation or unverified moment condition would propagate directly into the assertion that established routines lack justification and into the Bayes-optimal calibration claim.
Authors: We agree that the regularity conditions underlying the closed-form distributions must be stated explicitly. The derivations in the stochastic analysis section rely on standard assumptions for linear and ridge estimators (finite second moments of activations, full-rank covariance in the relevant subspace, and Gaussian or sub-Gaussian tails for concentration), but these were not collected in one place. In the revision we will insert a dedicated paragraph at the start of the section that enumerates all required conditions, including moment bounds and regularity requirements for the PatternCAV, FastCAV, and ridge-regression estimators. With these conditions visible, the claims about lack of justification for prior routines and the validity of Bayes-optimal tuning guidance will rest on a transparent foundation. revision: yes
-
Referee: [α-TCAV framework section] α-TCAV framework section: the replacement of the discontinuous indicator by the parameterized smooth function is asserted to preserve the exact sensitivity distribution without introducing new bias, yet the specific functional form chosen for the smooth surrogate may implicitly encode earlier empirical choices; explicit error bounds or a finite-sample bias analysis is required to support the claim that α can be tuned to a calibrated posterior without distortion.
Authors: The smooth surrogate is introduced as a continuous relaxation whose expectation recovers the original TCAV score in the limit as α → ∞, and the paper characterizes the resulting sensitivity-score distribution exactly under the same probabilistic model used for the CAV estimators. We do not claim the finite-α version is bias-free for every possible surrogate; the functional form is chosen for analytic tractability and monotonicity. To meet the referee's request we will add a short finite-sample bias analysis and approximation-error bounds in the α-TCAV framework section, showing that the bias term is O(1/α) under the stated moment conditions and vanishes uniformly away from the decision boundary. This will also clarify that the calibration of α to a Bayes-optimal posterior remains valid once the controlled approximation error is accounted for. revision: yes
Circularity Check
Derivations of CAV distributions and α-TCAV replacement are self-contained first-principles analysis.
full rationale
The paper derives distributions for PatternCAV, FastCAV, and ridge-regression CAVs directly from stochastic properties of the underlying models and then replaces the discontinuous indicator in TCAV with a parameterized smooth function to obtain α-TCAV. No step reduces a claimed prediction or uniqueness result to a fitted parameter or prior self-citation by construction. The analytic tractability statements and tuning guidance follow from the stated regularity conditions on the sensitivity scores rather than from re-labeling inputs as outputs. The central claim about non-decaying variance is therefore an independent consequence of the indicator discontinuity and is not forced by the paper's own definitions or citations.
Axiom & Free-Parameter Ledger
free parameters (1)
- alpha
axioms (1)
- domain assumption CAVs of PatternCAV, FastCAV, and ridge-regression types possess analytically derivable distributions under the stochastic model of activations.
invented entities (1)
-
α-TCAV sensitivity score
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Zur Elektrodynamik bewegter Körper
Albert Einstein. Zur Elektrodynamik bewegter Körper. Annalen der Physik. 1905
work page 1905
-
[2]
The Annals of Applied Probability , volume=
A random matrix approach to neural networks , author=. The Annals of Applied Probability , volume=. 2018 , publisher=
work page 2018
-
[3]
The Thirteenth International Conference on Learning Representations , year=
The breakdown of Gaussian universality in classification of high-dimensional linear factor mixtures , author=. The Thirteenth International Conference on Learning Representations , year=
-
[4]
Characterization of Gaussian Universality Breakdown in High-Dimensional Empirical Risk Minimization
Characterization of Gaussian Universality Breakdown in High-Dimensional Empirical Risk Minimization , author=. arXiv preprint arXiv:2604.03146 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Michel Goossens and Frank Mittelbach and Alexander Samarin. The \ Companion. 1993
work page 1993
-
[6]
arXiv preprint arXiv:2008.13033 , year=
Precise error analysis of the lasso under correlated designs , author=. arXiv preprint arXiv:2008.13033 , year=
-
[7]
SIAM Journal on optimization , volume=
A singular value thresholding algorithm for matrix completion , author=. SIAM Journal on optimization , volume=. 2010 , publisher=
work page 2010
-
[8]
Inventiones mathematicae , volume=
A central limit theorem for convex sets , author=. Inventiones mathematicae , volume=. 2007 , publisher=
work page 2007
-
[9]
arXiv preprint arXiv:1803.07554 , year=
Leave-one-out approach for matrix completion: Primal and dual analysis , author=. arXiv preprint arXiv:1803.07554 , year=
-
[10]
Learning fast approximations of sparse coding , author=. Proceedings of the 27th International Conference on International Conference on Machine Learning , pages=
-
[11]
The Bell system technical journal , volume=
A mathematical theory of communication , author=. The Bell system technical journal , volume=. 1948 , publisher=
work page 1948
-
[12]
Learning multiple layers of features from tiny images , author=. 2009 , publisher=
work page 2009
-
[13]
arXiv preprint arXiv:2109.11905 , year=
Graph-based approximate message passing iterations , author=. arXiv preprint arXiv:2109.11905 , year=
- [14]
-
[15]
arXiv preprint arXiv:2004.01571 , year=
Tramp: Compositional inference with tree approximate message passing , author=. arXiv preprint arXiv:2004.01571 , year=
-
[16]
Advances in Mathematics , volume=
A stability result for mean width of Lp-centroid bodies , author=. Advances in Mathematics , volume=. 2007 , publisher=
work page 2007
-
[17]
arXiv preprint arXiv:1805.08295 , year=
Concentration of Measure and Large Random Matrices with an application to Sample Covariance Matrices , author=. arXiv preprint arXiv:1805.08295 , year=
- [18]
-
[19]
Constructive Approximation , volume=
A simple proof of the restricted isometry property for random matrices , author=. Constructive Approximation , volume=. 2008 , publisher=
work page 2008
-
[20]
IEEE Transactions on information theory , volume=
Compressed sensing , author=. IEEE Transactions on information theory , volume=. 2006 , publisher=
work page 2006
-
[21]
The annals of Statistics , volume=
The Dantzig selector: Statistical estimation when p is much larger than n , author=. The annals of Statistics , volume=. 2007 , publisher=
work page 2007
-
[22]
Statistical analysis and improvement of large dimensional svm , author=. private communication , year=
-
[23]
High Dimensional Classification via Regularized and Unregularized Empirical Risk Minimization: Precise Error and Optimal Loss , author=. arXiv preprint arXiv:1905.13742 , year=
-
[24]
Journal of the Royal Statistical Society Series B , volume=
Regression selection and shrinkage via the lasso , author=. Journal of the Royal Statistical Society Series B , volume=
-
[25]
Proceedings of the international congress of mathematicians , volume=
Compressive sampling , author=. Proceedings of the international congress of mathematicians , volume=. 2006 , organization=
work page 2006
-
[26]
Group sparse reconstruction for image segmentation , author=. Neurocomputing , volume=. 2014 , publisher=
work page 2014
- [27]
-
[28]
Proceedings of the IEEE , volume=
On the role of sparse and redundant representations in image processing , author=. Proceedings of the IEEE , volume=. 2010 , publisher=
work page 2010
-
[29]
Proceedings of the 45th annual meeting of the association of computational linguistics , pages=
Biographies, bollywood, boom-boxes and blenders: Domain adaptation for sentiment classification , author=. Proceedings of the 45th annual meeting of the association of computational linguistics , pages=
-
[30]
Journal of Machine learning research , volume=
An interior-point method for large-scale l1-regularized logistic regression , author=. Journal of Machine learning research , volume=
-
[31]
International Journal of Machine Learning and Cybernetics , volume=
A comparison of l1-regularizion, PCA, KPCA and ICA for dimensionality reduction in logistic regression , author=. International Journal of Machine Learning and Cybernetics , volume=. 2014 , publisher=
work page 2014
-
[32]
Technical report, UCB/EECS-2010--126, EECS Department, University of California, Berkeley , year=
Safe feature elimination in sparse supervised learning technical report no , author=. Technical report, UCB/EECS-2010--126, EECS Department, University of California, Berkeley , year=
work page 2010
-
[33]
Lee, Su-In and Lee, Honglak and Abbeel, Pieter and Ng, Andrew Y , booktitle=. Efficient l\
-
[34]
Journal of Machine Learning Research , year =
Steven Diamond and Stephen Boyd , title =. Journal of Machine Learning Research , year =
-
[35]
Probabilistic interpretation of feedforward classification network outputs, with relationships to statistical pattern recognition , author=. Neurocomputing , pages=. 1990 , publisher=
work page 1990
-
[36]
arXiv preprint arXiv:2007.13716 , year=
The Lasso with general Gaussian designs with applications to hypothesis testing , author=. arXiv preprint arXiv:2007.13716 , year=
-
[37]
Conference on Learning Theory , pages=
Asymptotic errors for high-dimensional convex penalized linear regression beyond gaussian matrices , author=. Conference on Learning Theory , pages=. 2020 , organization=
work page 2020
-
[38]
SIAM journal on imaging sciences , volume=
A fast iterative shrinkage-thresholding algorithm for linear inverse problems , author=. SIAM journal on imaging sciences , volume=. 2009 , publisher=
work page 2009
-
[39]
2012 IEEE Conference on Computer Vision and Pattern Recognition , pages=
Geodesic flow kernel for unsupervised domain adaptation , author=. 2012 IEEE Conference on Computer Vision and Pattern Recognition , pages=. 2012 , organization=
work page 2012
-
[40]
IEEE Signal Processing Magazine , volume=
The MNIST database of handwritten digit images for machine learning research [best of the web] , author=. IEEE Signal Processing Magazine , volume=. 2012 , publisher=
work page 2012
-
[41]
Concentration of solutions to random equations with concentration of measure hypotheses , author=
-
[42]
International Conference on Machine Learning , pages=
Random matrix theory proves that deep learning representations of gan-data behave as gaussian mixtures , author=. International Conference on Machine Learning , pages=. 2020 , organization=
work page 2020
-
[43]
IEEE Transactions on Information Theory , volume=
The LASSO risk for Gaussian matrices , author=. IEEE Transactions on Information Theory , volume=. 2011 , publisher=
work page 2011
-
[44]
IEEE Open Journal of Signal Processing , volume=
On the precise error analysis of support vector machines , author=. IEEE Open Journal of Signal Processing , volume=. 2021 , publisher=
work page 2021
-
[45]
The Annals of Statistics , volume=
High-dimensional generalized linear models and the lasso , author=. The Annals of Statistics , volume=. 2008 , publisher=
work page 2008
-
[46]
Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=
The group lasso for logistic regression , author=. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=. 2008 , publisher=
work page 2008
-
[47]
A large scale analysis of logistic regression: Asymptotic performance and new insights , author=. ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2019 , organization=
work page 2019
-
[48]
International Conference on Artificial Intelligence and Statistics , pages=
The Unexpected Deterministic and Universal Behavior of Large Softmax Classifiers , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2021 , organization=
work page 2021
-
[49]
Proceedings of the National Academy of Sciences , volume=
On robust regression with high-dimensional predictors , author=. Proceedings of the National Academy of Sciences , volume=. 2013 , publisher=
work page 2013
-
[50]
2015 International Conference on Sampling Theory and Applications (SampTA) , pages=
Efficient dictionary learning via very sparse random projections , author=. 2015 International Conference on Sampling Theory and Applications (SampTA) , pages=. 2015 , organization=
work page 2015
-
[51]
Proceedings of the 24th international conference on Machine learning , pages=
Self-taught learning: transfer learning from unlabeled data , author=. Proceedings of the 24th international conference on Machine learning , pages=
-
[52]
International conference on machine learning , pages=
Sparse coding for multitask and transfer learning , author=. International conference on machine learning , pages=
-
[53]
International Conference on Learning Representations , year=
Deciphering and optimizing multi-task learning: a random matrix approach , author=. International Conference on Learning Representations , year=
-
[54]
IEEE transactions on information theory , volume=
Decoding by linear programming , author=. IEEE transactions on information theory , volume=. 2005 , publisher=
work page 2005
-
[55]
Stable signal recovery from incomplete and inaccurate measurements , author=. Communications on Pure and Applied Mathematics: A Journal Issued by the Courant Institute of Mathematical Sciences , volume=. 2006 , publisher=
work page 2006
-
[56]
Conference on Learning Theory , pages=
Regularized linear regression: A precise analysis of the estimation error , author=. Conference on Learning Theory , pages=. 2015 , organization=
work page 2015
-
[57]
The Annals of Statistics , volume=
Asymptotic risk and phase transition of l\_ \ 1 \ -penalized robust estimator , author=. The Annals of Statistics , volume=. 2020 , publisher=
work page 2020
-
[58]
IEEE Transactions on Information Theory , volume=
High-dimensional classification by sparse logistic regression , author=. IEEE Transactions on Information Theory , volume=. 2018 , publisher=
work page 2018
- [59]
-
[60]
A Mathematical Framework for Feature Selection from Real-World Data with Non-Linear Observations
A mathematical framework for feature selection from real-world data with non-linear observations , author=. arXiv preprint arXiv:1608.08852 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Journal of Multivariate analysis , volume=
On the empirical distribution of eigenvalues of a class of large dimensional random matrices , author=. Journal of Multivariate analysis , volume=. 1995 , publisher=
work page 1995
-
[62]
International conference on machine learning , pages=
Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav) , author=. International conference on machine learning , pages=. 2018 , organization=
work page 2018
-
[63]
arXiv preprint arXiv:2404.03713 , year=
Explaining Explainability: Understanding Concept Activation Vectors , author=. arXiv preprint arXiv:2404.03713 , year=
-
[64]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
From hope to safety: Unlearning biases of deep models via gradient penalization in latent space , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[65]
Proceedings of the National Academy of Sciences , volume=
Acquisition of chess knowledge in alphazero , author=. Proceedings of the National Academy of Sciences , volume=. 2022 , publisher=
work page 2022
-
[66]
arXiv preprint arXiv:2202.03482 , year=
PatClArC: Using pattern concept activation vectors for noise-robust model debugging , author=. arXiv preprint arXiv:2202.03482 , year=
-
[67]
On the interpretation of weight vectors of linear models in multivariate neuroimaging , author=. Neuroimage , volume=. 2014 , publisher=
work page 2014
-
[68]
International Conference on Machine Learning , pages=
Deciphering lasso-based classification through a large dimensional analysis of the iterative soft-thresholding algorithm , author=. International Conference on Machine Learning , pages=. 2022 , organization=
work page 2022
- [69]
-
[70]
The Concentration of Measure Phenomenon , author=. 2001 , publisher=
work page 2001
- [71]
-
[72]
arXiv preprint arXiv:2010.09877 , year=
Concentration of solutions to random equations with concentration of measure hypotheses , author=. arXiv preprint arXiv:2010.09877 , year=
-
[73]
Matematicheskii Sbornik , volume=
Distribution of eigenvalues for some sets of random matrices , author=. Matematicheskii Sbornik , volume=. 1967 , publisher=
work page 1967
-
[74]
Nature Machine Intelligence , volume=
From attribution maps to human-understandable explanations through concept relevance propagation , author=. Nature Machine Intelligence , volume=. 2023 , publisher=
work page 2023
-
[75]
On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation , author=. PloS one , volume=. 2015 , publisher=
work page 2015
-
[76]
Journal of Machine Learning Research , author =
Rademacher and. Journal of Machine Learning Research , author =. 2002 , pages =
work page 2002
-
[77]
Theory of Probability and Its Applications , volume=
On the Uniform Convergence of Relative Frequencies of Events to Their Probabilities , author=. Theory of Probability and Its Applications , volume=
-
[78]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
FastCAV: Efficient Computation of Concept Activation Vectors for Explaining Deep Neural Networks , author=. Proceedings of the 42nd International Conference on Machine Learning (ICML) , year =
-
[79]
Bridging the Human-AI Knowledge Gap: Concept Discovery and Transfer in AlphaZero , author=. CoRR , year=
-
[80]
IEEE Transactions on Signal Processing , volume=
A large dimensional analysis of least squares support vector machines , author=. IEEE Transactions on Signal Processing , volume=. 2019 , publisher=
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.