Confirming Correct, Missing the Rest: LLM Tutoring Agents Struggle Where Feedback Matters Most
Pith reviewed 2026-05-20 18:54 UTC · model grok-4.3
The pith
LLM tutoring agents correctly identify optimal solutions but over-reject valid suboptimal reasoning and over-validate incorrect ones in propositional logic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Models achieved near-ceiling performance on optimal steps but systematically over-rejected valid but suboptimal reasoning and over-validated incorrect solutions, precisely where adaptive tutoring matters most. These failures persisted across models regardless of solution context, suggesting architectural rather than informational limits. Moreover, accurate diagnosis did not reliably produce pedagogically actionable feedback, revealing a gap between diagnostic judgment and instructional effectiveness.
What carries the argument
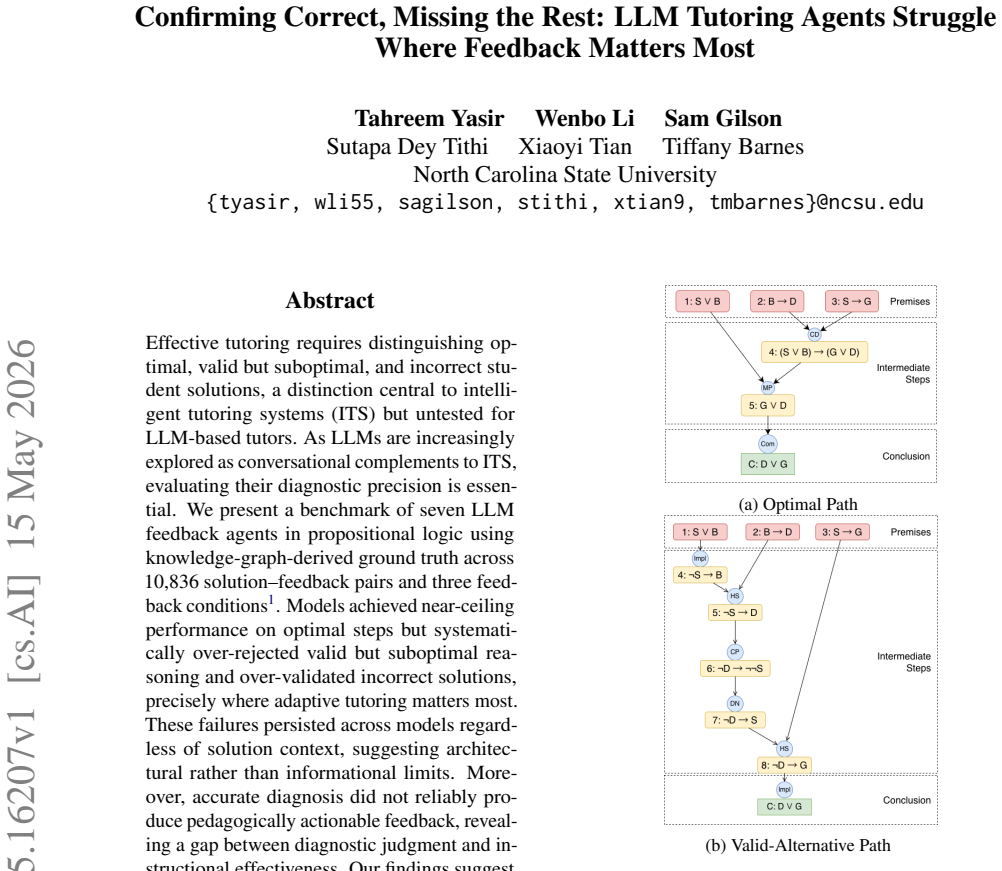
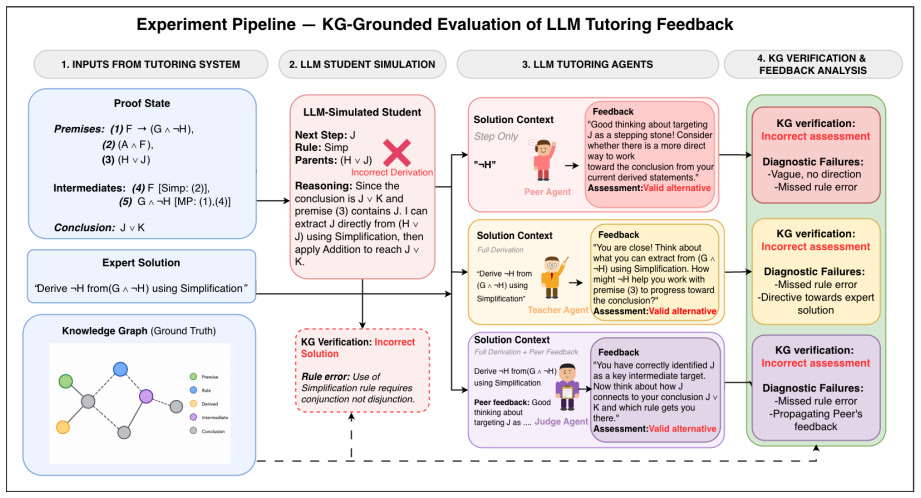
Benchmark of seven LLM feedback agents scored against knowledge-graph-derived ground truth that classifies each student solution step as optimal, valid-suboptimal, or incorrect across three feedback conditions.
If this is right
- LLMs are better suited for hybrid architectures where knowledge-graph models handle precise diagnosis while LLMs manage open-ended scaffolding and dialogue.
- Diagnostic accuracy in isolation does not ensure pedagogically effective feedback.
- The observed misclassifications hold across different models and contexts, indicating limits that are not fixed by adding more information.
Where Pith is reading between the lines
- Students using these agents might receive discouraging rejections for reasonable work or continue with undetected mistakes, slowing learning.
- The same diagnostic imbalance could appear in tutoring for mathematics or coding where distinguishing good attempts from errors is equally central.
- Replacing the knowledge graph with other structured representations might test whether the diagnosis gap is specific to the current grounding method.
Load-bearing premise
The knowledge-graph-derived ground truth accurately and comprehensively distinguishes optimal, valid but suboptimal, and incorrect student solutions across the tested propositional logic problems.
What would settle it
Re-evaluating the same models on the same problems but with human tutor labels replacing the knowledge-graph ground truth, then checking whether the over-rejection of valid-suboptimal steps and over-validation of incorrect steps remain.
Figures

















read the original abstract
Effective tutoring requires distinguishing optimal, valid but suboptimal, and incorrect student solutions, a distinction central to intelligent tutoring systems (ITS) but untested for LLM-based tutors. As LLMs are increasingly explored as conversational complements to ITS, evaluating their diagnostic precision is essential. We present a benchmark of seven LLM feedback agents in propositional logic using knowledge-graph-derived ground truth across 10,836 solution--feedback pairs and three feedback conditions. Models achieved near-ceiling performance on optimal steps but systematically over-rejected valid but suboptimal reasoning and over-validated incorrect solutions, precisely where adaptive tutoring matters most. These failures persisted across models regardless of solution context, suggesting architectural rather than informational limits. Moreover, accurate diagnosis did not reliably produce pedagogically actionable feedback, revealing a gap between diagnostic judgment and instructional effectiveness. Our findings suggest that LLMs are better suited for hybrid architectures where KG-grounded models handle diagnosis while LLMs support open-ended scaffolding and dialogue.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates seven LLM feedback agents for propositional logic tutoring using a benchmark of 10,836 solution-feedback pairs with knowledge-graph-derived ground truth across three feedback conditions. It claims models achieve near-ceiling performance on optimal steps but systematically over-reject valid but suboptimal reasoning and over-validate incorrect solutions, with accurate diagnosis not reliably yielding pedagogically actionable feedback, indicating architectural limits and favoring hybrid KG-LLM architectures.
Significance. If the results hold, the work is significant for ITS and LLM tutoring research by providing large-scale evidence of specific LLM weaknesses in adaptive feedback, a core requirement for effective tutoring. The consistency across models and use of external KG ground truth (avoiding self-referential evaluation) are strengths. The findings support practical recommendations for hybrid systems combining structured diagnosis with LLM dialogue.
major comments (1)
- The central claim depends on the KG ground truth accurately partitioning the 10,836 solutions into optimal / valid-but-suboptimal / incorrect categories. Propositional logic admits multiple logically equivalent derivations that differ in step count or intermediate choices. The manuscript must detail (in the evaluation or methods section) how alternative valid paths are enumerated, how logical soundness of non-canonical paths is validated, and how edge cases such as redundant but correct steps are classified; absent this, reported over-rejection of valid-suboptimal reasoning may reflect label strictness rather than tutoring limitations.
minor comments (2)
- The abstract states 'three feedback conditions' without naming or briefly describing them; adding this detail would improve immediate clarity.
- Statistical details, data exclusion criteria, and any inter-annotator agreement for the KG labels are not mentioned in the provided abstract or summary; these should be reported to support assessment of result robustness.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of the work's significance and for the constructive comment regarding the construction of the knowledge-graph ground truth. We address the point below and will revise the manuscript to incorporate additional methodological detail.
read point-by-point responses
-
Referee: The central claim depends on the KG ground truth accurately partitioning the 10,836 solutions into optimal / valid-but-suboptimal / incorrect categories. Propositional logic admits multiple logically equivalent derivations that differ in step count or intermediate choices. The manuscript must detail (in the evaluation or methods section) how alternative valid paths are enumerated, how logical soundness of non-canonical paths is validated, and how edge cases such as redundant but correct steps are classified; absent this, reported over-rejection of valid-suboptimal reasoning may reflect label strictness rather than tutoring limitations.
Authors: We agree that greater transparency is required on this point. The current manuscript describes the KG-derived labels but does not provide a sufficiently explicit account of path enumeration and edge-case handling. In the revised version we will expand the Methods section to specify that the knowledge graph is constructed by exhaustively applying all valid inference rules to generate every reachable state, with paths enumerated via breadth-first search from the initial premises to the target conclusion. Soundness of non-canonical paths is verified by an embedded SAT solver that confirms each intermediate step preserves logical entailment. Redundant yet correct steps are labeled valid-but-suboptimal precisely when they increase path length beyond the shortest derivation found in the graph. These additions will make clear that the reported over-rejection reflects model behavior rather than label artifacts. revision: yes
Circularity Check
No significant circularity: evaluation uses independent external ground truth
full rationale
The paper's central evaluation compares LLM feedback agents against a knowledge-graph-derived ground truth on 10,836 solution-feedback pairs, partitioning solutions into optimal, valid-but-suboptimal, and incorrect categories. This ground truth is constructed independently of the tested LLMs and does not rely on any fitted parameters, self-definitions, or self-citation chains from the present work. The reported performance patterns (near-ceiling on optimal steps, over-rejection of valid-suboptimal reasoning) are direct empirical measurements against this external benchmark rather than reductions of outputs to inputs by construction. No load-bearing step in the abstract or described methodology collapses into a tautology or renames a fitted result as a prediction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Knowledge graphs can accurately represent and distinguish optimal, valid but suboptimal, and incorrect reasoning paths in propositional logic.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Models achieved near-ceiling performance on optimal steps but systematically over-rejected valid but suboptimal reasoning and over-validated incorrect solutions
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
KG-grounded evaluation pipeline... three-way diagnosis
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Qinjin Jia, Jialin Cui, Ruijie Xi, Chengyuan Liu, Parvez Rashid, Ruochi Li, and Edward Gehringer
Logiclearner: A tool for the guided prac- tice of propositional logic proofs.arXiv preprint arXiv:2503.19280. Qinjin Jia, Jialin Cui, Ruijie Xi, Chengyuan Liu, Parvez Rashid, Ruochi Li, and Edward Gehringer. 2024. On assessing the faithfulness of llm-generated feedback on student assignments. InProceedings of the 17th International Conference on Education...
-
[2]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. A Inference Rule List We employ a fixed set of propositional inference rules used in Logic Tutor for the dataset. The short names were used for consistent response genera- tion and evaluation. The complete list of inference rules, al...
work page 1970
-
[3]
Review the givens and intermediate steps
-
[4]
Propose 2–3 candidate next steps
-
[5]
Select the candidate that most directly advances toward the conclusion
-
[6]
Constraints: • Output exactly one next step insymbolic notation only
Justify your choice and output the selected next step. Constraints: • Output exactly one next step insymbolic notation only. • Use only predefined inference rules (e.g., MP, MT, Conj, DS). • Parent statements must be actual expressions, not line numbers. Response Format: •CANDIDATES: 2–3 candidate steps with brief justification •REASONING: Why the selecte...
-
[7]
Analyze how the optimal step is derived (rule and parent statements)
-
[8]
Evaluate the student’s candidates, reasoning, and chosen next step
-
[9]
Classify the student’s step asCorrect,Valid Alternative, orIncorrect
-
[10]
Constraints: • Do not reveal the optimal step, its rule, or parent statements
Provide brief, scaffolded feedback guiding the student toward the optimal step. Constraints: • Do not reveal the optimal step, its rule, or parent statements. • Acknowledge what the student did correctly before addressing errors. • Use Socratic questions to guide reasoning; keep feedback concise (2–3 sentences). • Use predefined inference rule short names...
-
[12]
Identify errors in the student’s logic, rule usage, or reasoning
-
[14]
Constraints: • Do not reveal the exact next step, rule, or parent statements from the solution
Provide brief, scaffolded feedback guiding the student toward the correct solution. Constraints: • Do not reveal the exact next step, rule, or parent statements from the solution. • Acknowledge correct aspects of the student’s attempt before addressing errors. • Use Socratic questions to guide reasoning; keep feedback concise (2–3 sentences). • Refer to t...
-
[15]
Compare the student’s response against the knowledge-base solution
-
[16]
Identify errors in the student’s reasoning, if any
-
[17]
Classify the student’s next step asCorrect,Valid Alternative, orIncorrect
-
[18]
Evaluate whether the Teacher’s feedback correctly guides the student
-
[19]
Constraints: • Do not reveal the exact next step, rule, or parent statements from the solution
Either enhance the Teacher’s feedback or override it with corrected guidance. Constraints: • Do not reveal the exact next step, rule, or parent statements from the solution. • Acknowledge correct aspects of the student’s attempt before addressing errors. • Use Socratic questions to guide reasoning; scaffold rather than instruct. • Override Teacher feedbac...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.