Uncertainty-Aware Generation and Decision-Making Under Ambiguity
Pith reviewed 2026-06-30 05:52 UTC · model grok-4.3
The pith
Uncertainty estimates over strategies and scores let Bayesian decision rules raise the utility of LLM outputs in tutoring and reviewing, while risk-averse rules can produce overly generic text when ambiguity is high.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
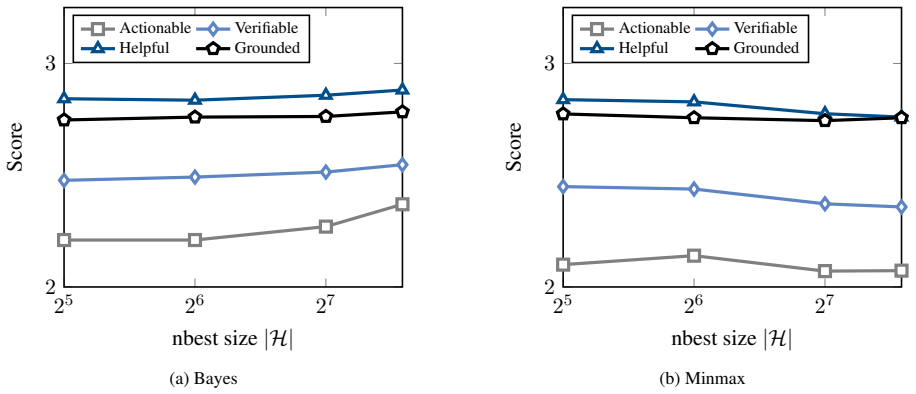
When uncertainty over tutoring strategies and review scores is propagated through Bayesian decision theory or risk-averse criteria, the resulting generations achieve higher task utility than standard greedy or sampling baselines; however, risk-averse criteria degrade performance by selecting generic outputs under high ambiguity, whereas Bayesian selection tends to remain effective.
What carries the argument
Bayesian decision theory and risk-averse criteria applied to uncertainty sets over tutoring strategies and review scores, with conformal prediction supplying the sets.
If this is right
- Bayesian selection of tutor responses yields higher measured student learning gains than deterministic baselines.
- Risk-averse review scoring produces shorter and more formulaic reviews precisely on papers with high model uncertainty.
- Conformal sets can be used to guarantee that the chosen output lies inside a high-probability region of acceptable strategies or scores.
- When ambiguity is high the performance ordering between Bayesian and risk-averse rules reverses in favor of the Bayesian rule.
Where Pith is reading between the lines
- The same machinery could be applied to other subjective generation tasks such as medical advice or legal drafting where multiple acceptable outputs exist.
- If conformal sets grow too large the decision rules may need an explicit cost for asking the user for clarification.
- Utility functions that incorporate long-term user retention rather than immediate scores might change which rule performs best.
Load-bearing premise
The uncertainty estimates produced by the LLM or by conformal prediction are well enough calibrated that the chosen utility functions correctly rank the real-world value of different outputs.
What would settle it
A controlled experiment in which the same set of tutoring or review instances is run once with the uncertainty-aware rules and once without them, and measured task utility shows no gain or a loss under the uncertainty-aware rules.
Figures











read the original abstract
With rapidly improving capabilities, Large Language Models (LLMs) are increasingly used in many complex real-world tasks. Beyond requiring in-depth knowledge and reasoning skills, many of these tasks exhibit a high degree of subjectivity and require that the outputs of the model can be trusted. While a lot of progress has been made to train better models, decision-making algorithms have received less attention. In this work, we present and evaluate various uncertainty-aware decision-making algorithms based on Bayesian decision theory and risk-averse decision making on the tasks of tutoring and automatic peer reviewing. Concretely, we take uncertainty over tutoring strategies and review scores into account when generating a tutor response or review and use conformal prediction to provide guarantees over strategy and score. We find empirically that these algorithms can improve the utility of the generations but need to be carefully implemented when ambiguity is high. For example, risk-averse rules can degrade performance by optimizing for generic outputs, while Bayesian methods tend to perform better. Our work uses techniques from decision theory to improve LLM-based decision-making and outlines open challenges for the community.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents and evaluates uncertainty-aware decision-making algorithms for LLMs, drawing on Bayesian decision theory and risk-averse methods, applied to tutoring and automatic peer-review tasks. It incorporates uncertainty over tutoring strategies and review scores, employs conformal prediction for coverage guarantees, and reports that the algorithms can improve generation utility when carefully implemented, with Bayesian methods outperforming risk-averse rules under high ambiguity (the latter sometimes producing overly generic outputs).
Significance. If the empirical comparisons hold after validation of the core assumptions, the work would be significant for bridging decision theory with LLM generation in subjective domains, offering concrete algorithms and highlighting implementation pitfalls that are relevant to reliability in real-world applications.
major comments (2)
- [Experimental results / evaluation sections] The central empirical claim (Bayesian rules improve utility over risk-averse ones under high ambiguity) depends on the calibration of the uncertainty distributions over strategies and scores; the manuscript provides no explicit calibration diagnostics, reliability diagrams, or sensitivity checks in the experimental evaluation, leaving open the possibility that observed gaps are artifacts of miscalibration rather than intrinsic properties of the decision rules.
- [Methods and evaluation] The utility functions used to score tutor responses and reviews are load-bearing for all quantitative comparisons, yet no validation against human judgments, downstream outcomes (e.g., actual learning gains or review helpfulness), or alternative utility specifications is reported; without this, the reported utility improvements cannot be confidently attributed to the decision-theoretic methods.
minor comments (1)
- [Abstract] The abstract states that conformal prediction supplies 'guarantees over strategy and score' but does not indicate the target coverage level, how the prediction sets are constructed, or how the guarantees are propagated into the Bayesian or risk-averse decision rules.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on empirical validation. We address the two major comments below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experimental results / evaluation sections] The central empirical claim (Bayesian rules improve utility over risk-averse ones under high ambiguity) depends on the calibration of the uncertainty distributions over strategies and scores; the manuscript provides no explicit calibration diagnostics, reliability diagrams, or sensitivity checks in the experimental evaluation, leaving open the possibility that observed gaps are artifacts of miscalibration rather than intrinsic properties of the decision rules.
Authors: We agree that calibration diagnostics are needed to support the central claim. In the revised manuscript we will add reliability diagrams for the uncertainty distributions over tutoring strategies and review scores, together with sensitivity analyses that vary the degree of miscalibration. These additions will show whether the reported gaps between Bayesian and risk-averse rules remain stable under different calibration conditions. revision: yes
-
Referee: [Methods and evaluation] The utility functions used to score tutor responses and reviews are load-bearing for all quantitative comparisons, yet no validation against human judgments, downstream outcomes (e.g., actual learning gains or review helpfulness), or alternative utility specifications is reported; without this, the reported utility improvements cannot be confidently attributed to the decision-theoretic methods.
Authors: We acknowledge that the chosen utility functions are central to the quantitative results. In revision we will expand the evaluation section to include (i) explicit discussion of how the utilities were derived from task requirements, (ii) results under two alternative utility specifications, and (iii) a limitations paragraph noting the absence of direct human or downstream validation. Full human-subject studies lie outside the current scope but are flagged as important future work. revision: partial
Circularity Check
No significant circularity; derivation applies external decision-theoretic methods
full rationale
The paper applies established Bayesian decision theory and risk-averse rules (drawn from prior literature) to LLM outputs for tutoring and peer review, combined with conformal prediction for uncertainty bounds. No load-bearing step reduces a claimed result to a self-defined parameter, a fitted input renamed as prediction, or a self-citation chain. The central empirical observation—that Bayesian methods outperform risk-averse ones under high ambiguity—is presented as an experimental finding contingent on calibration assumptions, not derived by construction from the authors' own prior work. This satisfies the default expectation for non-circular papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Julius Cheng and Andreas Vlachos
Conformal prediction for natural language pro- cessing: A survey.Transactions of the Association for Computational Linguistics, 12:1497–1516. Julius Cheng and Andreas Vlachos. 2023. Faster min- imum Bayes risk decoding with confidence-based pruning. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Process- ing, pages 12473–124...
2023
-
[2]
Gemini-backed paper assistant tool provides automated feedback for theoretical computer scientists at stoc 2026. https: //research.google/blog/gemini-provides- automated-feedback-for-theoretical- computer-scientists-at-stoc-2026/ . Google Research Blog, accessed June 30, 2026. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
From problem-solving to teaching problem- solving: Aligning LLMs with pedagogy using re- inforcement learning. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 272–292, Suzhou, China. Association for Computational Linguistics. Nils Dycke, Ilia Kuznetsov, and Iryna Gurevych. 2023. NLPeer: A unified resource ...
-
[4]
InProceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 15262–15306
R-u-SURE? Uncertainty-aware code sug- gestions by maximizing utility across random user intents. InProceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 15262–15306. PMLR. Manu Kapur. 2008. Productive failure.Cognition and Instruction, 26(3):379–424. Shayan Kiyani, George J. Pap...
2008
-
[5]
InProceedings of the Ninth Conference on Machine Translation, pages 1063–1094, Miami, Florida, USA
Mitigating metric bias in minimum Bayes risk decoding. InProceedings of the Ninth Conference on Machine Translation, pages 1063–1094, Miami, Florida, USA. Association for Computational Lin- guistics. Sandeep Kumar, Tirthankar Ghosal, and Asif Ekbal
-
[6]
InProceedings of the 2023 Conference on Empirical Methods in Natu- ral Language Processing, pages 16693–16704, Sin- gapore
When reviewers lock horns: Finding disagree- ments in scientific peer reviews. InProceedings of the 2023 Conference on Empirical Methods in Natu- ral Language Processing, pages 16693–16704, Sin- gapore. Association for Computational Linguistics. Shankar Kumar and William Byrne. 2004. Minimum Bayes-risk decoding for statistical machine transla- tion. InPro...
2023
-
[7]
Llm-as-a-verifier: A general-purpose verifica- tion framework. Notion Blog. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. Effi- cient memory management for large language model serving with pagedattention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Syst...
-
[8]
Autotutor and family: A review of 17 years of natural language tutoring.Int. J. Artif. Intell. Educ., 24(4):427–469. Vardhan Palod, Upasana Biswas, and Subbarao Kamb- hampati. 2026. Evaluating the false trust engendered by llm explanations.Preprint, arXiv:2605.10930. Jieun Park, KyungTae Lim, and Joon-ho Lim. 2026. Be- yond accuracy: Alignment and error d...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
DeepReviewer 2.0: A Traceable Agentic System for Auditable Scientific Peer Review
Cycleresearcher: Improving automated re- search via automated review. InThe Thirteenth Inter- national Conference on Learning Representations. Yixuan Weng, Minjun Zhu, Qiujie Xie, Zhiyuan Ning, Shichen Li, Panzhong Lu, Zhen Lin, Enhao Gu, Qiyao Sun, and Yue Zhang. 2026. Deepreviewer 2.0: A traceable agentic system for auditable scien- tific peer review.Pr...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
In Proceedings of the 63rd Annual Meeting of the As- sociation for Computational Linguistics (V olume 1: Long Papers), pages 29330–29355, Vienna, Austria
DeepReview: Improving LLM-based paper review with human-like deep thinking process. In Proceedings of the 63rd Annual Meeting of the As- sociation for Computational Linguistics (V olume 1: Long Papers), pages 29330–29355, Vienna, Austria. Association for Computational Linguistics. Furkan ¸ Sahinuç, Subhabrata Dutta, and Iryna Gurevych
-
[11]
Reward Modeling for Scientific Writing Evaluation
Reward modeling for scientific writing evalua- tion.Preprint, arXiv:2601.11374. 12 A Experimental Details A.1 Reviewing Experiments We first detail the exact prompts that we use for our work for reproducibility. The prompts for generating reviews on ICLR and ACL are found in Fig. 3 and Fig. 4, respectively. These prompts directly follow the guidelines tha...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
? - Recall Relevant Information: Can you reread the question and tell me what is
Focus: - Seek Strategy: So what should you do next? - Guiding Student: Can you calculate . . . ? - Recall Relevant Information: Can you reread the question and tell me what is . . . ?
-
[13]
items instead? - Seeking World Knowledge: How do you calculate the perimeter of a square?
Probing: - Asking for Explanation: Why do you think you need to add these numbers? - Seeking Self Correction: Are you sure you need to add here? - Perturbing the Question: How would things change if they had . . . items instead? - Seeking World Knowledge: How do you calculate the perimeter of a square?
-
[14]
Telling: - Revealing Strategy: You need to add . . . to . . . to get your answer. - Revealing Answer No, he had . . . items
-
[15]
, how are you doing with the word problem? - General inquiry: Can you go walk me through your solution? Telling should only be used rarely, for example, if the student is stuck
Generic: - Greeting/Farewell: Hi . . . , how are you doing with the word problem? - General inquiry: Can you go walk me through your solution? Telling should only be used rarely, for example, if the student is stuck. ## Output Format Return only one number in the range 0-3 to indicate the tutoring strategy from the list and nothing else. Figure 13: Prompt...
-
[16]
? - Recall Relevant Information: Can you reread the question and tell me what is
focus: - Seek Strategy: So what should you do next? - Guiding Student: Can you calculate . . . ? - Recall Relevant Information: Can you reread the question and tell me what is . . . ?
-
[17]
items instead? - Seeking World Knowledge: How do you calculate the perimeter of a square?
probing: - Asking for Explanation: Why do you think you need to add these numbers? - Seeking Self Correction: Are you sure you need to add here? - Perturbing the Question: How would things change if they had . . . items instead? - Seeking World Knowledge: How do you calculate the perimeter of a square?
-
[18]
telling: - Revealing Strategy: You need to add . . . to . . . to get your answer. - Revealing Answer No, he had . . . items
-
[19]
generic: - Greeting/Farewell: Hi . . . , how are you doing with the word problem? - General inquiry: Can you go walk me through your solution? 18 # Scoring Guidelines Use these criteria to score a response according to the following rubrics: (a) correctness: the teacher should guide the student towards the correct answer and not state incorrect facts (b) ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.