ClinicBot: A Guideline-Grounded Clinical Chatbot with Prioritized Evidence RAG and Verifiable Citations
Pith reviewed 2026-05-10 16:55 UTC · model grok-4.3
The pith
ClinicBot extracts clinical guidelines into semantic units and prioritizes evidence by significance to generate verifiable answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
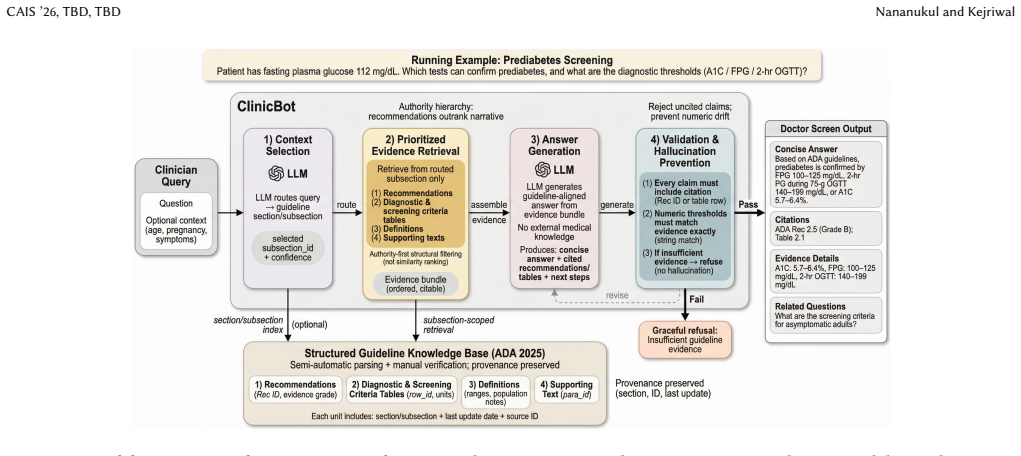
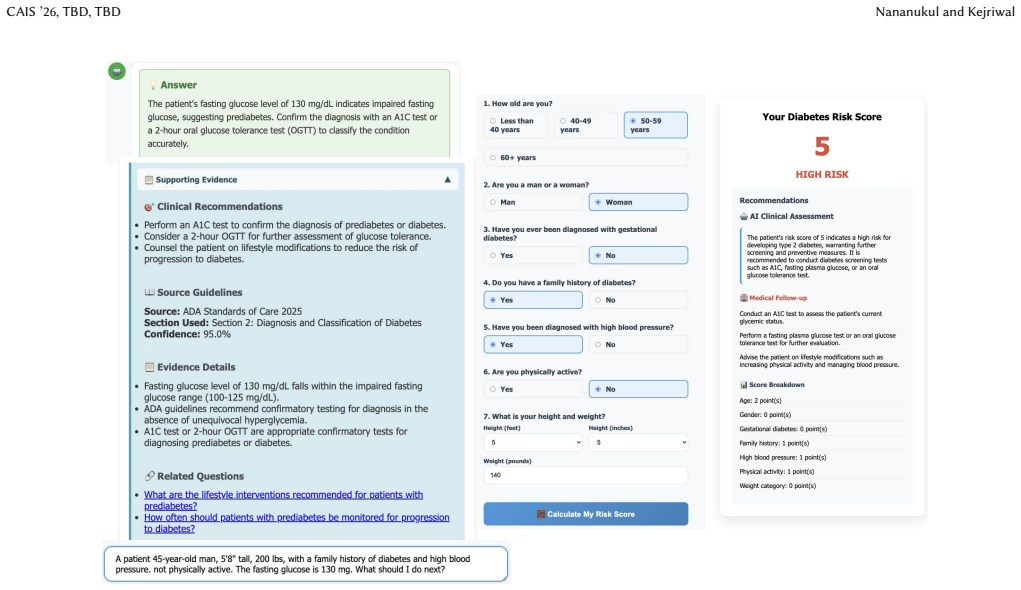
ClinicBot translates guideline recommendations into trustworthy clinical support through three advances: structured extraction of clinical guidelines into semantic units (recommendations, tables, definitions, narrative) with explicit provenance; evidence prioritization that ranks content by clinical significance and guideline structure rather than textual similarity; and a web-based interface that presents concise, actionable answers with verifiable evidence. The system operates in a multi-agent setting to process complex guidelines, as demonstrated with diabetes patient questions and a risk assessment tool faithful to the ADA Standards of Care in Diabetes (2025).
What carries the argument
Prioritized Evidence RAG, which ranks guideline-derived semantic units by clinical significance and structure hierarchy instead of textual similarity, paired with provenance-tracked extraction.
If this is right
- Clinical chatbots can deliver answers aligned with official guidelines rather than generic language model outputs.
- Verifiable citations become standard in medical AI responses, allowing direct checking against source documents.
- The approach scales to process lengthy, multi-section guidelines through structured extraction and multi-agent coordination.
- Diabetes-specific tools can be built that remain faithful to standards like the ADA 2025 guidelines for both questions and risk assessment.
- Actionable, concise responses replace noisy or unprioritized evidence in high-stakes medical interactions.
Where Pith is reading between the lines
- The same extraction-plus-prioritization pattern could extend to guidelines in other medical specialties where official documents are lengthy and hierarchical.
- Traceable evidence might increase clinician willingness to consult AI tools during patient consultations.
- Future tests could measure whether the ranking reduces specific error types, such as over-emphasis on less critical narrative sections.
- The structure might apply outside medicine to any domain that relies on authoritative, hierarchical documents for decision support.
Load-bearing premise
Clinical significance and guideline structure can be defined and ranked objectively enough to produce reliable prioritization without introducing new errors or omitting critical context.
What would settle it
A side-by-side clinician evaluation of ClinicBot outputs versus standard similarity-based RAG on the same set of guideline questions, checking whether prioritization causes omissions of key recommendations or context.
Figures
read the original abstract
Clinical diagnosis requires answers that are accurate, verifiable, and explicitly grounded in official guidelines. While large language models excel at natural language processing, their tendency to hallucinate undermines their utility in high-stakes medical contexts where precision is essential. Existing retrieval-augmented generation (RAG) systems treat all evidence equally, producing noisy context and generic answers misaligned with clinical practice. We present ClinicBot, an AI system that translates guideline recommendations into trustworthy clinical support through three key advances: (1) structured extraction of clinical guidelines into semantic units (recommendations, tables, definitions, narrative) with explicit provenance, (2) evidence prioritization that ranks content by clinical significance and guideline structure rather than textual similarity, and (3) a web-based interface that presents concise, actionable answers with verifiable evidence. We will demonstrate ClinicBot using diabetes questions from real patients and an additional diabetes risk assessment tool that is faithful to the American Diabetes Association (ADA) Standards of Care in Diabetes (2025). The demonstration will illustrate how semantic knowledge extraction and hierarchical evidence ranking can reliably operate in a multi-agent setting to process complex clinical guidelines at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes ClinicBot, a multi-agent clinical chatbot that extracts guidelines into semantic units (recommendations, tables, definitions, narrative) with explicit provenance, ranks evidence by clinical significance and guideline structure rather than textual similarity, and delivers concise answers via a web interface with verifiable citations. It asserts that these advances enable trustworthy support and reliable operation on complex guidelines, with a planned demonstration on real-patient diabetes queries and an ADA Standards of Care (2025)-aligned risk assessment tool.
Significance. If the prioritization mechanism and extraction pipeline prove reliable, the work could meaningfully advance RAG systems for guideline-grounded clinical use by reducing noise from similarity-based retrieval and improving alignment with clinical priorities and provenance. The focus on verifiable citations and structured semantic units addresses a recognized gap in medical AI trustworthiness.
major comments (3)
- [Abstract] Abstract: The assertion that the three advances 'produce trustworthy support and reliable multi-agent operation' lacks any supporting evaluation data, baselines, error rates, expert agreement metrics, or user studies; the manuscript only states that it 'will demonstrate' the system.
- [System description / Demonstration] Demonstration and system description sections: No implementation details are supplied for the evidence prioritization function (how 'clinical significance' and 'guideline structure' are operationalized and scored), no ablation or error analysis of the ranking, and no head-to-head comparison against standard similarity-based RAG.
- [Abstract] Abstract and conclusion: The claim of faithful ADA alignment for the risk tool and reliable multi-agent processing of complex guidelines is presented without quantitative validation or failure-case analysis, leaving the central reliability assertion untested.
minor comments (2)
- [Methods] The manuscript would benefit from explicit pseudocode or a small worked example of the prioritization ranking to clarify how guideline structure is encoded.
- [Interface] Figure captions and interface screenshots should include concrete examples of citation provenance display to illustrate verifiability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the distinction between system design and empirical validation. We address each major point below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that the three advances 'produce trustworthy support and reliable multi-agent operation' lacks any supporting evaluation data, baselines, error rates, expert agreement metrics, or user studies; the manuscript only states that it 'will demonstrate' the system.
Authors: We agree that the current abstract presents forward-looking claims without accompanying data. The manuscript is structured as a system description paper that outlines the architecture and a planned demonstration rather than reporting completed experiments. In revision we will rephrase the abstract to state that the three advances are designed to produce trustworthy support and reliable operation, with these properties to be assessed through the forthcoming demonstration on real-patient queries and the ADA-aligned risk tool. We will also add a brief forward-looking evaluation plan subsection describing intended metrics (e.g., citation accuracy, expert agreement on clinical appropriateness). revision: yes
-
Referee: [System description / Demonstration] Demonstration and system description sections: No implementation details are supplied for the evidence prioritization function (how 'clinical significance' and 'guideline structure' are operationalized and scored), no ablation or error analysis of the ranking, and no head-to-head comparison against standard similarity-based RAG.
Authors: The full manuscript contains a high-level description of the prioritization criteria (clinical significance derived from recommendation class and patient applicability; guideline structure derived from section hierarchy and provenance metadata). However, we acknowledge that operational details, scoring formulas, and comparison to baseline RAG are insufficiently specified. In the revised manuscript we will expand the system description with explicit scoring rules, pseudocode for the ranking function, and a qualitative head-to-head discussion of how prioritized retrieval differs from similarity-only retrieval. A quantitative ablation or error analysis will be added after the planned demonstration is completed. revision: partial
-
Referee: [Abstract] Abstract and conclusion: The claim of faithful ADA alignment for the risk tool and reliable multi-agent processing of complex guidelines is presented without quantitative validation or failure-case analysis, leaving the central reliability assertion untested.
Authors: The manuscript presents the risk tool and multi-agent pipeline as aligned with ADA 2025 by construction (via structured extraction of the official document) and states that reliability will be illustrated by the demonstration. We agree that no quantitative validation or failure-case analysis is currently provided. We will revise the abstract and conclusion to make this prospective framing explicit and will include a short discussion of anticipated failure modes (e.g., guideline ambiguity, conflicting recommendations) together with the mitigation strategies built into the extraction and prioritization stages. Quantitative results cannot be supplied until the demonstration is executed. revision: yes
Circularity Check
No circularity: system description with no derivations or fitted predictions
full rationale
The manuscript is a descriptive presentation of ClinicBot's architecture (structured guideline extraction, prioritization by clinical significance rather than similarity, and verifiable interface). No equations, parameters, predictions, or derivation chains appear in the provided text or abstract. Claims rest on design choices and a planned demonstration rather than any reduction of outputs to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. This matches the default expectation of no significant circularity for system-description papers.
Axiom & Free-Parameter Ledger
invented entities (1)
-
ClinicBot multi-agent system
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Inform, Coach, Relate, Listen: Auditing LLM Caregiving Support Roles
LLM support roles in Alzheimer's caregiving queries systematically alter interactional risk prevalence and composition, with directive roles rated higher in quality despite elevated risks.
Reference graph
Works this paper leans on
-
[1]
Manar Aljohani, Jun Hou, Sindhura Kommu, and Xuan Wang. 2025. A compre- hensive survey on the trustworthiness of large language models in healthcare. npj Digital Medicine8 (2025), 1–18
work page 2025
-
[2]
American Diabetes Association. 2025. Standards of Care in Diabetes.Diabetes Care48, Suppl. 1 (2025), S1–S387
work page 2025
-
[3]
Z Chen et al. 2023. Harnessing the power of clinical decision support systems: challenges and opportunities.Open Heart10, 1 (2023), e001878
work page 2023
-
[4]
Kristof Coussement, Mohammad Zoynul Abedin, Mathias Kraus, Sebastián Mal- donado, and Kazim Topuz. 2024. Explainable AI for enhanced decision-making. Decision Support Systems184 (2024), 114276
work page 2024
-
[5]
Gordon Guyatt, Andrew D Oxman, Gunn E Vist, Regina Kunz, Yngve Falck-Ytter, Pablo Alonso-Coello, and Holger J Schünemann. 2011. GRADE: an emerging consensus on rating quality of evidence and strength of recommendations.BMJ 336, 7650 (2011), 924–926
work page 2011
-
[6]
Andreas Holzinger, Georg Langs, Helmut Denk, et al. 2024. FUTURE-AI: Guiding principles and consensus recommendations for responsible development and deployment of artificial intelligence in healthcare.BMJ Health Care Informatics 31, 1 (2024), e100623
work page 2024
-
[7]
Lei Huang, Weijiang Yu, Weitao Ma, et al. 2025. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on Information Systems43, 2 (2025), 1–55
work page 2025
-
[8]
Qiao Jin, Woojeong Kim, Qingyu Chen, et al. 2023. MedCPT: Contrastive pre- trained transformers with large-scale PubMed search logs for zero-shot biomedi- cal information retrieval.Bioinformatics39 (2023), btad651
work page 2023
-
[9]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open- domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 6769–6781
work page 2020
-
[10]
Jessica L Kwan, Linda Lo, Jane Ferguson, William A Ghali, and Diane Rabi. 2020. Computerised clinical decision support systems and absolute improvements in care: meta-analysis of controlled clinical trials.BMJ359 (2020), j4437
work page 2020
-
[11]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems, Vol. 33. 9459–9474
work page 2020
-
[12]
Jerry Liu. 2023. LlamaIndex: Data Framework for LLM Applications. https: //github.com/run-llama/llama_index
work page 2023
-
[13]
OpenAI. 2024. GPT-4 Technical Report. https://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed Chi, Nathanael Schärli, and Denny Zhou. 2023. Large language models can be easily distracted by irrelevant context. InInternational Conference on Machine Learning (ICML). 31210–31227
work page 2023
-
[15]
Karan Singhal, Shekoofeh Azizi, Tao Tu, Sara S Mahdavi, Jonathan Lau, Jacob C Barnett, Cesar Bifulco, Andrew Callahan, Nancy Chang, Carolyn Gentzel, et al
-
[16]
Large language models encode clinical knowledge.Nature620 (2023), 172–180
work page 2023
-
[17]
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R Pfohl, Heather Cole-Lewis, et al . 2025. Toward expert-level medical question answering with large language models. Nature Medicine31, 3 (2025), 943–950
work page 2025
-
[18]
Arun James Thirunavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, and Daniel Shu Wei Ting. 2023. Large language models in medicine.Nature Medicine29, 8 (2023), 1930–1940
work page 2023
-
[19]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal
-
[20]
InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics
Interleaving retrieval with chain-of-thought reasoning for knowledge- intensive multi-step questions. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics. 10014–10037
-
[21]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, Vol. 35. 24824–24837
work page 2022
-
[22]
Xiangru Zhao et al. 2025. MedRAG: Enhancing retrieval-augmented generation with knowledge graph-elicited reasoning for healthcare copilot. InProceedings of the ACM Web Conference 2025. 4442–4457. Received 13 March 2026; revised 13 March 2026; accepted 13 March 2026
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.