Inform, Coach, Relate, Listen: Auditing LLM Caregiving Support Roles
Pith reviewed 2026-06-29 05:52 UTC · model grok-4.3
The pith
Assigning different support roles to LLMs changes the interactional risks they produce in caregiving conversations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
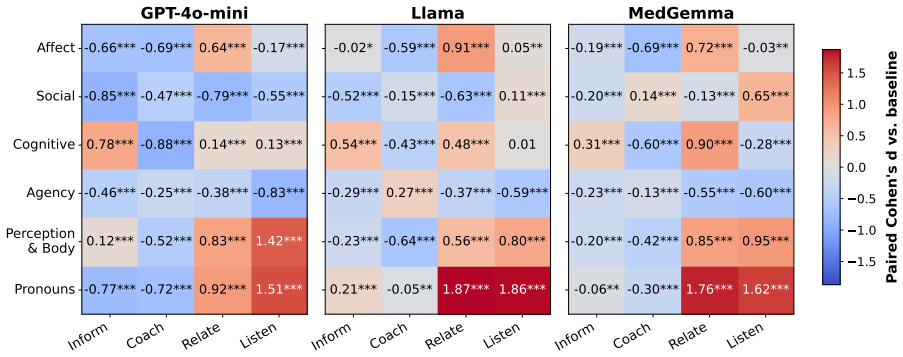
The LLM's support role systematically shapes both the prevalence and composition of interactional risks. A human evaluation study reveals a perceived quality-safety tension: more directive, information-oriented roles are rated as more helpful and trustworthy despite exhibiting elevated interactional risk profiles.
What carries the argument
Four expert-reviewed support roles (Inform, Coach, Relate, Listen) grounded in social support theory, applied to 5,000 real-world ADRD queries and compared against basic and RAG baselines.
If this is right
- The prevalence and composition of interactional risks vary systematically with the assigned support role.
- Information-oriented roles exhibit higher interactional risk profiles yet receive higher human ratings for helpfulness and trustworthiness.
- The pattern appears across GPT-4o-mini, Llama-3.1-8B-Instruct, and MedGemma-1.5-4b-it.
- The released set of role-conditioned responses supports further study of safer conversational support designs.
Where Pith is reading between the lines
- Role choice offers a direct way to adjust risk levels in deployed caregiving systems without retraining the underlying model.
- The same role-based auditing approach could be applied to other high-stakes conversational domains such as mental health or financial advice.
- Users may continue to prefer directive roles in practice even when risks are documented, creating a design trade-off that requires new mitigation strategies.
- Dynamic role switching during a single conversation might reduce the observed tension between perceived quality and measured safety.
Load-bearing premise
The four support roles are distinct and the risk annotations on the queries from ADRD communities reliably capture interactional risks in caregiving contexts.
What would settle it
Re-running the same queries with new role prompts or fresh risk annotations that show no systematic difference in risk prevalence or composition across roles would falsify the central claim.
Figures
read the original abstract
Language models are increasingly being deployed for conversational support in informal caregiving contexts, where interactions often extend beyond information-seeking: caregivers seek emotional reassurance, guidance, and help, while navigating uncertain, relationally complex care decisions. Yet most safety evaluations assess model behavior under generic prompts, leaving a critical question unexamined: does a model's safety profile change with its support role? We study this by operationalizing four expert-reviewed support roles grounded in social support theory: Inform, Coach, Relate, and Listen, and comparing them against two baseline controls: a basic prompting condition and a retrieval-augmented generation (RAG) condition. We evaluate across three language models (GPT-4o-mini, Llama-3.1-8B-Instruct, and MedGemma-1.5-4b-it) on 5,000 real-world queries from online Alzheimer's Disease and Related Dementias (ADRD) communities. We find that the LLM's support role systematically shapes both the prevalence and composition of interactional risks. Furthermore, a human evaluation study reveals a perceived quality--safety tension: more directive, information-oriented roles are rated as more helpful and trustworthy despite exhibiting elevated interactional risk profiles. We release ~90,000 support role-conditioned model responses with risk annotations as an ecologically grounded resource for research on safer LLM-mediated conversational support.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper operationalizes four expert-reviewed support roles (Inform, Coach, Relate, Listen) grounded in social support theory, plus two baselines, and evaluates their effects on interactional risks in ~90k LLM responses to 5,000 real-world ADRD caregiving queries across GPT-4o-mini, Llama-3.1-8B-Instruct, and MedGemma. It claims that support role systematically alters both the prevalence and composition of risks, and reports a human evaluation finding a quality-safety tension in which more directive roles receive higher helpfulness/trustworthiness ratings despite elevated risk profiles. The authors release the annotated response corpus as a resource.
Significance. If the risk annotations prove reliable and unbiased, the work would usefully demonstrate that role prompting is a controllable factor in conversational safety for high-stakes caregiving domains and would supply an ecologically grounded dataset for follow-on research. The public release of the ~90k role-conditioned responses with annotations is a concrete strength for reproducibility.
major comments (2)
- [Methods] Methods section (risk annotation protocol): the central claim that roles shape prevalence and composition of interactional risks rests on the validity of the ~90k risk annotations, yet the manuscript supplies no description of whether annotations were performed by human experts or LLMs, whether annotators were blinded to role condition, the number of annotators per response, inter-rater reliability statistics, or any validation against expert caregivers. Without these details the observed role differences could be artifacts of annotation bias rather than genuine interactional risk shifts.
- [Human Evaluation] Human evaluation study: the reported quality-safety tension (directive roles rated more helpful/trustworthy despite higher risks) is load-bearing for the practical implications, but the manuscript provides insufficient detail on participant recruitment, rating scales and instructions, blinding procedures, statistical tests used to establish the tension, or sample size/power. This prevents assessment of whether the tension is robust or an artifact of the evaluation design.
minor comments (2)
- [Abstract] Abstract: the claim that the four roles are 'expert-reviewed' is stated without any citation or description of the review process; a brief sentence on the review criteria or reviewers would improve transparency.
- [Results] The manuscript does not report baseline risk rates under the two control conditions (basic prompting and RAG) in the main results tables, making it harder to interpret the magnitude of role-induced changes.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback emphasizing the need for greater methodological transparency. We address each major comment below and commit to revisions that will strengthen the paper's reproducibility.
read point-by-point responses
-
Referee: [Methods] Methods section (risk annotation protocol): the central claim that roles shape prevalence and composition of interactional risks rests on the validity of the ~90k risk annotations, yet the manuscript supplies no description of whether annotations were performed by human experts or LLMs, whether annotators were blinded to role condition, the number of annotators per response, inter-rater reliability statistics, or any validation against expert caregivers. Without these details the observed role differences could be artifacts of annotation bias rather than genuine interactional risk shifts.
Authors: We agree that the manuscript omits these essential details on the risk annotation protocol, which is a limitation that prevents full assessment of annotation validity. In the revised manuscript we will add a dedicated methods subsection specifying the annotator type (human experts), blinding to role condition, number of annotators per response, inter-rater reliability statistics, and any validation steps against expert caregivers. revision: yes
-
Referee: [Human Evaluation] Human evaluation study: the reported quality-safety tension (directive roles rated more helpful/trustworthy despite higher risks) is load-bearing for the practical implications, but the manuscript provides insufficient detail on participant recruitment, rating scales and instructions, blinding procedures, statistical tests used to establish the tension, or sample size/power. This prevents assessment of whether the tension is robust or an artifact of the evaluation design.
Authors: We concur that the human evaluation section lacks sufficient detail to evaluate the quality-safety tension. In the revised manuscript we will expand this section to describe participant recruitment, rating scales and instructions, blinding procedures, statistical tests, sample size, and power analysis. revision: yes
Circularity Check
No circularity: empirical comparisons rest on external queries, theory-grounded roles, and human ratings
full rationale
The paper operationalizes four roles from social support theory, applies them to 5,000 real ADRD queries, generates responses, annotates risks, and conducts separate human evaluation. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the abstract or described chain. The central finding (role shapes risk prevalence/composition) is a statistical comparison across conditions, not a reduction to its own inputs. Annotation validity is a measurement concern but does not create circularity per the enumerated patterns; the derivation remains self-contained against the external query corpus and human raters.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
When AI Says "I have been in similar situations": Synthetic Lived Experience in Peer-Like Caregiver Support
LLMs prompted as peer supporters for ADRD caregivers produce synthetic lived experience through narrative language that differs from human peers in first-person and past-tense usage, revealing a narrative authenticity gap.
-
A Taxonomy of Mental Health and Technology Needs for Alzheimer's and Dementia Caregivers
Develops a Caregiver Mental Health and Technology Taxonomy from literature review and qualitative studies to link AD/ADRD caregiver needs with technology interventions and identify mismatches.
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, and 1 others. 2022. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Asma Ben Abacha and Dina Demner-Fushman. 2019. A question-entailment approach to question answering. BMC bioinformatics, 20(1):511
2019
-
[5]
Kesstan Blandin and Renee Pepin. 2017. Dementia grief: A theoretical model of a unique grief experience. Dementia, 16(1):67--78
2017
-
[6]
Brant R Burleson and Daena J Goldsmith. 1996. How the comforting process works: Alleviating emotional distress through conversationally induced reappraisals. In Handbook of communication and emotion, pages 245--280. Elsevier
1996
-
[7]
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J Pappas, Florian Tramer, and 1 others. 2024. Jailbreakbench: An open robustness benchmark for jailbreaking large language models. Advances in Neural Information Processing Systems, 37:55005--55029
2024
-
[8]
Vivienne Bihe Chi, Adithya V Ganesan, Ryan L Boyd, Lyle Ungar, and Sharath Chandra Guntuku. 2026. When support escalates distress: Regulation and escalation in llm responses to venting and advice-seeking. arXiv preprint arXiv:2605.21569
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E Gonzalez, and 1 others. 2024. Chatbot arena: An open platform for evaluating llms by human preference. arXiv preprint arXiv:2403.04132
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Carolyn E Cutrona and Beth R Troutman. 1986. Social support, infant temperament, and parenting self-efficacy: A mediational model of postpartum depression. Child development, pages 1507--1518
1986
-
[11]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazar \'e , Maria Lomeli, Lucas Hosseini, and Herv \'e J \'e gou. 2025. The faiss library. IEEE Transactions on Big Data
2025
-
[12]
Yan Du, Brittany Dennis, Jia Liu, Kylie Meyer, Nazish Siddiqui, Katrina Lopez, Carole White, Sahiti Myneni, Mitzi Gonzales, and Jing Wang. 2021. A conceptual model to improve care for individuals with alzheimer’s disease and related dementias and their caregivers: qualitative findings in an online caregiver forum. Journal of Alzheimer’s disease, 81(4):1673--1684
2021
-
[13]
Nicolas Farina, Thomas E Page, Stephanie Daley, Anna Brown, Ann Bowling, Thurstine Basset, Gill Livingston, Martin Knapp, Joanna Murray, and Sube Banerjee. 2017. Factors associated with the quality of life of family carers of people with dementia: A systematic review. Alzheimer's & Dementia, 13(5):572--581
2017
-
[14]
i feel guilty
Laura Gallego-Alberto, Andr \'e s Losada, Isabel Cabrera, Rosa Romero-Moreno, Ana P \'e rez-Miguel, Mar \' a Del Sequeros Pedroso-Chaparro, and Mar \' a M \'a rquez-Gonz \'a lez. 2022. “i feel guilty”. exploring guilt-related dynamics in family caregivers of people with dementia. Clinical Gerontologist, 45(5):1294--1303
2022
-
[15]
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, and 1 others. 2022. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned. arXiv preprint arXiv:2209.07858
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A Smith. 2020. Realtoxicityprompts: Evaluating neural toxic degeneration in language models. arXiv preprint arXiv:2009.11462
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [17]
-
[18]
Wordh Ul Hasan, Kimia Tuz Zaman, Xin Wang, Juan Li, Bo Xie, and Cui Tao. 2024. Empowering alzheimer’s caregivers with conversational ai: A novel approach for enhanced communication and personalized support. npj Biomedical Innovations, 1(1):3
2024
-
[19]
Andrew C High and James Price Dillard. 2012. A review and meta-analysis of person-centered messages and social support outcomes. Communication Studies, 63(1):99--118
2012
- [20]
-
[21]
Yue Huang, Lichao Sun, Haoran Wang, Siyuan Wu, Qihui Zhang, Yuan Li, Chujie Gao, Yixin Huang, Wenhan Lyu, Yixuan Zhang, and 1 others. 2024. Trustllm: Trustworthiness in large language models. arXiv preprint arXiv:2401.05561
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [22]
-
[23]
Becky Inkster, Shubhankar Sarda, and Vinod Subramanian. 2018. An empathy-driven, conversational artificial intelligence agent (wysa) for digital mental well-being: real-world data evaluation mixed-methods study. JMIR mHealth and uHealth, 6(11):e12106
2018
-
[24]
Gautier Izacard and Edouard Grave. 2021. https://doi.org/10.18653/v1/2021.eacl-main.74 Leveraging passage retrieval with generative models for open domain question answering . In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 874--880, Online. Association for Computational Li...
-
[25]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. ACM computing surveys, 55(12):1--38
2023
-
[26]
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. 2019. https://doi.org/10.18653/v1/D19-1259 P ub M ed QA : A dataset for biomedical research question answering . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-I...
-
[27]
Sidharth Kaliappan, Chunyu Liu, Yoshee Jain, Ravi Karkar, and Koustuv Saha. 2025. Online communities as a support system for alzheimer disease and dementia care: Large-scale exploratory study. JMIR aging, 8:e68890
2025
-
[28]
Meeyun Kim, Koustuv Saha, Munmun De Choudhury, and Daejin Choi. 2023. Supporters first: understanding online social support on mental health from a supporter perspective. Proceedings of the ACM on Human-Computer Interaction, 7(CSCW1):1--28
2023
- [29]
-
[30]
Shuyue S Li, Vidhisha Balachandran, Shangbin Feng, Jonathan S Ilgen, Emma Pierson, Pang W Koh, and Yulia Tsvetkov. 2024. Mediq: Question-asking llms and a benchmark for reliable interactive clinical reasoning. Advances in Neural Information Processing Systems, 37:28858--28888
2024
-
[31]
Hudson, and 31 others
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D Manning, Christopher Re, Diana Acosta-Navas, Drew A. Hudson, and 31 others. 2023. https://openreview.net/forum?id=iO4LZibEqW...
2023
-
[32]
Yang Liu, Yuanshun Yao, Jean-Francois Ton, Xiaoying Zhang, Ruocheng Guo, Hao Cheng, Yegor Klochkov, Muhammad Faaiz Taufiq, and Hang Li. 2023. Trustworthy llms: a survey and guideline for evaluating large language models' alignment. arXiv preprint arXiv:2308.05374
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Mantas Mazeika, Long Phan, Xuwang Yin, Andy Zou, Zifan Wang, Norman Mu, Elham Sakhaee, Nathaniel Li, Steven Basart, Bo Li, and 1 others. 2024. Harmbench: A standardized evaluation framework for automated red teaming and robust refusal. arXiv preprint arXiv:2402.04249
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
William R Miller and Stephen Rollnick. 2012. Motivational interviewing: Helping people change. Guilford press
2012
-
[35]
Yutao Mou, Shikun Zhang, and Wei Ye. 2024. Sg-bench: Evaluating llm safety generalization across diverse tasks and prompt types. Advances in Neural Information Processing Systems, 37:123032--123054
2024
-
[36]
Navapat Nananukul and Mayank Kejriwal. 2026. Clinicbot: A guideline-grounded clinical chatbot with prioritized evidence rag and verifiable citations. arXiv preprint arXiv:2605.00846
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[37]
World Health Organization and 1 others. 2017. Global action plan on the public health response to dementia 2017--2025. World Health Organization
2017
-
[38]
Andrew C Pickett, Danny Valdez, Kelsey L Sinclair, Wesley J Kochell, Boone Fowler, and Nicole E Werner. 2024. Social media discourse related to caregiving for older adults living with alzheimer disease and related dementias: computational and qualitative study. JMIR aging, 7(1):e59294
2024
-
[39]
Jennifer S Priem and Denise Haunani Solomon. 2018. What is supportive about supportive conversation? qualities of interaction that predict emotional and physiological outcomes. Communication Research, 45(3):443--473
2018
-
[40]
Pragnya Ramjee, Mehak Chhokar, Bhuvan Sachdeva, Mahendra Meena, Hamid Abdullah, Aditya Vashistha, Ruchit Nagar, and Mohit Jain. 2025. Ashabot: An llm-powered chatbot to support the informational needs of community health workers. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1--22
2025
-
[41]
Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 3982--3992
2019
-
[42]
Koustuv Saha, Yoshee Jain, Chunyu Liu, Sidharth Kaliappan, and Ravi Karkar. 2025. Ai vs. humans for online support: Comparing the language of responses from llms and online communities of alzheimer’s disease. ACM Transactions on Computing for Healthcare
2025
-
[43]
Koustuv Saha and Amit Sharma. 2020. Causal factors of effective psychosocial outcomes in online mental health communities. In ICWSM
2020
-
[44]
Leonard Salewski, Stephan Alaniz, Isabel Rio-Torto, Eric Schulz, and Zeynep Akata. 2023. In-context impersonation reveals large language models' strengths and biases. Advances in neural information processing systems, 36:72044--72057
2023
-
[45]
Murray Shanahan, Kyle McDonell, and Laria Reynolds. 2023. Role play with large language models. Nature, 623(7987):493--498
2023
-
[46]
Jiayue Melissa Shi, Keran Wang, Dong Whi Yoo, Ravi Karkar, and Koustuv Saha. 2025 a . Balancing caregiving and self-care: Exploring mental health needs of alzheimer's and dementia caregivers. Proceedings of the ACM on Human-Computer Interaction, 9(7):1--36
2025
-
[47]
Jiayue Melissa Shi, Dong Whi Yoo, Keran Wang, Violeta J Rodriguez, Ravi Karkar, and Koustuv Saha. 2025 b . Mapping caregiver needs to ai chatbot design: Strengths and gaps in mental health support for alzheimer's and dementia caregivers. ACM Transactions on Computing for Healthcare
2025
-
[48]
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adri \`a Garriga-Alonso, and 1 others. 2023. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on machine learning research
2023
-
[49]
Julie A Suhr, Carolyn E Cutrona, Krista K Krebs, and Sandra L Jensen. 2004. The social support behavior code (ssbc). In Couple observational coding systems, pages 307--318. Routledge
2004
-
[50]
Xian Wu, Yutian Zhao, Yunyan Zhang, Jiageng Wu, Zhihong Zhu, Yingying Zhang, Yi Ouyang, Ziheng Zhang, Huimin Wang, Zhenxi Lin, and 1 others. 2024. Medjourney: Benchmark and evaluation of large language models over patient clinical journey. Advances in Neural Information Processing Systems, 37:87621--87646
2024
-
[51]
Wei Xu, Xin Liu, and Yihong Gong. 2003. Document clustering based on non-negative matrix factorization. In Proceedings of the 26th annual international ACM SIGIR conference on Research and development in informaion retrieval, pages 267--273
2003
-
[52]
Dong Whi Yoo, Jiayue Melissa Shi, Violeta J Rodriguez, and Koustuv Saha. 2026. Ai chatbots for mental health self-management: Lived experience--centered qualitative study. JMIR Mental Health, 13:e78288
2026
-
[53]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, and 1 others. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems, 36:46595--46623
2023
-
[54]
Xi Zheng, Zhuoyang Li, Xinning Gui, and Yuhan Luo. 2025. Customizing emotional support: How do individuals construct and interact with llm-powered chatbots. In Proceedings of the 2025 CHI conference on human factors in computing systems, pages 1--20
2025
-
[55]
Jiawei Zhou, Koustuv Saha, Irene Michelle Lopez Carron, Dong Whi Yoo, Catherine R Deeter, Munmun De Choudhury, and Rosa I Arriaga. 2022. Veteran critical theory as a lens to understand veterans' needs and support on social media. Proceedings of the ACM on Human-Computer Interaction, 6(CSCW1):1--28
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.