Beyond Next-Token Prediction: An RLVR Proof of Concept for Tool-Use Agents on Atlassian Workflows
Pith reviewed 2026-07-03 20:15 UTC · model grok-4.3
The pith
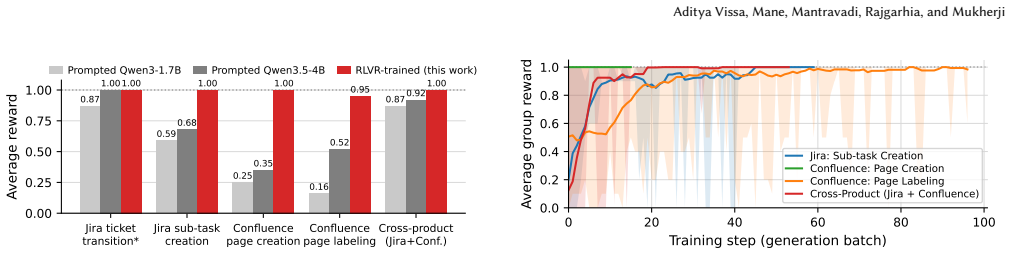
Reinforcement learning with verifiable rewards raises average tool-use reward from 0.35-0.92 to 0.95-1.00 on synthetic enterprise API tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that RLVR applied in synthetic environments emulating the Jira REST v3 and Confluence v2 APIs produces policies whose tool-call traces yield rewards of 0.95-1.00 on four non-degenerate tasks, compared to 0.35-0.92 for the prompted 4B baseline, including a jump from 0.35 to 1.00 on Confluence page creation.
What carries the argument
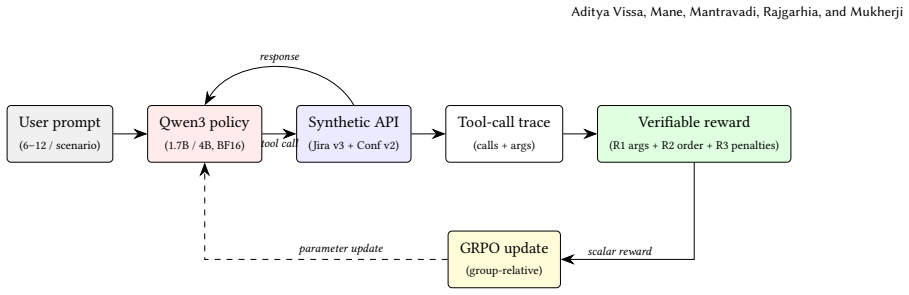
Reinforcement Learning with Verifiable Rewards (RLVR) trained using rewards computed from tool-call traces in schema-faithful synthetic API environments.
If this is right
- RL-trained policies reach near-perfect reward on tasks like Confluence page creation where baselines score 0.35.
- Small models can be outcome-optimised for specific enterprise API sequences using only synthetic traces.
- Verifiable rewards derived from tool calls alone suffice to drive policy improvement without external judges.
- The ticket-transition scenario already saturates at the prompted baseline level.
Where Pith is reading between the lines
- Automating the creation of verifiable rewards could extend this method to a wider range of APIs beyond the five tested here.
- Success on synthetic environments suggests the trained policies might transfer to real Atlassian instances if schema fidelity holds.
- Similar RLVR setups could address tool-use failures in other SaaS platforms with complex nested arguments.
Load-bearing premise
That the synthetic environments match the real APIs closely enough and that rewards from tool-call traces alone produce policies effective on actual workflows.
What would settle it
Deploying the RL-trained policy against live Jira and Confluence APIs and comparing success rates to the synthetic rewards and to human judgments on the same tasks.
Figures
read the original abstract
Large language models are trained to predict the next token, not to act inside a specific API. In niche enterprise SaaS workflows -- where success means hitting the right endpoint with the right nested arguments in the right order -- this objective mismatch shows up as silent failures: dropped required fields, hallucinated tools, or early stops after a single read. We ask whether Reinforcement Learning with Verifiable Rewards (RLVR), applied directly in the target environment, closes the gap. As a proof of concept we build a suite of five synthetic environments emulating the Jira REST v3 and Confluence v2 APIs at schema fidelity; rewards are computed entirely from the tool-call trace, with no live API, no learned judge, and no human label in the loop. Scoring prompted Qwen3-1.7B and Qwen3.5-4B on the same checkers that drive GRPO training, we find that on the four scenarios whose rewards are non-degenerate the RL-trained policy lifts average reward from a 4B-baseline range of 0.35--0.92 to 0.95--1.00, with the largest single gain on Confluence page creation ($0.35 \rightarrow 1.00$). We position this as a preliminary step toward outcome-optimised small models for niche enterprise APIs, and foreground two limitations a workshop reader should weigh: hand-crafting verifiable rewards does not scale beyond the handful of endpoints reported here, and one of our five scenarios (ticket-transition) has a saturating reward shape that the prompted 4B already maxes out.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Reinforcement Learning with Verifiable Rewards (RLVR) via GRPO can train small LLMs (Qwen3-1.7B/4B) to perform tool-use in Atlassian workflows. Using five synthetic environments that emulate Jira REST v3 and Confluence v2 APIs at schema level, with rewards derived solely from tool-call traces, the RL policy raises average reward from a prompted 4B baseline of 0.35--0.92 to 0.95--1.00 on the four non-degenerate scenarios, with the largest gain on Confluence page creation (0.35 to 1.00). The work is positioned as a preliminary proof of concept with two explicit limitations noted.
Significance. If the central empirical result holds, the paper supplies a concrete, reproducible demonstration that verifiable trace-based rewards can optimize tool-calling policies for narrow enterprise API domains without live API access, learned judges, or human labels. This is a strength for falsifiability and reproducibility in the synthetic setting. The significance remains limited by the narrow scope (five hand-crafted scenarios) and the absence of any real-world validation, so the result primarily shows optimization to the synthetic reward functions rather than a general solution for SaaS tool-use agents.
major comments (2)
- [Evaluation / Results] Evaluation / Results section (performance numbers and Table reporting 0.35--0.92 to 0.95--1.00 lifts): the reported gains are obtained exclusively inside the five synthetic schema-emulation environments. No experiments are presented that execute the trained policies against live Jira v3 / Confluence v2 endpoints, inject real error responses, permission checks, or cross-endpoint consistency constraints, or measure downstream task success. This assumption is load-bearing for the claim that RLVR closes the gap for enterprise workflows.
- [Experimental Setup] Experimental Setup section: the manuscript reports performance numbers but supplies no details on the number of independent training runs, variance or standard error across seeds, exact baseline prompting configurations (including temperature, few-shot examples, or system prompts), or any validation that the synthetic environments reproduce live API behavioral fidelity beyond schema matching. These omissions prevent assessment of whether the 0.95--1.00 scores are robust.
minor comments (1)
- [Abstract] Abstract: the fifth scenario (ticket-transition) is described only as saturating; a brief parenthetical on its reward shape or why it was retained would improve clarity without lengthening the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the reproducibility strengths of the synthetic setting. We address the two major comments point-by-point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Evaluation / Results] Evaluation / Results section (performance numbers and Table reporting 0.35--0.92 to 0.95--1.00 lifts): the reported gains are obtained exclusively inside the five synthetic schema-emulation environments. No experiments are presented that execute the trained policies against live Jira v3 / Confluence v2 endpoints, inject real error responses, permission checks, or cross-endpoint consistency constraints, or measure downstream task success. This assumption is load-bearing for the claim that RLVR closes the gap for enterprise workflows.
Authors: We agree that all empirical results are confined to the five synthetic environments; this is a deliberate choice for the proof-of-concept to isolate verifiable trace-based rewards without live API access. The manuscript already states two explicit limitations in the abstract. To prevent any misreading of scope, we will revise the Evaluation/Results section, abstract, and conclusion to more precisely qualify all claims as applying to optimization within the synthetic reward functions and to state that live-endpoint validation is left for future work. We will also add a short paragraph explaining the rationale for schema-level emulation. revision: yes
-
Referee: [Experimental Setup] Experimental Setup section: the manuscript reports performance numbers but supplies no details on the number of independent training runs, variance or standard error across seeds, exact baseline prompting configurations (including temperature, few-shot examples, or system prompts), or any validation that the synthetic environments reproduce live API behavioral fidelity beyond schema matching. These omissions prevent assessment of whether the 0.95--1.00 scores are robust.
Authors: We acknowledge the missing details. In the revised manuscript we will expand the Experimental Setup section to report the number of independent training runs and random seeds, means with standard errors, the precise baseline prompting configuration (system prompt, few-shot examples, temperature), and any schema-fidelity checks performed on the synthetic environments. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper constructs synthetic environments with rewards computed directly from tool-call traces using explicit checkers, then reports empirical reward lifts after GRPO training on those same checkers. This is standard RL reporting of training success on the defined objective and does not reduce any claimed result to a definitional equivalence, a fitted parameter renamed as prediction, or a self-citation chain. No load-bearing self-citations, uniqueness theorems, or smuggled ansatzes appear in the abstract or described setup; the central claim remains an empirical observation inside the hand-crafted synthetic reward functions rather than a tautology.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-scenario reward functions
Reference graph
Works this paper leans on
-
[1]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training Verifiers to Solve Math Word Problems.arXiv preprint arXiv:2110.14168(2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [2]
-
[3]
DeepSeek-AI. 2025. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-World GitHub Issues?. InInternational Conference on Learning Representa- tions (ICLR)
2024
-
[5]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V. Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, et al. 2024. Tülu 3: Pushing Frontiers in Open Language Model Post-Training. arXiv preprint arXiv:2411.15124(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. 2024. AgentBench: Evaluating LLMs as Agents. InInternational Conference on Learning Represe...
2024
-
[7]
Jiarui Lu, Thomas Holleis, Yizhe Zhang, Bernhard Aumayer, Feng Nan, Felix Bai, Shuang Ma, Shen Ma, Mengyu Li, Guoli Yin, Zirui Wang, and Ruoming Pang. 2024. ToolSandbox: A Stateful, Conversational, Interactive Evaluation Benchmark for LLM Tool Use Capabilities.arXiv preprint arXiv:2408.04682(2024)
-
[8]
Cheng Qian, Emre Can Acikgoz, Qi He, Hongru Wang, Xiusi Chen, Dilek Hakkani-Tür, Gokhan Tur, and Heng Ji. 2025. ToolRL: Reward is All Tool Learning Needs.arXiv preprint arXiv:2504.13958(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al . 2024. ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. InInternational Conference on Learning Representations (ICLR)
2024
-
[10]
Qwen Team. 2026. Qwen3.5: Hybrid Mixture-of-Experts and Linear-Attention Foundation Models. https://huggingface.co/collections/Qwen/qwen35
2026
-
[11]
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language Models Can Teach Themselves to Use Tools. InAdvances in Neural Information Processing Systems (NeurIPS)
2023
-
[12]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian
-
[14]
InAnnual Meeting of the Association for Computational Linguistics (ACL)
AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents. InAnnual Meeting of the Association for Computational Linguistics (ACL)
-
[15]
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tris- tan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gal- louédec. 2020. TRL: Transformer Reinforcement Learning. https://github.com/ huggingface/trl
2020
-
[16]
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. 2024. Executable Code Actions Elicit Better LLM Agents. InInternational Conference on Machine Learning (ICML)
2024
-
[17]
An Yang, Baosong Yang, et al. 2025. Qwen3 Technical Report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InInternational Conference on Learning Representations (ICLR)
2023
-
[19]
XYZ-456") get_page(page_id=
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. 2024. WebArena: A Realistic Web Environment for Building Autonomous Agents. InInternational Conference on Learning Representations (ICLR). A Pre- and Post-Training Tool-Call Sequences The listings be...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.