When do complex-valued neural networks help? A study of representation, geometry, and optimization
Pith reviewed 2026-06-29 18:43 UTC · model grok-4.3
The pith
Complex-valued networks help only when signals encode information in phase or magnitude-phase coupling, with RadioML gaps mostly from unequal tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
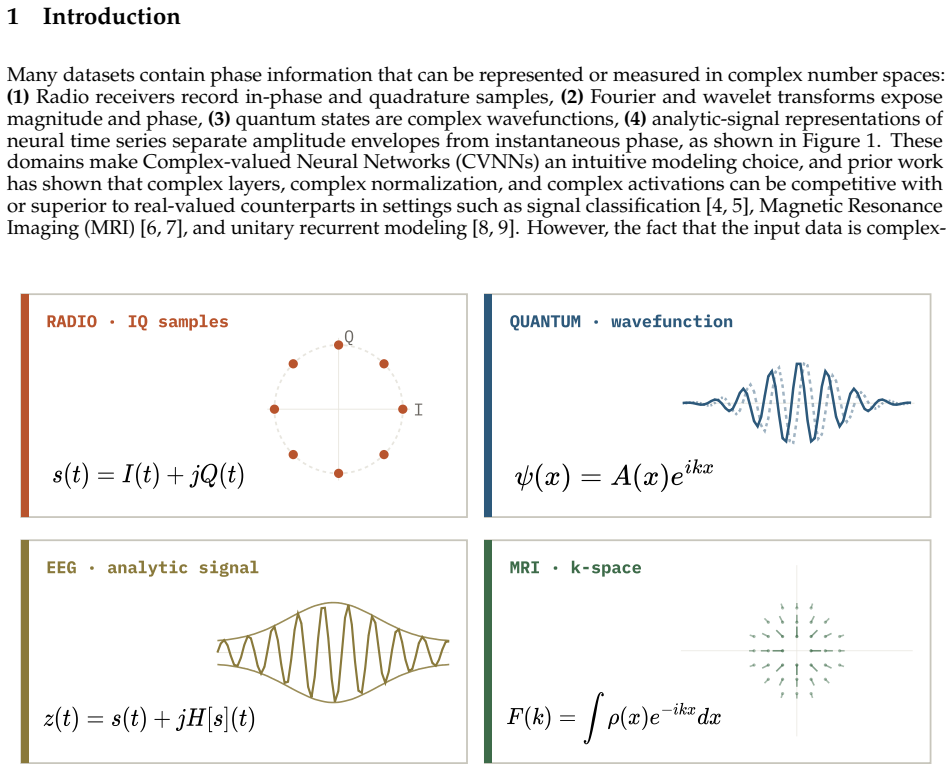
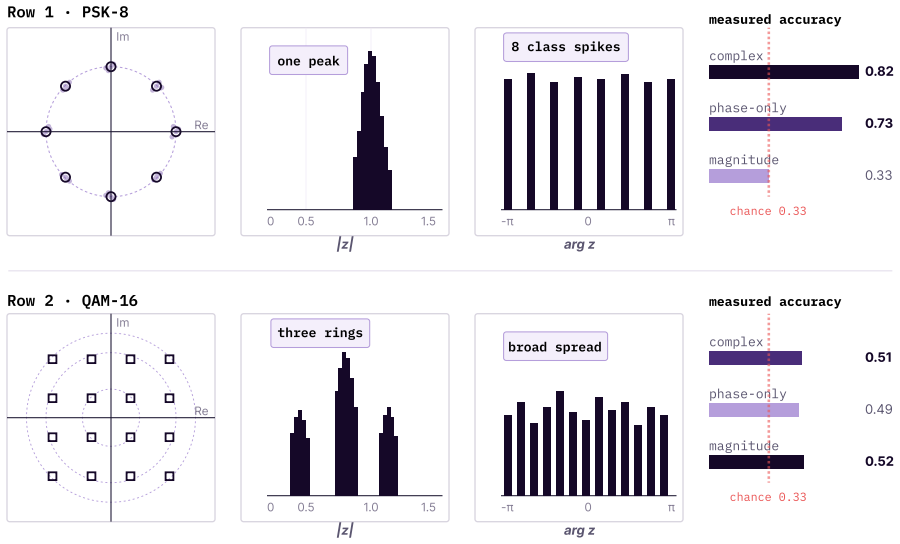
Complex-valued neural networks are structured inductive biases whose effectiveness depends on alignment between data geometry and representation choice. On synthetic RF tasks, PSK-only signals favor phase-aware and complex-valued models, QAM-only signals favor magnitude-based models, mixed PSK+QAM yields only a small complex advantage, and unseen carrier-phase rotations degrade coordinate-dependent models without augmentation. Parallel patterns appear in quantum wavefunction prediction, where phase recovers momentum invisible to magnitude alone, and in EEG analytic signals, where phase locking, amplitude bursts, and phase-amplitude coupling each favor different coordinate views. On RadioML 2
What carries the argument
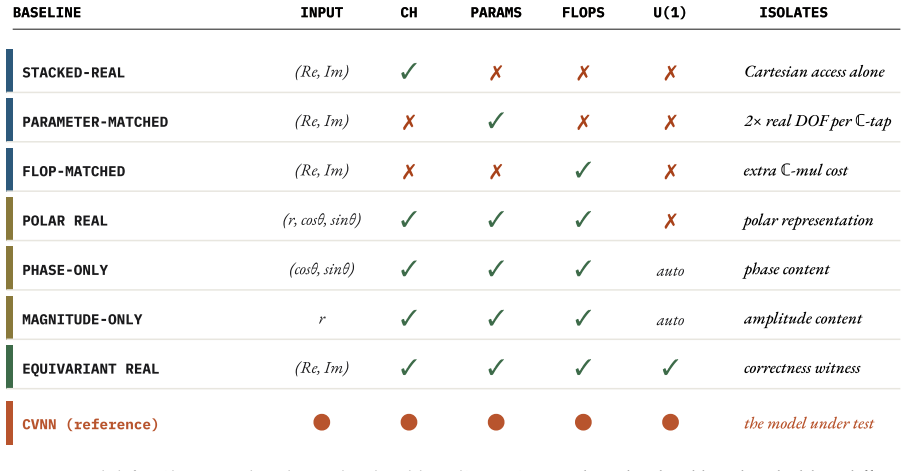
Side-by-side evaluation of Cartesian real, polar, phase-only, magnitude-only, parameter-matched real, and FLOP-matched real baselines, together with gradient analysis of loss-signal distribution through complex parameter coupling.
If this is right
- PSK-only tasks favor phase-aware and complex-valued models over magnitude-only real models.
- QAM-only tasks favor magnitude-based real models over phase-aware or complex ones.
- Mixed PSK+QAM tasks produce only a small complex-valued advantage.
- Unseen carrier-phase rotations break performance of coordinate-dependent models unless the training data includes augmentation.
- The RadioML performance gap is primarily an artifact of unequal hyperparameter sensitivity rather than an inherent representational superiority of complex arithmetic.
Where Pith is reading between the lines
- Practitioners should run equivalent tuning budgets across real and complex families before crediting gains to complex arithmetic.
- The conditional benefit pattern is likely to appear in other phase-sensitive domains such as audio or radar, where magnitude versus phase encoding can be isolated.
- Whether complex coupling confers similar first-step stability under optimizers other than those tested remains open and directly testable.
Load-bearing premise
The 16-trial per-family search space plus the learning-rate times activation factorial is assumed to have sufficiently explored the real baseline optimization landscape.
What would settle it
Finding a broader hyperparameter search or different optimizer that raises real baseline accuracy on RadioML 2018.01A to within roughly 3 percentage points of the complex model would show the reported gap is not primarily hyperparameter-driven.
Figures


read the original abstract
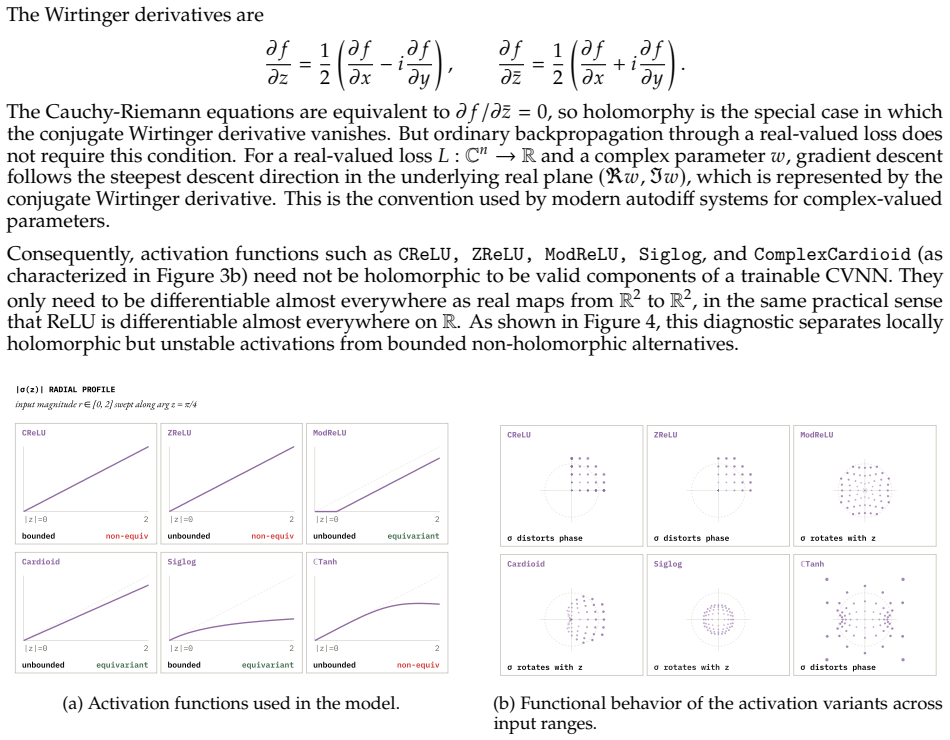
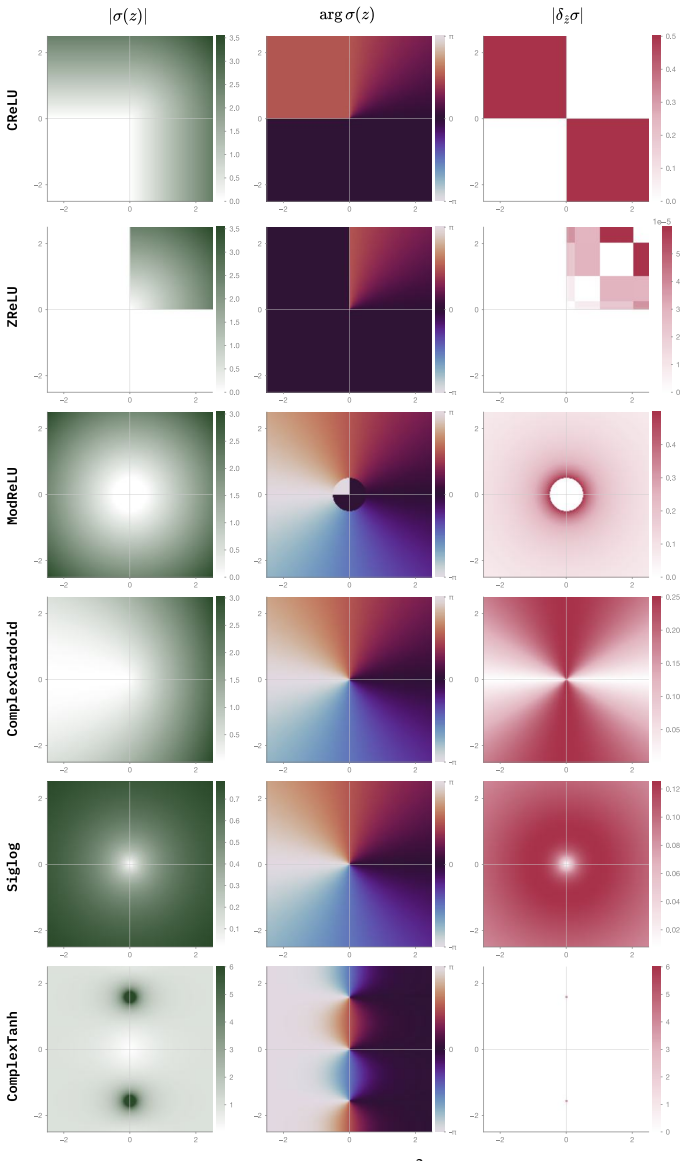
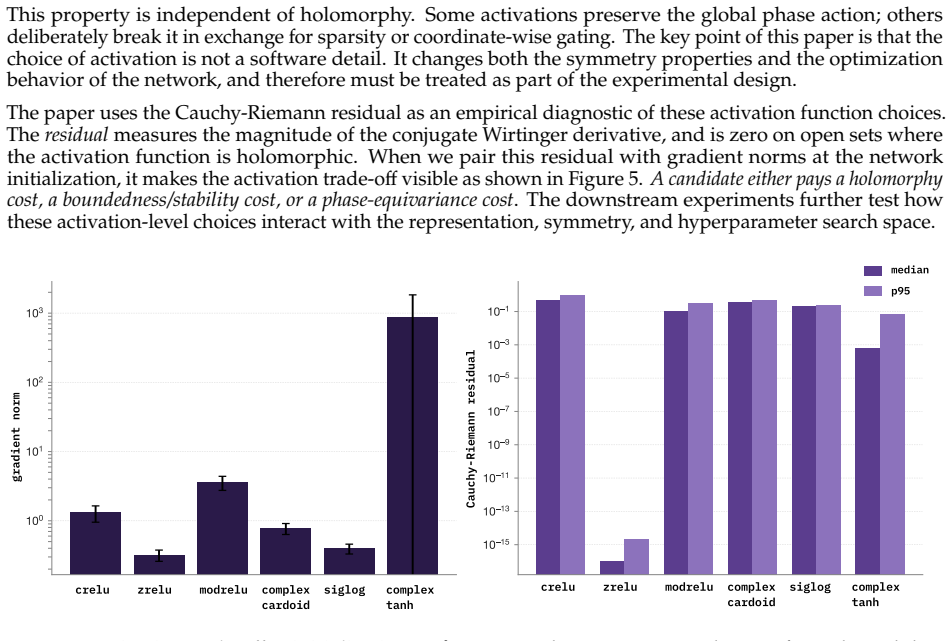
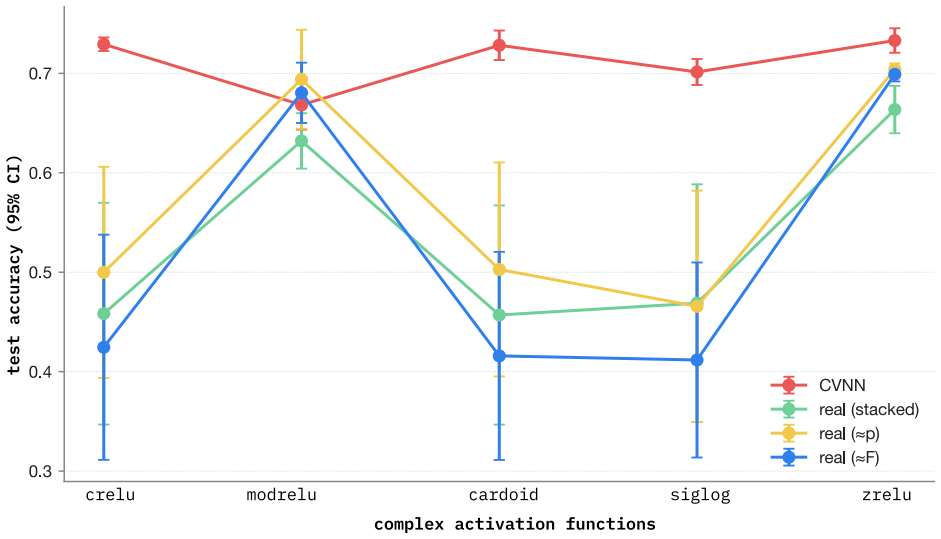
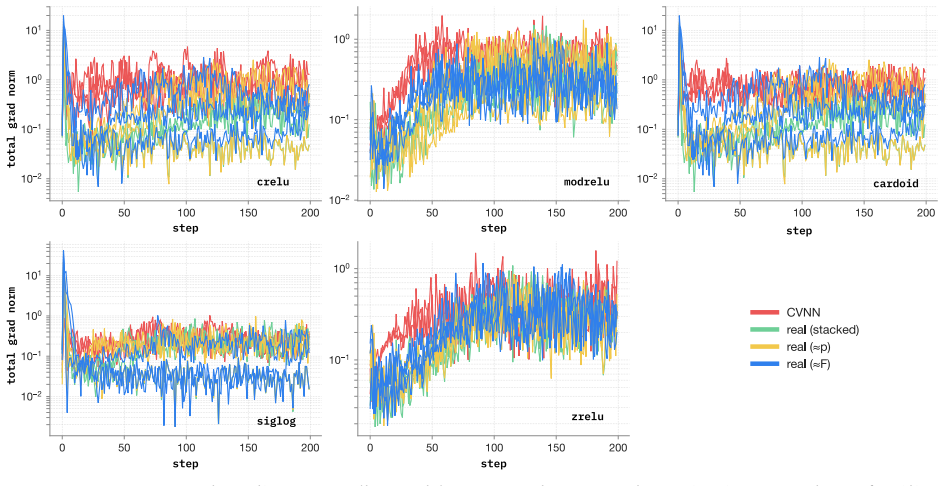
Complex-valued Neural Networks (CVNNs) are often motivated by domains where information is naturally encoded in magnitude and phase. Yet complex-valued inputs alone do not determine when complex arithmetic improves learning: the label signal may lie in amplitude, phase, their coupling, or a symmetry that real-valued models can also represent under suitable coordinates. We study this through a representation-first evaluation of CVNNs against Cartesian real, polar, phase-only, magnitude-only, parameter-matched real, and FLOP-matched real baselines. Across synthetic RF tasks, complex representations are useful but not universally superior. PSK-only tasks favor phase-aware and complex-valued models, QAM-only tasks favor magnitude-based models, mixed PSK+QAM gives only a small complex-valued advantage, and unseen carrier-phase rotations break coordinate-dependent models without augmentation. Similar patterns appear beyond RF: in quantum-wavefunction prediction, momentum is invisible to $|\psi|$ but recoverable from phase, while EEG analytic-signal experiments show that phase locking, amplitude bursts, and phase-amplitude coupling each favor different coordinate views. We also identify a benchmarking artifact on RadioML 2018.01A. Under matched-shared-trial selection, a CReLU complex model exceeds the best real baseline by 22.94 PP; under independent per-family tuning on the same data and 16-trial search space, the gap collapses to 2.46 PP. Gradient analysis traces the inflated gap to high-learning-rate first-step instability in real baselines, while complex parameter coupling distributes the loss signal more robustly. A learning-rate $\times$ activation factorial confirms the failure is primarily hyperparameter-driven. Overall, CVNNs are best viewed as structured inductive biases whose gains depend on representation, symmetry, and optimization, not as universally superior architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that complex-valued neural networks (CVNNs) provide advantages in specific tasks involving phase or magnitude information but are not universally superior to real-valued models. This is demonstrated through representation-first evaluations on synthetic RF tasks (PSK, QAM, mixed), quantum wavefunction prediction, and EEG analytic-signal experiments. On the RadioML 2018.01A benchmark, an apparent 22.94 percentage point advantage for a CReLU complex model under matched-shared-trial selection reduces to 2.46 PP under independent per-family tuning with a 16-trial search space. Gradient analysis and a learning-rate × activation factorial experiment attribute the initial gap to hyperparameter-driven optimization instability in real baselines rather than representational superiority.
Significance. If the results hold, the paper provides a valuable nuanced perspective on CVNN utility, emphasizing inductive biases tied to representation and symmetry rather than blanket superiority. Strengths include the use of multiple matched baselines (Cartesian real, polar, phase-only, magnitude-only, parameter-matched, FLOP-matched), FLOP-matched controls, gradient tracing, and the factorial hyperparameter experiment, which directly support claims about task dependence and benchmarking artifacts. This could guide future work in domains like RF, quantum, and neuroscience signals.
major comments (1)
- [RadioML benchmarking experiment] The attribution of the RadioML gap primarily to hyperparameter effects (reducing from 22.94 PP to 2.46 PP under independent per-family tuning) rests on the 16-trial search space plus LR×activation factorial sufficiently exploring the real-valued loss landscape. If better optima for real baselines exist outside this space (e.g., wider ranges or different optimizers), the residual gap may reflect representational differences rather than tuning failure. This is load-bearing for the benchmarking-artifact conclusion in the RadioML section.
minor comments (2)
- [Abstract] The abstract clearly summarizes the claims but could briefly note the total number of non-RF domains evaluated to emphasize breadth.
- [Methods/Notation] Notation for complex activations (e.g., CReLU) should be defined once in a dedicated subsection and referenced consistently in all experimental descriptions.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the recommendation of minor revision. The single major comment concerns the sufficiency of the hyperparameter search in the RadioML experiment; we respond directly below.
read point-by-point responses
-
Referee: [RadioML benchmarking experiment] The attribution of the RadioML gap primarily to hyperparameter effects (reducing from 22.94 PP to 2.46 PP under independent per-family tuning) rests on the 16-trial search space plus LR×activation factorial sufficiently exploring the real-valued loss landscape. If better optima for real baselines exist outside this space (e.g., wider ranges or different optimizers), the residual gap may reflect representational differences rather than tuning failure. This is load-bearing for the benchmarking-artifact conclusion in the RadioML section.
Authors: We agree that a finite search cannot guarantee that the global optimum for real-valued models has been found, and therefore cannot exclude the possibility that a residual gap after independent tuning reflects representational differences. The 16-trial per-family search and the LR×activation factorial were chosen specifically to target the high-learning-rate first-step instability identified in the gradient analysis; this design isolates a concrete optimization pathology rather than attempting exhaustive coverage. The observed collapse of the gap under these controls supports hyperparameter sensitivity as the dominant factor in the original matched-shared-trial comparison, yet we accept that the experiment does not constitute proof against all possible real-valued configurations. We will revise the RadioML section to state this limitation explicitly and to qualify the benchmarking-artifact claim accordingly. revision: partial
- Exhaustively enumerating all hyperparameter ranges, optimizers, and architectures to prove that no superior real baseline exists is computationally intractable and lies outside the scope of the present study.
Circularity Check
No circularity: purely empirical model comparisons and tuning experiments
full rationale
The paper reports results from representation comparisons, hyperparameter searches (16-trial per-family tuning plus LR×activation factorial), and gradient analysis on synthetic RF, quantum, EEG, and RadioML tasks. No derivations, predictions, or uniqueness theorems are claimed; all performance gaps and attributions are directly measured from data splits and optimization runs. No self-citation chains or fitted inputs renamed as predictions appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gradient-based optimization behaves comparably for real and complex parameterizations under the tested learning-rate ranges.
Reference graph
Works this paper leans on
-
[1]
Charles Clancy
Timothy James O’Shea, Tamoghna Roy, and T. Charles Clancy. Over-the-air deep learning based radio signal classification.IEEE Journal of Selected Topics in Signal Processing, 12(1):168–179, 2018
2018
-
[2]
Understanding and improving convolutional neural networks via concatenated rectified linear units
Wenling Shang, Kihyuk Sohn, Diogo Almeida, and Honglak Lee. Understanding and improving convolutional neural networks via concatenated rectified linear units. Ininternational conference on machine learning, pages 2217–2225. PMLR, 2016
2016
-
[3]
IlyaLoshchilovandFrankHutter.Decoupledweightdecayregularization.arXivpreprintarXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[4]
Springer, 2006
Akira Hirose.Complex-valued neural networks. Springer, 2006
2006
-
[5]
Chiheb Trabelsi, Olexa Bilaniuk, Ying Zhang, Dmitriy Serdyuk, Sandeep Subramanian, Joao Felipe Santos, Soroush Mehri, Negar Rostamzadeh, Yoshua Bengio, and Christopher J Pal. Deep complex networks.arXiv preprint arXiv:1705.09792, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
Better than real: Complex-valued neural nets for mri fingerprinting
Patrick Virtue, X Yu Stella, and Michael Lustig. Better than real: Complex-valued neural nets for mri fingerprinting. In2017 IEEE international conference on image processing (ICIP), pages 3953–3957. IEEE, 2017
2017
-
[7]
Analysis of deep complex-valued convolutionalneuralnetworksformrireconstructionandphase-focusedapplications.Magneticresonance in medicine, 86(2):1093–1109, 2021
Elizabeth Cole, Joseph Cheng, John Pauly, and Shreyas Vasanawala. Analysis of deep complex-valued convolutionalneuralnetworksformrireconstructionandphase-focusedapplications.Magneticresonance in medicine, 86(2):1093–1109, 2021
2021
-
[8]
Unitary evolution recurrent neural networks
Martin Arjovsky, Amar Shah, and Yoshua Bengio. Unitary evolution recurrent neural networks. In International conference on machine learning, pages 1120–1128. PMLR, 2016
2016
-
[9]
Full-capacity unitary recurrent neural networks.Advances in neural information processing systems, 29, 2016
Scott Wisdom, Thomas Powers, John Hershey, Jonathan Le Roux, and Les Atlas. Full-capacity unitary recurrent neural networks.Advances in neural information processing systems, 29, 2016
2016
-
[10]
Group equivariant convolutional networks
Taco Cohen and Max Welling. Group equivariant convolutional networks. InInternational conference on machine learning, pages 2990–2999. PMLR, 2016
2016
-
[11]
Taco S Cohen and Max Welling. Steerable cnns.arXiv preprint arXiv:1612.08498, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[12]
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
Michael M Bronstein, Joan Bruna, Taco Cohen, and Petar Veličković. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges.arXiv preprint arXiv:2104.13478, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Generale(2)-equivariantsteerablecnns.Advancesinneuralinformation processing systems, 32, 2019
MauriceWeilerandGabrieleCesa. Generale(2)-equivariantsteerablecnns.Advancesinneuralinformation processing systems, 32, 2019
2019
-
[14]
Harmonic networks: Deep translation and rotation equivariance
Daniel E Worrall, Stephan J Garbin, Daniyar Turmukhambetov, and Gabriel J Brostow. Harmonic networks: Deep translation and rotation equivariance. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5028–5037, 2017
2017
-
[15]
Springer, 2011
Igor Aizenberg.Complex-valued neural networks with multi-valued neurons, volume 353. Springer, 2011
2011
-
[16]
On Complex Valued Convolutional Neural Networks
Nitzan Guberman. On complex valued convolutional neural networks.arXiv preprint arXiv:1602.09046, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[17]
A complex gradient operator and its application in adaptive array theory
David H Brandwood. A complex gradient operator and its application in adaptive array theory. InIEE Proceedings F (Communications, Radar and Signal Processing), volume 130, pages 11–16. IET, 1983
1983
-
[18]
The Complex Gradient Operator and the CR-Calculus
Ken Kreutz-Delgado. The complex gradient operator and the cr-calculus.arXiv preprint arXiv:0906.4835, 2009
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[19]
Convolutionalradiomodulationrecognition networks
TimothyJO’Shea,JohnathanCorgan,andTCharlesClancy. Convolutionalradiomodulationrecognition networks. InInternational conference on engineering applications of neural networks, pages 213–226. Springer, 2016
2016
-
[20]
Modulation pattern detection using complex convolutions in deep learning
Jakob Krzyston, Rajib Bhattacharjea, and Andrew Stark. Modulation pattern detection using complex convolutions in deep learning. In2020 25th International Conference on Pattern Recognition (ICPR), pages 2233–2239. IEEE, 2021
2021
-
[21]
Complex-valued networks for automatic modulation classification.IEEE Transactions on Vehicular Technology, 69(9):10085–10089, 2020
Ya Tu, Yun Lin, Changbo Hou, and Shiwen Mao. Complex-valued networks for automatic modulation classification.IEEE Transactions on Vehicular Technology, 69(9):10085–10089, 2020
2020
-
[22]
Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations.Journal of Computational physics, 378:686–707, 2019. 24
2019
-
[23]
Deep learning with convolutional neural networks for eeg decoding and visualization.Human brain mapping, 38(11):5391–5420, 2017
RobinTiborSchirrmeister,JostTobiasSpringenberg,LukasDominiqueJosefFiederer,MartinGlasstetter, Katharina Eggensperger, Michael Tangermann, Frank Hutter, Wolfram Burgard, and Tonio Ball. Deep learning with convolutional neural networks for eeg decoding and visualization.Human brain mapping, 38(11):5391–5420, 2017
2017
-
[24]
Eegnet: acompactconvolutionalneuralnetworkforeeg-basedbrain–computerinterfaces
Vernon J Lawhern, Amelia J Solon, Nicholas R Waytowich, Stephen M Gordon, Chou P Hung, and BrentJLance. Eegnet: acompactconvolutionalneuralnetworkforeeg-basedbrain–computerinterfaces. Journal of neural engineering, 15(5):056013, 2018
2018
-
[25]
Measuring phase- amplitude coupling between neuronal oscillations of different frequencies.Journal of neurophysiology, 104(2):1195–1210, 2010
Adriano BL Tort, Robert Komorowski, Howard Eichenbaum, and Nancy Kopell. Measuring phase- amplitude coupling between neuronal oscillations of different frequencies.Journal of neurophysiology, 104(2):1195–1210, 2010
2010
-
[26]
Deep reinforcement learning that matters
Peter Henderson, Riashat Islam, Philip Bachman, Joelle Pineau, Doina Precup, and David Meger. Deep reinforcement learning that matters. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[27]
Are gans created equal? a large-scale study.Advances in neural information processing systems, 31, 2018
Mario Lucic, Karol Kurach, Marcin Michalski, Sylvain Gelly, and Olivier Bousquet. Are gans created equal? a large-scale study.Advances in neural information processing systems, 31, 2018
2018
-
[28]
On the State of the Art of Evaluation in Neural Language Models
Gábor Melis, Chris Dyer, and Phil Blunsom. On the state of the art of evaluation in neural language models.arXiv preprint arXiv:1707.05589, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Accounting for variance in machine learning benchmarks.Proceedings of machine learning and systems, 3:747–769, 2021
Xavier Bouthillier, Pierre Delaunay, Mirko Bronzi, Assya Trofimov, Brennan Nichyporuk, Justin Szeto, Nazanin Mohammadi Sepahvand, Edward Raff, Kanika Madan, Vikram Voleti, et al. Accounting for variance in machine learning benchmarks.Proceedings of machine learning and systems, 3:747–769, 2021. 25
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.