Learning a Maximum Entropy Model for Visual Textures using Diffusion
Pith reviewed 2026-06-27 03:04 UTC · model grok-4.3
The pith
A diffusion-trained maximum entropy model generates high-quality visual textures using only 512 statistics, matching or exceeding models with 177,000 statistics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
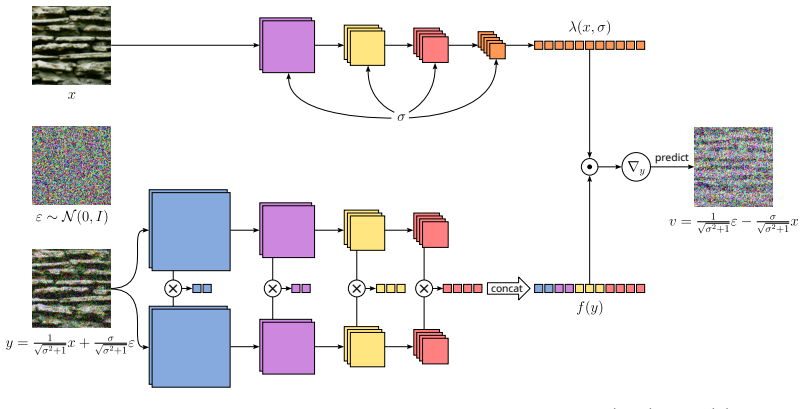
By deriving training and sampling procedures from diffusion models, a set of 512 learned statistics can be used to constrain a maximum entropy model that generates texture samples matching or surpassing the visual quality of models using approximately 177,000 statistics, while also enabling smooth interpolations in representation space.
What carries the argument
Diffusion-derived training and sampling procedures for the maximum entropy distribution defined by the learned statistics.
Load-bearing premise
The diffusion-derived training and sampling procedures correctly optimize and sample from the maximum-entropy distribution without introducing bias.
What would settle it
Generating samples from the model and checking if they match the target statistics within expected variance, or if their visual quality falls below the compared model in blind tests.
Figures










read the original abstract
Visual textures -- spatially homogeneous image regions containing repeated elements (e.g. a field of grass, the bark of a tree) -- are ubiquitous in visual scenes and provide important cues for recognizing and analyzing materials and objects. A number of existing texture models extract essential statistics from a single texture image, and can then generate high-quality samples that are visually similar to the original by matching these statistics. However, their statistics are either hand-designed or based on a network pretrained for another purpose (e.g., object recognition). Here, we develop the first principled method for unsupervised learning of a set of statistics that are used to constrain a maximum entropy probability model. We leverage methods developed for generative diffusion models to derive training and sampling procedures, and compare these to the traditional method of sampling via matching the statistics. Despite the compactness of our trained model (512 statistics), it generates texture images whose quality is as good as or better than the current state-of-the-art model (~177k statistics). A more direct comparison of the two models, obtained by synthesizing images that are indistinguishable for one model but maximally different for the other, reveals their relative strengths and weaknesses. Finally, we show that unlike previous statistical texture models, a straight trajectory in the representation space of our model generates homogeneous texture samples that interpolate smoothly between the features of the two end points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce the first principled unsupervised method for learning a compact set of 512 statistics that define a maximum-entropy model for visual textures, deriving training and sampling procedures from diffusion models. It reports that samples from this model achieve visual quality equal or superior to the prior state-of-the-art (~177k statistics), provides a direct comparison via images that are indistinguishable under one model but maximally different under the other, and demonstrates smooth interpolation along straight trajectories in the learned representation space.
Significance. If the diffusion-derived procedures are shown to correctly optimize and sample from the intended maxent distribution, the work would be significant for texture synthesis: it supplies a data-driven, compact alternative to hand-crafted or pretrained-network statistics while retaining the theoretical advantages of maximum-entropy modeling. The direct cross-model comparison and the interpolation result are concrete strengths that would remain valuable even if the maxent equivalence requires further verification.
major comments (2)
- [Method (diffusion adaptation for training/sampling)] The central claim that the adapted diffusion training and sampling procedures enforce the exact maximum-entropy distribution p(x) ∝ exp(∑ λ_i f_i(x)) with the learned 512 statistics rests on an unverified equivalence between the diffusion objective and classical maxent fitting. No moment-matching error on held-out statistics, entropy comparison against traditional sampling, or other diagnostic is reported that would confirm the stationary distribution matches the intended model rather than a diffusion-biased approximation.
- [Experiments / Results] The headline performance comparison (512-statistic model vs. ~177k-statistic SOTA) is load-bearing for the compactness claim, yet the manuscript provides no quantitative metrics (e.g., perceptual distances, texture classification accuracy on generated samples, or statistical fidelity scores) that would allow independent verification of the “as good as or better” assertion beyond visual inspection.
minor comments (2)
- [Method] Notation for the learned statistics f_i(x) and the Lagrange multipliers λ_i is introduced without an explicit equation linking them to the partition function or the score function used in diffusion training.
- [Experiments] The description of the “straight trajectory in the representation space” for interpolation would benefit from a precise definition of the representation (e.g., the vector of 512 statistics or an intermediate latent) and a quantitative measure of homogeneity along the path.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment below and propose revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method (diffusion adaptation for training/sampling)] The central claim that the adapted diffusion training and sampling procedures enforce the exact maximum-entropy distribution p(x) ∝ exp(∑ λ_i f_i(x)) with the learned 512 statistics rests on an unverified equivalence between the diffusion objective and classical maxent fitting. No moment-matching error on held-out statistics, entropy comparison against traditional sampling, or other diagnostic is reported that would confirm the stationary distribution matches the intended model rather than a diffusion-biased approximation.
Authors: Section 3 derives the training and sampling procedures by adapting the diffusion objective to enforce the moment constraints of the maximum-entropy model, establishing the theoretical equivalence. We acknowledge that empirical diagnostics would further confirm the stationary distribution. In revision we will report moment-matching errors on held-out statistics and entropy comparisons against traditional sampling. revision: yes
-
Referee: [Experiments / Results] The headline performance comparison (512-statistic model vs. ~177k-statistic SOTA) is load-bearing for the compactness claim, yet the manuscript provides no quantitative metrics (e.g., perceptual distances, texture classification accuracy on generated samples, or statistical fidelity scores) that would allow independent verification of the “as good as or better” assertion beyond visual inspection.
Authors: Visual comparison is standard in texture synthesis, yet we agree quantitative metrics would enable independent verification. In the revision we will add LPIPS perceptual distances and texture classification accuracy on generated samples using a pretrained classifier. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe leveraging established diffusion model methods to derive training/sampling procedures for a maximum-entropy texture model constrained by 512 learned statistics. No equations, self-citations, or derivation steps are visible that reduce the maxent claim or performance results to inputs by construction (e.g., no fitted parameters renamed as predictions, no self-definitional statistics, no load-bearing self-citation chains). The central claim of competitive quality with compact statistics is presented as an empirical outcome independent of the derivation method itself. This is the expected honest non-finding when no explicit reduction can be quoted.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion training and sampling procedures correctly optimize and sample the maximum-entropy distribution defined by the learned statistics.
Reference graph
Works this paper leans on
-
[1]
IRE transactions on Information Theory , volume=
Visual pattern discrimination , author=. IRE transactions on Information Theory , volume=. 1962 , publisher=
1962
-
[2]
Advances in neural information processing systems , volume=
Generative modeling by estimating gradients of the data distribution , author=. Advances in neural information processing systems , volume=
-
[3]
Annual review of vision science , volume=
Textures as probes of visual processing , author=. Annual review of vision science , volume=. 2017 , publisher=
2017
-
[4]
Stochastic solutions for linear inverse problems using the prior implicit in a denoiser , author=. NeurIPS
-
[5]
Diffusion Posterior Sampling for General Noisy Inverse Problems , author=
-
[6]
2024 , journal=
A Survey on Diffusion Models for Inverse Problems , author=. 2024 , journal=
2024
-
[7]
, author=
Estimation of non-normalized statistical models by score matching. , author=. Journal of Machine Learning Research , volume=
-
[8]
An empirical
Robbins, Herbert E , booktitle=. An empirical. 1956 , publisher=
1956
-
[9]
Neural Comp
Least squares estimation without priors or supervision , author=. Neural Comp. , volume=. 2011 , publisher=
2011
-
[10]
Denoising diffusion restoration models , author=
-
[11]
Nature neuroscience , volume=
A functional and perceptual signature of the second visual area in primates , author=. Nature neuroscience , volume=. 2013 , publisher=
2013
-
[12]
International journal of computer vision , volume=
A parametric texture model based on joint statistics of complex wavelet coefficients , author=. International journal of computer vision , volume=. 2000 , publisher=
2000
-
[13]
Advances in neural information processing systems , volume=
Texture synthesis using convolutional neural networks , author=. Advances in neural information processing systems , volume=
-
[14]
IEEE transactions on pattern analysis and machine intelligence , volume=
Image quality assessment: Unifying structure and texture similarity , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2020 , publisher=
2020
-
[15]
SIAM Journal on Mathematics of Data Science , volume=
Maximum entropy methods for texture synthesis: theory and practice , author=. SIAM Journal on Mathematics of Data Science , volume=. 2021 , publisher=
2021
-
[16]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Image style transfer using convolutional neural networks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[17]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Soda: Bottleneck diffusion models for representation learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[18]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[19]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Hierarchical text-conditional image generation with clip latents , author=. arXiv preprint arXiv:2204.06125 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[21]
International conference on machine learning , pages=
Diffusion based representation learning , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Diffusion autoencoders: Toward a meaningful and decodable representation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[23]
International Conference on Machine Learning , pages=
Infodiffusion: Representation learning using information maximizing diffusion models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[24]
International conference on learning representations , year=
ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness , author=. International conference on learning representations , year=
-
[25]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
A convnet for the 2020s , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[26]
An empirical Bayes estimator of the mean of a normal population , author=. Bull. Inst. Internat. Statist , volume=
-
[27]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[28]
, author=
The steerable pyramid: a flexible architecture for multi-scale derivative computation. , author=. ICIP (3) , pages=
-
[29]
International Conference on Medical image computing and computer-assisted intervention , pages=
U-net: Convolutional networks for biomedical image segmentation , author=. International Conference on Medical image computing and computer-assisted intervention , pages=. 2015 , organization=
2015
-
[30]
Proceedings of the AAAI conference on artificial intelligence , volume=
Film: Visual reasoning with a general conditioning layer , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[31]
Advances in Neural Information Processing Systems , volume=
Lossy image compression with conditional diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
International Journal of Computer Vision , volume=
Filters, random fields and maximum entropy (FRAME): Towards a unified theory for texture modeling , author=. International Journal of Computer Vision , volume=. 1998 , publisher=
1998
-
[33]
Proceedings of the 22nd annual conference on Computer graphics and interactive techniques , pages=
Pyramid-based texture analysis/synthesis , author=. Proceedings of the 22nd annual conference on Computer graphics and interactive techniques , pages=
-
[34]
Advances in neural information processing systems , volume=
A non-parametric multi-scale statistical model for natural images , author=. Advances in neural information processing systems , volume=
-
[35]
Proceedings of the 28th annual conference on Computer graphics and interactive techniques , pages=
Image quilting for texture synthesis and transfer , author=. Proceedings of the 28th annual conference on Computer graphics and interactive techniques , pages=
-
[36]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Diffusion models and representation learning: A survey , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[37]
Advances in neural information processing systems , volume=
Gans trained by a two time-scale update rule converge to a local nash equilibrium , author=. Advances in neural information processing systems , volume=
-
[38]
Progressive Distillation for Fast Sampling of Diffusion Models
Progressive distillation for fast sampling of diffusion models , author=. arXiv preprint arXiv:2202.00512 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
Advances in neural information processing systems , volume=
Elucidating the design space of diffusion-based generative models , author=. Advances in neural information processing systems , volume=
-
[40]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Proceedings of the 29th ACM international conference on architectural support for programming languages and operating systems, volume 2 , pages=
Pytorch 2: Faster machine learning through dynamic python bytecode transformation and graph compilation , author=. Proceedings of the 29th ACM international conference on architectural support for programming languages and operating systems, volume 2 , pages=
-
[42]
arXiv preprint arXiv:2203.06026 , year=
The role of imagenet classes in fr\'echet inception distance , author=. arXiv preprint arXiv:2203.06026 , year=
-
[43]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Very deep convolutional networks for large-scale image recognition , author=. arXiv preprint arXiv:1409.1556 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Journal of vision , volume=
Maximum differentiation (MAD) competition: A methodology for comparing computational models of perceptual quantities , author=. Journal of vision , volume=. 2008 , publisher=
2008
-
[45]
Stat 5421 Lecture Notes: Exponential Families , author=
-
[46]
Proceedings of the National Academy of Sciences , volume=
Texture-like representation of objects in human visual cortex , author=. Proceedings of the National Academy of Sciences , volume=. 2022 , publisher=
2022
-
[47]
BioRxiv , pages=
Responses of neurons in macaque V4 to object and texture images , author=. BioRxiv , pages=
-
[48]
Physical review , volume=
Information theory and statistical mechanics , author=. Physical review , volume=. 1957 , publisher=
1957
-
[49]
The Annals of probability , pages=
A new look at independence , author=. The Annals of probability , pages=. 1996 , publisher=
1996
-
[50]
Neuron , volume=
Sound texture perception via statistics of the auditory periphery: evidence from sound synthesis , author=. Neuron , volume=. 2011 , publisher=
2011
-
[51]
IEEE transactions on pattern analysis and machine intelligence , volume=
Learning energy-based spatial-temporal generative convnets for dynamic patterns , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2019 , publisher=
2019
-
[52]
Nature , volume=
Weak pairwise correlations imply strongly correlated network states in a neural population , author=. Nature , volume=. 2006 , publisher=
2006
-
[53]
Elife , volume=
Homeostatic synaptic normalization optimizes learning in network models of neural population codes , author=. Elife , volume=. 2024 , publisher=
2024
-
[54]
Proceedings of the AAAI conference on artificial intelligence , volume=
Learning FRAME models using CNN filters , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[55]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Describing textures in the wild , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[56]
Demystifying mmd gans , author=. arXiv preprint arXiv:1801.01401 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Advances in neural information processing systems , volume=
Improved precision and recall metric for assessing generative models , author=. Advances in neural information processing systems , volume=
-
[58]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Rethinking fid: Towards a better evaluation metric for image generation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[59]
Journal of the Optical Society of America A , volume=
Local image statistics: maximum-entropy constructions and perceptual salience , author=. Journal of the Optical Society of America A , volume=. 2012 , publisher=
2012
-
[60]
Elife , volume=
Visual processing of informative multipoint correlations arises primarily in V2 , author=. Elife , volume=. 2015 , publisher=
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.