Empirical Evaluation of Large Language Models for Migration of Code Fragments to Post-Quantum Cryptography
Pith reviewed 2026-06-27 21:51 UTC · model grok-4.3
The pith
Fine-tuned GPT-4.1-mini migrates pre-quantum cryptographic code to post-quantum versions at 92.5 percent functional correctness.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
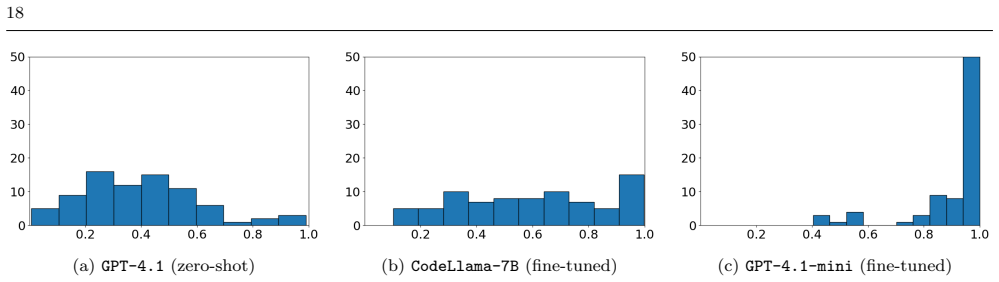
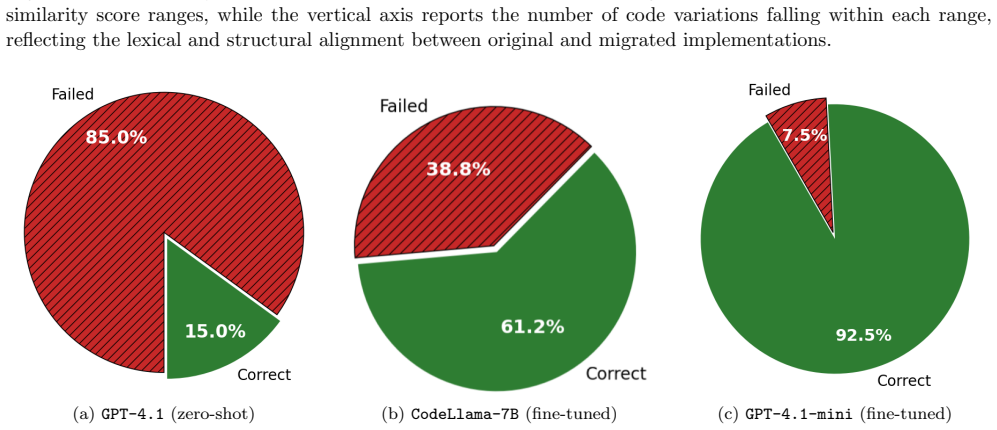
Domain-specific fine-tuning of large language models enables reliable migration of pre-quantum cryptographic code fragments to post-quantum counterparts. On a synthetic dataset of 800 validated pairs the fine-tuned GPT-4.1-mini reached a mean static similarity of 0.9072 and 92.5 percent dynamic functional correctness, substantially outperforming zero-shot GPT-4.1. The same model generated useful migrations in localized modules of real repositories while revealing difficulties with complex cross-module dependencies.
What carries the argument
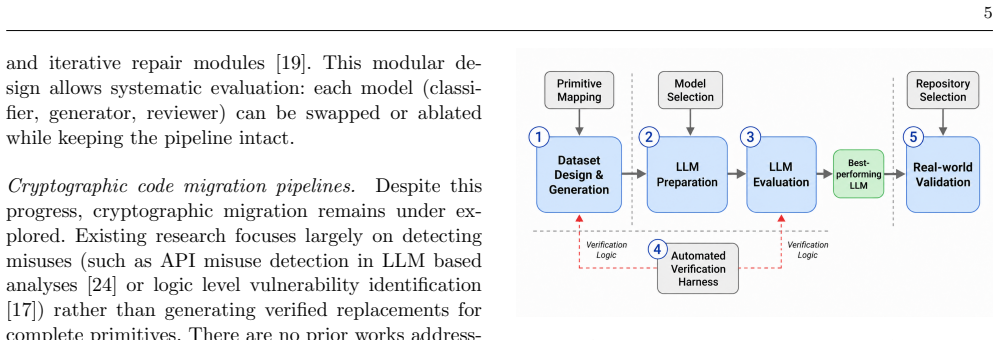
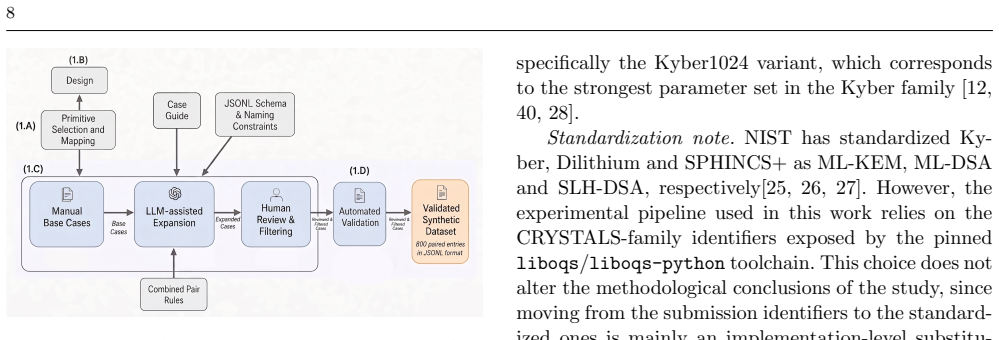
A reproducible experimental framework centered on a synthetic dataset of 800 paired Python code fragments, each validated by category-specific functional tests, that measures both static code similarity and dynamic functional correctness of model outputs.
If this is right
- Domain-specific fine-tuning is essential for reliable cryptographic migration performance.
- Fine-tuned LLMs can serve as practical components inside crypto-agile migration pipelines when paired with automated verification.
- The method produces useful migrations inside localized cryptographic modules of open-source projects.
- Larger projects with complex dependencies and cross-module interactions remain challenging for the current approach.
Where Pith is reading between the lines
- Extending the dataset to additional languages such as C or Java would test whether the same fine-tuning gains appear outside Python.
- Combining the LLM migration step with static dependency-graph analysis could reduce failures on multi-module codebases.
- Measuring how often the generated post-quantum code passes the same test suite used for the original fragments on a broader set of libraries would give a clearer picture of generalization.
Load-bearing premise
The synthetic dataset of 800 paired code fragments, validated only through category-specific functional tests, sufficiently represents the structure, dependencies, and edge cases found in real-world cryptographic modules.
What would settle it
Running the fine-tuned GPT-4.1-mini on a large real-world cryptographic library and measuring whether dynamic functional correctness falls below 80 percent on modules with cross-file dependencies would test the central performance claim.
Figures


read the original abstract
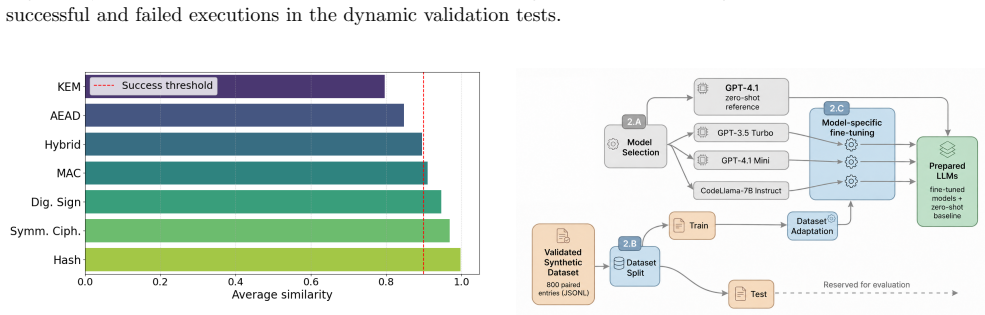
The transition to post-quantum cryptography (PQC) requires not only replacing vulnerable cryptographic primitives, but also refactoring the surrounding software logic. While existing PQC migration frameworks provide organizational guidance, practical code-level remediation remains largely manual and error-prone. This paper evaluates whether large language models (LLMs) can be trained to assist in the migration of pre-quantum cryptographic code fragments to post-quantum counterparts while preserving functional correctness. To this end, we introduce a reproducible experimental framework built around a synthetic dataset of 800 paired Python code fragments covering six cryptographic families and combined multi-primitive cases. Each pair is validated through category-specific functional tests, enabling both dataset quality control and objective evaluation of model-generated migrations. Four models are assessed: GPT-4.1 in a zero-shot setting, and fine-tuned versions of GPT-3.5-turbo, GPT-4.1-mini, and CodeLlama-7B-Instruct. The results show that domain-specific fine-tuning is essential for reliable cryptographic migration. The fine-tuned GPT-4.1-mini model achieves the best overall performance, with a mean static similarity of 0.9072 and a dynamic functional correctness rate of 92.5%, substantially outperforming the zero-shot baseline. A complementary validation on six open-source repositories further shows that the approach can produce useful migrations in localized cryptographic modules, while also revealing limitations in larger projects with complex dependencies and cross-module interactions. These findings suggest that fine-tuned LLMs can serve as practical components in future crypto-agile migration pipelines, provided they are coupled with automated verification and dependency-aware validation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
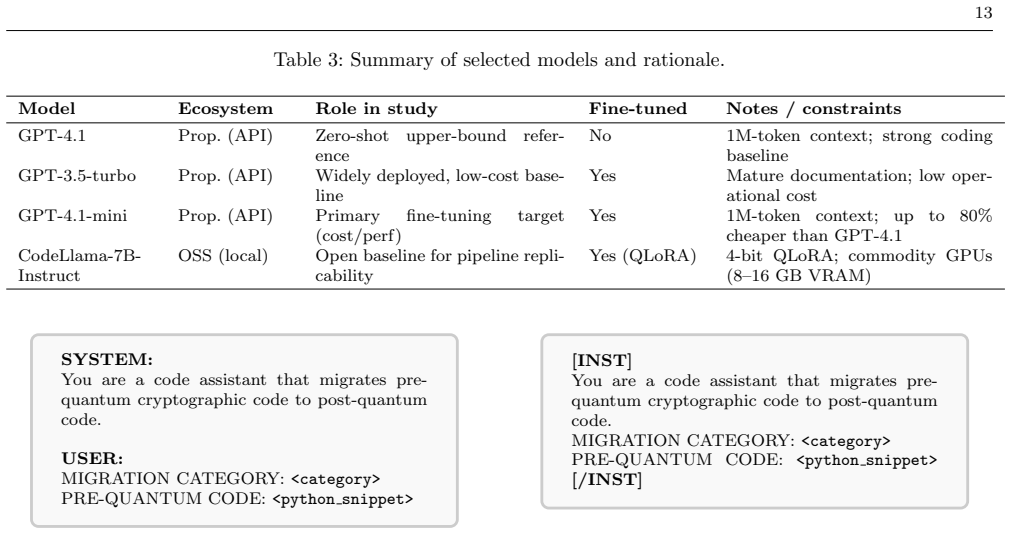
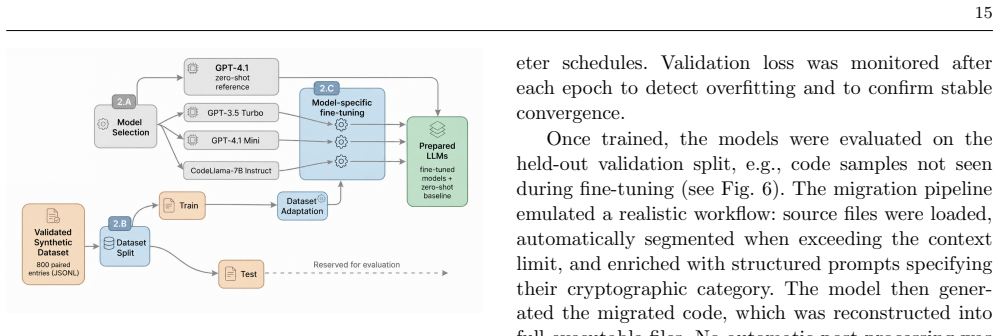
Summary. The paper introduces a reproducible experimental framework and a synthetic dataset of 800 paired Python code fragments covering six cryptographic families plus multi-primitive cases. It evaluates zero-shot GPT-4.1 against fine-tuned GPT-3.5-turbo, GPT-4.1-mini, and CodeLlama-7B-Instruct on migrating pre-quantum cryptographic fragments to post-quantum counterparts, reporting that the fine-tuned GPT-4.1-mini achieves the highest mean static similarity (0.9072) and dynamic functional correctness (92.5%). A secondary check on six open-source repositories shows localized utility but degraded results on complex dependency structures.
Significance. If the central empirical claims hold, the work demonstrates that domain-specific fine-tuning enables LLMs to produce functionally correct PQC migrations at the fragment level and supplies a reusable test harness with both static similarity and dynamic execution metrics. The explicit real-repository validation and the paper's own acknowledgment of cross-module limitations are positive features that strengthen the contribution relative to purely synthetic studies.
major comments (2)
- [Dataset section] Dataset section (synthetic 800-pair construction): the headline static similarity of 0.9072 and dynamic correctness of 92.5% rest on category-specific functional tests whose coverage of call-pattern changes, exception handling, and multi-primitive interactions is not independently quantified; the paper itself reports degraded performance on real repositories with cross-module dependencies, indicating that the synthetic regime may systematically understate task difficulty.
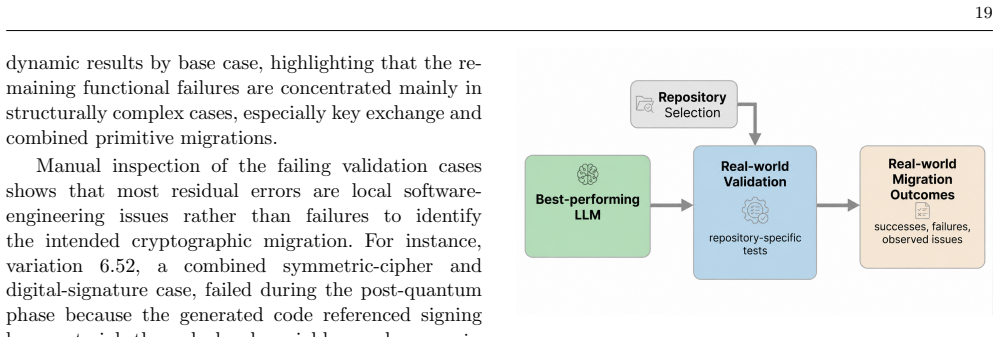
- [Real-repository validation paragraph] Real-repository validation paragraph: the claim that the approach 'can produce useful migrations in localized cryptographic modules' is supported only by qualitative description; without quantitative static/dynamic scores comparable to the synthetic 0.9072/92.5% figures, it is impossible to calibrate how far the primary results generalize to production cryptographic code.
minor comments (2)
- [Abstract] Abstract and model list: 'GPT-4.1' is used for the zero-shot baseline while 'GPT-4.1-mini' appears in the fine-tuned results; consistent naming and explicit parameter counts or API versions would improve clarity.
- [Evaluation metrics paragraph] Evaluation metrics paragraph: the precise definition of 'static similarity' (e.g., which token or AST metric) is referenced only at a high level; adding the exact formula or library call would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the scope and limitations of our empirical evaluation. We address each major comment below, indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Dataset section] Dataset section (synthetic 800-pair construction): the headline static similarity of 0.9072 and dynamic correctness of 92.5% rest on category-specific functional tests whose coverage of call-pattern changes, exception handling, and multi-primitive interactions is not independently quantified; the paper itself reports degraded performance on real repositories with cross-module dependencies, indicating that the synthetic regime may systematically understate task difficulty.
Authors: We agree that independent quantification of test coverage (e.g., via statement or branch coverage) would improve transparency. The category-specific tests were constructed to exercise the primary functional requirements of each primitive family and multi-primitive combinations, including representative call patterns and exception paths. We did not compute aggregate coverage metrics across the 800 pairs. The manuscript already notes performance degradation on real repositories as a limitation of the synthetic regime. In revision we will expand the Dataset section with a more explicit description of the test cases and add a dedicated paragraph discussing how the synthetic setting may understate cross-module complexity. revision: partial
-
Referee: [Real-repository validation paragraph] Real-repository validation paragraph: the claim that the approach 'can produce useful migrations in localized cryptographic modules' is supported only by qualitative description; without quantitative static/dynamic scores comparable to the synthetic 0.9072/92.5% figures, it is impossible to calibrate how far the primary results generalize to production cryptographic code.
Authors: We accept that the real-repository check is qualitative and cannot be directly calibrated against the synthetic metrics. This component was included to illustrate localized applicability rather than to provide a quantitative generalization study; constructing executable test harnesses and resolving full dependency graphs for the six repositories would have required substantial additional engineering outside the paper's scope. We will revise the paragraph to explicitly characterize the validation as qualitative, remove any implication of direct comparability, and reinforce the already-stated limitations regarding complex dependencies. revision: yes
Circularity Check
No circularity: purely empirical measurement on synthetic dataset
full rationale
The paper reports experimental results from fine-tuning and evaluating LLMs on a fixed synthetic dataset of 800 code pairs, using static similarity and dynamic functional tests as direct metrics. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains are present; performance numbers (0.9072 similarity, 92.5% correctness) are measured outputs, not reductions of prior fitted quantities. The study is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Category-specific functional tests are sufficient to determine whether a migrated code fragment preserves functional correctness.
Reference graph
Works this paper leans on
-
[1]
A survey of post-quantum cryptog- raphy support in cryptographic libraries
Nadeem Ahmed, Lei Zhang, and Aryya Gan- gopadhyay. “A survey of post-quantum cryptog- raphy support in cryptographic libraries”. In: arXiv preprint arXiv:2508.16078(2025)
arXiv 2025
-
[2]
NIST Interagency/Internal Report (NISTIR) 8528
Gorjan Alagic et al.Status Report on the First Round of the Additional Digital Sig- nature Schemes for the NIST Post-Quantum Cryptography Standardization Process. NIST Interagency/Internal Report (NISTIR) 8528. Gaithersburg, MD, USA: National Institute of Standards and Technology, Oct. 2024.doi: 10 . 6028 / NIST . IR . 8528.url:https : / / doi . org/10.60...
-
[3]
NIST Cybersecurity White Paper NIST CSWP
Elaine Barker et al.Considerations for Achieving Cryptographic Agility: Strategies and Practices. NIST Cybersecurity White Paper NIST CSWP
-
[4]
National Institute of Standards and Technol- ogy, Dec. 2025.doi:10 . 6028 / NIST . CSWP . 39. url:https://doi.org/10.6028/NIST.CSWP. 39
-
[5]
Ward Beullens et al.Post-Quantum Cryptog- raphy: Current State and Quantum Mitigation (v2). Tech. rep. European Union Agency for Cybersecurity (ENISA), 2021.doi:10 . 2824 / 92307.url:https : / / www . enisa . europa . eu / sites / default / files / publications / ENISA % 20Report % 20 - %20Post - Quantum % 20Cryptography % 20Current % 20state % 20and % 20...
2021
-
[6]
Cybersecurity and Infrastructure Security Agency (CISA).Strategy for Migrating to Au- tomated Post-Quantum Cryptography Discov- ery and Inventory Tools. Tech. rep. Accedido el 23 de mayo de 2025. U.S. Department of Homeland Security, Sept. 2024.url:https : //www.cisa.gov/sites/default/files/2024- 09/Strategy- for- Migrating- to- Automated- PQC-Discovery-a...
2025
-
[7]
Qlora: Efficient finetuning of quantized llms
Tim Dettmers et al. “Qlora: Efficient finetuning of quantized llms”. In:Advances in neural infor- mation processing systems36 (2023), pp. 10088– 10115
2023
-
[8]
Nos CorpusNOS-GL: Galician Macrocorpus for LLM training
Iria de-Dios-Flores et al. “Nos CorpusNOS-GL: Galician Macrocorpus for LLM training”. In: Nos CorpusNOS-GL: Galician Macrocorpus for LLM training(2024)
2024
-
[9]
SHA-3 standard: Permutation-based hash and extendable-output functions
Morris J Dworkin et al. “SHA-3 standard: Permutation-based hash and extendable-output functions”. In: (2015)
2015
-
[10]
European Commission and NIS Cooperation Group.Coordinated Implementation Roadmap for the Transition to Post-Quantum Cryptog- raphy.https : / / digital - strategy . ec . europa . eu / en / library / coordinated - implementation - roadmap - transition - post - quantum-cryptography. European Union policy roadmap on coordinated migration to post- quantum cryp...
2025
-
[11]
Why Do Large Language Mod- els (LLMs) Struggle to Count Letters?
Tairan Fu et al. “Why Do Large Language Mod- els (LLMs) Struggle to Count Letters?” In:arXiv preprint arXiv:2412.18626(2024)
arXiv 2024
-
[12]
Response accuracy of GPT- 4 across languages: insights from an expert-level diagnostic radiology examination in Japan
Ayaka Harigai et al. “Response accuracy of GPT- 4 across languages: insights from an expert-level diagnostic radiology examination in Japan”. In:Japanese Journal of Radiology43.2 (2025), pp. 319–329
2025
-
[13]
A framework for migrating to post-quantum cryptography: Secu- rity dependency analysis and case studies
Khondokar Fida Hasan et al. “A framework for migrating to post-quantum cryptography: Secu- rity dependency analysis and case studies”. In: IEEE Access12 (2024), pp. 23427–23450
2024
-
[14]
A Survey on Large Language Models for Code Generation
Juyong Jiang et al. “A Survey on Large Language Models for Code Generation”. In:ACM Transac- tions on Software Engineering and Methodology 35.2 (Jan. 2026), pp. 1–72.issn: 1557-7392.doi: 10.1145/3747588.url:http://dx.doi.org/ 10.1145/3747588
-
[15]
Breaking symmetric cryp- tosystems using quantum period finding
Marc Kaplan et al. “Breaking symmetric cryp- tosystems using quantum period finding”. In:Ad- vances in Cryptology–CRYPTO 2016: 36th An- nual International Cryptology Conference, Santa Barbara, CA, USA, August 14-18, 2016, Proceed- ings, Part II 36. Springer. 2016, pp. 207–237
2016
-
[16]
Unsupervised trans- lation of programming languages
Marie-Anne Lachaux et al. “Unsupervised trans- lation of programming languages”. In:arXiv preprint arXiv:2006.03511(2020)
arXiv 2006
-
[17]
On the post- quantum security of classical authenticated en- cryption schemes
Nathalie Lang and Stefan Lucks. “On the post- quantum security of classical authenticated en- cryption schemes”. In:International Conference on Cryptology in Africa. Springer. 2023, pp. 79– 104
2023
-
[18]
Zhihao Li et al. “CryptoScope: Utilizing Large Language Models for Automated Cryptographic Logic Vulnerability Detection”. In:arXiv preprint arXiv:2508.11599(2025)
arXiv 2025
-
[19]
Quantifying multilingual per- formance of large language models across lan- guages
Zihao Li et al. “Quantifying multilingual per- formance of large language models across lan- guages”. In:arXiv e-prints(2024), arXiv–2404
2024
-
[20]
Zijie Lin et al. “AutoP2C: An LLM-Based Agent Framework for Code Repository Generation from Multimodal Content in Academic Papers”. In: arXiv preprint arXiv:2504.20115(2025)
arXiv 2025
-
[21]
Understanding llms: A com- prehensive overview from training to inference
Yiheng Liu et al. “Understanding llms: A com- prehensive overview from training to inference”. In:Neurocomputing(2024), p. 129190. 27
2024
-
[22]
Self-refine: Iterative refine- ment with self-feedback
Aman Madaan et al. “Self-refine: Iterative refine- ment with self-feedback”. In:Advances in Neural Information Processing Systems36 (2023), pp. 46534–46594
2023
-
[23]
Automated Update of Android Deprecated API Usages with Large Lan- guage Models
Tarek Mahmud et al. “Automated Update of Android Deprecated API Usages with Large Lan- guage Models”. In:arXiv preprint arXiv:2411.04387 (2024)
arXiv 2024
-
[24]
Benchmarking large language models for cryptanalysis and mismatched-generalization
Utsav Maskey, Chencheng Zhu, and Usman Naseem. “Benchmarking large language models for cryptanalysis and mismatched-generalization”. In:arXiv preprint arXiv:2505.24621(2025)
Pith/arXiv arXiv 2025
-
[25]
Be- yond Static Tools: Evaluating Large Language Models for Cryptographic Misuse Detection
Zohaib Masood and Miguel Vargas Martin. “Be- yond Static Tools: Evaluating Large Language Models for Cryptographic Misuse Detection”. In: arXiv preprint arXiv:2411.09772(2024)
arXiv 2024
-
[26]
Federal Information Processing Standards Publication NIST FIPS 203
National Institute of Standards and Technol- ogy.FIPS 203: Module-Lattice-Based Key- Encapsulation Mechanism Standard. Federal In- formation Processing Standards Publication 203. National Institute of Standards and Technology, Aug. 2024.doi:10.6028/NIST.FIPS.203.url: https://doi.org/10.6028/NIST.FIPS.203
-
[27]
Federal Information Pro- cessing Standards Publication 204
National Institute of Standards and Technol- ogy.FIPS 204: Module-Lattice-Based Digital Signature Standard. Federal Information Pro- cessing Standards Publication 204. National Institute of Standards and Technology, Aug. 2024.doi:10 . 6028 / NIST . FIPS . 204.url: https://doi.org/10.6028/NIST.FIPS.204
-
[28]
FIPS 205: Stateless Hash-Based Digital Signature Standard
National Institute of Standards and Technology. FIPS 205: Stateless Hash-Based Digital Signature Standard. Federal Information Processing Stan- dards Publication 205. National Institute of Stan- dards and Technology, Aug. 2024.doi:10.6028/ NIST . FIPS . 205.url:https : / / doi . org / 10 . 6028/NIST.FIPS.205
2024
-
[29]
NIST Announces First Four Quantum-Resistant Cryptographic Algorithms.https://www.nist
National Institute of Standards and Technology. NIST Announces First Four Quantum-Resistant Cryptographic Algorithms.https://www.nist. gov / news - events / news / 2022 / 07 / nist - announces- first- four- quantum- resistant- cryptographic- algorithms. Accedido el 30 de mayo de 2025. July 2022
2022
-
[30]
National Institute of Standards and Technology (NIST).Migration to Post-Quantum Cryptog- raphy: Mappings to Risk Framework. Tech. rep. Draft White Paper. Available athttps : / / www . nist . gov / news - events / news / 2025 / 09/new-draft-white-paper-pqc-migration- mappings - risk - framework - docs. National Cybersecurity Center of Excellence (NCCoE), S...
2025
-
[31]
Accedido el 22 de mayo de 2025
OpenAI.GPT-4.1 Overview. Accedido el 22 de mayo de 2025. 2025.url:https://platform. openai.com/docs/models/gpt-4.1
2025
-
[32]
Ac- cedido el 22 de mayo de 2025
OpenAI.Introducing GPT-4.1 in the API. Ac- cedido el 22 de mayo de 2025. Apr. 2025.url: https://openai.com/index/gpt-4-1/
2025
-
[33]
Accedido el 22 de mayo de 2025
OpenAI.Pricing - OpenAI API. Accedido el 22 de mayo de 2025. 2025.url:https://platform. openai.com/docs/pricing/
2025
-
[34]
Javier Pallar´ es de Bonrostro and Ana Is- abel Gonz´ alez-Tablas.Cryptographic Migration Dataset: Pre-Quantum to Post-Quantum. Ver- sion V1. 2025.doi:10 . 21950 / 7GK4MJ.url: https://doi.org/10.21950/7GK4MJ
-
[35]
PQC Migration Roadmap
Post-Quantum Cryptography Coalition (PQCC). PQC Migration Roadmap. Tech. rep. Available at https : / / pqcc . org / wp - content / uploads / 2025 / 05 / PQC - Migration - Roadmap - PQCC - 2 . pdf. PQC Coalition, May 2025
2025
-
[36]
Robert Praas.Self-Reflection on Chain-of- Thought Reasoning in Large Language Models. 2023
2023
-
[37]
Accessed January
IBM Research.Cryptography Bill of Materials (CBOM).https://research.ibm.com/blog/ crypto-bill-of-materials. Accessed January
-
[38]
Nino Ricchizzi, Christian Schwinne, and Jan Pelzl. “Applied Post Quantum Cryptography: A Practical Approach for Generating Certificates in Industrial Environments”. In:arXiv preprint arXiv:2505.04333(2025)
arXiv 2025
-
[39]
Code llama: Open foun- dation models for code
Baptiste Roziere et al. “Code llama: Open foun- dation models for code”. In:arXiv preprint arXiv:2308.12950(2023)
Pith/arXiv arXiv 2023
-
[40]
Refactoring programs using large language models with few-shot ex- amples
Atsushi Shirafuji et al. “Refactoring programs using large language models with few-shot ex- amples”. In:2023 30th Asia-Pacific Software Engineering Conference (APSEC). IEEE. 2023, pp. 151–160
2023
-
[41]
ELCA: Introducing enterprise-level cryptographic agility for a post- quantum era
Dimitrios Sikeridis et al. “ELCA: Introducing enterprise-level cryptographic agility for a post- quantum era”. In:Cryptology ePrint Archive (2023)
2023
-
[42]
Assessing and Enhancing Quantum Readiness in Mobile Apps
Joseph Strauss et al. “Assessing and Enhancing Quantum Readiness in Mobile Apps”. In:arXiv preprint arXiv:2506.00790(2025). Available at https://arxiv.org/abs/2506.00790
arXiv 2025
-
[43]
Large language models for software vulnerabil- ity detection: a guide for researchers on mod- els, methods, techniques, datasets, and metrics
Seyed Mohammad Taghavi Far and Farid Feyzi. “Large language models for software vulnerabil- ity detection: a guide for researchers on mod- els, methods, techniques, datasets, and metrics”. In:International Journal of Information Security 24.2 (2025), p. 78. 28
2025
-
[44]
Llama: Open and efficient foundation language models
Hugo Touvron et al. “Llama: Open and efficient foundation language models”. In:arXiv preprint arXiv:2302.13971(2023)
Pith/arXiv arXiv 2023
-
[45]
Meltem S¨ onmez Turan et al.Ascon-Based Lightweight Cryptography Standards for Con- strained Devices: Authenticated Encryption, Hash, and Extendable Output Functions. Tech. rep. NIST SP 800-232 (Initial Public Draft). Initial Public Draft. National Institute of Stan- dards and Technology, Oct. 2024.url:https : //csrc.nist.gov/pubs/sp/800/232/ipd
2024
-
[46]
Attention is all you need
Ashish Vaswani et al. “Attention is all you need”. In:Advances in neural information processing systems30 (2017)
2017
-
[47]
A survey of human-in-the- loop for machine learning
Xingjiao Wu et al. “A survey of human-in-the- loop for machine learning”. In:Future Generation Computer Systems135 (2022), pp. 364–381
2022
-
[48]
Jingfeng Yang et al.Harnessing the Power of LLMs in Practice: A Survey on ChatGPT and Beyond. 2023. arXiv:2304.13712 [cs.CL].url: https://arxiv.org/abs/2304.13712
arXiv 2023
-
[49]
Quanjun Zhang et al.A Survey on Large Lan- guage Models for Software Engineering. 2024. arXiv:2312 . 15223 [cs.SE].url:https : //arxiv.org/abs/2312.15223
arXiv 2024
-
[50]
Hybrid API migration: A marriage of small API mapping models and large language models
Bingzhe Zhou et al. “Hybrid API migration: A marriage of small API mapping models and large language models”. In:Proceedings of the 14th Asia-Pacific Symposium on Internetware. 2023, pp. 12–21
2023
-
[51]
Migrating Code At Scale With LLMs At Google
Celal Ziftci et al. “Migrating Code At Scale With LLMs At Google”. In:arXiv preprint arXiv:2504.09691(2025). 29 Appendix A: F ull dataset distribution Table 8: Distribution of single cryptographic primitives across training and validation splits. Primitive / Alg. #Var. Train Val. Hash functions BLAKE2b 7 7 0 BLAKE2s 7 7 0 MD5 10 9 1 RIPEMD160 1 1 0 SHA-1 ...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.