Property-Guided LLM Program Synthesis for Planning
Pith reviewed 2026-05-20 17:43 UTC · model grok-4.3
The pith
Property-guided LLM synthesis with counterexample feedback creates direct planning heuristics that solve tasks without search using seven times fewer programs than score-based methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors show that a counterexample-guided repair loop, which checks whether every improving state has an improving successor over a training set and returns the first violating case, guides an LLM to synthesize direct heuristics. On ten planning domains the resulting programs are effectively direct on virtually all test tasks, generate seven times fewer programs per domain on average than the best prior method, solve more tasks without search, and require several orders of magnitude less computation to evaluate candidates.
What carries the argument
The counterexample-guided repair loop that enforces the direct-heuristic property by halting evaluation at the first violation and feeding the concrete failure case back to the LLM.
If this is right
- Hill-climbing with the heuristics reaches goal states directly on virtually all test tasks.
- The method works across ten planning domains using out-of-distribution test sets.
- Average program generations per domain drop to one-seventh the number needed by prior score-based generation.
- Candidate evaluation cost falls by several orders of magnitude due to early stopping on violations.
- More tasks are solved without invoking any search procedure.
Where Pith is reading between the lines
- The same property-check loop could be reused in other synthesis tasks where a domain admits an efficiently checkable correctness or progress property.
- Hybrid systems that pair LLM generation with symbolic property checkers may reduce the need for expensive search in broader automated planning.
- Testing the approach on properties stricter than direct heuristics or on larger state spaces would show where the cost savings break down.
- Efficient property verifiers become a new bottleneck once LLM generation itself is cheap.
Load-bearing premise
A single formally defined property plus counterexample feedback is enough to steer the LLM to high-quality direct heuristics across diverse planning domains without extra mechanisms.
What would settle it
Measure whether hill-climbing with the synthesized heuristics reaches the goal on the out-of-distribution test tasks in virtually every case without any search steps.
Figures



read the original abstract
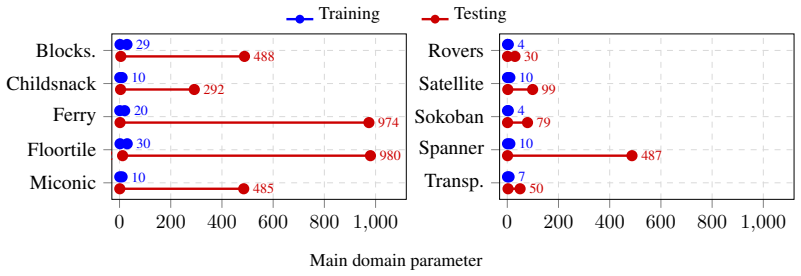
LLMs have shown impressive success in program synthesis, discovering programs that surpass prior solutions. However, these approaches rely on simple numeric scores to signal program quality, such as the value of the solution or the number of passed tests. Because a score offers no guidance on why a program failed, the system must generate and evaluate many candidates hoping some succeed, increasing LLM inference and evaluation costs. We study a different approach: property-guided LLM program synthesis. Instead of scoring programs after evaluation, we check whether a candidate satisfies a formally defined property. When the property is violated, we stop the evaluation early and provide the LLM with a concrete counterexample showing exactly how the program failed. This feedback drastically reduces both the number of program generations and the evaluation cost, and can guide the LLM to generate stronger programs. We evaluate this approach on PDDL planning domains, asking the LLM to synthesize direct heuristic functions: every state reachable by strictly improving transitions has a strictly improving successor. A heuristic with this property leads hill-climbing algorithm directly to a goal state. A counterexample-guided repair loop generates one candidate program, checks the property over a training set, and returns the first case that violates the property. We evaluate our approach on ten planning domains with an out-of-distribution test set. The synthesized heuristics are effectively direct on virtually all test tasks, and compared to the best prior generation method our approach generates seven times fewer programs per domain on average, solves more tasks without using search, and requires several orders of magnitude less computation to evaluate candidates. Whenever a problem admits a verifiable property, property-guided LLM synthesis can reduce cost and improve program quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes property-guided LLM program synthesis to generate direct heuristic functions for PDDL planning domains. The formal property requires that every state reachable by strictly improving transitions has a strictly improving successor, allowing hill-climbing search to reach the goal without backtracking. A counterexample-guided repair loop checks candidate programs against this property on a training set and feeds violations back to the LLM. The approach is evaluated on ten planning domains using an out-of-distribution test set, with claims of generating seven times fewer programs per domain on average, solving more tasks without search, and requiring orders of magnitude less computation than the best prior generation method.
Significance. If the empirical claims hold after verification details are added, the work shows that formally checkable properties plus counterexample feedback can substantially reduce LLM inference cost and improve program quality compared to numeric-score-based synthesis. This is a concrete strength for domains where such properties are definable, with potential extension beyond planning.
major comments (3)
- [Abstract] Abstract: the headline claim that 'the synthesized heuristics are effectively direct on virtually all test tasks' lacks any description of post-synthesis verification that the property holds on OOD test states (as opposed to only the training set used in the repair loop). This is load-bearing for both the 'solves more tasks without using search' and 'seven times fewer programs' comparisons.
- [Evaluation] Evaluation section: no details are given on statistical significance of the reported gains, the precise baselines compared against, or the exact number of tasks solved per domain. These omissions leave the central quantitative results only partially supported.
- [Method] Method: the assumption that a program satisfying the property on all checked training states will preserve the direct property on unseen test states is not justified or tested; a local maximum reachable only from OOD initial states would still require search or cause failure, directly affecting the no-search success claims.
minor comments (2)
- [Abstract] Abstract: define 'effectively direct' quantitatively and state how it was measured on the test set.
- [Introduction] Add a short related-work paragraph contrasting the counterexample mechanism with prior LLM synthesis approaches that rely solely on numeric scores.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment below, indicating where revisions will be made to improve clarity and support for the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that 'the synthesized heuristics are effectively direct on virtually all test tasks' lacks any description of post-synthesis verification that the property holds on OOD test states (as opposed to only the training set used in the repair loop). This is load-bearing for both the 'solves more tasks without using search' and 'seven times fewer programs' comparisons.
Authors: We agree that the abstract would benefit from greater precision on this point. The claim that the heuristics are 'effectively direct' on test tasks is grounded in the empirical results, where the synthesized programs enable solving the large majority of OOD test tasks without any search; this outcome would be impossible if the direct property failed to hold on the states actually encountered during test execution. To make the verification explicit, we will revise the abstract and add a short paragraph in the evaluation section describing the post-synthesis checks we performed on sampled OOD states from the test distribution. These checks were run during our experiments but were not reported in the original submission. revision: yes
-
Referee: [Evaluation] Evaluation section: no details are given on statistical significance of the reported gains, the precise baselines compared against, or the exact number of tasks solved per domain. These omissions leave the central quantitative results only partially supported.
Authors: We accept that these omissions reduce the strength of the quantitative claims. In the revised manuscript we will expand the evaluation section to include a per-domain table listing the exact number of tasks solved by each method, a clear enumeration of all baselines with citations and implementation notes, and statistical significance results (paired t-tests with p-values and 95% confidence intervals) for the key metrics of program generations and no-search success rate. The underlying data already exist and will be used to populate these additions. revision: yes
-
Referee: [Method] Method: the assumption that a program satisfying the property on all checked training states will preserve the direct property on unseen test states is not justified or tested; a local maximum reachable only from OOD initial states would still require search or cause failure, directly affecting the no-search success claims.
Authors: This is a substantive concern about generalization. The counterexample loop guarantees the property only on the training distribution; we did not conduct an exhaustive search for OOD-specific local maxima beyond the observed no-search success rates. Nevertheless, the fact that our method solves substantially more test tasks without search than the baselines supplies indirect evidence that such failures are infrequent in the domains studied. We will add a dedicated paragraph in the method section that states the generalization assumption explicitly, discusses its limitations, and reports an auxiliary verification experiment in which the property was checked on additional OOD states drawn from the test distribution. This is a partial revision because we strengthen the justification and add supporting evidence without introducing entirely new experimental campaigns. revision: partial
Circularity Check
No significant circularity; claims rest on external benchmarks
full rationale
The paper defines a formal property for direct heuristics and uses counterexample-guided LLM synthesis on a training set, then reports empirical success rates on out-of-distribution test tasks from standard PDDL benchmarks. No equations, fitted parameters, or self-citations reduce the reported improvements (fewer programs, more tasks solved without search) to quantities defined by the authors' own inputs by construction. The evaluation compares against prior generation methods on independent planning domains, making the derivation self-contained against external benchmarks. This is the expected honest non-finding for an empirical synthesis paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A heuristic satisfying the property that every state reachable by strictly improving transitions has a strictly improving successor leads hill-climbing directly to a goal state.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We target the direct property: every state reachable from s0 by strictly improving transitions has a strictly improving successor.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
counterexample-guided repair loop generates one candidate program, checks the property over a training set
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Counterexample guided inductive synthesis modulo theories
Alessandro Abate, Cristina David, Pascal Kesseli, Daniel Kroening, and Elizabeth Polgreen. Counterexample guided inductive synthesis modulo theories. InInternational Conference Computer Aided Verification, 2018
work page 2018
-
[2]
Mohammad Abdulaziz, Florian Pommerening, and Augusto B. Corrêa. Mechanically proving guarantees of generalized heuristics: First results and ongoing work. InICAPS Workshop on Heuristics and Search for Domain-independent Planning, 2022
work page 2022
-
[3]
Pyperplan.https://doi.org/10.5281/zenodo.3700819, 2020
Yusra Alkhazraji, Matthias Frorath, Markus Grützner, Malte Helmert, Thomas Liebetraut, Robert Mattmüller, Manuela Ortlieb, Jendrik Seipp, Tobias Springenberg, Philip Stahl, and Jan Wülfing. Pyperplan.https://doi.org/10.5281/zenodo.3700819, 2020
-
[4]
Arfaee, Sandra Zilles, and Robert C
Shahab J. Arfaee, Sandra Zilles, and Robert C. Holte. Learning heuristic functions for large state spaces.Artificial Intelligence, 175:2075–2098, 2011
work page 2075
-
[5]
Cambridge University Press, 2017
Franz Baader, Ian Horrocks, Carsten Lutz, and Uli Sattler, editors.An Introduction to Descrip- tion Logic. Cambridge University Press, 2017
work page 2017
-
[6]
Rafael V Bettker, Pedro P Minini, André G Pereira, and Marcus Ritt. Understanding sample generation strategies for learning heuristic functions in classical planning.Journal of Artificial Intelligence Research, 80:243–271, 2024
work page 2024
-
[7]
Exploring and benchmarking the planning capabilities of large language models
Bernd Bohnet, Azade Nova, Aaron T Parisi, Kevin Swersky, Katayoon Goshvadi, Hanjun Dai, Dale Schuurmans, Noah Fiedel, and Hanie Sedghi. Exploring and benchmarking the planning capabilities of large language models. arXiv:2406.13094 [cs.CL], 2024
-
[8]
Planning as heuristic search.Artificial Intelligence, 129(1): 5–33, 2001
Blai Bonet and Héctor Geffner. Planning as heuristic search.Artificial Intelligence, 129(1): 5–33, 2001
work page 2001
-
[9]
Learning features and abstract actions for computing generalized plans
Blai Bonet, Guillem Francès, and Héctor Geffner. Learning features and abstract actions for computing generalized plans. InProc. AAAI 2019, pages 2703–2710, 2019
work page 2019
-
[10]
Corrêa, Salomé Eriksson, Patrick Ferber, Jendrik Seipp, and Silvan Sievers
Clemens Büchner, Remo Christen, Augusto B. Corrêa, Salomé Eriksson, Patrick Ferber, Jendrik Seipp, and Silvan Sievers. Fast Downward Stone Soup 2023. InIPC-10 Planner Abstracts, 2023
work page 2023
-
[11]
Chen, Sylvie Thiébaux, and Felipe Trevizan
Dillon Z. Chen, Sylvie Thiébaux, and Felipe Trevizan. Learning domain-independent heuristics for grounded and lifted planning. InProc. AAAI 2024, pages 20078–20086, 2024
work page 2024
-
[12]
Chen, Johannes Zenn, Tristan Cinquin, and Sheila A
Dillon Z. Chen, Johannes Zenn, Tristan Cinquin, and Sheila A. McIlraith. Language models for generalised pddl planning: Synthesising sound and programmatic policies. arXiv:2508.18507 [cs.CL], 2025
-
[13]
A unified theory of heuristic evaluation functions and its application to learning
Jens Christensen and Richard E Korf. A unified theory of heuristic evaluation functions and its application to learning. In Tom Kehler and Stanley J. Rosenschein, editors,Proc. AAAI 1986, pages 148–152, 1986
work page 1986
-
[14]
Corrêa and Giuseppe De Giacomo
Augusto B. Corrêa and Giuseppe De Giacomo. Lifted planning: Recent advances in planning using first-order representations. InProc. IJCAI 2024, pages 8010–8019, 2024
work page 2024
-
[15]
Corrêa, Guillem Francès, Markus Hecher, Davide Mario Longo, and Jendrik Seipp
Augusto B. Corrêa, Guillem Francès, Markus Hecher, Davide Mario Longo, and Jendrik Seipp. Scorpion Maidu: Width search in the Scorpion planning system. InIPC-10 Planner Abstracts, 2023. 10
work page 2023
-
[16]
Corrêa, André Grahl Pereira, and Jendrik Seipp
Augusto B. Corrêa, André Grahl Pereira, and Jendrik Seipp. Classical planning with LLM- generated heuristics: Challenging the state of the art with Python code. InProc. NeurIPS 2025, 2025
work page 2025
-
[17]
Frontier Large Language Models Rival State-of-the-Art Planners
Augusto B. Corrêa, André G. Pereira, and Jendrik Seipp. The 2025 planning performance of frontier large language models. arXiv:2511.09378 [cs.CL], 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [18]
-
[19]
Simon Dold and Malte Helmert. Novelty vs. potential heuristics: A comparison of hardness measures for satisficing planning. InProc. AAAI 2024, pages 20692–20699, 2024
work page 2024
-
[20]
Learning sketches for decomposing planning problems into subproblems of bounded width
Dominik Drexler, Jendrik Seipp, and Hector Geffner. Learning sketches for decomposing planning problems into subproblems of bounded width. InProc. ICAPS 2022, pages 62–70, 2022
work page 2022
-
[21]
Dominik Drexler, Jendrik Seipp, and Hector Geffner. Expressing and exploiting subgoal structure in classical planning using sketches.Journal of Artificial Intelligence Research, 80: 171–208, 2024
work page 2024
-
[22]
Kutluhan Erol, Dana S. Nau, and V . S. Subrahmanian. Complexity, decidability and unde- cidability results for domain-independent planning.Artificial Intelligence, 76(1–2):75–88, 1995
work page 1995
-
[23]
Patrick Ferber, Florian Geißer, Felipe Trevizan, Malte Helmert, and Jörg Hoffmann. Neural network heuristic functions for classical planning: Bootstrapping and comparison to other methods. InProc. ICAPS 2022, pages 583–587, 2022
work page 2022
-
[24]
Corrêa, Cedric Geissmann, and Florian Pommerening
Guillem Francès, Augusto B. Corrêa, Cedric Geissmann, and Florian Pommerening. Generalized potential heuristics for classical planning. InProc. IJCAI 2019, pages 5554–5561, 2019
work page 2019
-
[25]
Gemini Team Google. Gemini 3.1 Pro model card. Google DeepMind, 2026
work page 2026
-
[26]
Malik Ghallab, Dana Nau, and Paolo Traverso.Automated Planning: Theory and Practice. Morgan Kaufmann, 2004
work page 2004
-
[27]
Daniel Gnad, Álvaro Torralba, and Alexander Shleyfman. DecStar-2023. InIPC-10 Planner Abstracts, 2023
work page 2023
-
[28]
Lin Guan, Karthik Valmeekam, Sarath Sreedharan, and Subbarao Kambhampati. Leveraging pre-trained large language models to construct and utilize world models for model-based task planning. InProc. NeurIPS 2023, pages 79081–79094, 2023
work page 2023
-
[29]
Guiding GBFS through learned pairwise rankings
Mingyu Hao, Felipe Trevizan, Sylvie Thiébaux, Patrick Ferber, and Jörg Hoffmann. Guiding GBFS through learned pairwise rankings. InProc. IJCAI 2024, pages 6724–6732, 2024
work page 2024
-
[30]
Patrik Haslum, Nir Lipovetzky, Daniele Magazzeni, and Christian Muise.An Introduction to the Planning Domain Definition Language, volume 13 ofSynthesis Lectures on Artificial Intelligence and Machine Learning. Morgan & Claypool, 2019
work page 2019
-
[31]
The Fast Downward planning system.Journal of Artificial Intelligence Research, 26:191–246, 2006
Malte Helmert. The Fast Downward planning system.Journal of Artificial Intelligence Research, 26:191–246, 2006
work page 2006
-
[32]
Malte Helmert, Silvan Sievers, Alexander Rovner, and Augusto B. Corrêa. On the complexity of heuristic synthesis for satisficing classical planning: Potential heuristics and beyond. InProc. ICAPS 2022, pages 124–133, 2022
work page 2022
-
[33]
Jörg Hoffmann and Bernhard Nebel. The FF planning system: Fast plan generation through heuristic search.Journal of Artificial Intelligence Research, 14:253–302, 2001
work page 2001
-
[34]
Chasing progress, not perfection: Revisiting strategies for end-to-end LLM plan generation
Sukai Huang, Trevor Cohn, and Nir Lipovetzky. Chasing progress, not perfection: Revisiting strategies for end-to-end LLM plan generation. arXiv:2412.10675 [cs.CL], 2024. 11
-
[35]
Susmit Jha, Sumit Gulwani, Sanjit A. Seshia, and Ashish Tiwari. Oracle-guided component- based program synthesis. InACM/IEEE International Conference on Software, 2010
work page 2010
-
[36]
Competition-Level Code Generation with AlphaCode
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, Thomas Hubert, Peter Choy, Cyprien de Masson d’Autume, Igor Babuschkin, Xinyun Chen, Po-Sen Huang, Johannes Welbl, Sven Gowal, Alexey Cherepanov, James Molloy, Daniel J. Mankowitz, Esme Sutherland Robson, Pushm...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Best-first width search: Exploration and exploitation in classical planning
Nir Lipovetzky and Hector Geffner. Best-first width search: Exploration and exploitation in classical planning. InProc. AAAI 2017, pages 3590–3596, 2017
work page 2017
-
[38]
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
Bo Liu, Yuqian Jiang, Xiaohan Zhang, Qiang Liu, Shiqi Zhang, Joydeep Biswas, and Pe- ter Stone. LLM+P: Empowering large language models with optimal planning proficiency. arXiv:2304.11477 [cs.CL], 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Evolution of heuristics: Towards efficient automatic algorithm design using large language model
Fei Liu, Xialiang Tong, Mingxuan Yuan, Xi Lin, Fu Luo, Zhenkun Wang, Zhichao Lu, and Qingfu Zhang. Evolution of heuristics: Towards efficient automatic algorithm design using large language model. InProc. ICML 2024, 2024
work page 2024
-
[40]
The 1998 AI Planning Systems competition.AI Magazine, 21(2):35–55, 2000
Drew McDermott. The 1998 AI Planning Systems competition.AI Magazine, 21(2):35–55, 2000
work page 1998
-
[41]
GenePlan: Evolv- ing better generalized PDDL plans using large language models
Andrew Murray, Danial Dervovic, Alberto Pozanco, and Michael Cashmore. GenePlan: Evolv- ing better generalized PDDL plans using large language models. InProc. ICAPS 2026, 2026
work page 2026
-
[42]
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A coding agent for scientific and algor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [43]
-
[44]
Large language models as planning domain generators
James Oswald, Kavitha Srinivas, Harsha Kokel, Junkyu Lee, Michael Katz, and Shirin Sohrabi. Large language models as planning domain generators. InProc. ICAPS 2024, pages 423–431, 2024
work page 2024
-
[45]
Stefan O’Toole, Miquel Ramirez, Nir Lipovetzky, and Adrian R. Pearce. Sampling from pre- images to learn heuristic functions for classical planning (extended abstract). InProc. SoCS 2022, pages 308–310, 2022
work page 2022
-
[46]
Judea Pearl.Heuristics: Intelligent Search Strategies for Computer Problem Solving. Addison- Wesley, 1984
work page 1984
-
[47]
First results on the effect of error in heuristic search
Ira Pohl. First results on the effect of error in heuristic search. In Bernard Meltzer and Donald Michie, editors,Machine Intelligence 5, pages 219–236. Edinburgh University Press, 1969
work page 1969
-
[48]
From non-negative to general operator cost partitioning
Florian Pommerening, Malte Helmert, Gabriele Röger, and Jendrik Seipp. From non-negative to general operator cost partitioning. InProc. AAAI 2015, pages 3335–3341, 2015
work page 2015
-
[49]
Silvia Richter and Matthias Westphal. The LAMA planner: Guiding cost-based anytime planning with landmarks.Journal of Artificial Intelligence Research, 39:127–177, 2010
work page 2010
-
[50]
Pawan Kumar, Emilien Dupont, Francisco J
Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M. Pawan Kumar, Emilien Dupont, Francisco J. R. Ruiz, Jordan S. Ellenberg, Pengming Wang, Omar Fawzi, Pushmeet Kohli, and Alhussein Fawzi. Mathematical discoveries from program search with large language models.Nature, 625(7995):468–475, 2024
work page 2024
-
[51]
Learning general policies for planning through GPT models
Nicholas Rossetti, Massimiliano Tummolo, Alfonso Emilio Gerevini, Luca Putelli, Ivan Serina, Mattia Chiari, and Matteo Olivato. Learning general policies for planning through GPT models. InProc. ICAPS 2024, pages 500–508, 2024. 12
work page 2024
-
[52]
Learning from multiple heuristics
Mehdi Samadi, Ariel Felner, and Jonathan Schaeffer. Learning from multiple heuristics. In Proc. AAAI 2008, pages 357–362, 2008
work page 2008
-
[53]
Arthur L Samuel. Some studies in machine learning using the game of checkers.IBM Journal of research and development, 1959
work page 1959
-
[54]
Correlation complex- ity of classical planning domains
Jendrik Seipp, Florian Pommerening, Gabriele Röger, and Malte Helmert. Correlation complex- ity of classical planning domains. InProc. IJCAI 2016, pages 3242–3250, 2016
work page 2016
-
[55]
Jendrik Seipp, Florian Pommerening, Silvan Sievers, and Malte Helmert. Downward Lab. https://doi.org/10.5281/zenodo.790461, 2017
-
[56]
Learning domain-independent planning heuristics with hypergraph networks
William Shen, Felipe Trevizan, and Sylvie Thiébaux. Learning domain-independent planning heuristics with hypergraph networks. InProc. ICAPS 2020, pages 574–584, 2020
work page 2020
-
[57]
Rabbah, Rastislav Bodík, and Kemal Ebcioglu
Armando Solar-Lezama, Rodric M. Rabbah, Rastislav Bodík, and Kemal Ebcioglu. Program- ming by sketching for bit-streaming programs. In Vivek Sarkar and Mary W. Hall, editors,ACM SIGPLAN 2005 Conference on Programming anguage Design and Implementation, 2005
work page 2005
-
[58]
Simon Ståhlberg, Blai Bonet, and Hector Geffner. Learning general optimal policies with graph neural networks: Expressive power, transparency, and limits. InProc. ICAPS 2022, pages 629–637, 2022
work page 2022
-
[59]
Chain of thoughtlessness? an analysis of CoT in planning
Kaya Stechly, Karthik Valmeekam, and Subbarao Kambhampati. Chain of thoughtlessness? an analysis of CoT in planning. InProc. NeurIPS 2024, pages 29106–29141, 2024
work page 2024
-
[60]
The 2023 International Planning Competition.AI Magazine, 45(2):280–296,
Ayal Taitler, Ron Alford, Joan Espasa, Gregor Behnke, Daniel Fišer, Michael Gimelfarb, Florian Pommerening, Scott Sanner, Enrico Scala, Dominik Schreiber, Javier Segovia-Aguas, and Jendrik Seipp. The 2023 International Planning Competition.AI Magazine, 45(2):280–296,
work page 2023
-
[61]
doi: 10.1002/aaai.12169
-
[62]
Marcus Tantakoun, Christian Muise, and Xiaodan Zhu. LLMs as planning formalizers: A survey for leveraging large language models to construct automated planning models. InFindings of the Association for Computational Linguistics: ACL 2025, 2025
work page 2025
-
[63]
Successor-generator planning with LLM-generated heuristics
Alexander Tuisov, Yonatan Vernik, and Alexander Shleyfman. Successor-generator planning with LLM-generated heuristics. InProc. ICAPS 2026, 2026
work page 2026
-
[64]
Karthik Valmeekam, Matthew Marquez, Alberto Olmo, Sarath Sreedharan, and Subbarao Kambhampati. PlanBench: An extensible benchmark for evaluating large language models on planning and reasoning about change. InProc. NeurIPS 2023, pages 38975–38987, 2023
work page 2023
-
[65]
On the planning abilities of large language models - A critical investigation
Karthik Valmeekam, Matthew Marquez, Sarath Sreedharan, and Subbarao Kambhampati. On the planning abilities of large language models - A critical investigation. InProc. NeurIPS 2023, pages 75993–76005, 2023. 13 A Benchmark Domains We evaluate on the ten domains of the Learning Track of the IPC 2023 [ 60]. We give a brief description of each domain below, b...
work page 2023
-
[66]
Alive State : r e a c h a b l e from the initial state , solvable , and not a goal state
-
[67]
I m p r o v i n g S u c c e s s o r : a s u c c e s s o r s ’ such that h (s ’) < h ( s )
-
[68]
All states that DFS can reach must contain an i m p r o v i n g s u c c e s s o r
Direct : every alive state r e a c h a b l e from the initial state via a se qu en ce of s tr ict ly d e c r e a s i n g h values has at least one i m p r o v i n g s u c c e s s o r . All states that DFS can reach must contain an i m p r o v i n g s u c c e s s o r
-
[69]
Dead - End Av oi di ng : no i m p r o v i n g s u c c e s s o r of an alive state r e a c h a b l e by DFS is itself u n s o l v a b l e ( h = i nfi ni ty ) . </ success - criteria > < previous - iterations > I t e r a t i o n 0: - Prompt Type : Init - Solved 5 i n s t a n c e s ( Average ex pan de d nodes : 2.4) - Direct v a l i d a t e d on 5 tasks ( la...
-
[70]
action =( stack b3 b2 ) , h =6 , added =[ ’( clear b3 ) ’, ’( on b3 b2 ) ’, ’( arm - empty ) ’] , deleted =[ ’( holding b3 ) ’, ’( clear b2 ) ’]
-
[71]
action =( stack b3 b1 ) , h =6 , added =[ ’( clear b3 ) ’, ’( on b3 b1 ) ’, ’( arm - empty ) ’] , deleted =[ ’( holding b3 ) ’, ’( clear b1 ) ’]
-
[72]
</ previous - heuristic - code > I t e r a t i o n 1: - Prompt Type : Pr ope rt y - Main Idea :
action =( putdown b3 ) , h =4 , added =[ ’( clear b3 ) ’, ’( on - table b3 ) ’, ’( arm - empty ) ’] , deleted =[ ’( holding b3 ) ’] < previous - heuristic - code > ... </ previous - heuristic - code > I t e r a t i o n 1: - Prompt Type : Pr ope rt y - Main Idea : ... - Solved 16 i n s t a n c e s ( Average ex pa nd ed nodes : 7.0) - Direct v a l i d a t e...
-
[73]
action =( unstack b3 b2 ) , h =11 , added =[ ’( holding b3 ) ’, ’( clear b2 ) ’] , deleted =[ ’( clear b3 ) ’, ’( on b3 b2 ) ’, ’( arm - empty ) ’]
-
[74]
action =( pickup b4 ) , h =11 , added =[ ’( holding b4 ) ’] , deleted =[ ’( on - table b4 ) ’, ’( clear b4 ) ’, ’( arm - empty ) ’]
-
[75]
</ previous - heuristic - code > I t e r a t i o n 2: - Prompt Type : Pr ope rt y - Main Idea :
action =( pickup b1 ) , h =11 , added =[ ’( holding b1 ) ’] , deleted =[ ’( clear b1 ) ’, ’( on - table b1 ) ’, ’( arm - empty ) ’] < previous - heuristic - code > ... </ previous - heuristic - code > I t e r a t i o n 2: - Prompt Type : Pr ope rt y - Main Idea : ... - Solved 17 i n s t a n c e s ( Average ex pa nd ed nodes : 7.8) - Direct v a l i d a t e...
-
[76]
action =( unstack b5 b2 ) , h =9 , added =[ ’( holding b5 ) ’, ’( clear b2 ) ’] , deleted =[ ’( on b5 b2 ) ’, ’( clear b5 ) ’, ’( arm - empty ) ’]
-
[77]
action =( pickup b1 ) , h =9 , added =[ ’( holding b1 ) ’] , deleted =[ ’( clear b1 ) ’, ’( on - table b1 ) ’, ’( arm - empty ) ’]
-
[78]
action =( pickup b3 ) , h =9 , added =[ ’( holding b3 ) ’] , deleted =[ ’( clear b3 ) ’, ’( on - table b3 ) ’, ’( arm - empty ) ’] < previous - heuristic - code > ... </ previous - heuristic - code > </ previous - iterations > < current - status > Domain P ro gre ss : solving 99 i n s t a n c e s of i n c r e a s i n g d i f f i c u l t y . V a l i d a t ...
-
[79]
action =( unstack b15 b12 ) , h =39 , added =[ ’( holding b15 ) ’, ’( clear b12 ) ’] , deleted =[ ’( clear b15 ) ’, ’( on b15 b12 ) ’, ’( arm - empty ) ’]
-
[80]
action =( unstack b9 b16 ) , h =39 , added =[ ’( holding b9 ) ’, ’( clear b16 ) ’] , deleted =[ ’( on b9 b16 ) ’, ’( clear b9 ) ’, ’( arm - empty ) ’]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.