Dynamic Resilient Spatio-Semantic Memory with Hybrid Localization for Mobile Manipulation
Pith reviewed 2026-06-28 18:50 UTC · model grok-4.3
The pith
DREAM builds an online voxel memory that prunes redundancies after pose corrections to raise success in dynamic mobile manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
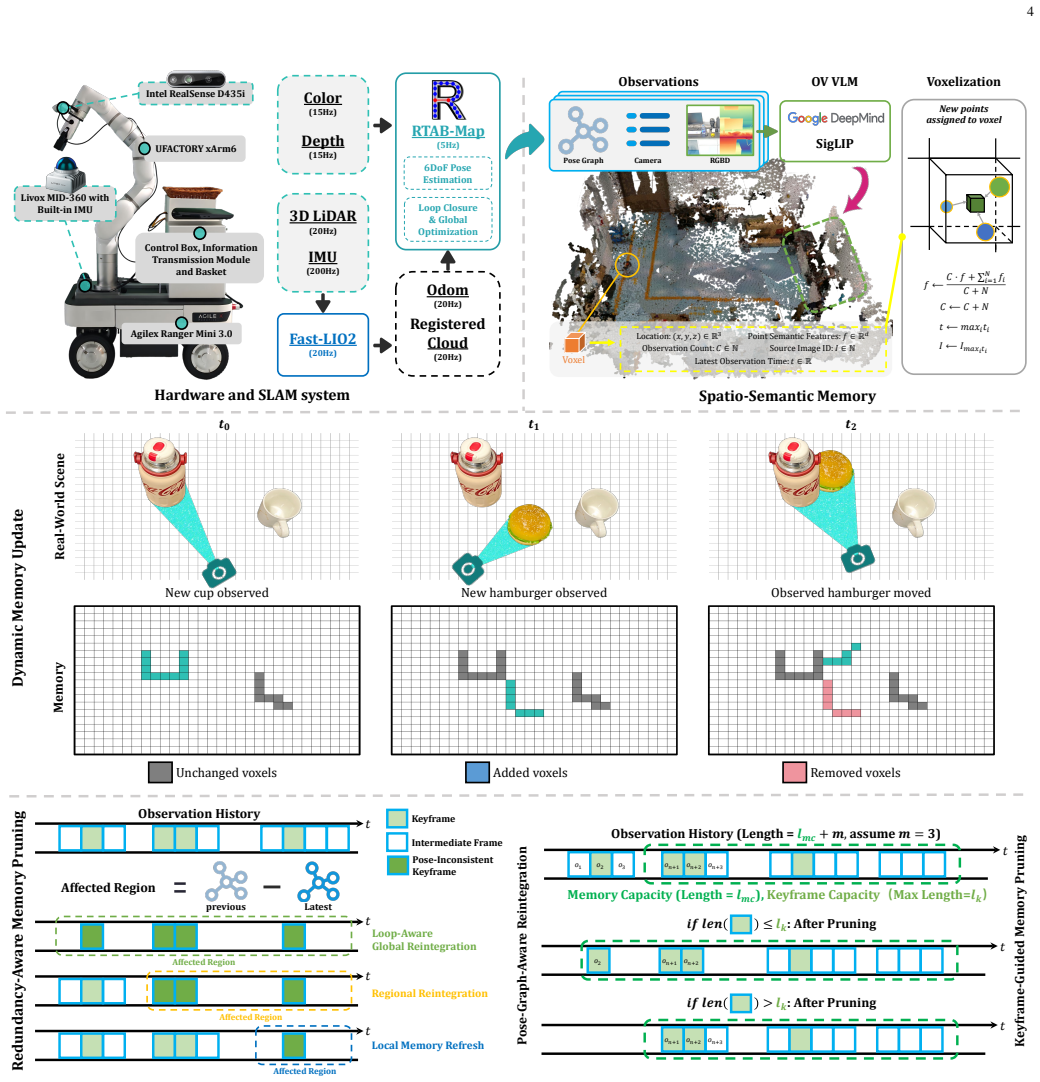
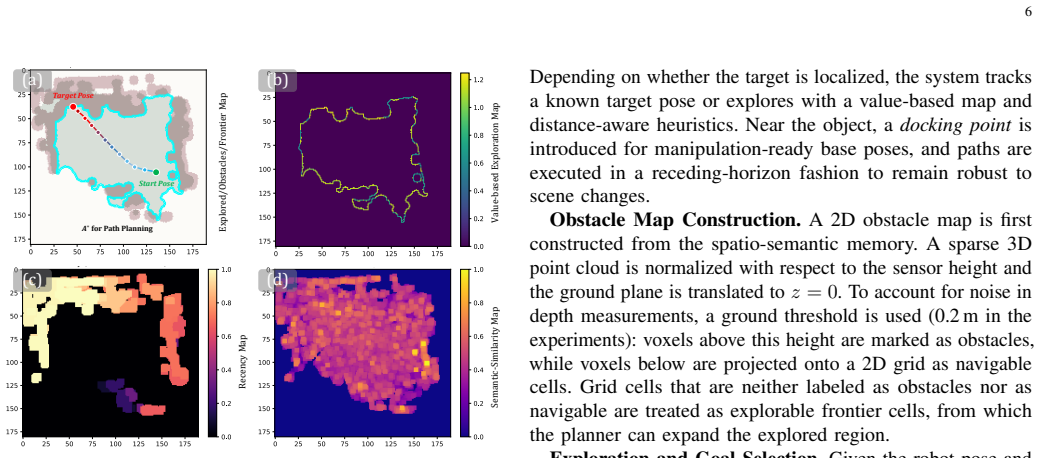
DREAM constructs an online spatio-semantic voxel memory from RGB-D observations registered by a LiDAR-inertial-visual SLAM backend and introduces pose-graph-aware Redundancy-Aware Memory Pruning to update historical observations after pose corrections while keeping long-horizon observation history bounded, enabling reliable target localization and reacquisition through language-conditioned 3D retrieval, open-vocabulary detection, and multimodal large language model verification.
What carries the argument
Pose-graph-aware Redundancy-Aware Memory Pruning (RMP), which removes redundant voxels and refreshes stored observations once the SLAM pose graph revises earlier estimates.
If this is right
- Long-horizon task success rates increase from 40-60% to 55-70% in dynamic indoor scenes.
- Memory footprint remains bounded between 0.37 GB and 0.63 GB across four tested environments.
- Online memory updates complete in 0.43-0.53 seconds without requiring a pre-built map.
- Hybrid localization successfully reacquires relocated targets using combined 3D retrieval and semantic verification.
- The system operates end-to-end on a real robot integrating perception, navigation, and manipulation.
Where Pith is reading between the lines
- The pruning step could allow robots to operate for longer periods before memory saturation forces a reset.
- If SLAM accuracy degrades in larger or more cluttered spaces the same registration errors would likely amplify pruning mistakes.
- Replacing the current open-vocabulary detector with a newer model would be a direct way to test whether semantic verification is the current performance bottleneck.
- The bounded-memory property suggests the approach could be tested in repeated multi-hour sessions where objects are rearranged between tasks.
Load-bearing premise
The SLAM backend supplies pose estimates accurate enough for reliable registration of new RGB-D frames and correct pruning decisions when objects have moved.
What would settle it
Deploy the system in one of the tested scenes, deliberately move a target object after the first pass, introduce measurable pose drift, and measure whether long-horizon success stays above the DynaMem baseline or whether memory size exceeds 0.63 GB.
Figures



read the original abstract
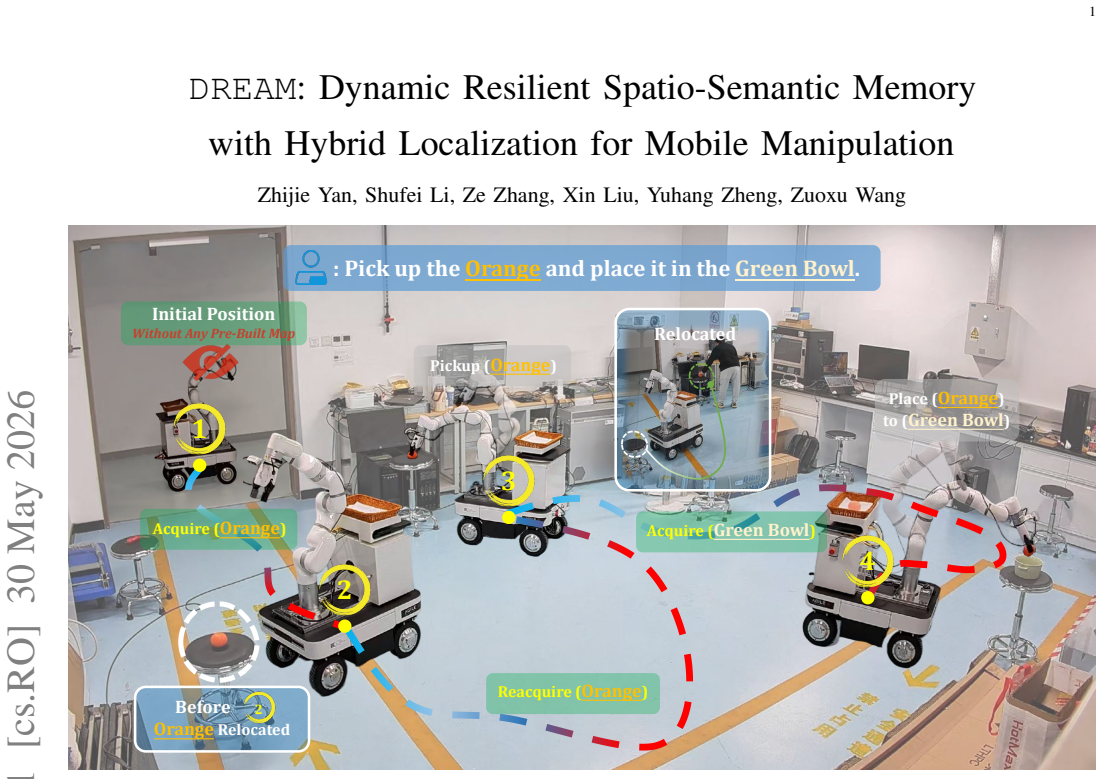
Reliable mobile manipulation in dynamic indoor environments requires a scene representation that remains geometrically consistent, semantically queryable, and computationally bounded as the environment changes. Existing systems often rely on pre-built maps, static-scene assumptions, or highly accurate camera poses, which can lead to stale or misaligned scene information when target objects are relocated or pose estimates are corrected. This paper presents DREAM, a real-robot mobile manipulation framework that integrates perception, memory, localization, navigation, and manipulation in previously unseen indoor environments without a pre-built map. DREAM constructs an online spatio-semantic voxel memory from RGB-D observations registered by a LiDAR-inertial-visual SLAM backend. It further introduces pose-graph-aware Redundancy-Aware Memory Pruning (RMP) to update historical observations after pose corrections while keeping long-horizon observation history bounded. For target localization and reacquisition, DREAM combines language-conditioned 3D retrieval, open-vocabulary image detection, and multimodal large language model based semantic verification. Real-robot experiments in four dynamic indoor laboratory scenes show that DREAM improves long-horizon task success rates from 40%-60% with DynaMem to 55%-70%, while maintaining a memory footprint of 0.37-0.63 GB and an online memory-update time of 0.43-0.53 s across scenes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents DREAM, a mobile manipulation framework for dynamic indoor environments without pre-built maps. It constructs an online spatio-semantic voxel memory from RGB-D observations registered via a LiDAR-inertial-visual SLAM backend, introduces pose-graph-aware Redundancy-Aware Memory Pruning (RMP) to maintain bounded history after pose corrections, and combines language-conditioned 3D retrieval, open-vocabulary detection, and MLLM semantic verification for target localization. Real-robot experiments across four dynamic laboratory scenes report improved long-horizon task success rates (55-70% vs. 40-60% for DynaMem) with memory footprints of 0.37-0.63 GB and update times of 0.43-0.53 s.
Significance. If the empirical claims hold under proper statistical validation and SLAM accuracy checks, the work would offer a practical advance in resilient, bounded scene representations for long-horizon mobile manipulation in changing environments. The RMP mechanism that ties memory pruning to the pose graph directly addresses a common failure mode when loop closures occur amid object relocation.
major comments (2)
- [Abstract] Abstract: The headline result (success rates rising from 40%-60% with DynaMem to 55%-70%) is presented without any report of trial counts per scene, error bars, statistical tests, or exclusion criteria. This directly undermines evaluation of the central performance claim.
- [Abstract] Abstract: The framework's memory construction and RMP pruning presuppose that the LiDAR-inertial-visual SLAM backend supplies poses accurate enough for reliable RGB-D registration and post-correction updates. No ATE/RPE numbers, pose-noise ablation, or registration-error statistics from the four dynamic scenes are supplied, leaving this load-bearing assumption untested.
minor comments (1)
- [Abstract] Abstract: Memory footprint and update-time ranges are given without per-scene breakdowns or discussion of how they scale with the number of relocated objects.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and evaluation. We address each point below and will revise the manuscript to improve clarity on experimental details and assumptions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline result (success rates rising from 40%-60% with DynaMem to 55%-70%) is presented without any report of trial counts per scene, error bars, statistical tests, or exclusion criteria. This directly undermines evaluation of the central performance claim.
Authors: We agree that the abstract would benefit from additional context on the evaluation protocol. The manuscript body details the experimental setup across the four scenes. In revision we will update the abstract to note that success rates are aggregated over multiple trials per scene, include reference to standard deviations or ranges, and direct readers to the experimental section for trial counts, error bars, and any exclusion criteria applied. revision: yes
-
Referee: [Abstract] Abstract: The framework's memory construction and RMP pruning presuppose that the LiDAR-inertial-visual SLAM backend supplies poses accurate enough for reliable RGB-D registration and post-correction updates. No ATE/RPE numbers, pose-noise ablation, or registration-error statistics from the four dynamic scenes are supplied, leaving this load-bearing assumption untested.
Authors: This observation is correct. The current manuscript does not supply explicit ATE/RPE or registration-error statistics for the dynamic scenes. We will revise the methods and discussion sections to include available calibration-based accuracy information for the SLAM backend and clarify how RMP handles post-correction updates. A full pose-noise ablation or dynamic-scene ATE evaluation would require new ground-truth data collection and is noted as a limitation for future work. revision: partial
Circularity Check
No circularity: empirical system evaluation against external task benchmarks
full rationale
The paper describes an integrated mobile manipulation framework (DREAM) whose central claims are measured success-rate improvements (55-70% vs. 40-60% baseline) obtained from real-robot trials in four dynamic scenes. No equations, fitted parameters, or derivations appear in the supplied abstract or context; the reported metrics are direct empirical outcomes against an external baseline (DynaMem) and real-world task completion, not quantities defined in terms of the system's own outputs. The evaluation is therefore self-contained against observable performance and does not reduce to self-definition or self-citation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ConceptGraphs: Open- V ocabulary 3D Scene Graphs for Perception and Planning,
Q. Gu, A. Kuwajerwala, S. Morinet al., “ConceptGraphs: Open- V ocabulary 3D Scene Graphs for Perception and Planning,” inProceed- ings of the IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 5021–5028
2024
-
[2]
Hierarchical Open-V ocabulary 3D Scene Graphs for Language-Grounded Robot Navigation,
A. Werby, C. Huang, M. Büchneret al., “Hierarchical Open-V ocabulary 3D Scene Graphs for Language-Grounded Robot Navigation,” inPro- ceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[3]
OK-Robot: What Really Matters in Integrating Open-Knowledge Models for Robotics,
P. Liu, Y . R. Orru, J. Vakilet al., “OK-Robot: What Really Matters in Integrating Open-Knowledge Models for Robotics,” inProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[4]
DynaMem: Online Dynamic Spatio- Semantic Memory for Open World Mobile Manipulation,
P. Liu, Z. Guo, M. Warkeet al., “DynaMem: Online Dynamic Spatio- Semantic Memory for Open World Mobile Manipulation,” inProceedings of the IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 13 346–13 355
2025
-
[5]
Dynamic Open-V ocabulary 3D Scene Graphs for Long-Term Language-Guided Mobile Manipulation,
Z. Yan, S. Li, Z. Wanget al., “Dynamic Open-V ocabulary 3D Scene Graphs for Long-Term Language-Guided Mobile Manipulation,”IEEE Robotics and Automation Letters, 2025
2025
-
[6]
OpenAI, J. Achiam, S. Adleret al., “GPT-4 Technical Report,”arXiv preprint arXiv:2303.08774, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, R. Anıl, S. Borgeaudet al., “Gemini: A Family of Highly Capable Multimodal Models,”arXiv preprint arXiv:2312.11805, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Interactive Task Planning with Language Models,
B. Li, P. Wu, P. Abbeelet al., “Interactive Task Planning with Language Models,”Transactions on Machine Learning Research (TMLR), 2025. 11
2025
-
[9]
Navigation World Models,
A. Bar, G. Zhou, D. Tranet al., “Navigation World Models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[10]
ManiSkill-HAB: A Benchmark for Low- Level Manipulation in Home Rearrangement Tasks,
A. Shukla, S. Tao, and H. Su, “ManiSkill-HAB: A Benchmark for Low- Level Manipulation in Home Rearrangement Tasks,” inProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[11]
AMO: Adaptive Motion Optimization for Hyper-Dexterous Humanoid Whole-Body Control,
J. Li, X. Cheng, T. Huanget al., “AMO: Adaptive Motion Optimization for Hyper-Dexterous Humanoid Whole-Body Control,”arXiv preprint arXiv:2505.03738, 2025
-
[12]
Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation,
Z. Fu, T. Z. Zhao, and C. Finn, “Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation,” in Proceedings of the IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 5515–5522
2024
-
[13]
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
Q. Liao, T. E. Truong, X. Huanget al., “BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion,”arXiv preprint arXiv:2508.08241, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
CLIP-Fields: Weakly Supervised Semantic Fields for Robotic Memory,
N. M. M. Shafiullah, C. Paxton, L. Pintoet al., “CLIP-Fields: Weakly Supervised Semantic Fields for Robotic Memory,” inProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[15]
RoboEXP: Action-Conditioned Scene Graph via Interactive Exploration for Robotic Manipulation,
H. Jiang, B. Huang, R. Wuet al., “RoboEXP: Action-Conditioned Scene Graph via Interactive Exploration for Robotic Manipulation,” in Conference on Robot Learning (CoRL). PMLR, 2025, pp. 3027–3052
2025
-
[16]
NeRF-SLAM: Real-Time Dense Monocular SLAM with Neural Radiance Fields,
A. Rosinol, J. J. Leonard, and L. Carlone, “NeRF-SLAM: Real-Time Dense Monocular SLAM with Neural Radiance Fields,” inProceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 3437–3444
2023
-
[17]
Loc-NeRF: Monte Carlo Localization using Neural Radiance Fields,
D. Maggio, M. Abate, J. Shiet al., “Loc-NeRF: Monte Carlo Localization using Neural Radiance Fields,” inProceedings of the IEEE/RSJ Inter- national Conference on Intelligent Robots and Systems (IROS). IEEE, 2023, pp. 4018–4025
2023
-
[18]
3D Gaussian Splatting for Real-Time Radiance Field Rendering,
B. Kerbl, G. Kopanas, T. Leimkühleret al., “3D Gaussian Splatting for Real-Time Radiance Field Rendering,”ACM Transactions on Graphics (TOG), vol. 42, no. 4, pp. 1–14, 2023
2023
-
[19]
DynamicGSG: Dynamic 3D Gaus- sian Scene Graphs for Environment Adaptation,
L. Ge, X. Zhu, Z. Yanget al., “DynamicGSG: Dynamic 3D Gaus- sian Scene Graphs for Environment Adaptation,”arXiv preprint arXiv:2502.15309, 2025
-
[20]
Embodied Instruction Following in Unknown Environments,
Z. Wu, Z. Wang, X. Xuet al., “Embodied Instruction Following in Unknown Environments,” inProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[21]
UniGoal: Towards Universal Zero-Shot Goal-Oriented Navigation,
H. Yin, X. Xu, L. Zhaoet al., “UniGoal: Towards Universal Zero-Shot Goal-Oriented Navigation,”arXiv preprint arXiv:2503.10630, 2025
-
[22]
A Holistic Approach to Reactive Mobile Manipulation,
J. Haviland, N. Sunderhauf, and P. Corke, “A Holistic Approach to Reactive Mobile Manipulation,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 3122–3129, 2022
2022
-
[23]
NaVILA: Legged Robot Vision- Language-Action Model for Navigation,
A.-C. Cheng, Y . Ji, Z. Yanget al., “NaVILA: Legged Robot Vision- Language-Action Model for Navigation,” inProceedings of the IEEE International Conference on Robotics and Automation (ICRA), 2025
2025
-
[24]
RTAB-Map as an open-source lidar and visual simultaneous localization and mapping library for large-scale and long-term online operation,
M. Labbé and F. Michaud, “RTAB-Map as an open-source lidar and visual simultaneous localization and mapping library for large-scale and long-term online operation,”Journal of Field Robotics, vol. 36, no. 2, pp. 416–446, 2018
2018
-
[25]
FAST-LIO2: Fast Direct LiDAR-Inertial Odometry,
W. Xu, Y . Cai, D. Heet al., “FAST-LIO2: Fast Direct LiDAR-Inertial Odometry,”IEEE Transactions on Robotics, vol. 38, no. 4, pp. 2053– 2073, 2022
2053
-
[26]
Learning Transferable Visual Models from Natural Language Supervision,
A. Radford, J. W. Kim, C. Hallacyet al., “Learning Transferable Visual Models from Natural Language Supervision,” inProceedings of the International Conference on Machine Learning (ICML). PMLR, 2021, pp. 8748–8763
2021
-
[27]
Sigmoid Loss for Language Image Pre-Training,
X. Zhai, B. Mustafa, A. Kolesnikovet al., “Sigmoid Loss for Language Image Pre-Training,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 11 975– 11 986
2023
-
[28]
Scaling Open-V ocabulary Object Detection,
M. Minderer, A. Gritsenko, and N. Houlsby, “Scaling Open-V ocabulary Object Detection,”Advances in Neural Information Processing Systems (NeurIPS), vol. 36, pp. 72 983–73 007, 2023
2023
-
[29]
S. Bai, K. Chen, X. Liuet al., “Qwen2.5-VL Technical Report,”arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
A formal basis for the heuristic determination of minimum cost paths,
P. E. Hart, N. J. Nilsson, and B. Raphael, “A formal basis for the heuristic determination of minimum cost paths,”IEEE Transactions on Systems Science and Cybernetics, vol. 4, no. 2, pp. 100–107, 1968
1968
-
[31]
Unified Vision-Language-Action Model,
Y . Wang, X. Li, W. Wanget al., “Unified Vision-Language-Action Model,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
2026
-
[32]
Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation
Y . Liao, P. Zhou, S. Huanget al., “Genie Envisioner: A Unified World Foundation Platform for Robotic Manipulation,”arXiv preprint arXiv:2508.05635, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection,
S. Liu, Z. Zeng, T. Renet al., “Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection,” inProceedings of the European Conference on Computer Vision (ECCV). Springer, 2024, pp. 38–55
2024
-
[34]
SAM 2: Segment Anything in Images and Videos,
N. Ravi, V . Gabeur, Y .-T. Huet al., “SAM 2: Segment Anything in Images and Videos,” inProceedings of the International Conference on Learn Represent (ICLR), 2025
2025
-
[35]
AnyGrasp: Robust and Efficient Grasp Perception in Spatial and Temporal Domains,
H.-S. Fang, C. Wang, H. Fanget al., “AnyGrasp: Robust and Efficient Grasp Perception in Spatial and Temporal Domains,”IEEE Transactions on Robotics, vol. 39, no. 6, pp. 4455–4472, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.