OrthoTrack: Continuous 6-DoF UAV Trajectory Estimation Anchored in Public Orthophotos
Pith reviewed 2026-06-30 09:44 UTC · model grok-4.3
The pith
OrthoTrack produces continuous metric 6-DoF UAV trajectories by anchoring keyframes to public orthophotos and propagating via optical flow.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
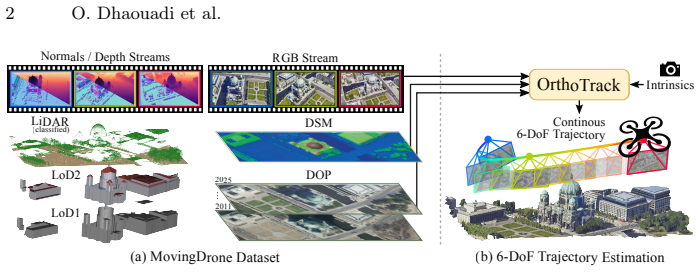
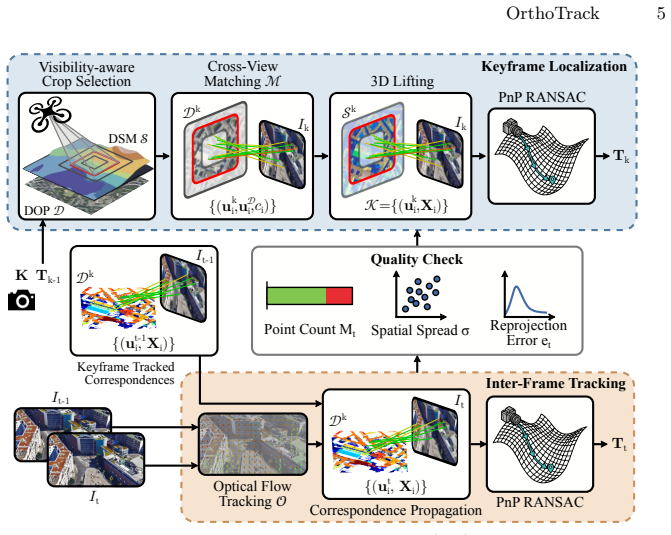
OrthoTrack matches keyframes against the orthophoto and lifts correspondences to metric 3D via the surface model. It then propagates these map-anchored correspondences to intermediate frames with optical flow, producing absolute, metrically scaled poses at every frame without GPS or post-hoc alignment.
What carries the argument
Keyframe-to-orthophoto matching followed by 3D lifting via the surface model and optical-flow propagation to non-key frames.
If this is right
- Absolute metric scale is available at every frame without any post-hoc correction.
- The system runs in real time on a single GPU using only public map data.
- New regions can be handled without site-specific training or adaptation.
- Continuous trajectories are produced even though only keyframes are matched to the map.
- The approach outperforms both relative visual odometry and single-frame geo-localization baselines.
Where Pith is reading between the lines
- The same anchoring idea could be tested on satellite imagery or other public elevation sources if the matching step remains reliable.
- Integration with onboard inertial sensors might further improve robustness when visual matches are sparse.
- The pipeline could support repeated flights over the same area by reusing the same public map across missions.
- Performance on outdated maps would reveal how much temporal mismatch the matching stage can tolerate before drift appears.
Load-bearing premise
Orthophoto-to-image matching must yield sufficiently accurate and repeatable correspondences that survive viewpoint, lighting, and temporal differences.
What would settle it
Trajectory error remains low on sequences where the orthophoto and UAV imagery differ substantially in season, time of day, or construction changes.
Figures
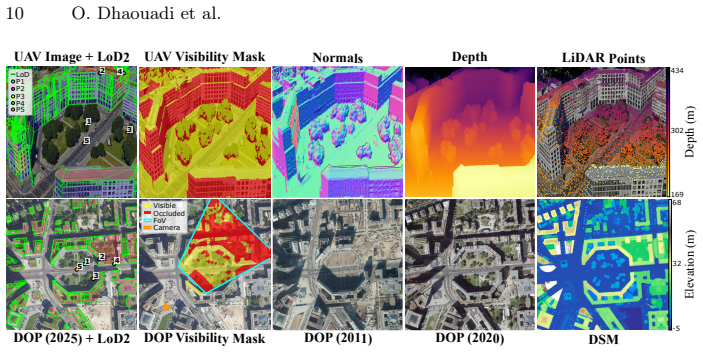
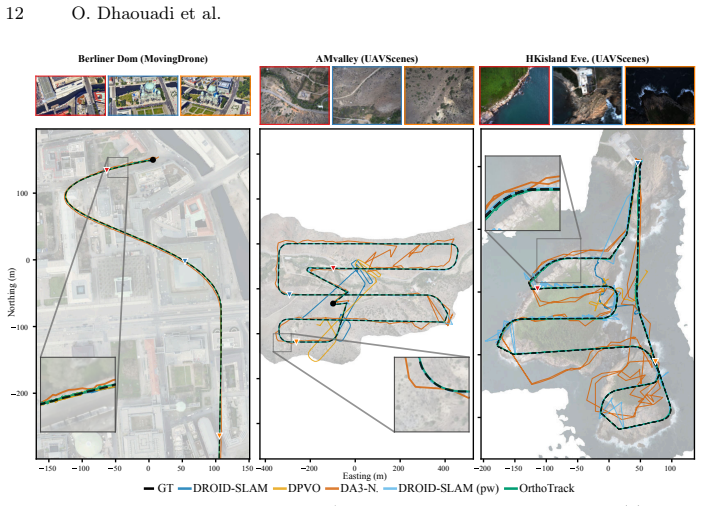
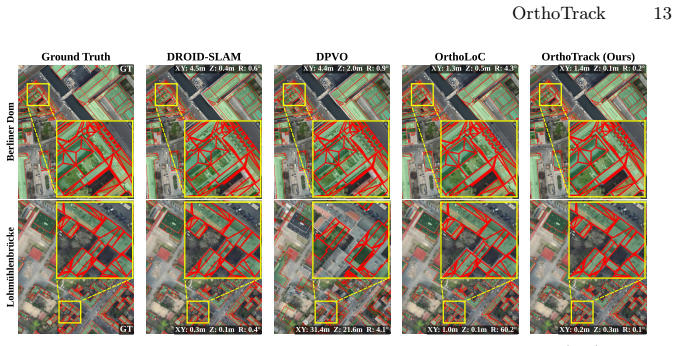
read the original abstract
Continuous 6-DoF pose estimation is essential for autonomous UAV operations. Yet, existing visual odometry and SLAM methods accumulate drift and yield only relative, up-to-scale trajectories. Single-frame geo-localization, in turn, discards temporal continuity and remains too slow for real-time use. We present OrthoTrack, a training-free system that estimates continuous 6-DoF UAV trajectories using only publicly available orthophotos and surface models as a map prior. OrthoTrack matches keyframes against the orthophoto and lifts correspondences to metric 3D via the surface model. It then propagates these map-anchored correspondences to intermediate frames with optical flow, producing absolute, metrically scaled poses at every frame without GPS or post-hoc alignment. We also introduce the MovingDrone Dataset, a large-scale benchmark pairing photorealistic UAV sequences with dense 6-DoF ground truth and co-registered multi-modal geodata including multi-temporal orthophotos. On MovingDrone and real-world benchmarks, OrthoTrack runs in real time on a single GPU. It outperforms all baselines by a large margin, even those receiving oracle scale and alignment. By relying on publicly available geodata, OrthoTrack enables deployment to new regions without site-specific adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents OrthoTrack, a training-free pipeline for continuous 6-DoF UAV trajectory estimation that anchors keyframes to public orthophotos, lifts 2D-2D correspondences to metric 3D using a surface model, and propagates the anchored points to all frames via optical flow to obtain absolute, metrically scaled poses at every timestep without GPS or post-hoc alignment. It introduces the MovingDrone Dataset pairing photorealistic UAV sequences with dense ground truth and co-registered multi-temporal geodata. Experiments claim real-time GPU operation and large-margin outperformance over VO/SLAM and geo-localization baselines, including those given oracle scale and alignment.
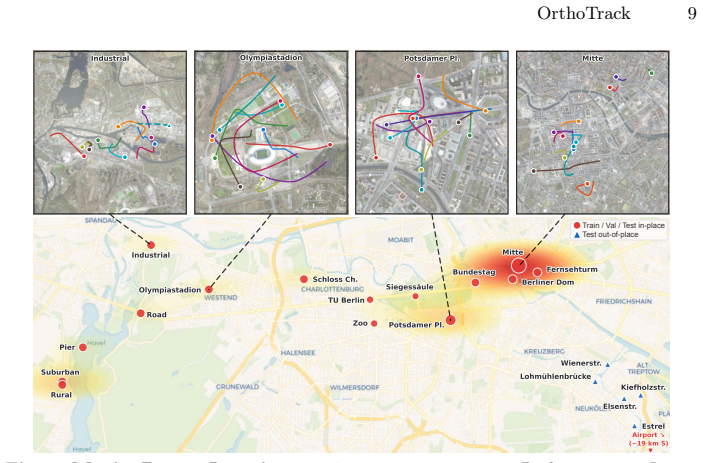
Significance. If the performance and robustness claims hold, the work would enable practical, drift-free absolute localization for UAVs in new regions using only publicly available orthophotos and DSMs, removing the need for site-specific training or GPS. The training-free design, real-time capability, and introduction of the MovingDrone Dataset (with its multi-modal, multi-temporal registration) are clear strengths that could support reproducible benchmarking in aerial visual localization.
major comments (3)
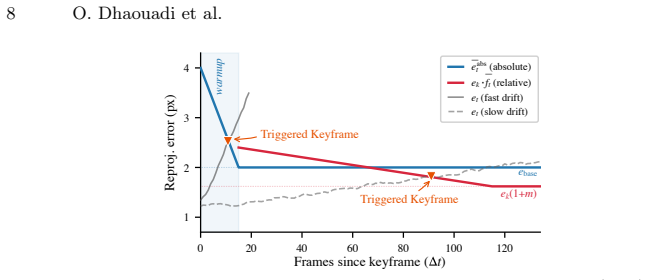
- [§3.2] §3.2 (Keyframe-to-orthophoto matching): The module is described only at the level of 'matches keyframes against the orthophoto' with no specification of the descriptor, similarity metric, RANSAC threshold, or inlier selection criteria. This is load-bearing for the central claim because the accuracy of 3D lifting via the surface model and the drift-free property of the subsequent optical-flow propagation both rest on the repeatability and precision of these correspondences under nadir-to-oblique viewpoint change, illumination variation, and possible multi-temporal map misalignment.
- [Table 2] Table 2 (MovingDrone quantitative results): The reported ATE and RPE values show large-margin gains, yet the table omits per-sequence inlier rates for the orthophoto matching step, 3D lifting error statistics, and the fraction of frames where matching fails. Without these, it is impossible to verify whether the absolute metric property is maintained or whether the outperformance is driven by easy sequences where matching succeeds.
- [§4.3] §4.3 (Real-world benchmarks): The evaluation does not report any controlled stress test on temporal map misalignment or strong lighting changes, both of which are explicitly flagged as failure modes for orthophoto-to-image matching. This directly affects the claim that the method works 'even those receiving oracle scale and alignment' across diverse conditions.
minor comments (3)
- [Figure 2] Figure 2: The pipeline diagram would be clearer if the optical-flow propagation arrows were labeled with the frame indices they connect.
- [§2] §2 (Related work): Several recent learned geo-localization methods that also use orthophoto priors are not cited; adding them would better situate the training-free design choice.
- [Eq. (3)] Eq. (3): The notation for the lifted 3D point P does not explicitly state whether the surface model is assumed to be in the same coordinate frame as the orthophoto or requires an additional rigid transform.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where additional detail and analysis will strengthen the manuscript. We address each major comment below and will revise the paper accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Keyframe-to-orthophoto matching): The module is described only at the level of 'matches keyframes against the orthophoto' with no specification of the descriptor, similarity metric, RANSAC threshold, or inlier selection criteria. This is load-bearing for the central claim because the accuracy of 3D lifting via the surface model and the drift-free property of the subsequent optical-flow propagation both rest on the repeatability and precision of these correspondences under nadir-to-oblique viewpoint change, illumination variation, and possible multi-temporal map misalignment.
Authors: We agree that the description in §3.2 lacks the necessary implementation specifics for reproducibility. In the revised manuscript we will expand this section to explicitly state the feature descriptor, similarity metric, RANSAC threshold, and inlier selection criteria employed, thereby clarifying how the method maintains correspondence quality under the cited viewpoint, illumination, and map-misalignment conditions. revision: yes
-
Referee: [Table 2] Table 2 (MovingDrone quantitative results): The reported ATE and RPE values show large-margin gains, yet the table omits per-sequence inlier rates for the orthophoto matching step, 3D lifting error statistics, and the fraction of frames where matching fails. Without these, it is impossible to verify whether the absolute metric property is maintained or whether the outperformance is driven by easy sequences where matching succeeds.
Authors: We concur that these per-sequence diagnostics are important for validating the absolute-metric claim. We will revise Table 2 (or introduce a companion table) to report per-sequence inlier rates, 3D lifting error statistics, and the fraction of frames where orthophoto matching fails, providing a clearer picture of performance variation across the benchmark. revision: yes
-
Referee: [§4.3] §4.3 (Real-world benchmarks): The evaluation does not report any controlled stress test on temporal map misalignment or strong lighting changes, both of which are explicitly flagged as failure modes for orthophoto-to-image matching. This directly affects the claim that the method works 'even those receiving oracle scale and alignment' across diverse conditions.
Authors: The referee correctly notes the absence of targeted stress tests on these failure modes. Although the MovingDrone dataset already includes multi-temporal orthophotos, we will add controlled experiments and analysis in §4.3 that isolate temporal misalignment and strong lighting variations, directly supporting the robustness claims. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper describes a training-free pipeline that matches keyframes to public orthophotos, lifts correspondences via surface models, and propagates via optical flow to produce absolute poses. No equations, fitted parameters, or self-citations are presented that would make any claimed output equivalent to its inputs by construction. The central claims rest on an externally introduced benchmark dataset (MovingDrone) with independent ground truth and comparisons to baselines, rendering the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bochkovskiy, A., Delaunoy, A., Germain, H., Santos, M., Zhou, Y., Richter, S., Koltun, V.: Depth pro: Sharp monocular metric depth in less than a second. In: Int. Conf. Learn. Represent. (2025)
2025
-
[2]
In: IEEE Conf
Cabon, Y., Stoffl, L., Antsfeld, L., Csurka, G., Chidlovskii, B., Revaud, J., Leroy, V.: Must3r: Multi-view network for stereo 3d reconstruction. In: IEEE Conf. Com- put. Vis. Pattern Recog. pp. 1050–1060 (2025)
2025
-
[3]
IEEE Trans
Campos, C., Elvira, R., Gómez, J.J., Montiel, J.M.M., Tardós, J.D.: ORB-SLAM3: An accurate open-source library for visual, visual-inertial and multi-map SLAM. IEEE Trans. Robot.37(6), 1874–1890 (2021)
2021
-
[4]
In: IEEE Conf
Chen, G., Fu, T., Chen, H., Teng, W., Xiao, H., Zhao, Y.: Rdd: Robust feature detector and descriptor using deformable transformer. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 6394–6403 (2025) 16 O. Dhaouadi et al
2025
-
[5]
arXiv preprint arXiv:2207.12317 (2022)
Cisneros, I., Yin, P., Zhang, J., Choset, H., Scherer, S.: Alto: A large-scale dataset for uav visual place recognition and localization. arXiv preprint arXiv:2207.12317 (2022)
-
[6]
Dhaouadi,O.,Marin,R.,Meier,J.M.,Kaiser,J.,Cremers,D.:Ortholoc:UAV6-dof localization and calibration using orthographic geodata. In: Adv. Neural Inform. Process. Syst. (2025)
2025
-
[7]
In: IEEE Conf
Edstedt, J., Athanasiadis, I., Wadenbäck, M., Felsberg, M.: Dkm: Dense kernelized feature matching for geometry estimation. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 17765–17775 (2023)
2023
-
[8]
arXiv preprint arXiv:2503.07347 (2025)
Edstedt, J., Bökman, G., Wadenbäck, M., Felsberg, M.: Dad: Distilled reinforce- ment learning for diverse keypoint detection. arXiv preprint arXiv:2503.07347 (2025)
-
[9]
Edstedt, J., Bökman, G., Wadenbäck, M., Felsberg, M.: DeDoDe: Detect, Don’t Describe — Describe, Don’t Detect for Local Feature Matching. In: Int. Conf. 3D Vis. IEEE (2024)
2024
-
[10]
arXiv preprint arXiv:2511.15706 , year=
Edstedt, J., Nordström, D., Zhang, Y., Bökman, G., Astermark, J., Larsson, V., Heyden, A., Kahl, F., Wadenbäck, M., Felsberg, M.: Roma v2: Harder better faster denser feature matching. arXiv preprint arXiv:2511.15706 (2025)
-
[11]
In: IEEE Conf
Edstedt, J., Sun, Q., Bökman, G., Wadenbäck, M., Felsberg, M.: Roma: Robust dense feature matching. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 19790– 19800 (2024)
2024
-
[12]
Google: Google earth studio.https://earth.google.com/studio/(2026)
2026
-
[13]
Scientific reports6(1), 22574 (2016)
Hodgson, J.C., Baylis, S.M., Mott, R., Herrod, A., Clarke, R.H.: Precision wildlife monitoring using unmanned aerial vehicles. Scientific reports6(1), 22574 (2016)
2016
-
[14]
IEEE Trans
Hu, M., Yin, W., Zhang, C., Cai, Z., Long, X., Chen, H., Wang, K., Yu, G., Shen, C., Shen, S.: Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation. IEEE Trans. Pattern Anal. Mach. Intell.46(12), 10579–10596 (2024)
2024
-
[15]
In: IEEE Conf
Jang, W., Weinzaepfel, P., Leroy, V., Agapito, L., Revaud, J.: Pow3r: Empowering unconstrained 3d reconstruction with camera and scene priors. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 1071–1081 (2025)
2025
-
[16]
In: AAAI
Ji, Y., He, B., Tan, Z., Wu, L.: Game4loc: A uav geo-localization benchmark from game data. In: AAAI. vol. 39, pp. 3913–3921 (2025)
2025
-
[17]
IET Radar, Sonar & Nav- igation12(2), 151–164 (2018)
Jordan, S., Moore, J., Hovet, S., Box, J., Perry, J., Kirsche, K., Lewis, D., Tse, Z.T.H.: State-of-the-art technologies for uav inspections. IET Radar, Sonar & Nav- igation12(2), 151–164 (2018)
2018
-
[18]
IEEE Trans
Ke, B., Qu, K., Wang, T., Metzger, N., Huang, S., Li, B., Obukhov, A., Schindler, K.: Marigold: Affordable adaptation of diffusion-based image generators for image analysis. IEEE Trans. Pattern Anal. Mach. Intell. (2025)
2025
-
[19]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Keetha, N., Müller, N., Schönberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., et al.: Mapanything: Univer- sal feed-forward metric 3d reconstruction. arXiv preprint arXiv:2509.13414 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Künzel, J., Hilsmann, A., Eisert, P.: Ripe: Reinforcement learning on unlabeled image pairs for robust keypoint extraction. In: Int. Conf. Comput. Vis. pp. 4868– 4877 (2025)
2025
-
[21]
Online geodata platform (2025), https://data.geobasis-bb.de, data licensed under Datenlizenz Deutschland Na- mensnennung 2.0
Landesvermessung und Geobasisinformation Brandenburg (LGB): Opengeo- data.brandenburg - data portal of geobasis-de. Online geodata platform (2025), https://data.geobasis-bb.de, data licensed under Datenlizenz Deutschland Na- mensnennung 2.0
2025
-
[22]
Leroy, V., Cabon, Y., Revaud, J.: Grounding image matching in 3d with mast3r. In: Eur. Conf. Comput. Vis. pp. 71–91. Springer (2024) OrthoTrack 17
2024
-
[23]
Li, X., Rao, T., Pan, C.: Edm: Efficient deep feature matching. In: Int. Conf. Comput. Vis. pp. 26198–26208 (2025)
2025
-
[24]
Liang, Y., Hu, Y., Shao, W., Fu, Y.: Learning dense feature matching via lifting single 2d image to 3d space. In: Int. Conf. Comput. Vis. pp. 6621–6631 (2025)
2025
-
[25]
Depth Anything 3: Recovering the Visual Space from Any Views
Lin, H., Chen, S., Liew, J., Chen, D.Y., Li, Z., Shi, G., Feng, J., Kang, B.: Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
Lindenberger, P., Sarlin, P.E., Pollefeys, M.: Lightglue: Local feature matching at light speed. In: Int. Conf. Comput. Vis. pp. 17627–17638 (2023)
2023
-
[27]
In: IEEE Int
Liu, Y., Lai, W., Zhao, Z., Xiong, Y., Zhu, J., Cheng, J., Xu, Y.: Liftfeat: 3d geometry-aware local feature matching. In: IEEE Int. Conf. Robot. Autom. pp. 11714–11720. IEEE (2025)
2025
-
[28]
In: AAAI
Lucas, B.D., Kanade, T.: An iterative image registration technique with an appli- cation to stereo vision. In: AAAI. vol. 2, pp. 674–679 (1981)
1981
-
[29]
Pattern Anal
Nistér,D.:Anefficientsolutiontothefive-pointrelativeposeproblem.IEEETrans. Pattern Anal. Mach. Intell.26(6), 756–770 (2004)
2004
-
[30]
Panek, V., Kukelova, Z., Sattler, T.: Meshloc: Mesh-based visual localization. In: Eur. Conf. Comput. Vis. pp. 589–609. Springer (2022)
2022
-
[31]
In: IEEE Conf
Piccinelli, L., Yang, Y.H., Sakaridis, C., Segu, M., Li, S., Van Gool, L., Yu, F.: Unidepth: Universal monocular metric depth estimation. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 10106–10116 (2024)
2024
-
[32]
In: IEEE Conf
Potje, G., Cadar, F., Araujo, A., Martins, R., Nascimento, E.R.: Xfeat: Accelerated features for lightweight image matching. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 2682–2691 (2024)
2024
-
[33]
Sarlin, P.E., DeTone, D., Malisiewicz, T., Rabinovich, A.: Superglue: Learning featurematchingwithgraphneuralnetworks.In:IEEEConf.Comput.Vis.Pattern Recog. pp. 4938–4947 (2020)
2020
-
[34]
In: Proceedings of the first workshop on micro aerial vehicle networks, systems, and applications for civilian use
Scherer, J., Yahyanejad, S., Hayat, S., Yanmaz, E., Andre, T., Khan, A., Vukadi- novic, V., Bettstetter, C., Hellwagner, H., Rinner, B.: An autonomous multi-uav system for search and rescue. In: Proceedings of the first workshop on micro aerial vehicle networks, systems, and applications for civilian use. pp. 33–38 (2015)
2015
-
[35]
arXiv preprint arXiv:2205.11567 (2022)
Schleiss, M., Rouatbi, F., Cremers, D.: Vpair–aerial visual place recognition and localization in large-scale outdoor environments. arXiv preprint arXiv:2205.11567 (2022)
-
[36]
Senate Department for Urban Development, Building and Housing (Senatsverwal- tung für Stadtentwicklung, Bauen und Wohnen), Berlin: Geoportal berlin (geospa- tial data infrastructure berlin).https://gdi.berlin.de(2026), accessed: 2026- 02-24
2026
-
[37]
arXiv e-prints pp
Sun, J., Liu, K., Zhang, C., Chen, C., Shen, J., Vong, C.M.: Cross-view uav geo- localization with precision-focused efficient design: A hierarchical distillation ap- proach with multi-view refinement. arXiv e-prints pp. arXiv–2510 (2025)
2025
-
[38]
Teed, Z., Deng, J.: Raft: Recurrent all-pairs field transforms for optical flow. In: Eur. Conf. Comput. Vis. pp. 402–419. Springer (2020)
2020
-
[39]
Teed, Z., Deng, J.: Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras. In: Adv. Neural Inform. Process. Syst. vol. 34, pp. 16558–16569 (2021)
2021
-
[40]
Teed, Z., Lipson, L., Deng, J.: Deep patch visual odometry. In: Adv. Neural Inform. Process. Syst. vol. 36 (2024)
2024
-
[41]
Terzakis, G., Lourakis, M.: A consistently fast and globally optimal solution to the perspective-n-point problem. In: Eur. Conf. Comput. Vis. pp. 478–494. Springer (2020) 18 O. Dhaouadi et al
2020
-
[42]
virtualcitymap
virtualcitymap berlin 3d city model.https : / / berlin . virtualcitymap . de/ (2025),https://berlin.virtualcitymap.de/
2025
-
[43]
In: IEEE Conf
Vuong, K., Ghosh, A., Ramanan, D., Narasimhan, S., Tulsiani, S.: Aerialmegadepth: Learning aerial-ground reconstruction and view synthesis. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 21674–21684 (2025)
2025
-
[44]
In: IEEE Conf
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Vi- sual geometry grounded transformer. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 5294–5306 (2025)
2025
-
[45]
Wang, R., Xu, S., Dong, Y., Deng, Y., Xiang, J., Lv, Z., Sun, G., Tong, X., Yang, J.: Moge-2: Accurate monocular geometry with metric scale and sharp details. In: Adv. Neural Inform. Process. Syst. (2025)
2025
-
[46]
In: IEEE Conf
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: Dust3r: Geometric 3d vision made easy. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 20697–20709 (2024)
2024
-
[47]
Wang, S., Li, S., Zhang, Y., Yu, S., Yuan, S., She, R., Guo, Q., Zheng, J., Howe, O.K., Chandra, L., et al.: Uavscenes: A multi-modal dataset for uavs. In: Int. Conf. Comput. Vis. pp. 28946–28958 (2025)
2025
-
[48]
In: IEEE Conf
Wang, Y., He, X., Peng, S., Tan, D., Zhou, X.: Efficient loftr: Semi-dense local feature matching with sparse-like speed. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 21666–21675 (2024)
2024
-
[49]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Wang, Y., Zhou, J., Zhu, H., Chang, W., Zhou, Y., Li, Z., Chen, J., Pang, J., Shen, C., He, T.:π 3: Permutation-equivariant visual geometry learning. arXiv preprint arXiv:2507.13347 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Wang, Y., Lipson, L., Deng, J.: Sea-raft: Simple, efficient, accurate raft for optical flow. In: Eur. Conf. Comput. Vis. pp. 36–54. Springer (2024)
2024
-
[51]
Wu, R., Cheng, X., Zhu, J., Liu, X., Zhang, M., Yan, S.: Uavd4l: A large-scale dataset for uav 6-dof localization. In: Int. Conf. 3D Vis. (2024)
2024
-
[52]
arXiv preprint arXiv:2405.11936 (2024) 22, 29
Xu, W., Yao, Y., Cao, J., Wei, Z., Liu, C., Wang, J., Peng, M.: Uav-visloc: A large- scale dataset for uav visual localization. arXiv preprint arXiv:2405.11936 (2024)
-
[53]
In: IEEE Conf
Yan, Q., Zheng, J., Reding, S., Li, S., Doytchinov, I.: Crossloc: Scalable aerial localization assisted by multimodal synthetic data. In: IEEE Conf. Comput. Vis. Pattern Recog. pp. 17358–17368 (2022)
2022
-
[54]
Yan, S., Cheng, X., Liu, Y., Zhu, J., Wu, R., Liu, Y., Zhang, M.: Render-and- compare: Cross-view 6-dof localization from noisy prior. In: Int. Conf. Multimedia and Expo. pp. 2171–2176. IEEE (2023)
2023
-
[55]
Advances in Neural Information Processing Systems37, 21875–21911 (2024)
Yang, L., Kang, B., Huang, Z., Zhao, Z., Xu, X., Feng, J., Zhao, H.: Depth anything v2. Advances in Neural Information Processing Systems37, 21875–21911 (2024)
2024
-
[56]
Ye, Y., Teng, X., Chen, S., Li, Z., Liu, L., Yu, Q., Tan, T.: Exploring the best way for uav visual localization under low-altitude multi-view observation condition: a benchmark. arXiv preprint arXiv:2503.10692 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Zhang, Y., Keetha, N., Lyu, C., Jhamb, B., Chen, Y., Qiu, Y., Karhade, J., Jha, S., Hu, Y., Ramanan, D., et al.: Ufm: A simple path towards unified dense corre- spondence with flow. arXiv preprint arXiv:2506.09278 (2025)
-
[58]
In: IEEE/RSJ Int
Zhang, Z., Gupta, A., Jiang, H., Singh, H.: Neuflow-v2: Push high-efficiency optical flow to the limit. In: IEEE/RSJ Int. Conf. Intell. Robots Syst. pp. 2479–2485. IEEE (2025)
2025
-
[59]
In: ACM Int
Zheng, Z., Wei, Y., Yang, Y.: University-1652: A multi-view multi-source bench- mark for drone-based geo-localization. In: ACM Int. Conf. Multimedia. pp. 1395– 1403 (2020) OrthoTrack 19
2020
-
[60]
Zhu, J., Peng, S., Wang, L., Tan, H., Liu, Y., Zhang, M., Yan, S.: Lod-loc v2: Aerial visual localization over low level-of-detail city models using explicit silhou- ette alignment. In: Int. Conf. Comput. Vis. pp. 26610–26621 (2025)
2025
-
[61]
In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C
Zhu, J., Yan, S., Wang, L., shengYue, z., Liu, Y., Zhang, M.: Lod-loc: Aerial visual localization using lod 3d map with neural wireframe alignment. In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C. (eds.) Adv. Neural Inform. Process. Syst. vol. 37, pp. 119063–119098. Curran Associates, Inc. (2024) 20 O. Dhaouadi et a...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.