MoCA-Agent: A Market-of-Claims Code Agent for Financial and Numerical Reasoning
Pith reviewed 2026-06-27 10:15 UTC · model grok-4.3
The pith
Aggregating evidence at the level of atomic claims rather than whole answers improves robustness in high-stakes numerical reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
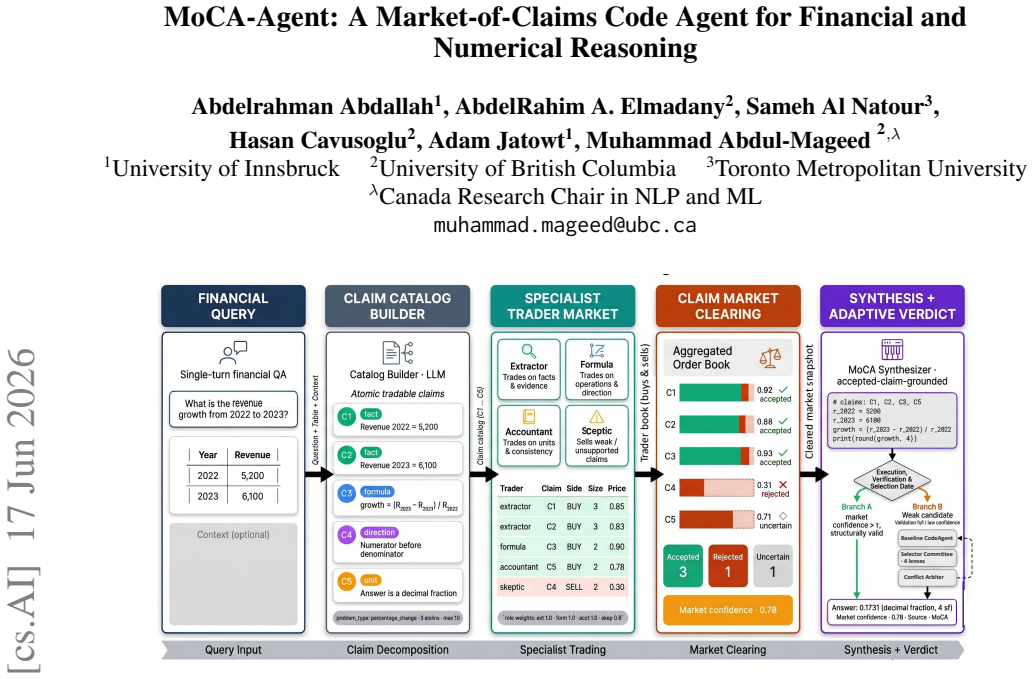
MoCA-Agent replaces free-form multi-agent debate with claim-level verification. Each question is decomposed into typed atomic claims. Specialist trader agents buy or sell the claims. Orders are cleared into confidence-weighted accept/reject decisions. An executable Python program is synthesized from the market-supported evidence. A code verifier checks the program for execution, structural consistency, and common financial reasoning errors, with at most one market-aware repair round. This produces strong results across financial, tabular, ESG, and chart benchmarks.
What carries the argument
The market-of-claims mechanism: atomic claims are traded by specialist agents and cleared into weighted decisions that support code synthesis and final answers.
If this is right
- Strong performance on FinQA at 78.3 percent, FinanceMath at 76.0 percent, and MultiHiertt at 71.2 percent.
- High scores on ESGenius at 86.9 percent for ESG tasks and 85.6 percent average on FinChart-Bench for multimodal charts.
- At most one market-aware repair round after code verification.
- Effective results using a fixed Qwen3 27B backbone across all ten benchmarks.
Where Pith is reading between the lines
- The claim-trading structure could be applied to other domains that require precise grounding in numbers and units, such as scientific data analysis.
- Market clearing at the claim level offers a potential way to surface disagreement among agents before code is generated.
- The typed claim categories (fact, formula, sign, scale) suggest a modular agent design that might be extended by adding new specialist trader types.
- The approach separates evidence aggregation from program writing, which might allow independent improvement of the trading step without retraining the code generator.
Load-bearing premise
The decomposition into typed atomic claims can be performed reliably and that specialist trader agents can evaluate those claims without introducing systematic bias or missing context that would invalidate the market clearing step.
What would settle it
A controlled test set of questions where the atomic claim decomposition omits or mis-types a critical context element, causing the market to accept an incorrect claim and produce a wrong final answer even after code verification.
Figures
read the original abstract
Financial and tabular question answering requires more than fluent reasoning: answers must be grounded in the exact facts, formulas, units, signs, and scales that support them. A single misread cell or incorrect operation can silently produce a plausible but wrong result. We introduce \textsc{MOCA-Agent}, a market-of-claims code agent that replaces free-form multi-agent debate with claim-level verification. The system decomposes each question into typed atomic claims, asks specialist trader agents to buy or sell those claims, clears their orders into confidence-weighted accept/reject decisions, and synthesizes an executable Python program from market-supported evidence. A code-aware verifier then checks the program for execution, structural consistency, and common financial reasoning errors, with at most one market-aware repair round. Across ten public benchmarks spanning financial numerical reasoning, general tabular reasoning, ESG question answering, and multimodal chart reasoning, \textsc{MOCA-Agent} achieves strong performance using a fixed Qwen3.6-27B backbone, including $78.3\%$ on FinQA, $76.0\%$ on FinanceMath, $71.2\%$ on MultiHiertt, $86.9\%$ on ESGenius, and $85.6\%$ average on FinChart-Bench. These results show that aggregating evidence at the level of atomic claims, rather than whole answers, improves robustness in high-stakes numerical reasoning.\footnote{The code and data are available: https://github.com/UBC-NLP/MoCA-Agent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MoCA-Agent, a system that decomposes financial/numerical questions into typed atomic claims, solicits buy/sell orders from specialist trader agents, clears the market into confidence-weighted accept/reject decisions, synthesizes an executable Python program from the supported claims, and applies a code-aware verifier (with at most one repair round). Using a fixed Qwen3.6-27B backbone, it reports results such as 78.3% on FinQA, 76.0% on FinanceMath, 71.2% on MultiHiertt, 86.9% on ESGenius, and 85.6% average on FinChart-Bench, claiming that claim-level aggregation improves robustness over whole-answer debate.
Significance. If the reported gains are attributable to the market-of-claims mechanism rather than the underlying model or unmeasured factors, the work could provide a useful template for verifiable numerical reasoning in high-stakes domains. The public release of code and data supports reproducibility.
major comments (3)
- [Method (decomposition and trader pipeline, likely §3)] The central robustness claim (abstract and §1) rests on the assumptions that (1) questions can be decomposed into typed atomic claims without omission or hallucination and (2) trader agents evaluate claims without systematic bias or loss of cross-claim context. No accuracy metrics, inter-annotator agreement scores, or human validation results for the decomposition step are reported, which is load-bearing for the claim that market clearing aggregates reliable evidence.
- [Experiments and results tables] Experiments section and benchmark tables: the manuscript supplies no ablation that removes the market-clearing step (or replaces it with direct claim aggregation), no comparison against the same backbone without the MoCA pipeline, and no error analysis of cases where decomposition or trader decisions fail. This makes it impossible to attribute the reported benchmark numbers specifically to claim-level aggregation rather than other components.
- [Code synthesis and verifier subsection] The code-synthesis and verifier stages are described at a high level (abstract and method), but no quantitative breakdown is given of how often the market-supported evidence is sufficient for correct code generation versus how often the single repair round is invoked or fails.
minor comments (2)
- [Method] Notation for claim types and market-clearing rule could be formalized with a short pseudocode or equation block for precision.
- [Abstract / footnote] The footnote states code and data are available, but the manuscript should include a direct link or repository reference in the main text rather than only the footnote.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on validation, attribution of gains, and component analysis. We address each point below and commit to revisions that strengthen the manuscript without overstating current evidence.
read point-by-point responses
-
Referee: [Method (decomposition and trader pipeline, likely §3)] The central robustness claim (abstract and §1) rests on the assumptions that (1) questions can be decomposed into typed atomic claims without omission or hallucination and (2) trader agents evaluate claims without systematic bias or loss of cross-claim context. No accuracy metrics, inter-annotator agreement scores, or human validation results for the decomposition step are reported, which is load-bearing for the claim that market clearing aggregates reliable evidence.
Authors: We agree that explicit validation of the decomposition step is important for supporting the robustness claim. The decomposition uses a structured prompt on the fixed Qwen3.6-27B backbone to produce typed atomic claims, and the market mechanism is intended to filter errors via trader buy/sell orders. We did not include human validation or inter-annotator metrics in the original submission. In revision we will add a dedicated analysis subsection reporting decomposition accuracy on a held-out sample of questions from FinQA and MultiHiertt, along with discussion of observed failure modes such as omitted context or hallucinated units. revision: partial
-
Referee: [Experiments and results tables] Experiments section and benchmark tables: the manuscript supplies no ablation that removes the market-clearing step (or replaces it with direct claim aggregation), no comparison against the same backbone without the MoCA pipeline, and no error analysis of cases where decomposition or trader decisions fail. This makes it impossible to attribute the reported benchmark numbers specifically to claim-level aggregation rather than other components.
Authors: We concur that ablations and error analysis are needed to isolate the contribution of market clearing. The current results use a fixed backbone across all benchmarks, but lack direct comparisons. In the revised manuscript we will add an ablation table on FinQA, FinanceMath, and MultiHiertt comparing (i) full MoCA-Agent, (ii) MoCA without market clearing (direct claim aggregation), and (iii) the backbone model prompted end-to-end. We will also include a qualitative error analysis of 50 failure cases categorized by decomposition, trader decision, and code-synthesis issues. revision: yes
-
Referee: [Code synthesis and verifier subsection] The code-synthesis and verifier stages are described at a high level (abstract and method), but no quantitative breakdown is given of how often the market-supported evidence is sufficient for correct code generation versus how often the single repair round is invoked or fails.
Authors: We will expand the experiments section with a quantitative breakdown. The revised version will report, for each benchmark, the percentage of cases where market-supported claims directly yield correct executable code, the invocation rate of the single repair round, and the success rate of that repair round. These statistics will be derived from the existing experimental logs. revision: yes
Circularity Check
No circularity: empirical system description with no derivation chain or self-referential steps
full rationale
The paper presents an agent architecture (decomposition into atomic claims, trader buy/sell orders, market clearing, code synthesis, and verifier) evaluated on public benchmarks. No equations, fitted parameters renamed as predictions, or first-principles derivations appear. No self-citations are used to justify uniqueness theorems, ansatzes, or load-bearing premises. The robustness claim rests on reported accuracies (e.g., 78.3% on FinQA) rather than reducing to its own inputs by construction. This is a standard empirical systems paper whose central pipeline choices are design decisions, not derived results that loop back to the inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Finqa: A dataset of numerical reasoning over financial data , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[2]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
DocMath-eval: Evaluating math reasoning capabilities of LLMs in understanding long and specialized documents , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[3]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Financemath: Knowledge-intensive math reasoning in finance domains , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[4]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Hitab: A hierarchical table dataset for question answering and natural language generation , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[5]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
MultiHiertt: Numerical reasoning over multi hierarchical tabular and textual data , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[6]
arXiv preprint arXiv:2209.14610 , year=
Dynamic prompt learning via policy gradient for semi-structured mathematical reasoning , author=. arXiv preprint arXiv:2209.14610 , year=
-
[7]
Compositional semantic parsing on semi-structured tables , author=. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[8]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Esgenius: Benchmarking llms on environmental, social, and governance (esg) and sustainability knowledge , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[9]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
arXiv preprint arXiv:2107.07653 , year=
TAPEX: Table pre-training via learning a neural SQL executor , author=. arXiv preprint arXiv:2107.07653 , year=
-
[13]
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
OmniTab: Pretraining with natural and synthetic data for few-shot table-based question answering , author=. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2022
-
[14]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Tablellm: Enabling tabular data manipulation by llms in real office usage scenarios , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[15]
arXiv preprint arXiv:2411.02059 , year=
Tablegpt2: A large multimodal model with tabular data integration , author=. arXiv preprint arXiv:2411.02059 , year=
-
[16]
arXiv preprint arXiv:2503.12345 , year=
General Table Question Answering via Answer-Formula Joint Generation , author=. arXiv preprint arXiv:2503.12345 , year=
-
[17]
CCF International Conference on Natural Language Processing and Chinese Computing , pages=
Napg: Non-autoregressive program generation for hybrid tabular-textual question answering , author=. CCF International Conference on Natural Language Processing and Chinese Computing , pages=. 2023 , organization=
2023
-
[18]
Advances in Neural Information Processing Systems , volume=
Chameleon: Plug-and-play compositional reasoning with large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
International Conference on Learning Representations , volume=
Chain-of-table: Evolving tables in the reasoning chain for table understanding , author=. International Conference on Learning Representations , volume=
-
[20]
ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Bridging neural and symbolic reasoning: A dual-system framework for interpretable question answering , author=. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2025 , organization=
2025
-
[21]
TableMaster: A Recipe to Advance Table Understanding with Language Models
Tablemaster: A recipe to advance table understanding with language models , author=. arXiv preprint arXiv:2501.19378 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
arXiv preprint arXiv:2412.14146 , year=
ARTEMIS-DA: an advanced reasoning and transformation engine for multi-step insight synthesis in data analytics , author=. arXiv preprint arXiv:2412.14146 , year=
-
[23]
International Conference on Learning Representations , volume=
Critic: Large language models can self-correct with tool-interactive critiquing , author=. International Conference on Learning Representations , volume=
-
[24]
arXiv preprint arXiv:2308.00675 , year=
Tool documentation enables zero-shot tool-usage with large language models , author=. arXiv preprint arXiv:2308.00675 , year=
-
[25]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Creator: Tool creation for disentangling abstract and concrete reasoning of large language models , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[26]
arXiv preprint arXiv:2505.23667 , year=
Fortune: Formula-driven reinforcement learning for symbolic table reasoning in language models , author=. arXiv preprint arXiv:2505.23667 , year=
-
[27]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[28]
Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks , author=. arXiv preprint arXiv:2211.12588 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Forty-first international conference on machine learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first international conference on machine learning , year=
-
[31]
Advances in neural information processing systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in neural information processing systems , volume=
-
[32]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[33]
Proceedings of the 2022 conference on empirical methods in natural language processing , pages=
Convfinqa: Exploring the chain of numerical reasoning in conversational finance question answering , author=. Proceedings of the 2022 conference on empirical methods in natural language processing , pages=
2022
-
[34]
TAT-QA: A question answering benchmark on a hybrid of tabular and textual content in finance , author=. Proceedings of the 59th annual meeting of the Association for Computational Linguistics and the 11th international joint conference on natural language processing (volume 1: long papers) , pages=
-
[35]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Docfinqa: A long-context financial reasoning dataset , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[36]
arXiv preprint arXiv:2502.08127 , year=
Fino1: On the transferability of reasoning-enhanced llms and reinforcement learning to finance , author=. arXiv preprint arXiv:2502.08127 , year=
-
[37]
Advances in Neural Information Processing Systems , volume=
Finben: A holistic financial benchmark for large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
arXiv preprint arXiv:2306.05443 , year=
Pixiu: A large language model, instruction data and evaluation benchmark for finance , author=. arXiv preprint arXiv:2306.05443 , year=
-
[39]
B iz B ench: A Quantitative Reasoning Benchmark for Business and Finance
Krumdick, Michael and Koncel-Kedziorski, Rik and Lai, Viet Dac and Reddy, Varshini and Lovering, Charles and Tanner, Chris. B iz B ench: A Quantitative Reasoning Benchmark for Business and Finance. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.acl-long.452
-
[40]
arXiv preprint arXiv:2506.08726 , year=
Improved LLM agents for financial document question answering , author=. arXiv preprint arXiv:2506.08726 , year=
-
[41]
Proceedings of the Nineteenth ACM International Conference on Web Search and Data Mining , pages =
Jiang, Chuang and Cheng, Mingyue and Tao, Xiaoyu and Mao, Qingyang and Ouyang, Jie and Liu, Qi , title =. Proceedings of the Nineteenth ACM International Conference on Web Search and Data Mining , pages =. 2026 , isbn =. doi:10.1145/3773966.3777932 , abstract =
-
[42]
Tang, Zichen and E, Haihong and Ma, Ziyan and He, Haoyang and Liu, Jiacheng and Yang, Zhongjun and Rong, Zihua and Li, Rongjin and Ji, Kun and Huang, Qing and Hu, Xinyang and Liu, Yang and Zheng, Qianhe. F inance R easoning: Benchmarking Financial Numerical Reasoning More Credible, Comprehensive and Challenging. Proceedings of the 63rd Annual Meeting of t...
-
[43]
arXiv preprint arXiv:2506.11442 , year=
ReVeal: Self-Evolving Code Agents via Reliable Self-Verification , author=. arXiv preprint arXiv:2506.11442 , year=
-
[44]
arXiv preprint arXiv:2504.20434 , year=
ARCS: Agentic Retrieval-Augmented Code Synthesis with Iterative Refinement , author=. arXiv preprint arXiv:2504.20434 , year=
-
[45]
Liu, Chenghao and Liu, Qian and Zhu, Ziqin and Fei, Hao and Mahanti, Aniket. D avid vs. Goliath: Cost-Efficient Financial QA via Cascaded Multi-Agent Reasoning. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.225
-
[46]
arXiv preprint arXiv:2511.07784 , year=
Can LLM Agents Really Debate? A Controlled Study of Multi-Agent Debate in Logical Reasoning , author=. arXiv preprint arXiv:2511.07784 , year=
-
[47]
arXiv preprint arXiv:2510.22967 , year=
MAD-Fact: A Multi-Agent Debate Framework for Long-Form Factuality Evaluation in LLMs , author=. arXiv preprint arXiv:2510.22967 , year=
-
[48]
Advances in Neural Information Processing Systems , volume=
Multi-agent debate for LLM judges with adaptive stability detection , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Debate4MATH: Multi-agent debate for fine-grained reasoning in math , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[50]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Code to think, think to code: A survey on code-enhanced reasoning and reasoning-driven code intelligence in llms , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[51]
Large language model agent in financial trading: A survey.arXiv preprint arXiv:2408.06361, 2024
Large language model agent in financial trading: A survey , author=. arXiv preprint arXiv:2408.06361 , year=
-
[52]
arXiv preprint arXiv:2602.02196 , year=
TIDE: Trajectory-based Diagnostic Evaluation of Test-Time Improvement in LLM Agents , author=. arXiv preprint arXiv:2602.02196 , year=
-
[53]
Zhang, Yunjia and Henkel, Jordan and Floratou, Avrilia and Cahoon, Joyce and Deep, Shaleen and Patel, Jignesh M. , title =. Proc. VLDB Endow. , month = apr, pages =. 2024 , issue_date =. doi:10.14778/3659437.3659452 , abstract =
-
[54]
arXiv preprint arXiv:2412.20138 , year=
Tradingagents: Multi-agents llm financial trading framework , author=. arXiv preprint arXiv:2412.20138 , year=
-
[55]
arXiv preprint arXiv:2507.14823 , year=
Finchart-bench: Benchmarking financial chart comprehension in vision-language models , author=. arXiv preprint arXiv:2507.14823 , year=
-
[56]
Advances in Neural Information Processing Systems , volume=
Fincon: A synthesized llm multi-agent system with conceptual verbal reinforcement for enhanced financial decision making , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
SheetBrain: A neuro-symbolic agent for accurate reasoning over complex and large spreadsheets , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.