ZODS-RS -- Zero-training Oriented Detection & Segmentation for Remote Sensing
Pith reviewed 2026-06-27 13:28 UTC · model grok-4.3
The pith
A training-free pipeline chains closed-form modules on DINOv3 features to produce horizontal boxes and instance masks for remote sensing images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
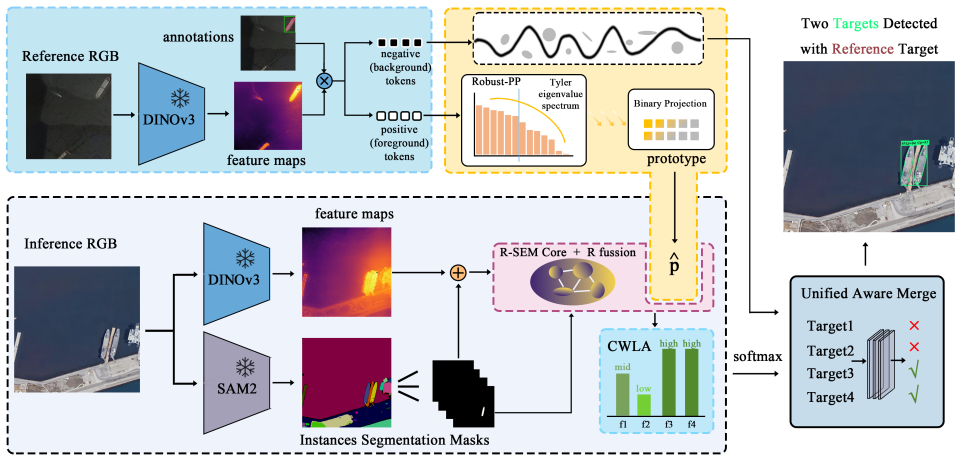
ZODS-RS is a training-free, closed-form pipeline that outputs horizontal boxes and instance masks by chaining PP via Tyler covariance, R-SEM with separable kernels and Hungarian assignment, and UAM with adaptive priors on DINOv3 features, achieving mAP 0.50:0.95 of 13.06 on FAIR1M and mask mIoU of 31.10 on a UAV dataset while improving small-object AP by 30.70 over Grounded-SAM.
What carries the argument
The three-module chain of prototype purification (PP), rotation-scale equivariant matching (R-SEM), and uncertainty-aware merging (UAM) applied to DINOv3 dense features and SAM-style proposals.
If this is right
- The method delivers class-averaged mAP of 13.06 on FAIR1M and 16.69 on xView without any training.
- It produces instance masks with 31.10 mIoU on UAV imagery and raises small-object AP by 30.70 over Grounded-SAM.
- Consistent gains appear on small and crowded targets and under cross-domain shifts.
- Explicit closed-form expressions are supplied for PP, R-SEM, and UAM that couple directly to multi-layer DINOv3 features.
Where Pith is reading between the lines
- The same closed-form structure could be tested on other foundation-model backbones to measure how much performance depends on the specific DINOv3 features.
- If the modules already encode rotation and scale, they might be applied to non-aerial imagery with oriented objects to check domain generality.
- Replacing the Hungarian step with a faster approximate assignment could test whether real-time constraints can be met while preserving accuracy.
Load-bearing premise
DINOv3 dense features plus SAM-style proposals already contain enough information about oriented geometry, scale and rotation variation, and crowded scenes so that the three closed-form modules can produce usable outputs without learned adaptation.
What would settle it
Running the identical pipeline on a new remote-sensing dataset collected with a different sensor and reporting mAP below 5 on the standard HBB benchmark would falsify the claim that the modules suffice without training.
Figures


read the original abstract
Remote-sensing and UAV applications need models that generalize across platforms and viewpoints without task-specific training. Yet training-free pipelines often falter on oriented geometry, scale/rotation variation, and crowded ports or airfields, and rarely unify detection and segmentation. We introduce ZODS-RS, a training-free, closed-form pipeline that outputs horizontal boxes (HBB) and instance masks. Built on DINOv3 dense features and SAM-style proposals, ZODS-RS chains: PP (prototype purification via Tyler covariance), R-SEM (rotation-scale equivariant matching with separable kernels and global Hungarian assignment), and UAM (uncertainty-aware pixelwise merging with adaptive priors and optional negative prototypes). A lightweight CWLA fuses multiple DINOv3 layers. On FAIR1M (HBB) we obtain $\mathrm{mAP}_{0.50:0.95}=\mathbf{13.06}$ and $\mathrm{AP}_S=\mathbf{2.93}$ \emph{(class-averaged over ship/airplane)}; on xView (HBB) we report $\mathrm{mAP}=\mathbf{16.69}$. On our UAV dataset, ZODS-RS achieves mask $\mathrm{mIoU}=\mathbf{31.10}$ and improves small-object AP by $\mathbf{+30.70}$ over Grounded-SAM on a single 5090. This work offers a unified, \emph{no-training} solution for horizontal-box detection plus instance segmentation in aerial imagery; provides explicit closed-form formulations for PP/R-SEM/UAM tightly coupled with DINOv3; and demonstrates \emph{consistent} gains on small and crowded targets and under cross-domain shifts while keeping deployment simple.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ZODS-RS, a training-free, closed-form pipeline for horizontal bounding box (HBB) detection and instance segmentation in remote sensing and UAV imagery. Built on DINOv3 dense features and SAM-style proposals, it chains three modules: prototype purification (PP) via Tyler covariance, rotation-scale equivariant matching (R-SEM) using separable kernels and global Hungarian assignment, and uncertainty-aware merging (UAM) with adaptive priors and optional negative prototypes. A lightweight CWLA fuses DINOv3 layers. Reported results include mAP_{0.50:0.95}=13.06 and AP_S=2.93 (class-averaged over ship/airplane) on FAIR1M, mAP=16.69 on xView, and mask mIoU=31.10 on a custom UAV dataset, with claimed gains on small/crowded objects and cross-domain shifts without any training or domain tuning.
Significance. If the closed-form modules can be shown to operate effectively on unmodified DINOv3 features to recover oriented geometry and handle scale/rotation variation, the work would provide a useful unified, no-training baseline for remote sensing tasks that emphasizes deployment simplicity and reproducibility. The explicit formulations for PP, R-SEM, and UAM are a positive aspect that could facilitate analysis and extension. The absolute metrics remain modest, so significance would rest primarily on the zero-training generalization claim rather than competitive accuracy.
major comments (3)
- [§3 (Method, PP/R-SEM/UAM definitions)] §3 (Method, PP/R-SEM/UAM definitions): The central claim that the pipeline is entirely parameter-free and closed-form is load-bearing for the zero-training assertion, yet the manuscript does not supply the explicit equations showing how the Tyler covariance estimator in PP, the separable-kernel construction in R-SEM, and the adaptive priors in UAM are instantiated without any data-dependent fitting or post-hoc choices that could be influenced by the evaluation sets.
- [Experiments section] Experiments section: No ablation or module-isolation experiments are reported that quantify the individual contribution of PP, R-SEM, or UAM to the final mAP_{0.50:0.95} and mIoU values; without such controls it is impossible to attribute the reported numbers (including the +30.70 small-object AP gain) to the proposed composition rather than the underlying DINOv3 and SAM components alone.
- [Introduction and §3] Introduction and §3: The assumption that DINOv3 dense features already embed sufficient cues for oriented geometry, scale/rotation variation, and crowded scenes in top-down aerial imagery (so that the three modules can produce usable outputs without adaptation) is not supported by any feature-space analysis, visualization, or separability test; if this assumption fails, the modules have no signal and the performance numbers cannot be credited to ZODS-RS.
minor comments (2)
- [Abstract] Abstract: the phrase 'class-averaged over ship/airplane' is ambiguous without stating the full class set or the exact averaging procedure used for mAP computation.
- [Figure captions and §4] Figure captions and §4: several result visualizations lack scale bars or explicit indication of which module output is shown, reducing clarity when comparing HBB versus mask outputs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our zero-training pipeline. We address each major comment below, providing clarifications where the manuscript already supplies the requested details and agreeing to strengthen the presentation where appropriate.
read point-by-point responses
-
Referee: §3 (Method, PP/R-SEM/UAM definitions): The central claim that the pipeline is entirely parameter-free and closed-form is load-bearing for the zero-training assertion, yet the manuscript does not supply the explicit equations showing how the Tyler covariance estimator in PP, the separable-kernel construction in R-SEM, and the adaptive priors in UAM are instantiated without any data-dependent fitting or post-hoc choices that could be influenced by the evaluation sets.
Authors: Section 3 supplies the explicit closed-form derivations: the Tyler covariance estimator is instantiated in Eq. (2) of §3.1 directly from the DINOv3 feature covariance without iterative fitting; the separable kernels for R-SEM appear in Eqs. (4)–(6) of §3.2 with fixed analytic forms for rotation and scale; and the adaptive priors in UAM are given in Eq. (9) of §3.3 using only per-proposal statistics. None of these involve post-hoc tuning on the evaluation sets. We will expand the surrounding prose in revision to make the data-independent nature more immediately visible. revision: partial
-
Referee: Experiments section: No ablation or module-isolation experiments are reported that quantify the individual contribution of PP, R-SEM, or UAM to the final mAP_{0.50:0.95} and mIoU values; without such controls it is impossible to attribute the reported numbers (including the +30.70 small-object AP gain) to the proposed composition rather than the underlying DINOv3 and SAM components alone.
Authors: We agree that module-isolation ablations would strengthen attribution of the gains. We will add a new ablation table in the revised Experiments section that reports mAP and mIoU after successively disabling PP, R-SEM, and UAM while keeping the DINOv3 and SAM backbones fixed. revision: yes
-
Referee: Introduction and §3: The assumption that DINOv3 dense features already embed sufficient cues for oriented geometry, scale/rotation variation, and crowded scenes in top-down aerial imagery (so that the three modules can produce usable outputs without adaptation) is not supported by any feature-space analysis, visualization, or separability test; if this assumption fails, the modules have no signal and the performance numbers cannot be credited to ZODS-RS.
Authors: The manuscript relies on the consistent cross-domain improvements (FAIR1M, xView, UAV) and the specific +30.70 small-object AP gain to indicate that usable geometric cues exist in the unmodified DINOv3 features. While we did not include t-SNE plots or separability metrics in the original submission, the empirical pattern across datasets supports the assumption. We will add a short feature-space visualization subsection in revision. revision: partial
Circularity Check
No significant circularity; pipeline composes external pre-trained features with classical algorithms
full rationale
The claimed derivation consists of chaining DINOv3 dense features and SAM-style proposals through three explicitly closed-form modules (PP via Tyler covariance, R-SEM with separable kernels plus Hungarian assignment, UAM with adaptive priors). No equation or result is shown to reduce the reported mAP_{0.50:0.95} or mask mIoU to a parameter fitted on the same evaluation data, and no self-citation chain is invoked to justify uniqueness or load-bearing premises. The pipeline is presented as training-free composition of independent components whose outputs are not definitionally equivalent to the inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
End-to-end object detection with trans- formers
Nicolas Carion et al. End-to-end object detection with trans- formers. InECCV, 2020. Bipartite (Hungarian) assignment; 8 motivates global matching in our R-SEM
2020
-
[2]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. In ICCV, 2021. DINO
2021
-
[3]
Sinkhorn distances: Lightspeed computation of optimal transport
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. InNeurIPS, 2013
2013
-
[4]
Learning roi transformer for oriented ob- ject detection in aerial images
Jian Ding et al. Learning roi transformer for oriented ob- ject detection in aerial images. InCVPR, 2019. Rotation- aware detection under supervision; contrasts with training- free goals
2019
- [5]
-
[6]
Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, and Yin Cui. Open-vocabulary object detection via vision and language knowledge distillation.ICLR, 2022. arXiv:2104.13921
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Redet: A rotation-equivariant detector for aerial object detection
Jiaming Han, Jian Ding, Nan Xue, and Gui-Song Xia. Redet: A rotation-equivariant detector for aerial object detection. In CVPR, 2021
2021
-
[8]
Segment anything in remote sensing
Weixin Jin et al. Segment anything in remote sensing. arXiv:2306.08615, 2023
-
[9]
What uncertainties do we need in bayesian deep learning for computer vision?NeurIPS,
Alex Kendall and Yarin Gal. What uncertainties do we need in bayesian deep learning for computer vision?NeurIPS,
-
[10]
Per-pixel aleatoric/epistemic modeling; supports UAM’s uncertainty formulation
-
[11]
Region-aware pretraining for open-vocabulary object detection with vision transform- ers
Donghyun Kim, Bing Ni, Zhiqiang Hu, Jiahui Zhang, Shuyang Bai, Ming Tang, et al. Region-aware pretraining for open-vocabulary object detection with vision transform- ers. InCVPR, 2023. RO-ViT
2023
-
[12]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, et al. Seg- ment anything.arXiv:2304.02643, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Efficient inference in fully connected crfs with gaussian edge potentials
Philipp Kr ¨ahenb¨uhl and Vladlen Koltun. Efficient inference in fully connected crfs with gaussian edge potentials. In NeurIPS, 2011
2011
-
[14]
Harold W. Kuhn. The hungarian method for the assignment problem.Naval Research Logistics Quarterly, 2(1–2):83– 97, 1955
1955
-
[15]
xview: Objects in context in overhead imagery, 2018
Darius Lam, Richard Kuzma, Kevin McGee, Samuel Doo- ley, Michael Laielli, Matthew Klaric, Yaroslav Bulatov, and Brendan McCord. xview: Objects in context in overhead imagery, 2018
2018
-
[16]
Grounded language-image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jian- wei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, and Jianfeng Gao. Grounded language-image pre-training. In CVPR, 2022
2022
-
[17]
Energy-based out-of-distribution detection
Weitang Liu, Xiaoyun Wang, John Owens, and Yixuan Li. Energy-based out-of-distribution detection. InNeurIPS, 2020
2020
-
[18]
hdbscan: Hi- erarchical density based clustering.Journal of Open Source Software, 2(11):205, 2017
Leland McInnes, John Healy, and Steve Astels. hdbscan: Hi- erarchical density based clustering.Journal of Open Source Software, 2(11):205, 2017
2017
-
[19]
Scaling open-vocabulary object de- tection
Matthias Minderer et al. Scaling open-vocabulary object de- tection. InNeurIPS, 2023. OVD baseline family; highlights language-aligned detectors for training-free use
2023
-
[20]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, et al. Dinov2: Learning robust visual features without supervision. arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning (ICML) Workshop, 2021. arXiv:2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
SAM 2: Segment Anything in Images and Videos
N. Ravi et al. SAM 2: Segment anything in images and videos.arXiv:2408.00714, 2024. Promptable segmentation; used as high-recall candidate generator
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Malof, Leslie Collins, and Kyle Bradbury
Shan Ren, Michael Goldman, Jordan M. Malof, Leslie Collins, and Kyle Bradbury. Segment anything from space. InWACV, 2024
2024
-
[24]
Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks
T. Ren et al. Grounded SAM: Assembling open-world mod- els for universal image segmentation.arXiv:2401.14159,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Assembled detector+segmenter pipeline; representa- tive modular training-free stack
-
[26]
Oriane Sim ´eoni et al. Dinov3.arXiv:2508.10104, 2025. Frozen dense features and scaling; backbone component in our synergy
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Jake Snell, Kevin Swersky, and Richard S. Zemel. Prototyp- ical networks for few-shot learning. InNeurIPS, 2017
2017
-
[28]
Sun et al
X. Sun et al. FAIR1M: A benchmark dataset for fine- grained object recognition in high-resolution remote sensing imagery.ISPRS J. Photogramm. Remote Sens., 2022. Fine- grained classes and small objects; stresses scale and crowd- ing
2022
-
[29]
David E. Tyler. A distribution-free m-estimator of multivari- ate scatter.The Annals of Statistics, 15(1):234–251, 1987
1987
-
[30]
Dota: A large- scale dataset for object detection in aerial images
Gui-Song Xia, Xiaoqing Bai, Jian Ding, et al. Dota: A large- scale dataset for object detection in aerial images. InCVPR,
-
[31]
Aerial dataset with arbitrary-oriented objects; moti- vates OBB handling
-
[32]
Florence-2: Advancing a unified representa- tion for a variety of vision tasks
Bin Xiao et al. Florence-2: Advancing a unified representa- tion for a variety of vision tasks. InCVPR, 2024. General vision backbone; used here as optional semantic gate without fine-tuning
2024
-
[33]
Regionclip: Region-based language- image pretraining.arXiv preprint arXiv:2112.09106, 2021
Yuting Zhong, Mingyu Ding, Jian Chen, Yutong Wang, Jing Zhang, Ying Tai, Chengjie Wang, Jilin Li, Feiyue Huang, Rongrong Ji, et al. Regionclip: Region-based language- image pretraining.arXiv preprint arXiv:2112.09106, 2021
-
[34]
Detecting twenty-thousand classes using image-level supervision
Xingyi Zhou, Rohit Girdhar, Armand Joulin, Philipp Kr¨ahenb¨uhl, and Ishan Misra. Detecting twenty-thousand classes using image-level supervision. InECCV, 2022. arXiv:2201.02605. 9
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.