Why Do Time Series Models Need Long Context Windows?
Pith reviewed 2026-06-28 15:49 UTC · model grok-4.3
The pith
Time series forecasting models require input windows longer than the processes' memory length to reach minimal error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
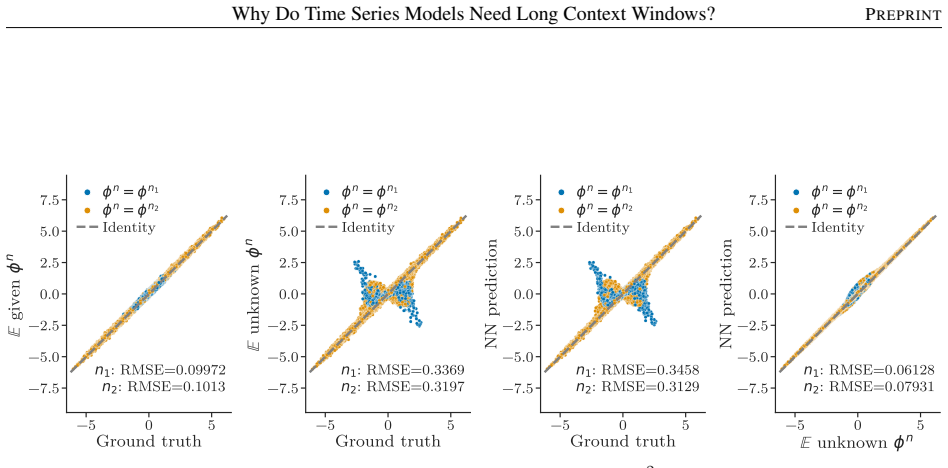
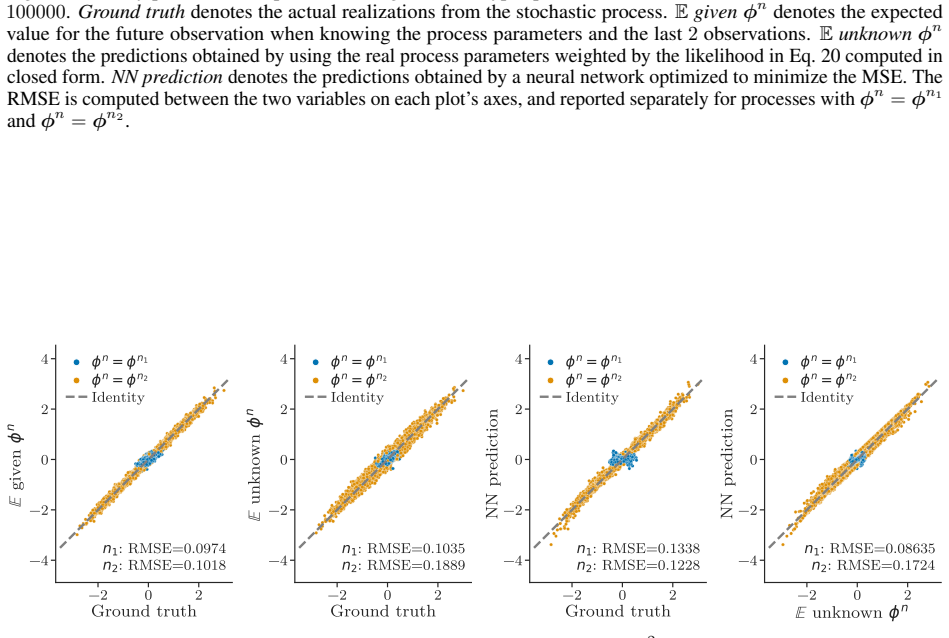
Forecasting groups of time series involves generative process identification, inferring the specific process generating the input sequence, and conditional forecasting. Optimal predictions are an average over plausible data-generating processes weighted by their likelihood given the input window. Even for processes with memory length P, an input window size strictly larger than P is necessary to achieve the minimum attainable error.
What carries the argument
The decomposition of the forecasting task into generative process identification (GPI) and conditional forecasting (CF), where GPI reduces uncertainty about the active process.
If this is right
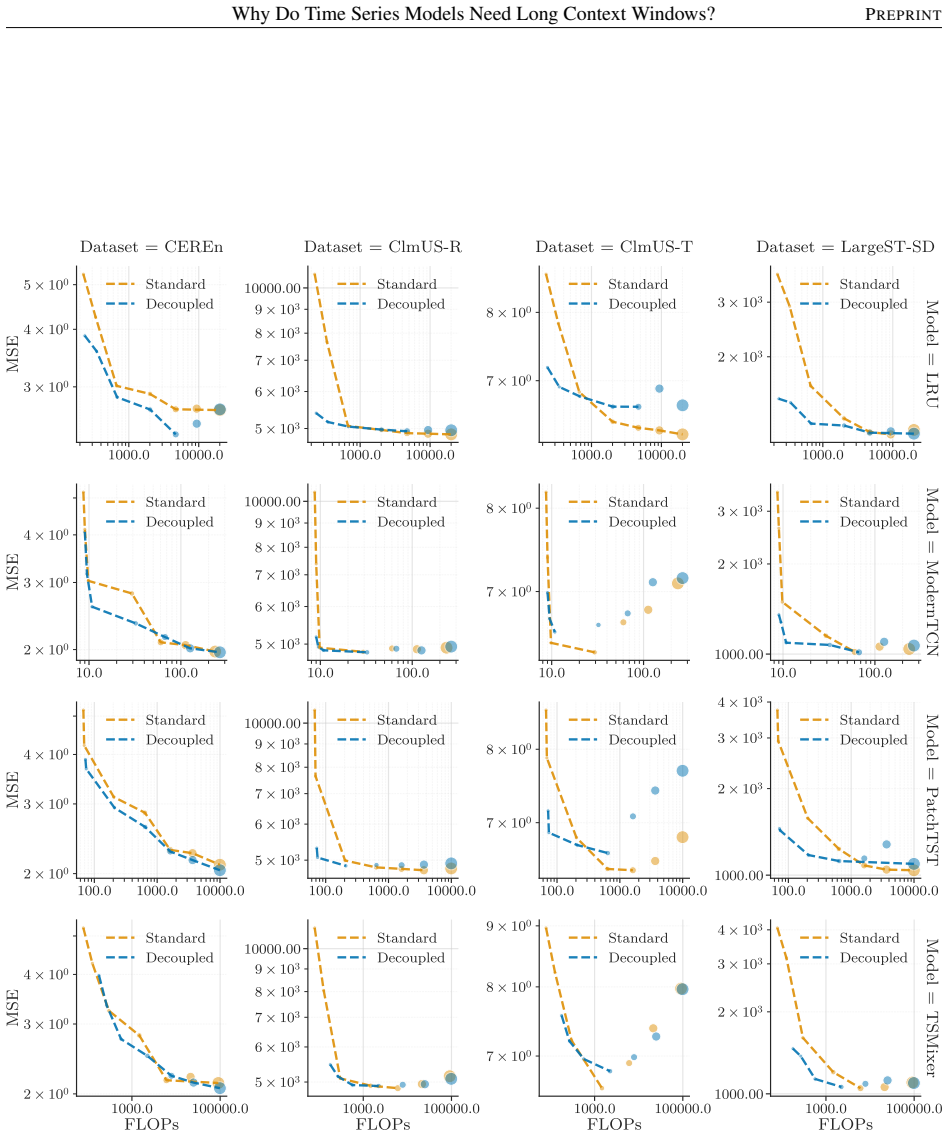
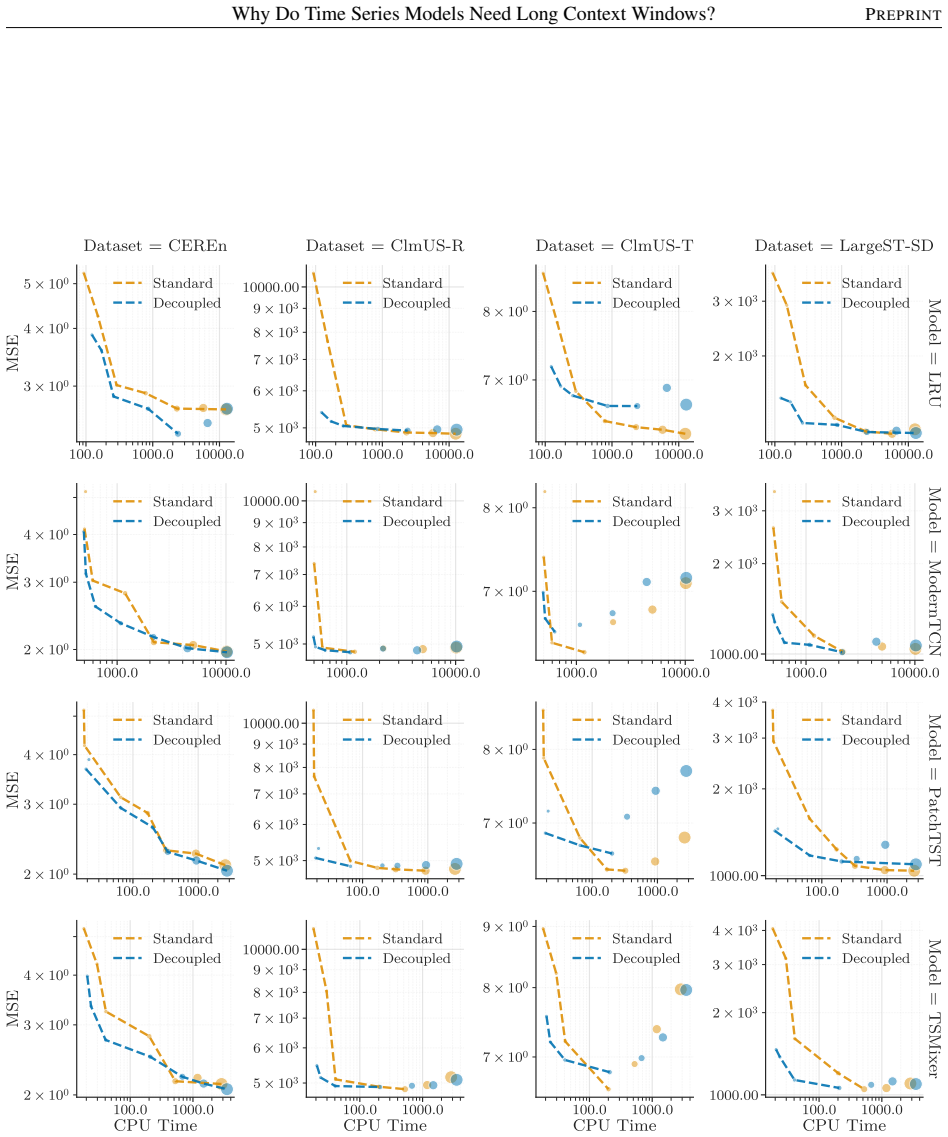
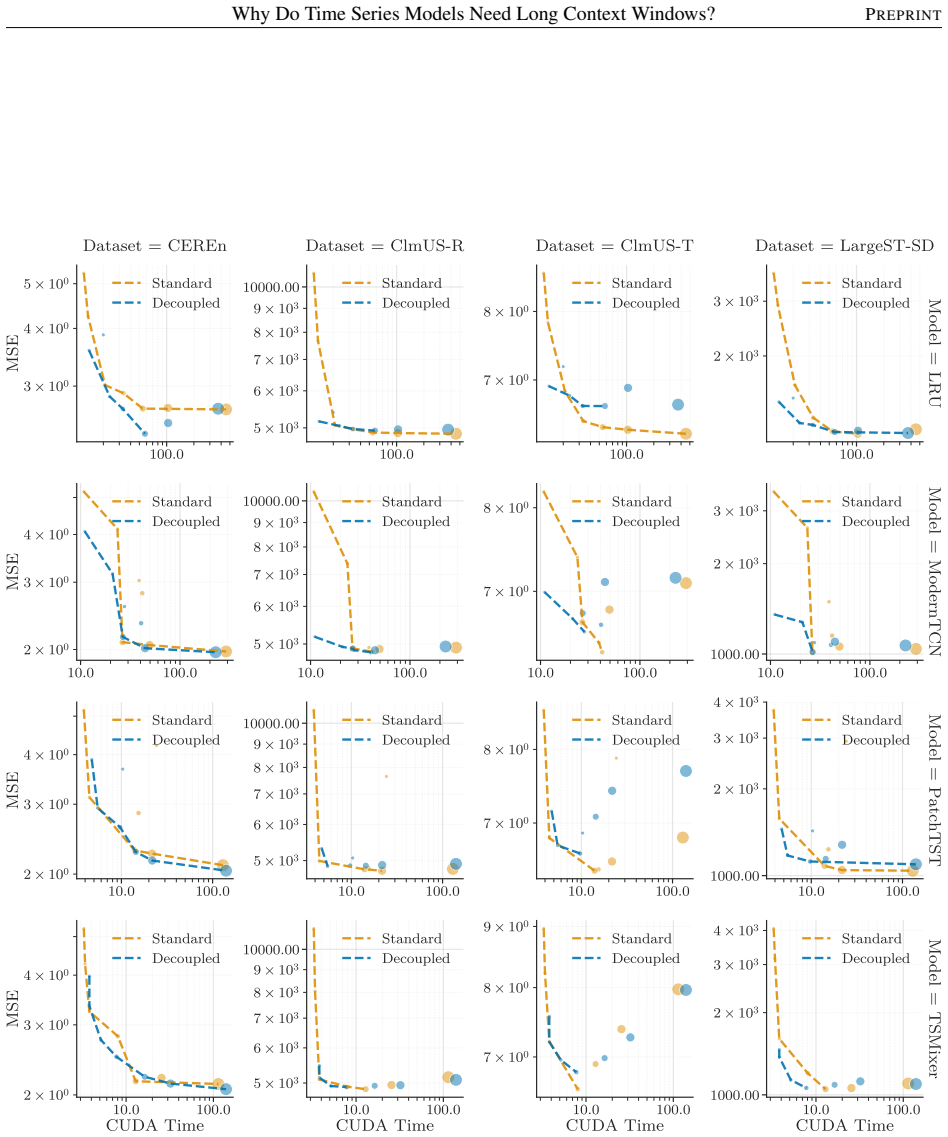
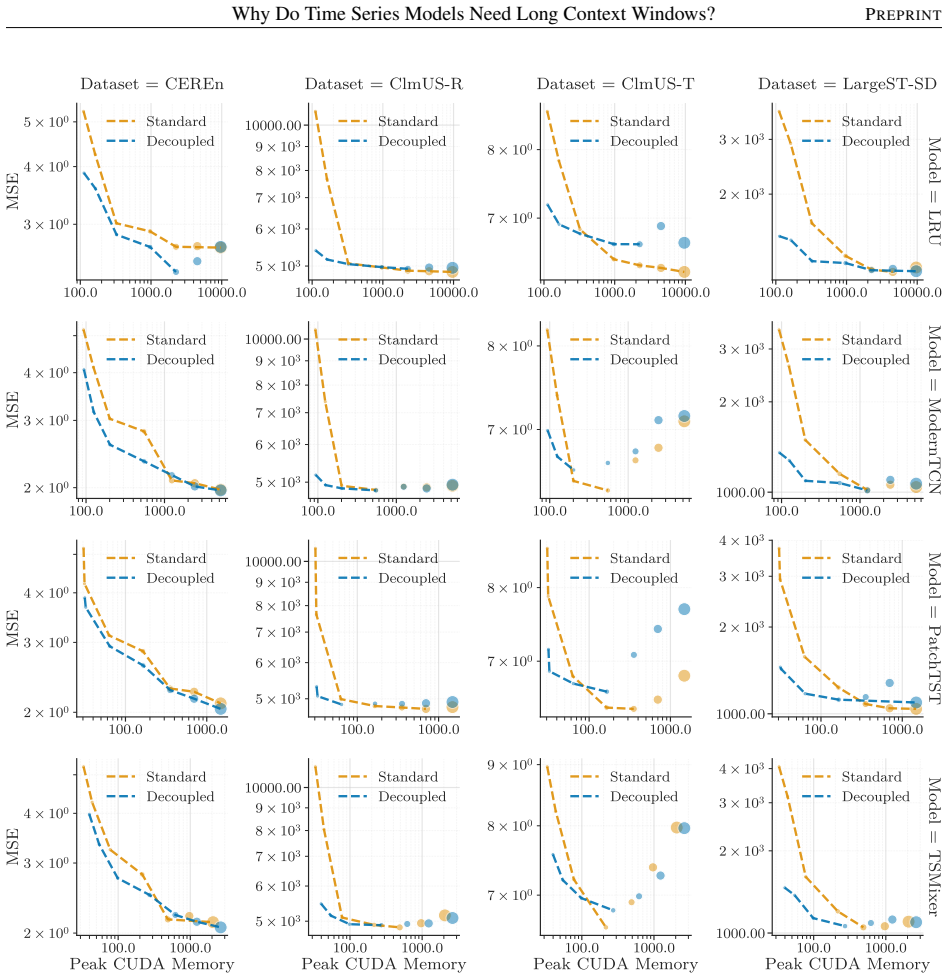
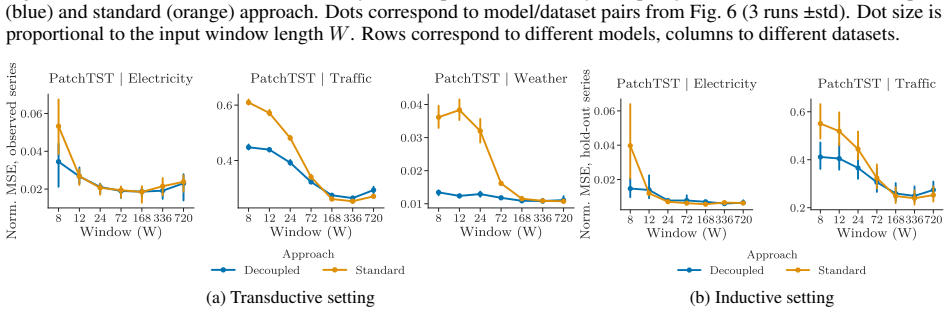
- Decoupling GPI from CF improves computational scalability without compromising accuracy.
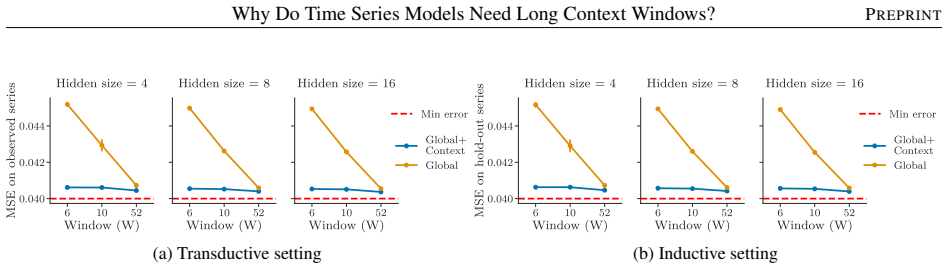
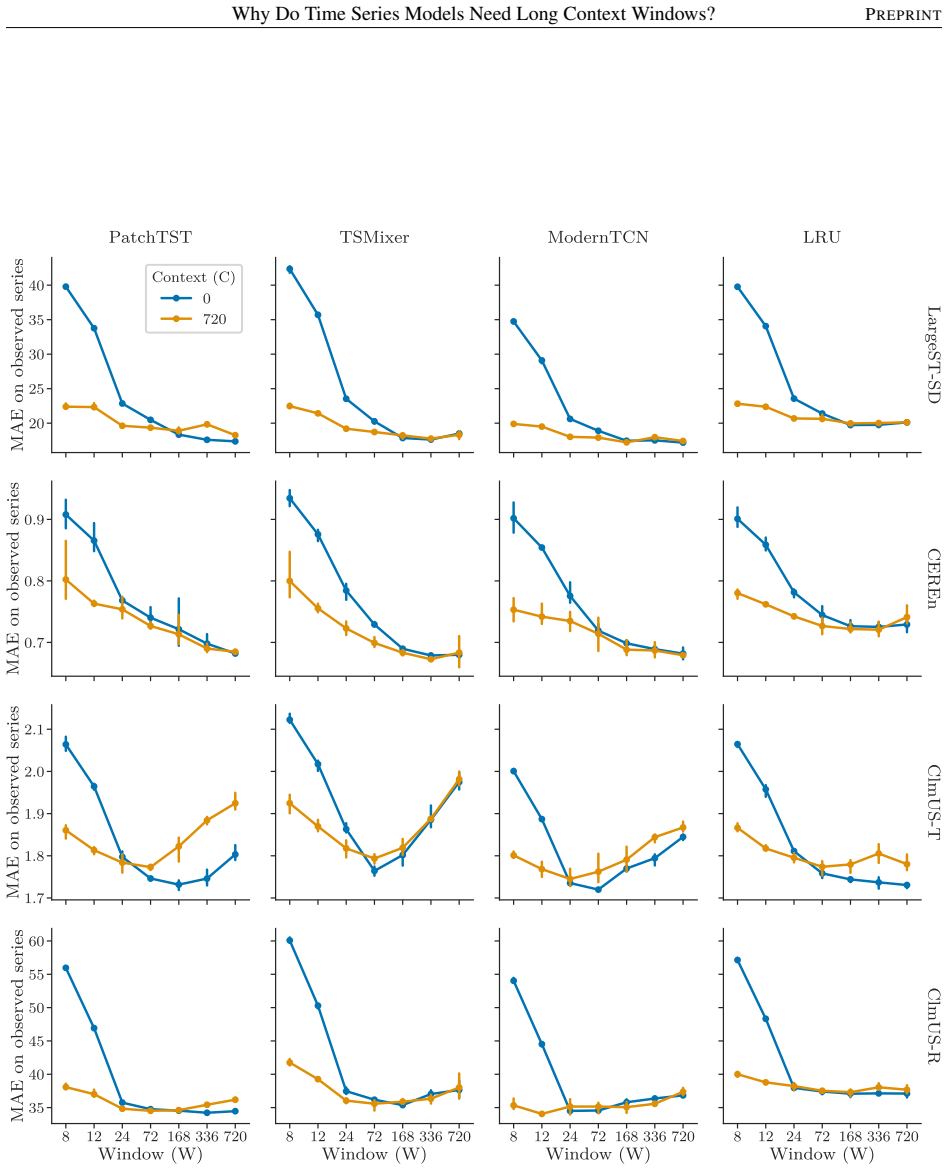
- Window sizes must be strictly larger than the memory length P to minimize error.
- The benefit of long context holds for collections of finite-memory processes.
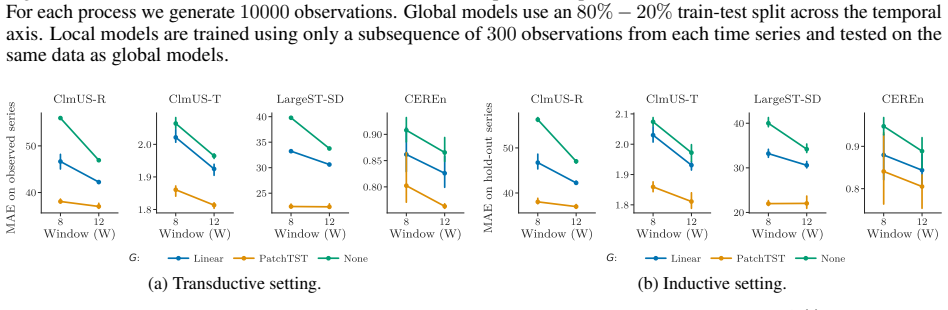
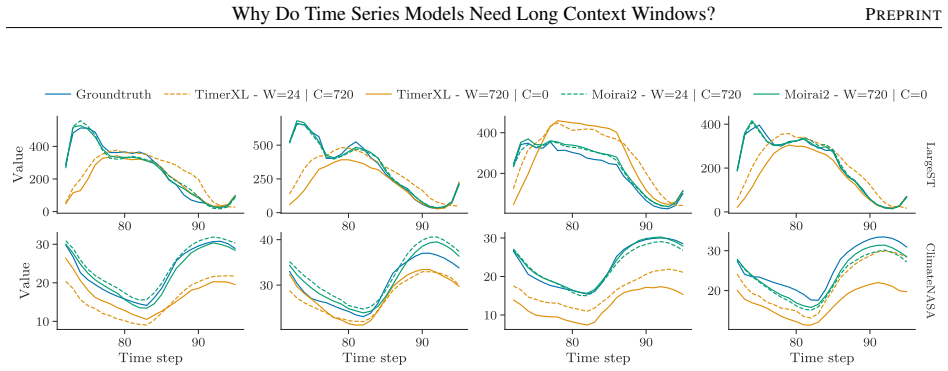
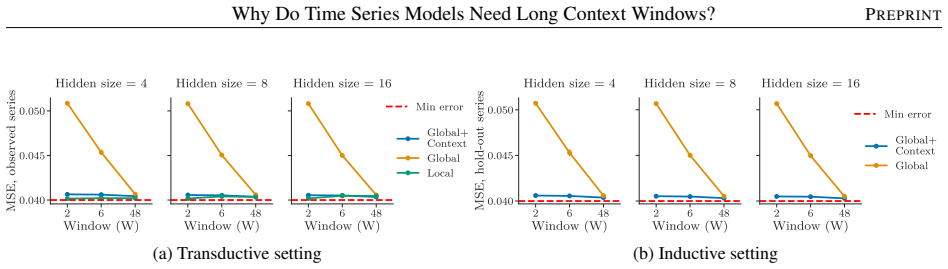
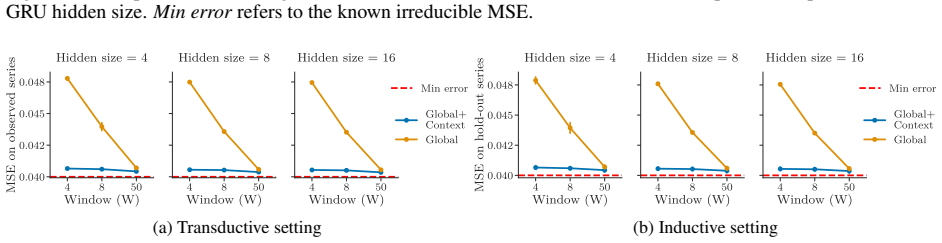
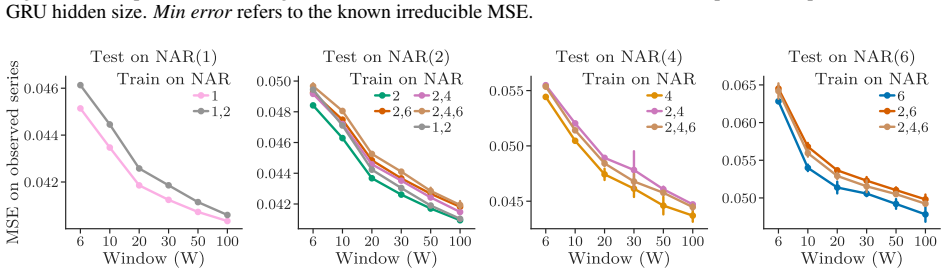
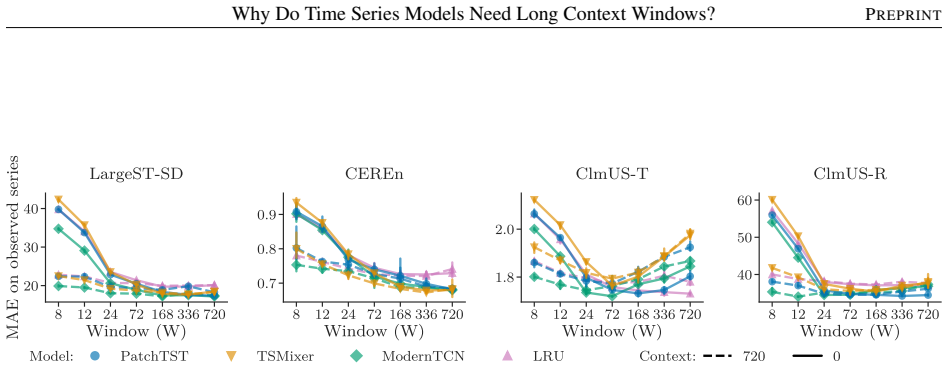
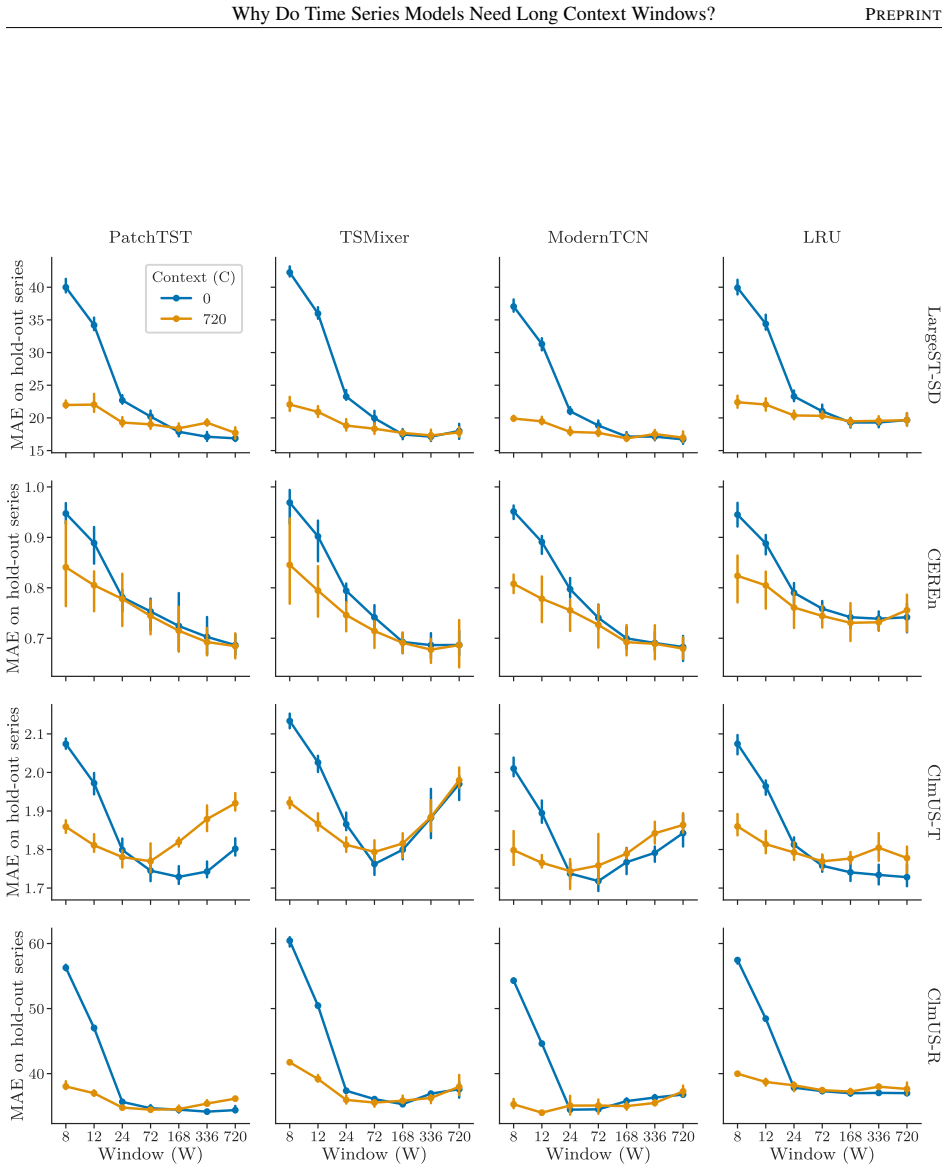
- Experiments on synthetic and real-world data support the need for longer windows to resolve process identity.
Where Pith is reading between the lines
- Models could explicitly estimate the posterior over processes to achieve the optimal average forecast.
- The requirement for extra context beyond memory length may generalize to other sequence modeling tasks with multiple possible sources.
- Designing architectures that first classify the process type before forecasting could be more efficient.
Load-bearing premise
That the best prediction is the average over possible processes weighted by how well they explain the input window, and that longer windows reduce uncertainty about the active process.
What would settle it
An experiment on a mixture of processes each with memory P where the prediction error with window length P equals the error with windows longer than P.
Figures

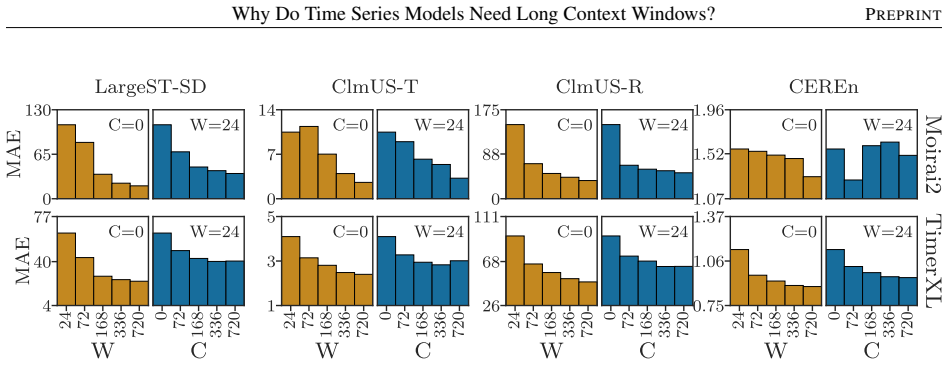

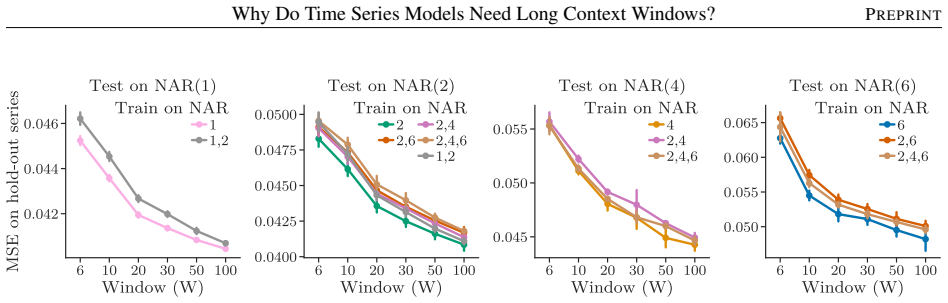
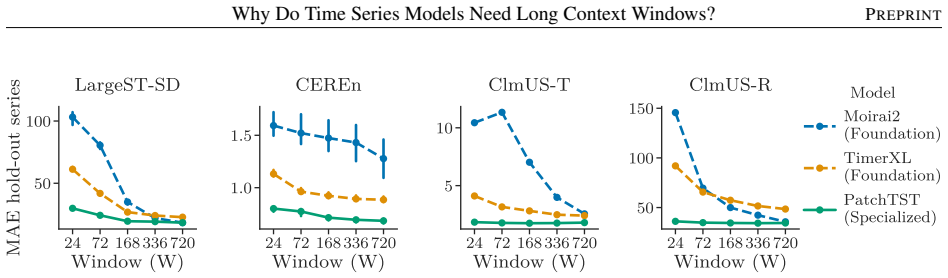
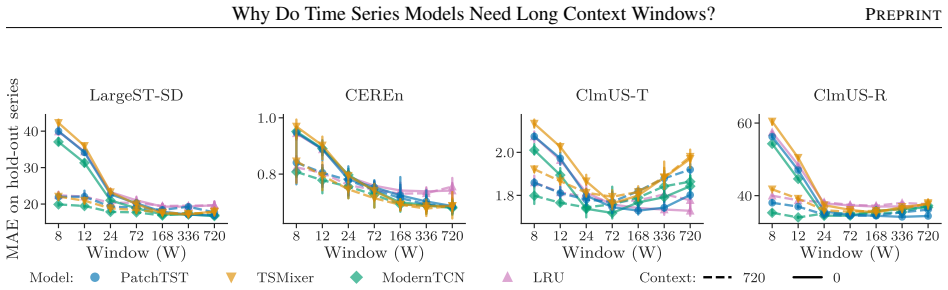
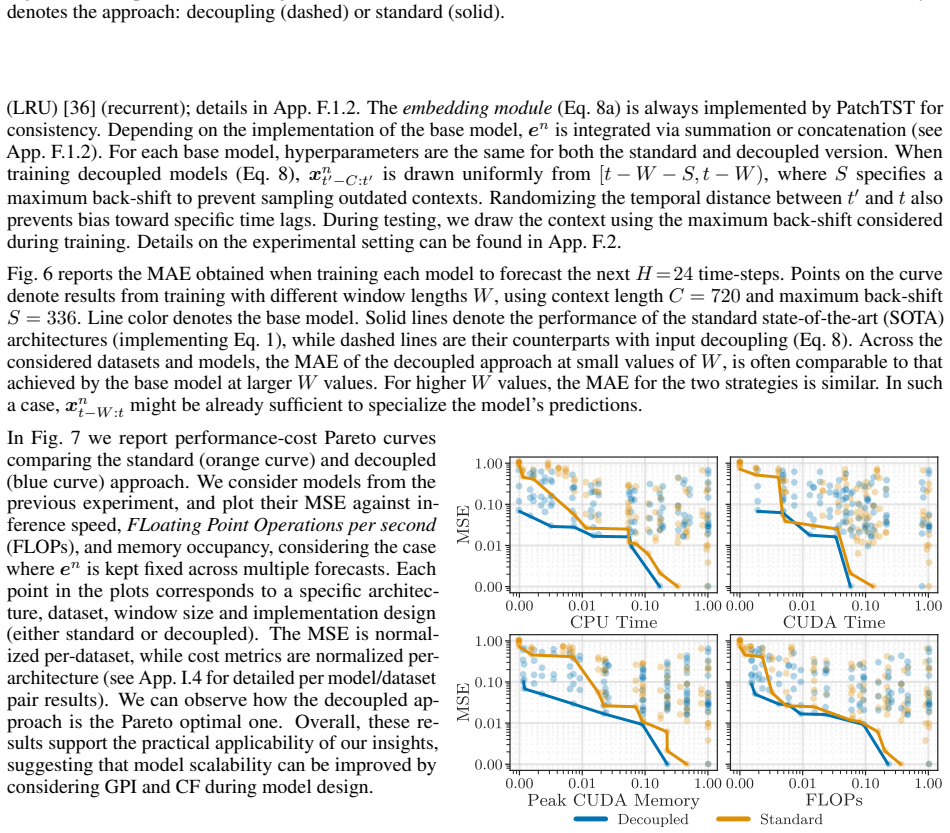
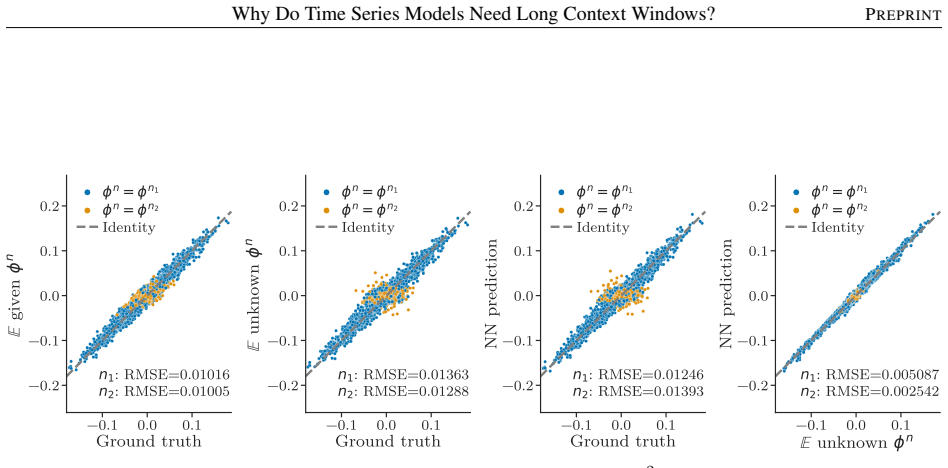
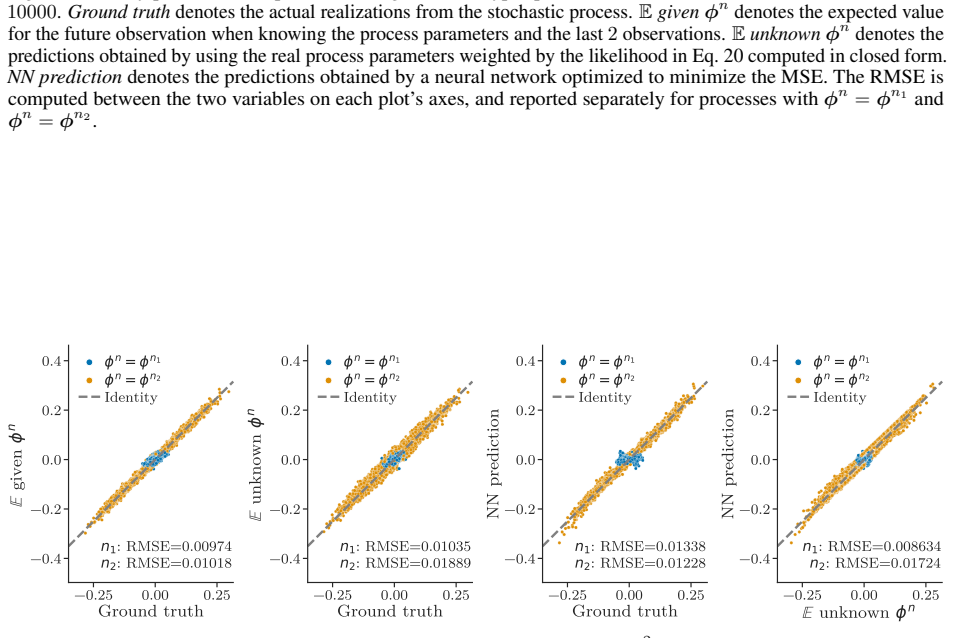
read the original abstract
Modern deep learning models for forecasting groups of time series rely on increasingly longer observation windows. However, the benefit of increasing the window size is often simply attributed to capturing long-range dependencies, and broader discussion on how global forecasting models leverage input observations has been limited. In this paper, we show that forecasting groups of time series involves two objectives: (i) generative process identification (GPI), i.e., inferring the specific process generating the input sequence, and (ii) conditional forecasting (CF), i.e., predicting future values given input observations. From this perspective, optimal predictions can be interpreted as an average over plausible data-generating processes, weighted by their likelihood given the input window. This suggests another explanation for the benefits of long context windows: they reduce the uncertainty about which specific process is generating the input time series during operation. We prove that even for processes with memory length $P$, an input window size strictly larger than $P$ is necessary to achieve the minimum attainable error. Finally, we show how decoupling GPI and CF can improve computational scalability without compromising accuracy. Experiments on synthetic and real-world data validate our insights and their relevance for designing forecasting architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that forecasting groups of time series involves two objectives: generative process identification (GPI), i.e., inferring the specific process generating the input sequence, and conditional forecasting (CF). Optimal predictions are interpreted as averages over plausible data-generating processes weighted by their likelihood given the input window. It proves that even for processes with memory length P, an input window size strictly larger than P is necessary to achieve the minimum attainable error. It further shows that decoupling GPI and CF can improve computational scalability without compromising accuracy, with validation on synthetic and real-world data.
Significance. If the central result holds, the work supplies a theoretical explanation for the empirical value of long context windows in global time-series models that is distinct from long-range dependence capture, namely reduction of uncertainty over process identity. The attempted proof, the decoupling proposal, and the dual synthetic/real-data validation are explicit strengths that would be credited if the derivation is complete and the experiments are reproducible.
major comments (2)
- [Theoretical results section (the proof referenced in the abstract)] The proof that a window strictly larger than P is required for minimum attainable error is the load-bearing claim. The manuscript must supply the full derivation (including the precise definition of minimum attainable error, the measure over processes, and the conditions under which the posterior-average interpretation equals the Bayes-optimal predictor) so that the result can be verified rather than asserted at the level of the abstract.
- [Introduction and theoretical framework] The weakest modeling assumption—that optimal forecasts are exactly the likelihood-weighted mixture over plausible processes—underpins both the necessity proof and the GPI/CF distinction. The paper should state whether this holds only for squared-error loss, only for finite process classes, or more generally, and should indicate what happens when the model class is misspecified.
minor comments (2)
- [Abstract] The abstract states the main claims clearly but does not name the concrete process class (e.g., order-P Markov chains) used in the necessity proof; adding this would help readers assess scope.
- [Experiments] Experimental sections should report the exact procedure used to generate the synthetic data that isolates the GPI effect and the quantitative improvement obtained by the proposed decoupling.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The major comments correctly identify areas where the theoretical presentation requires expansion for verifiability and precision. We address each point below and will revise the manuscript to incorporate the requested clarifications and full derivations.
read point-by-point responses
-
Referee: [Theoretical results section (the proof referenced in the abstract)] The proof that a window strictly larger than P is required for minimum attainable error is the load-bearing claim. The manuscript must supply the full derivation (including the precise definition of minimum attainable error, the measure over processes, and the conditions under which the posterior-average interpretation equals the Bayes-optimal predictor) so that the result can be verified rather than asserted at the level of the abstract.
Authors: We agree that the full derivation must be supplied for independent verification. The current manuscript presents the key steps at a high level in the theoretical results section but omits some intermediate lemmas and explicit definitions. In the revised version we will expand this section to include: (i) the definition of minimum attainable error as the Bayes risk (expected squared error) under the posterior over the finite process class; (ii) the prior measure as a probability mass function on the process class; and (iii) the proof that the posterior-weighted average equals the Bayes-optimal predictor under squared loss. We will also add the complete argument showing why any window of length exactly P leaves positive posterior mass on multiple processes, preventing attainment of the minimum error. revision: yes
-
Referee: [Introduction and theoretical framework] The weakest modeling assumption—that optimal forecasts are exactly the likelihood-weighted mixture over plausible processes—underpins both the necessity proof and the GPI/CF distinction. The paper should state whether this holds only for squared-error loss, only for finite process classes, or more generally, and should indicate what happens when the model class is misspecified.
Authors: We appreciate this observation. The equivalence between the posterior-weighted predictor and the Bayes-optimal forecast holds specifically for squared-error loss and finite process classes equipped with a known prior; we will state these scope conditions explicitly in the revised introduction and theoretical framework. Under model misspecification (true process outside the class), GPI selects the maximum-likelihood process within the class and CF proceeds conditionally on that choice, but optimality is no longer guaranteed. We will add a short discussion of this limitation, noting that the necessity result for window length > P continues to apply in an approximate sense when misspecification is not severe. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper advances a theoretical argument and proof that window size must exceed memory length P to minimize error, grounded in the distinction between generative process identification and conditional forecasting. This follows from standard properties of Markov processes (a single sequence of length P can arise from multiple processes) and the resulting mixture predictor, without reducing to any fitted parameter, self-defined quantity, or load-bearing self-citation chain. The provided abstract and reader analysis confirm the derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Time series data are generated by one of a family of processes possessing finite memory length P that remain distinguishable given sufficiently long observations.
Reference graph
Works this paper leans on
-
[1]
Autoformer: Decomposition transformers with auto- correlation for long-term series forecasting.Advances in neural information processing systems, 34:22419–22430, 2021
Haixu Wu, Jiehui Xu, Jianmin Wang, and Mingsheng Long. Autoformer: Decomposition transformers with auto- correlation for long-term series forecasting.Advances in neural information processing systems, 34:22419–22430, 2021
2021
-
[2]
Deep learning for time series forecasting: Tutorial and literature survey.ACM Computing Surveys, 55(6):1–36, 2022
Konstantinos Benidis, Syama Sundar Rangapuram, Valentin Flunkert, Yuyang Wang, Danielle Maddix, Caner Turkmen, Jan Gasthaus, Michael Bohlke-Schneider, David Salinas, Lorenzo Stella, et al. Deep learning for time series forecasting: Tutorial and literature survey.ACM Computing Surveys, 55(6):1–36, 2022
2022
-
[3]
Deep time series models: A comprehensive survey and benchmark.arXiv preprint arXiv:2407.13278, 2024
Yuxuan Wang, Haixu Wu, Jiaxiang Dong, Yong Liu, Mingsheng Long, and Jianmin Wang. Deep time series models: A comprehensive survey and benchmark.arXiv preprint arXiv:2407.13278, 2024
Pith/arXiv arXiv 2024
-
[4]
Some recent advances in forecasting and control.Journal of the Royal Statistical Society
George EP Box and Gwilym M Jenkins. Some recent advances in forecasting and control.Journal of the Royal Statistical Society. Series C (Applied Statistics), 17(2):91–109, 1968
1968
-
[5]
Jan G. De Gooijer and Rob J. Hyndman. 25 years of time series forecasting.International Journal of Forecasting, 22(3):443–473, 2006. ISSN 0169-2070. doi:https://doi.org/10.1016/j.ijforecast.2006.01.001. URL https:// www.sciencedirect.com/science/article/pii/S0169207006000021. Twenty five years of forecasting
-
[6]
Recurrent neural networks for time series forecasting: Current status and future directions.International Journal of Forecasting, 37(1):388–427, 2021
Hansika Hewamalage, Christoph Bergmeir, and Kasun Bandara. Recurrent neural networks for time series forecasting: Current status and future directions.International Journal of Forecasting, 37(1):388–427, 2021
2021
-
[7]
Deepar: Probabilistic forecasting with autoregressive recurrent networks.International journal of forecasting, 36(3):1181–1191, 2020
David Salinas, Valentin Flunkert, Jan Gasthaus, and Tim Januschowski. Deepar: Probabilistic forecasting with autoregressive recurrent networks.International journal of forecasting, 36(3):1181–1191, 2020
2020
-
[8]
International Journal of Forecasting 36, 54–74
Spyros Makridakis, Evangelos Spiliotis, and Vassilios Assimakopoulos. The m4 competition: 100,000 time series and 61 forecasting methods.International Journal of Forecasting, 36(1):54–74, 2020. ISSN 0169-2070. doi:https://doi.org/10.1016/j.ijforecast.2019.04.014. URL https://www.sciencedirect.com/ science/article/pii/S0169207019301128. M4 Competition
-
[9]
Principles and algorithms for forecasting groups of time series: Locality and globality.International Journal of Forecasting, 37(4):1632–1653, 2021
Pablo Montero-Manso and Rob J Hyndman. Principles and algorithms for forecasting groups of time series: Locality and globality.International Journal of Forecasting, 37(4):1632–1653, 2021. 9 Why Do Time Series Models Need Long Context Windows?PREPRINT
2021
-
[10]
Informer: Beyond efficient transformer for long sequence time-series forecasting
Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, and Wancai Zhang. Informer: Beyond efficient transformer for long sequence time-series forecasting. InThe Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Virtual Conference, volume 35, pages 11106–11115. AAAI Press, 2021
2021
-
[11]
A time series is worth 64 words: Long-term forecasting with transformers
Yuqi Nie, Nam H Nguyen, Phanwadee Sinthong, and Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. InThe Eleventh International Conference on Learning Representations, 2022
2022
-
[12]
FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting
Tian Zhou, Ziqing Ma, Qingsong Wen, Xue Wang, Liang Sun, and Rong Jin. FEDformer: Frequency enhanced decomposed transformer for long-term series forecasting. InProc. 39th International Conference on Machine Learning (ICML 2022), 2022
2022
-
[13]
Liu, and Schahram Dustdar
Shizhan Liu, Hang Yu, Cong Liao, Jianguo Li, Weiyao Lin, Alex X. Liu, and Schahram Dustdar. Pyraformer: Low-complexity pyramidal attention for long-range time series modeling and forecasting. InInternational Conference on Learning Representations, 2022. URLhttps://openreview.net/forum?id=0EXmFzUn5I
2022
-
[14]
A decoder-only foundation model for time-series forecasting
Abhimanyu Das, Weihao Kong, Rajat Sen, and Yichen Zhou. A decoder-only foundation model for time-series forecasting. InForty-first International Conference on Machine Learning, 2024
2024
-
[15]
Unified training of universal time series forecasting transformers
Gerald Woo, Chenghao Liu, Akshat Kumar, Caiming Xiong, Silvio Savarese, and Doyen Sahoo. Unified training of universal time series forecasting transformers. InInternational Conference on Machine Learning, pages 53140–53164. PMLR, 2024
2024
-
[16]
Moment: A family of open time-series foundation models.arXiv preprint arXiv:2402.03885, 2024
Mononito Goswami, Konrad Szafer, Arjun Choudhry, Yifu Cai, Shuo Li, and Artur Dubrawski. Moment: A family of open time-series foundation models.arXiv preprint arXiv:2402.03885, 2024
arXiv 2024
-
[17]
Foundation models for time series analysis: A tutorial and survey
Yuxuan Liang, Haomin Wen, Yuqi Nie, Yushan Jiang, Ming Jin, Dongjin Song, Shirui Pan, and Qingsong Wen. Foundation models for time series analysis: A tutorial and survey. InProceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining, pages 6555–6565, 2024
2024
-
[18]
An explanation of in-context learning as implicit bayesian inference
Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma. An explanation of in-context learning as implicit bayesian inference. InInternational Conference on Learning Representations, 2022. URL https: //openreview.net/forum?id=RdJVFCHjUMI
2022
-
[19]
What learning algorithm is in-context learning? investigations with linear models
Ekin Akyürek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. What learning algorithm is in-context learning? investigations with linear models. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=0g0X4H8yN4I
2023
-
[20]
Transformers as algorithms: Generalization and stability in in-context learning
Yingcong Li, Muhammed Emrullah Ildiz, Dimitris Papailiopoulos, and Samet Oymak. Transformers as algorithms: Generalization and stability in in-context learning. InInternational conference on machine learning, pages 19565–19594. PMLR, 2023
2023
-
[21]
What and how does in-context learning learn? bayesian model averaging, parameterization, and generalization
Yufeng Zhang, Fengzhuo Zhang, Zhuoran Yang, and Zhaoran Wang. What and how does in-context learning learn? bayesian model averaging, parameterization, and generalization. In Yingzhen Li, Stephan Mandt, Shipra Agrawal, and Emtiyaz Khan, editors,Proceedings of The 28th International Conference on Artificial Intelligence and Statistics, volume 258 ofProceedi...
-
[22]
URLhttps://proceedings.mlr.press/v258/zhang25d.html
-
[23]
A survey on in-context learning
Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Jingyuan Ma, Rui Li, Heming Xia, Jingjing Xu, Zhiyong Wu, Baobao Chang, Xu Sun, Lei Li, and Zhifang Sui. A survey on in-context learning. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1107–1128, Miami, Fl...
-
[24]
Chronos-2: From univariate to universal forecasting.arXiv preprint arXiv:2510.15821, 2025
Abdul Fatir Ansari, Oleksandr Shchur, Jaris Küken, Andreas Auer, Boran Han, Pedro Mercado, Syama Sundar Rangapuram, Huibin Shen, Lorenzo Stella, Xiyuan Zhang, et al. Chronos-2: From univariate to universal forecasting.arXiv preprint arXiv:2510.15821, 2025
Pith/arXiv arXiv 2025
-
[25]
Making and evaluating point forecasts.Journal of the American Statistical Association, 106 (494):746–762, 2011
Tilmann Gneiting. Making and evaluating point forecasts.Journal of the American Statistical Association, 106 (494):746–762, 2011
2011
-
[26]
Chapman and Hall/CRC, 1995
Andrew Gelman, John B Carlin, Hal S Stern, and Donald B Rubin.Bayesian data analysis. Chapman and Hall/CRC, 1995
1995
-
[27]
Chan, Biao Zhang, Aleksandra Faust, and Hugo Larochelle
Rishabh Agarwal, Avi Singh, Lei M Zhang, Bernd Bohnet, Luis Rosias, Stephanie C.Y . Chan, Biao Zhang, Aleksandra Faust, and Hugo Larochelle. Many-shot in-context learning. InICML 2024 Workshop on In-Context Learning, 2024. URLhttps://openreview.net/forum?id=goi7DFHlqS
2024
-
[28]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Nee- lakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020. 10 Why Do Time Series Models Need Long Context Windows?PREPRINT
1901
-
[29]
Moirai 2.0: When less is more for time series forecasting.arXiv preprint arXiv:2511.11698, 2025
Chenghao Liu, Taha Aksu, Juncheng Liu, Xu Liu, Hanshu Yan, Quang Pham, Doyen Sahoo, Caiming Xiong, Silvio Savarese, and Junnan Li. Moirai 2.0: When less is more for time series forecasting.arXiv preprint arXiv:2511.11698, 2025
arXiv 2025
-
[30]
Timer-xl: Long-context transformers for unified time series forecasting
Yong Liu, Guo Qin, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. Timer-xl: Long-context transformers for unified time series forecasting. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[31]
Largest: A benchmark dataset for large-scale traffic forecasting.Advances in Neural Information Processing Systems, 36:75354–75371, 2023
Xu Liu, Yutong Xia, Yuxuan Liang, Junfeng Hu, Yiwei Wang, Lei Bai, Chao Huang, Zhenguang Liu, Bryan Hooi, and Roger Zimmermann. Largest: A benchmark dataset for large-scale traffic forecasting.Advances in Neural Information Processing Systems, 36:75354–75371, 2023
2023
-
[32]
Commission for Energy Regulation. CER. CER Smart Metering Project - Electricity Customer Behaviour Trial, 2009-2010 [dataset].Irish Social Science Data Archive. SN: 0012-00, 2016. URL https://www.ucd.ie/ issda/data/commissionforenergyregulationcer/
2009
-
[33]
On the Properties of Neural Machine Translation: Encoder-Decoder Approaches , booktitle =
Kyunghyun Cho, Bart van Merriënboer, Dzmitry Bahdanau, and Yoshua Bengio. On the properties of neu- ral machine translation: Encoder–decoder approaches. In Dekai Wu, Marine Carpuat, Xavier Carreras, and Eva Maria Vecchi, editors,Proceedings of SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, pages 103–111, Doha, Qatar...
-
[34]
Are transformers effective for time series forecasting? In Proceedings of the AAAI conference on artificial intelligence, volume 37, pages 11121–11128, 2023
Ailing Zeng, Muxi Chen, Lei Zhang, and Qiang Xu. Are transformers effective for time series forecasting? In Proceedings of the AAAI conference on artificial intelligence, volume 37, pages 11121–11128, 2023
2023
-
[35]
Tsmixer: An all-mlp architecture for time series forecast-ing.Transactions on Machine Learning Research, 2023
Si-An Chen, Chun-Liang Li, Sercan O Arik, Nathanael Christian Yoder, and Tomas Pfister. Tsmixer: An all-mlp architecture for time series forecast-ing.Transactions on Machine Learning Research, 2023
2023
-
[36]
Moderntcn: A modern pure convolution structure for general time series analysis
Donghao Luo and Xue Wang. Moderntcn: A modern pure convolution structure for general time series analysis. InThe twelfth international conference on learning representations, pages 1–43, 2024
2024
-
[37]
Resurrecting recurrent neural networks for long sequences
Antonio Orvieto, Samuel L Smith, Albert Gu, Anushan Fernando, Caglar Gulcehre, Razvan Pascanu, and Soham De. Resurrecting recurrent neural networks for long sequences. InInternational Conference on Machine Learning, pages 26670–26698. PMLR, 2023
2023
-
[38]
Foundation models for time series: A survey.arXiv preprint arXiv:2504.04011, 2025
Siva Rama Krishna Kottapalli, Karthik Hubli, Sandeep Chandrashekhara, Garima Jain, Sunayana Hubli, Gayathri Botla, and Ramesh Doddaiah. Foundation models for time series: A survey.arXiv preprint arXiv:2504.04011, 2025
arXiv 2025
-
[39]
In-context fine-tuning for time-series foundation models
Matthew Faw, Rajat Sen, Yichen Zhou, and Abhimanyu Das. In-context fine-tuning for time-series foundation models. InForty-second International Conference on Machine Learning, 2025
2025
-
[40]
Andreas Auer, Raghul Parthipan, Pedro Mercado, Abdul Fatir Ansari, Lorenzo Stella, Bernie Wang, Michael Bohlke-Schneider, and Syama Sundar Rangapuram. Zero-shot time series forecasting with covariates via in-context learning.arXiv preprint arXiv:2506.03128, 2025
arXiv 2025
-
[41]
Context is key: A benchmark for forecasting with essential textual information
Andrew Robert Williams, Arjun Ashok, Étienne Marcotte, Valentina Zantedeschi, Jithendaraa Subramanian, Roland Riachi, James Requeima, Alexandre Lacoste, Irina Rish, Nicolas Chapados, and Alexandre Drouin. Context is key: A benchmark for forecasting with essential textual information. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Be...
2025
-
[42]
In-context time series predictor
Jiecheng Lu, Yan Sun, and Shihao Yang. In-context time series predictor. InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=dCcY2pyNIO
2025
-
[43]
A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting
Slawek Smyl. A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting. International journal of forecasting, 36(1):75–85, 2020
2020
-
[44]
Taming local effects in graph-based spatiotempo- ral forecasting.Advances in Neural Information Processing Systems, 36:55375–55393, 2023
Andrea Cini, Ivan Marisca, Daniele Zambon, and Cesare Alippi. Taming local effects in graph-based spatiotempo- ral forecasting.Advances in Neural Information Processing Systems, 36:55375–55393, 2023
2023
-
[45]
On the regularization of learnable embeddings for time series forecasting.Transactions on Machine Learning Research, 2025
Luca Butera, Giovanni De Felice, Andrea Cini, and Cesare Alippi. On the regularization of learnable embeddings for time series forecasting.Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URL https://openreview.net/forum?id=F5ALCh3GWG
2025
-
[46]
Zhe Li, Shiyi Qi, Yiduo Li, and Zenglin Xu. Revisiting long-term time series forecasting: An investigation on linear mapping.arXiv preprint arXiv:2305.10721, 2023. 11 Why Do Time Series Models Need Long Context Windows?PREPRINT
Pith/arXiv arXiv 2023
-
[47]
Graph-based virtual sensing from sparse and partial multivariate observations
Giovanni De Felice, Andrea Cini, Daniele Zambon, Vladimir V Gusev, and Cesare Alippi. Graph-based virtual sensing from sparse and partial multivariate observations. InInternational Conference on Learning Representations, 2024
2024
-
[48]
Taha Aksu, Gerald Woo, Juncheng Liu, Xu Liu, Chenghao Liu, Silvio Savarese, Caiming Xiong, and Doyen Sahoo. Gift-eval: A benchmark for general time series forecasting model evaluation.arXiv preprint arXiv:2410.10393, 2024
arXiv 2024
-
[49]
Timer: generative pre-trained transformers are large time series models
Yong Liu, Haoran Zhang, Chenyu Li, Xiangdong Huang, Jianmin Wang, and Mingsheng Long. Timer: generative pre-trained transformers are large time series models. InProceedings of the 41st International Conference on Machine Learning, pages 32369–32399, 2024
2024
-
[50]
Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
Pith/arXiv arXiv 2014
-
[51]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[52]
Oreshkin, Dmitri Carpov, Nicolas Chapados, and Yoshua Bengio
Boris N. Oreshkin, Dmitri Carpov, Nicolas Chapados, and Yoshua Bengio. N-BEATS: Neural basis expansion analysis for interpretable time series forecasting. InInternational Conference on Learning Representations, 2020. URLhttps://openreview.net/forum?id=r1ecqn4YwB
2020
-
[53]
One fits all: Power general time series analysis by pretrained LM
Tian Zhou, Peisong Niu, Xue Wang, Liang Sun, and Rong Jin. One fits all: Power general time series analysis by pretrained LM. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=gMS6FVZvmF
2023
-
[54]
Lag-llama: Towards foundation models for time series forecasting
Kashif Rasul, Arjun Ashok, Andrew Robert Williams, Arian Khorasani, George Adamopoulos, Rishika Bhag- watkar, Marin Biloš, Hena Ghonia, Nadhir Hassen, Anderson Schneider, et al. Lag-llama: Towards foundation models for time series forecasting. InR0-FoMo: Robustness of Few-shot and Zero-shot Learning in Large Foundation Models, 2023
2023
-
[55]
Chronos: Learning the language of time series.Transactions on Machine Learning Research, 2024
Abdul Fatir Ansari, Lorenzo Stella, Ali Caner Turkmen, Xiyuan Zhang, Pedro Mercado, Huibin Shen, Oleksandr Shchur, Syama Sundar Rangapuram, Sebastian Pineda Arango, Shubham Kapoor, et al. Chronos: Learning the language of time series.Transactions on Machine Learning Research, 2024
2024
-
[56]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
2019
-
[57]
Description based text classification with reinforcement learning
Duo Chai, Wei Wu, Qinghong Han, Fei Wu, and Jiwei Li. Description based text classification with reinforcement learning. InInternational conference on machine learning, pages 1371–1382. PMLR, 2020
2020
-
[58]
Finetuned language models are zero-shot learners
Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. InInternational Conference on Learning Representations, 2022
2022
-
[59]
Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[60]
Meta-learning via language model in-context tuning
Yanda Chen, Ruiqi Zhong, Sheng Zha, George Karypis, and He He. Meta-learning via language model in-context tuning. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 719–730, 2022
2022
-
[61]
Metaicl: Learning to learn in context
Sewon Min, Mike Lewis, Luke Zettlemoyer, and Hannaneh Hajishirzi. Metaicl: Learning to learn in context. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2791–2809, 2022
2022
-
[62]
In-context pretraining: Language modeling beyond document boundaries
Weijia Shi, Sewon Min, Maria Lomeli, Chunting Zhou, Margaret Li, Xi Victoria Lin, Noah A Smith, Luke Zettlemoyer, Wen-tau Yih, and Mike Lewis. In-context pretraining: Language modeling beyond document boundaries. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[63]
Fforma: Feature-based forecast model averaging.International Journal of Forecasting, 36(1):86–92, 2020
Pablo Montero-Manso, George Athanasopoulos, Rob J Hyndman, and Thiyanga S Talagala. Fforma: Feature-based forecast model averaging.International Journal of Forecasting, 36(1):86–92, 2020
2020
-
[64]
Learning to control fast-weight memories: An alternative to dynamic recurrent networks
Jürgen Schmidhuber. Learning to control fast-weight memories: An alternative to dynamic recurrent networks. Neural Computation, 4(1):131–139, 1992
1992
-
[65]
Hypernetworks
David Ha, Andrew M Dai, and Quoc V Le. Hypernetworks. InInternational Conference on Learning Representa- tions, 2017. 12 Why Do Time Series Models Need Long Context Windows?PREPRINT
2017
-
[66]
Meta-learning framework with applications to zero-shot time-series forecasting
Boris N Oreshkin, Dmitri Carpov, Nicolas Chapados, and Yoshua Bengio. Meta-learning framework with applications to zero-shot time-series forecasting. InProceedings of the AAAI conference on artificial intelligence, volume 35, pages 9242–9250, 2021
2021
-
[67]
Model-agnostic meta-learning for fast adaptation of deep networks
Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-agnostic meta-learning for fast adaptation of deep networks. In Doina Precup and Yee Whye Teh, editors,Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 1126–1135. PMLR, 06–11 Aug 2017. URLhttps://proceedings.mlr.press/v70/...
2017
-
[68]
Meta-learning how to forecast time series
Thiyanga S Talagala, Rob J Hyndman, and George Athanasopoulos. Meta-learning how to forecast time series. Journal of Forecasting, 42(6):1476–1501, 2023
2023
-
[69]
Declan A Norton, Edward Ott, Andrew Pomerance, Brian Hunt, and Michelle Girvan. Tailored forecasting from short time series via meta-learning.arXiv preprint arXiv:2501.16325, 2025. A Terminology We distinguish here several related terms. • Generative process identificationrefers to inferring which latent stochastic process generated an observed sequence, ...
arXiv 2025
-
[70]
introduced a unified backbone capable of addressing multiple time series tasks and efficiently adapting to new series via lightweight fine-tuning. TheMoiraifamily [ 15, 28] further extended the line of probabilistic foundation models with encoder-only and decoder-only architectures. Several decoder-based models followed [14, 48, 29], targeting point predi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.