Flow Map Denoisers: Traversing the Distortion-Perception Plane for Inverse Problems
Pith reviewed 2026-06-26 18:15 UTC · model grok-4.3
The pith
Flow map models use a lookahead parameter to traverse the full distortion-perception tradeoff in image restoration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
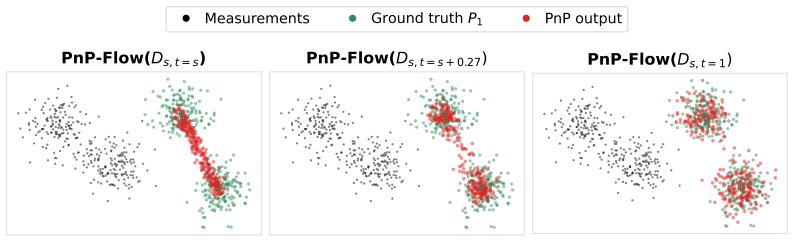
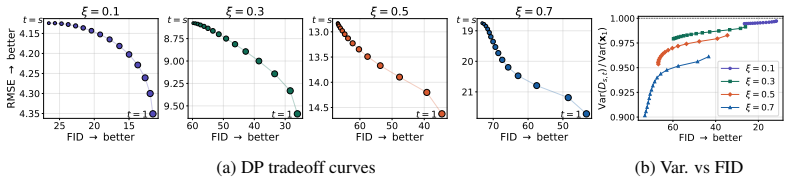
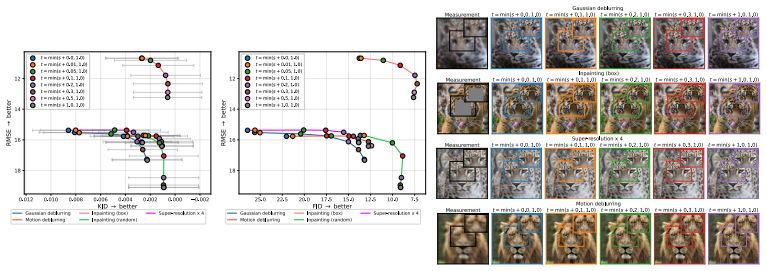
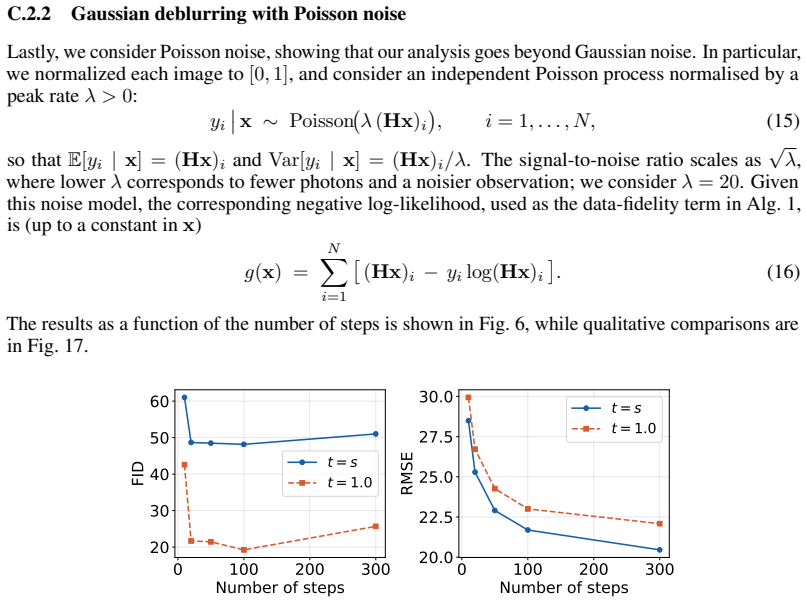
Flow map models implicitly define a one-parameter family of denoisers that continuously spans the distortion-perception frontier. The lookahead parameter t acts as a control knob between the MMSE and perceptual regimes. For Gaussian targets, varying t exactly recovers the optimal DP frontier; for natural images, similar behavior is observed empirically. Within a Plug-and-Play solver, the mechanism extends to general inverse problems.
What carries the argument
The flow map denoiser with its lookahead parameter t, which interpolates between different operating points on the distortion-perception plane by adjusting the prediction horizon in the learned average field.
If this is right
- A single trained model can access multiple points on the DP frontier without retraining or auxiliary models.
- In inverse problems, it allows trading off perceptual alignment and data consistency using the same mechanism.
- Matches or exceeds specialized baselines at both extremes of the tradeoff.
Where Pith is reading between the lines
- This approach might reduce the need for multiple specialized models in practical image restoration pipelines.
- Extending the Gaussian proof to non-Gaussian cases could lead to theoretical guarantees for real-world images.
- The method suggests that flow-based generative models have built-in flexibility for perception-distortion tradeoffs that other architectures might lack.
Load-bearing premise
The flow map model has learned a sufficiently accurate average field so that varying the lookahead parameter t produces the claimed continuous family of denoisers.
What would settle it
Training a flow map model on a dataset and then checking whether different values of t produce reconstructions that lie on or near the empirically measured optimal distortion-perception curve for that dataset.
Figures


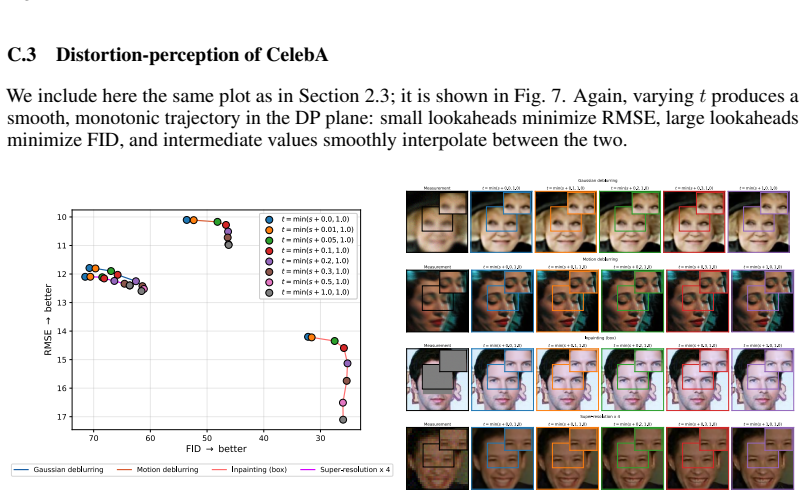
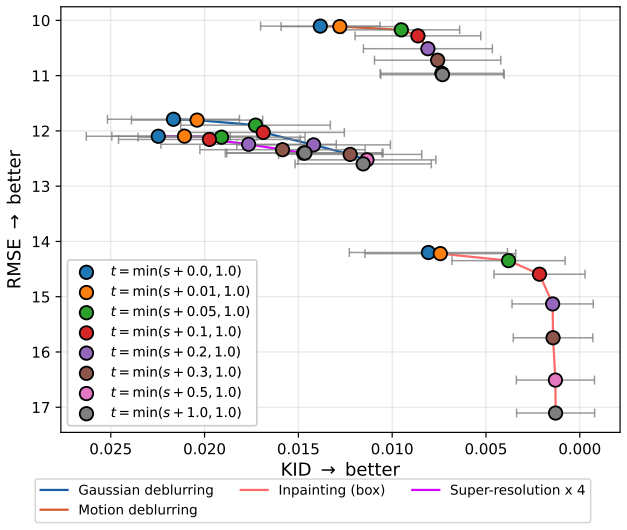



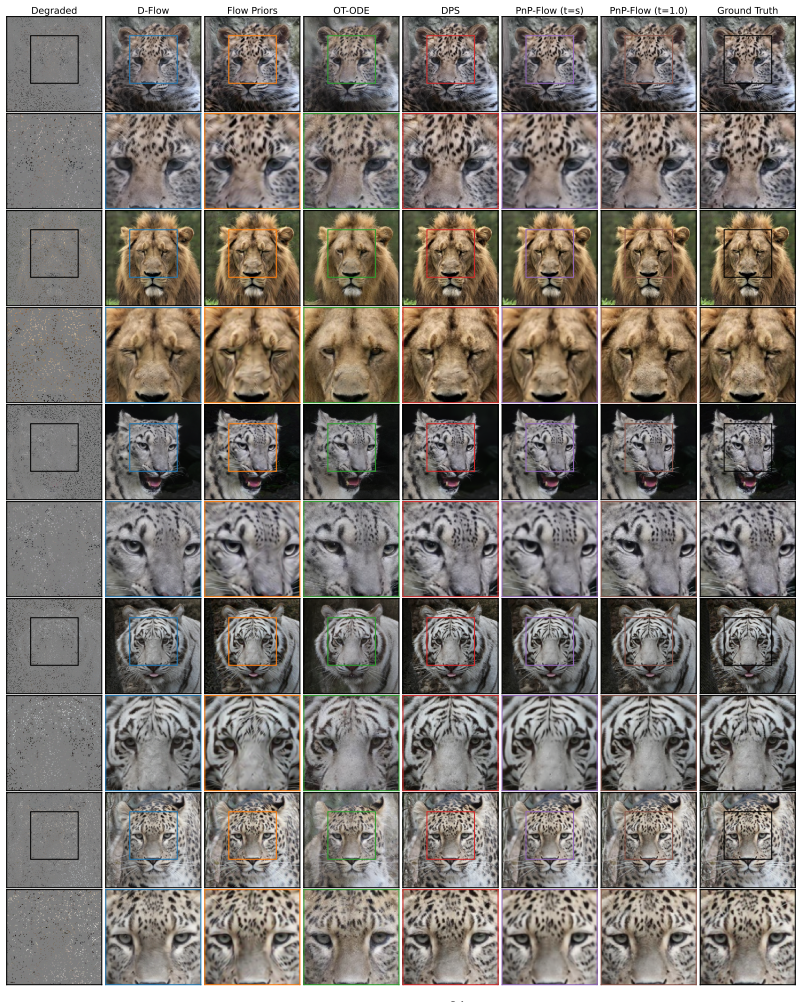




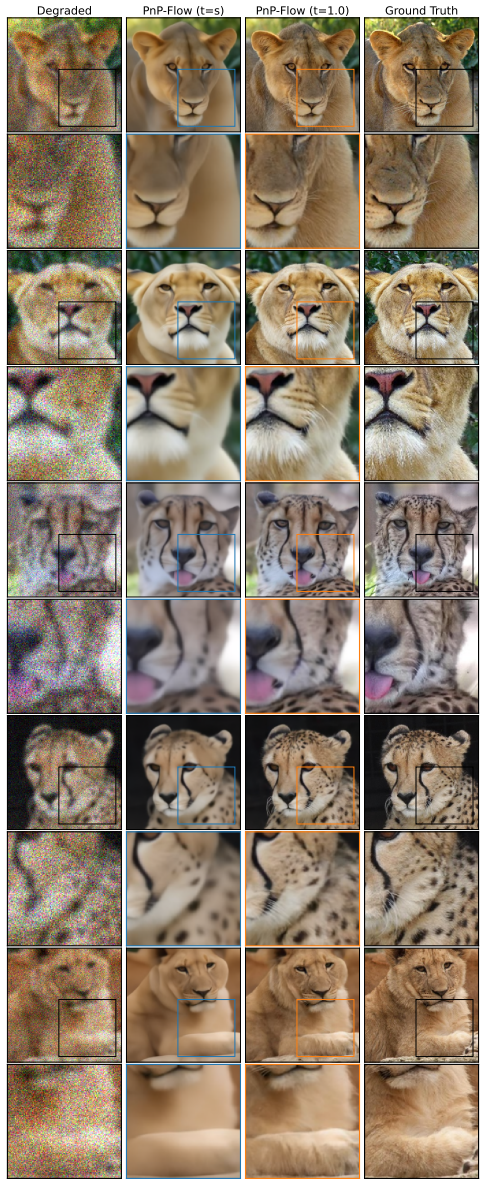






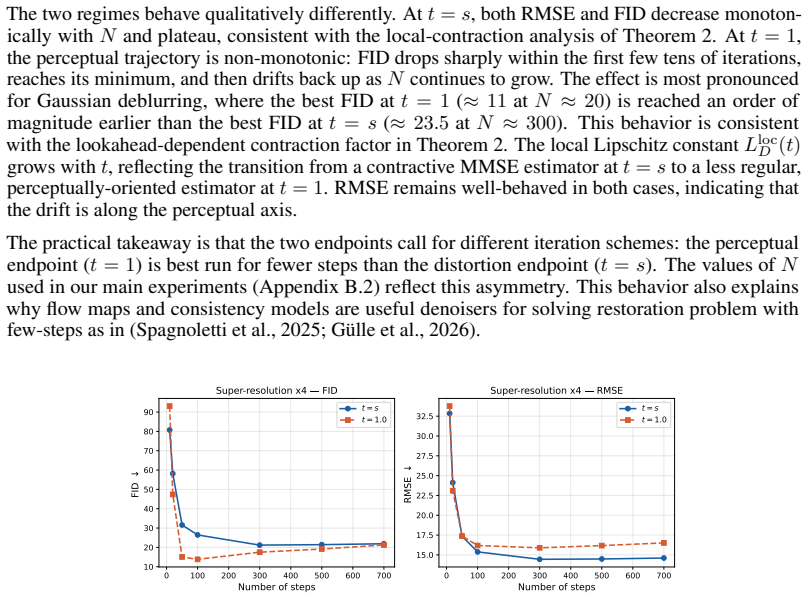
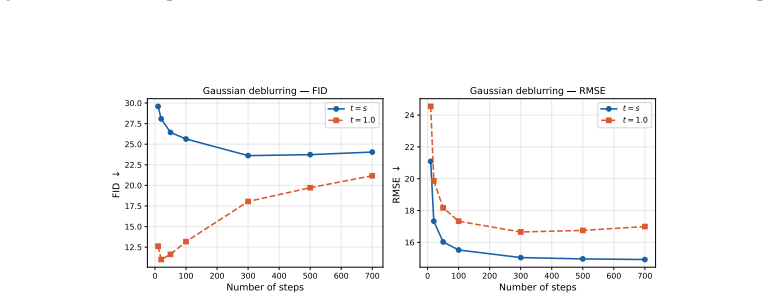
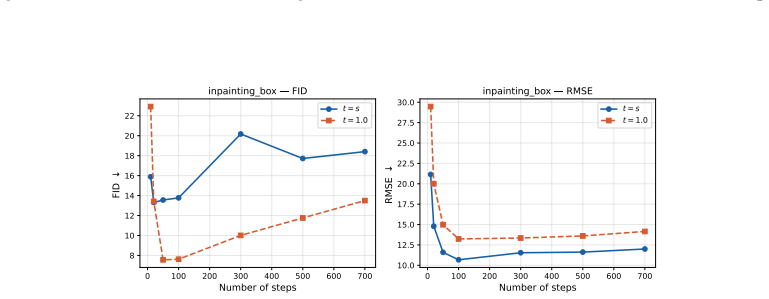
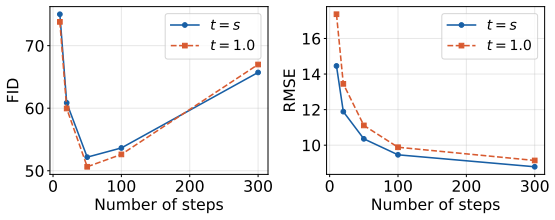
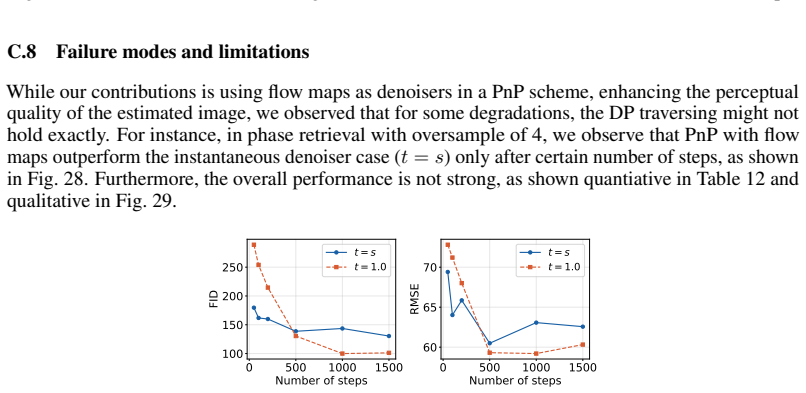



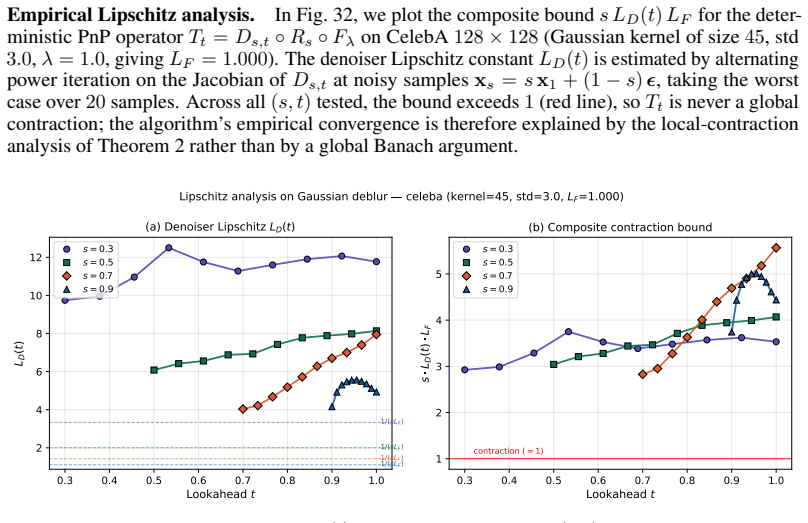
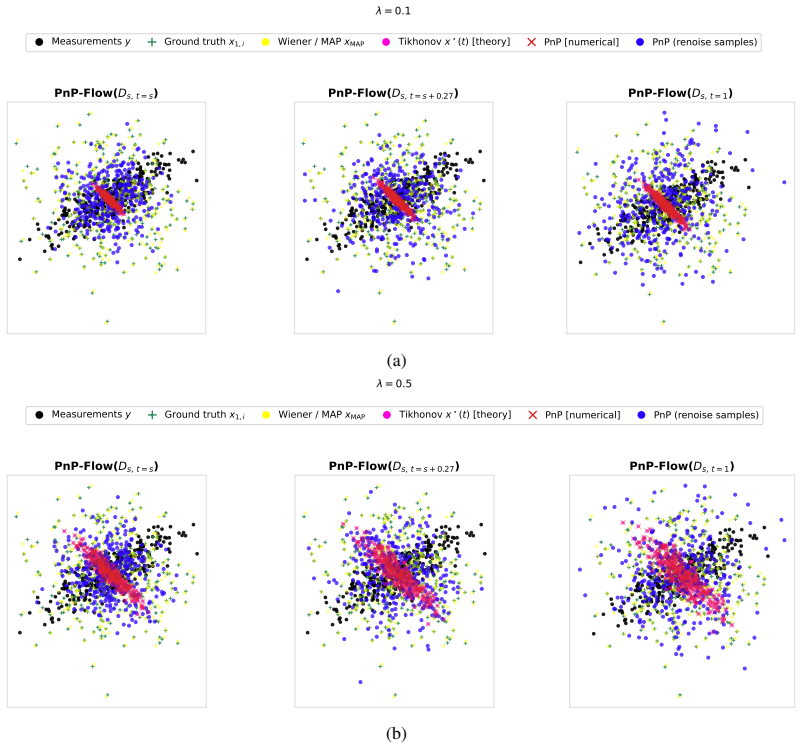
read the original abstract
Image restoration faces a fundamental tradeoff: methods that minimize error produce blurry reconstructions, while those that maximize perceptual quality yield sharp but less faithful images. Existing approaches either commit to a single operating point on this distortion perception (DP) frontier or require paired-data supervision, auxiliary models, or hyperparameter tuning of the sampler to access different points. We show that flow map models, a recent extension of flow matching for few-step sampling that learns an average field, implicitly define a one-parameter family of denoisers that continuously spans the DP frontier. The lookahead parameter t acts as a control knob between the MMSE and perceptual regimes. For Gaussian targets, we prove that varying t exactly recovers the optimal DP frontier; for natural images, we observe similar behavior empirically. Within a Plug-and-Play solver, the same mechanism extends to general inverse problems, where it controls a tradeoff between perceptual alignment and data consistency. Despite the lack of exact optimality guarantees in this setting, a single trained flow map spans the DP tradeoff, matching or exceeding specialized baselines at both extremes. Extensive experiments on CelebA ($128\times 128$) and AFHQ ($256\times 256$) across several linear and nonlinear inverse tasks validate our findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that flow map models, which learn an average field for few-step sampling, implicitly define a one-parameter family of denoisers controlled by the lookahead parameter t. This family continuously spans the distortion-perception (DP) frontier: for Gaussian targets the paper proves that varying t exactly recovers the optimal DP frontier, while for natural images similar behavior is observed empirically. The same t-mechanism is then used inside Plug-and-Play solvers for general inverse problems, where it controls the tradeoff between perceptual alignment and data consistency despite the acknowledged lack of exact optimality guarantees. Experiments on CelebA (128×128) and AFHQ (256×256) across linear and nonlinear tasks are presented to support the claims.
Significance. If the empirical results hold, the work supplies a simple, single-model mechanism for traversing the DP plane without paired supervision, auxiliary networks, or sampler hyperparameter search. The explicit Gaussian proof is a clear strength; the empirical extension to images and PnP solvers, while caveated, would still be useful if the observed curves reliably reach competitive extremes.
major comments (2)
- [Abstract / Gaussian proof section] Abstract and the section presenting the Gaussian result: the proof establishes exact recovery of the optimal frontier only for Gaussian targets; the extension to natural images and PnP rests on the unverified premise that the trained flow map has learned an average field whose error is small enough for t to trace the actual frontier rather than an arbitrary curve. The manuscript should quantify this approximation error (e.g., via residual norms or comparison against known optimal points where available) to make the load-bearing assumption explicit.
- [PnP experiments section] The PnP inverse-problem experiments: while the paper states that the mechanism 'matches or exceeds specialized baselines at both extremes' despite missing optimality guarantees, the central claim that a single model 'continuously spans the DP tradeoff' requires showing that the family produced by t is not merely a monotonic curve but lies near the frontier; additional plots comparing the obtained (distortion, perception) pairs against multiple strong baselines at intermediate t values would be needed to substantiate this.
minor comments (2)
- [Methods] Notation for the lookahead parameter t should be introduced with a clear equation reference in the methods section rather than only in the abstract.
- [Figures] Figure captions for the DP-plane plots should explicitly state the exact distortion and perception metrics used and whether error bars reflect multiple random seeds.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / Gaussian proof section] Abstract and the section presenting the Gaussian result: the proof establishes exact recovery of the optimal frontier only for Gaussian targets; the extension to natural images and PnP rests on the unverified premise that the trained flow map has learned an average field whose error is small enough for t to trace the actual frontier rather than an arbitrary curve. The manuscript should quantify this approximation error (e.g., via residual norms or comparison against known optimal points where available) to make the load-bearing assumption explicit.
Authors: We agree that exact optimality holds only for the Gaussian case, with the image and PnP results being empirical. To address the concern, we will add a new paragraph (and associated figure) in the Gaussian section that quantifies the residual norm of the learned flow map on held-out Gaussian samples and compares the empirical DP curve on images against the known MMSE and perceptual extremes. revision: yes
-
Referee: [PnP experiments section] The PnP inverse-problem experiments: while the paper states that the mechanism 'matches or exceeds specialized baselines at both extremes' despite missing optimality guarantees, the central claim that a single model 'continuously spans the DP tradeoff' requires showing that the family produced by t is not merely a monotonic curve but lies near the frontier; additional plots comparing the obtained (distortion, perception) pairs against multiple strong baselines at intermediate t values would be needed to substantiate this.
Authors: We accept that intermediate-t points require explicit comparison to establish proximity to the frontier. We will add a new figure (and corresponding text) in the PnP experiments section that plots the full DP trajectories for several inverse problems together with the same strong baselines evaluated at matched distortion or perception levels. revision: yes
Circularity Check
No significant circularity; Gaussian proof is external and image results are empirical observations
full rationale
The paper's core derivation for Gaussian targets is a mathematical proof that varying the lookahead t recovers the optimal DP frontier, stated against an external benchmark rather than reducing to the model's own fitted parameters. For natural images the text reports empirical similarity without claiming exact recovery, and the PnP extension is explicitly qualified by 'despite the lack of exact optimality guarantees.' No self-definitional equations, fitted-input predictions, or load-bearing self-citations appear in the abstract or described claims. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Flow map models learn an average field that can be queried at different lookahead horizons
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2210.10723 , year=
Diffusion models for text-to-3D generation , author=. arXiv preprint arXiv:2210.10723 , year=
-
[2]
arXiv preprint arXiv:2304.09367 , year=
DreamFusion: Text-to-3D using 2D Diffusion Priors , author=. arXiv preprint arXiv:2304.09367 , year=
-
[3]
arXiv preprint arXiv:2310.20090 , year=
Bridging the Gap Between Variational Inference and Wasserstein Gradient Flows , author=. arXiv preprint arXiv:2310.20090 , year=
-
[4]
Variational inference via
Lambert, Marc and Chewi, Sinho and Bach, Francis and Bonnabel, Silv. Variational inference via
-
[5]
2005 , publisher=
Gradient flows: in metric spaces and in the space of probability measures , author=. 2005 , publisher=
2005
-
[6]
A Variational Perspective on Solving Inverse Problems with Diffusion Models , author=
-
[7]
The variational formulation of the
Jordan, Richard and Kinderlehrer, David and Otto, Felix , journal=. The variational formulation of the. 1998 , publisher=
1998
-
[8]
Collaborative Score Distillation for Consistent Visual Editing , volume =
Kim, Subin and Lee, Kyungmin and Choi, June Suk and Jeong, Jongheon and Sohn, Kihyuk and Shin, Jinwoo , booktitle = NIPS, pages =. Collaborative Score Distillation for Consistent Visual Editing , volume =
-
[9]
Stein variational gradient descent: A general purpose
Liu, Qiang and Wang, Dilin , journal=NIPS, volume=. Stein variational gradient descent: A general purpose
-
[10]
Stein variational gradient descent as gradient flow , author=
-
[11]
Scaling limit of the
Lu, Jianfeng and Lu, Yulong and Nolen, James , journal=. Scaling limit of the. 2019 , publisher=
2019
-
[12]
Particle guidance: non-
Corso, Gabriele and Xu, Yilun and De Bortoli, Valentin and Barzilay, Regina and Jaakkola, Tommi , journal=ICLR, year=. Particle guidance: non-
-
[13]
Understanding the variance collapse of
Ba, Jimmy and Erdogdu, Murat A and Ghassemi, Marzyeh and Sun, Shengyang and Suzuki, Taiji and Wu, Denny and Zhang, Tianzong , booktitle=ICLR, year=. Understanding the variance collapse of
-
[14]
Annealed
D'Angelo, Francesco and Fortuin, Vincent , journal=. Annealed
-
[15]
Particle-based Variational Inference with Generalized
Cheng, Ziheng and Zhang, Shiyue and Yu, Longlin and Zhang, Cheng , journal=NIPS, volume=. Particle-based Variational Inference with Generalized
-
[16]
Particle-based variational inference with preconditioned functional gradient flow , author=
-
[17]
Noise-free Score Distillation , author=
-
[18]
Prolificdreamer: High-fidelity and diverse text-to-
Wang, Zhengyi and Lu, Cheng and Wang, Yikai and Bao, Fan and Li, Chongxuan and Su, Hang and Zhu, Jun , journal=NIPS, volume=. Prolificdreamer: High-fidelity and diverse text-to-
-
[19]
Diff-instruct: A universal approach for transferring knowledge from pre-trained diffusion models , author=
-
[20]
DreamFusion: Text-to-
Poole, Ben and Jain, Ajay and Barron, Jonathan T and Mildenhall, Ben , booktitle=ICLR, year=. DreamFusion: Text-to-
-
[21]
Neural computation , volume=
A connection between score matching and denoising autoencoders , author=. Neural computation , volume=. 2011 , publisher=
2011
-
[22]
Solving linear inverse problems provably via posterior sampling with latent diffusion models , author=
-
[23]
Denoising diffusion probabilistic models , author=
-
[24]
Denoising Diffusion Implicit Models , author=
-
[25]
Score-Based Generative Modeling with Critically-Damped
Dockhorn, Tim and Vahdat, Arash and Kreis, Karsten , booktitle=ICLR, year=. Score-Based Generative Modeling with Critically-Damped
-
[26]
Gradient flows for sampling: mean-field models,
Chen, Yifan and Huang, Daniel Zhengyu and Huang, Jiaoyang and Reich, Sebastian and Stuart, Andrew M , journal=. Gradient flows for sampling: mean-field models,
-
[27]
Taming Mode Collapse in Score Distillation for Text-to-
Wang, Peihao and Xu, Dejia and Fan, Zhiwen and Wang, Dilin and Mohan, Sreyas and Iandola, Forrest and Ranjan, Rakesh and Li, Yilei and Liu, Qiang and Wang, Zhangyang and others , journal=. Taming Mode Collapse in Score Distillation for Text-to-
-
[28]
Annealed
Zilberstein, Nicolas and Dick, Chris and Doost-Mohammady, Rahman and Sabharwal, Ashutosh and Segarra, Santiago , journal=TWC, year=. Annealed
-
[29]
Arvinte, Marius and Tamir, Jonathan I , journal=TWC, year=
-
[30]
Kong, Zhifeng and Ping, Wei and Huang, Jiaji and Zhao, Kexin and Catanzaro, Bryan , booktitle=ICLR, year=. Diff
-
[31]
Hu, Edward J and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu and others , booktitle=ICLR, year=
-
[32]
2022 , organization=
Feature space particle inference for neural network ensembles , author=. 2022 , organization=
2022
-
[33]
A rigorous link between deep ensembles and (variational) bayesian methods , author=
-
[34]
Repulsive deep ensembles are
D'Angelo, Francesco and Fortuin, Vincent , journal=NIPS, volume=. Repulsive deep ensembles are
-
[35]
Deep unsupervised learning using nonequilibrium thermodynamics , author=
-
[36]
Score-Based Generative Modeling through Stochastic Differential Equations , author=
-
[37]
Asymptotically exact data augmentation: Models, properties, and algorithms , author=. J. Comp. Graph. Stat. , volume=. 2020 , publisher=
2020
-
[38]
The art of data augmentation , author=. J. Comp. Graph. Stat. , volume=. 2001 , publisher=
2001
-
[39]
Delta denoising score , author=
-
[40]
Denoising diffusion models for plug-and-play image restoration , author=
-
[41]
Regularization by denoising:
Faye, Elhadji C and Fall, Mame Diarra and Dobigeon, Nicolas , journal=. Regularization by denoising:
-
[42]
Diffusion models as plug-and-play priors , author=
-
[43]
2013 , organization=
Plug-and-play priors for model based reconstruction , author=. 2013 , organization=
2013
-
[44]
The little engine that could: Regularization by denoising (
Romano, Yaniv and Elad, Michael and Milanfar, Peyman , journal=. The little engine that could: Regularization by denoising (. 2017 , publisher=
2017
-
[45]
Stochastic solutions for linear inverse problems using the prior implicit in a denoiser , author=
-
[46]
Robust compressed sensing
Jalal, Ajil and Arvinte, Marius and Daras, Giannis and Price, Eric and Dimakis, Alexandros G and Tamir, Jon , journal=NIPS, volume=. Robust compressed sensing
-
[47]
Kawar, Bahjat and Vaksman, Gregory and Elad, Michael , journal=NIPS, volume=
-
[48]
Denoising diffusion restoration models , author=
-
[49]
2021 , organization=
Choi, Jooyoung and Kim, Sungwon and Jeong, Yonghyun and Gwon, Youngjune and Yoon, Sungroh , booktitle=ICCV, pages=. 2021 , organization=
2021
-
[50]
Come-closer-diffuse-faster: Accelerating conditional diffusion models for inverse problems through stochastic contraction , author=
-
[51]
Improving diffusion models for inverse problems using manifold constraints , author=
-
[52]
Video diffusion models , author=
-
[53]
Diffusion Posterior Sampling for General Noisy Inverse Problems , author=
-
[54]
Pseudoinverse-guided diffusion models for inverse problems , author=
-
[55]
Solving inverse problems with latent diffusion models via hard data consistency , author=
-
[56]
arXiv preprint arXiv:2403.11415 , year=
DreamSampler: Unifying Diffusion Sampling and Score Distillation for Image Manipulation , author=. arXiv preprint arXiv:2403.11415 , year=
-
[57]
Steindreamer: Variance reduction for text-to-
Wang, Peihao and Fan, Zhiwen and Xu, Dejia and Wang, Dilin and Mohan, Sreyas and Iandola, Forrest and Ranjan, Rakesh and Li, Yilei and Liu, Qiang and Wang, Zhangyang and others , journal=. Steindreamer: Variance reduction for text-to-
-
[58]
On the geometry of
Duncan, Andrew and N. On the geometry of
-
[59]
2020 , publisher=
Deep learning techniques for inverse problems in imaging , author=. 2020 , publisher=
2020
-
[60]
2023 , organization=
Loss-guided diffusion models for plug-and-play controllable generation , author=. 2023 , organization=
2023
-
[61]
2017 , organization=
Compressed sensing using generative models , author=. 2017 , organization=
2017
-
[62]
Bayesian imaging using plug & play priors: when
Laumont, R. Bayesian imaging using plug & play priors: when. SIAM J. Imag. Sciences , volume=. 2022 , publisher=
2022
-
[63]
Debiasing scores and prompts of 2
Hong, Susung and Ahn, Donghoon and Kim, Seungryong , journal=NIPS, volume=. Debiasing scores and prompts of 2
-
[64]
arXiv preprint arXiv:2306.12422 , year=
Dreamtime: An improved optimization strategy for text-to-3d content creation , author=. arXiv preprint arXiv:2306.12422 , year=
-
[65]
Prompt-tuning latent diffusion models for inverse problems , author=
-
[66]
Zero-shot text-guided object generation with dream fields , author=
-
[67]
Maximum likelihood training of score-based diffusion models , author=
-
[68]
Ensemble Variational
Subrahmanya, Amit N and Popov, Andrey A and Sandu, Adrian , journal=. Ensemble Variational
-
[69]
Re-imagine the Negative Prompt Algorithm: Transform 2
Armandpour, Mohammadreza and Zheng, Huangjie and Sadeghian, Ali and Sadeghian, Amir and Zhou, Mingyuan , journal=. Re-imagine the Negative Prompt Algorithm: Transform 2
-
[70]
2021 , publisher=
Plug-and-play image restoration with deep denoiser prior , author=. 2021 , publisher=
2021
-
[71]
NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications , year=
Classifier-Free Diffusion Guidance , author=. NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications , year=
2021
-
[72]
2022 IEEE , author=
High-resolution image synthesis with latent diffusion models. 2022 IEEE , author=
2022
-
[73]
Score-based generative modeling in latent space , author=
-
[74]
Auto-encoding variational
Kingma, Diederik P and Welling, Max , booktitle=ICLR, year=. Auto-encoding variational
-
[75]
2022 , howpublished =
LAION-AI Team , title =. 2022 , howpublished =
2022
-
[76]
Emerging properties in self-supervised vision transformers , author=
-
[77]
2014 , organization=
Microsoft coco: Common objects in context , author=. 2014 , organization=
2014
-
[78]
ACM SIGGRAPH , pages=
Palette: Image-to-image diffusion models , author=. ACM SIGGRAPH , pages=
-
[79]
2021 , organization=
Hessel, Jack and Holtzman, Ari and Forbes, Maxwell and Le Bras, Ronan and Choi, Yejin , booktitle=. 2021 , organization=
2021
-
[80]
Imagenet large scale visual recognition challenge , author=. Int. J. Comp. Vision , volume=. 2015 , publisher=
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.