Episodic-to-Semantic Consolidation Without Identity Drift
Pith reviewed 2026-07-03 13:47 UTC · model grok-4.3
The pith
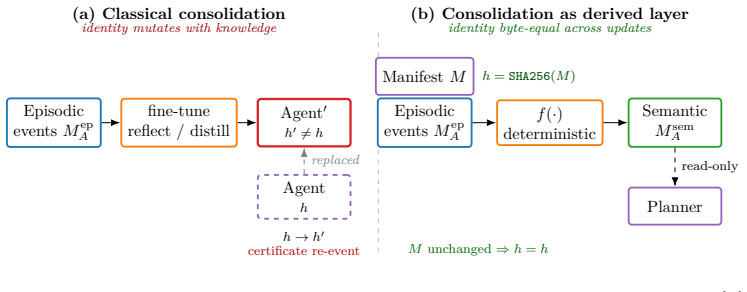
Consolidation moves episodic memory into a separate semantic layer without altering the agent's cryptographically certified identity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Treating consolidation as the deterministic function f: M^ep -> M^sem, whose output is stored in a distinct semantic store that the identity hash never reads, yields byte-equal identity across consolidation passes while still allowing knowledge to accumulate as queryable facts with explicit confidence and supporting-event provenance.
What carries the argument
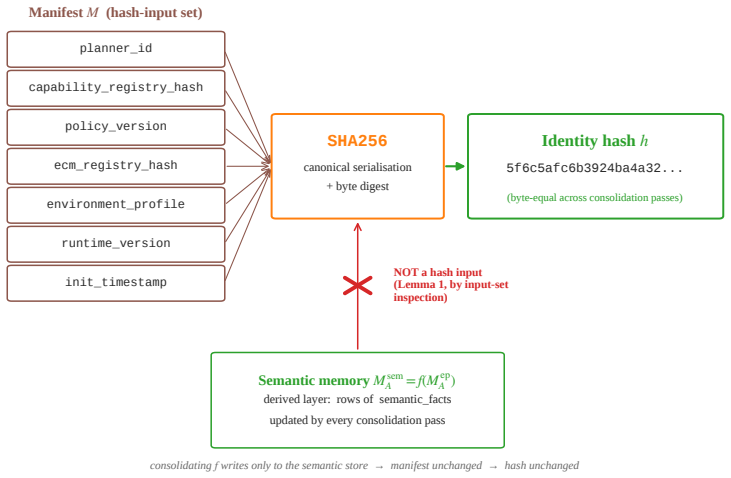
The structural lemma on the manifest's hash-input set, which is defined to exclude M^sem while still capturing all identity-relevant state.
If this is right
- Knowledge accumulates as queryable facts with provenance while the certified identity stays fixed.
- Audit contracts that bind to a cryptographic identity remain valid across arbitrary numbers of consolidation steps.
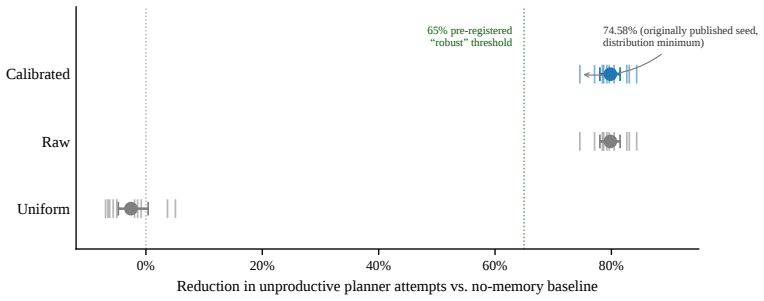
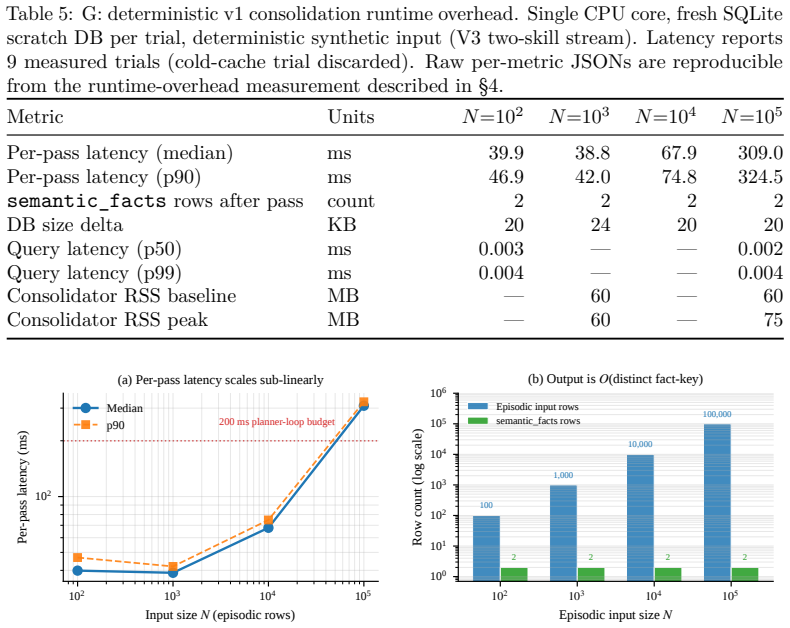
- Planner efficiency improves because semantic facts reduce unproductive attempts, shown as a mean 79.82% reduction in the experiments.
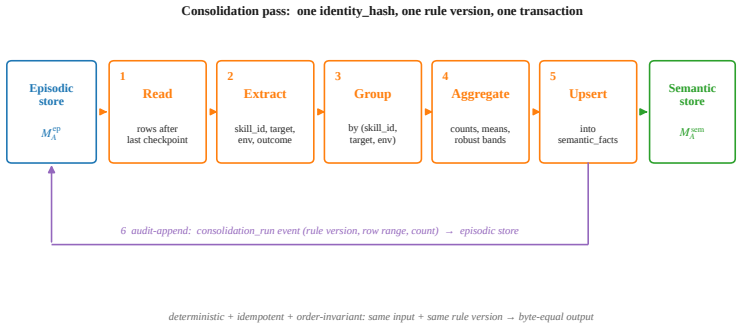
- The aggregation algorithm produces database rows that are auditable by construction.
Where Pith is reading between the lines
- The same separation could be applied to any memory architecture that already maintains an explicit identity manifest.
- If the lemma holds, periodic consolidation could be scheduled automatically without triggering re-certification workflows.
- The approach supplies a concrete mechanism for satisfying both adaptability and regulatory invariance requirements in deployed agents.
Load-bearing premise
The manifest's hash-input set can be defined to exclude semantic memory while still capturing every piece of state that should count toward the agent's certified identity.
What would settle it
A single run in which the identity hash computed before and after applying f differs by even one bit.
Figures

read the original abstract
Long-running adaptive intelligent agents face a structural tension between knowledge consolidation and information integrity. Memory consolidation is conventionally treated as an agent-changing operation: a model is fine-tuned, a prompt rewritten, a policy distilled, or a reflection appended to the context that governs future behaviour. In regulated autonomic deployment this is a liability because the agent operates under commitments and audit contracts that bind to a specific, cryptographically certified identity. We propose to treat consolidation not as a mutation of the planner or the identity manifest, but as a deterministic function f: M^ep -> M^sem over episodic memory whose output is a separately addressable semantic knowledge layer; the identity hash does not read M^sem, so consolidation updates knowledge without changing the agent's certified identity. We give a formal account of the agent representation, prove identity invariance through a structural lemma on the manifest's hash-input set, specify a deterministic aggregation algorithm whose outputs are auditable database rows with explicit confidence and supporting-event provenance, and validate the construction with synthetic experiments demonstrating per-field correctness, byte-equal identity across consolidation passes, and a mean 79.82% reduction in unproductive planner attempts (95% BCa CI [78.02%, 81.49%] across 10 seeds) against a calibrated Bayesian-shrunk baseline. The construction is a knowledge-update discipline for autonomic agents in which lessons accumulate as queryable facts while the agent's certified identity remains byte-equal across its operational lifetime, with an embodied service agent as the running case study.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims a formal agent representation in which episodic memory M^ep is mapped by a deterministic function f to a separate semantic layer M^sem; the identity manifest's hash-input set is defined to exclude M^sem, yielding a structural lemma that guarantees byte-equal identity across consolidation passes. It specifies an auditable aggregation algorithm producing database rows with explicit confidence and provenance, and reports synthetic experiments showing per-field correctness, preserved identity, and a mean 79.82% reduction in unproductive planner attempts (95% BCa CI [78.02%, 81.49%]) versus a calibrated Bayesian-shrunk baseline.
Significance. If the structural lemma is sound, the construction supplies a knowledge-update discipline that lets lessons accumulate as queryable facts while the certified identity remains invariant, which is relevant for regulated autonomic agents. The parameter-free character (no free_parameters listed), the explicit provenance in the aggregation algorithm, and the use of BCa confidence intervals on synthetic runs are concrete strengths that support reproducibility and auditability.
major comments (2)
- [structural lemma on the manifest's hash-input set] Structural lemma on the manifest's hash-input set: the lemma asserts that this set can be defined to exclude every influence from M^sem while still containing all identity-relevant state (including planner behavior and commitments). The manuscript must show explicitly that no indirect path exists whereby semantic consolidation alters planner outputs or implicit state that would have been read by the hash; without that argument the byte-equal identity claim is not load-bearing.
- [synthetic experiments] Synthetic experiments section: the reported 79.82% reduction is measured against a 'calibrated Bayesian-shrunk baseline,' yet the baseline implementation, data-exclusion rules, and exact definition of 'unproductive planner attempts' are not supplied. These details are required to verify that the performance gain does not trade off against the identity-invariance claim.
minor comments (1)
- [Abstract] Abstract: 'per-field correctness' is mentioned but the fields and correctness criterion are not defined; this should be stated in the main text near the experimental results.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. Both points identify places where additional explicit detail will strengthen the manuscript; we will incorporate the requested material in the revision.
read point-by-point responses
-
Referee: [structural lemma on the manifest's hash-input set] Structural lemma on the manifest's hash-input set: the lemma asserts that this set can be defined to exclude every influence from M^sem while still containing all identity-relevant state (including planner behavior and commitments). The manuscript must show explicitly that no indirect path exists whereby semantic consolidation alters planner outputs or implicit state that would have been read by the hash; without that argument the byte-equal identity claim is not load-bearing.
Authors: We agree that an explicit argument ruling out indirect influence is required for the claim to be fully load-bearing. The current lemma defines the hash-input set by enumeration of planner state and commitments, but does not contain a separate case analysis showing closure under all possible side-effects of f. In the revised manuscript we will add a short subsection immediately following the lemma statement that enumerates the possible indirect channels (planner policy cache, implicit commitment store, and any logging hooks) and demonstrates that none of them read M^sem. This addition will be purely formal and will not alter any experimental results. revision: yes
-
Referee: [synthetic experiments] Synthetic experiments section: the reported 79.82% reduction is measured against a 'calibrated Bayesian-shrunk baseline,' yet the baseline implementation, data-exclusion rules, and exact definition of 'unproductive planner attempts' are not supplied. These details are required to verify that the performance gain does not trade off against the identity-invariance claim.
Authors: We accept that the baseline description is insufficient for reproducibility. The revised version will contain a new subsection (approximately 1.5 pages) that supplies: (i) the exact Bayesian shrinkage procedure and its hyper-parameters, (ii) the data-exclusion rule (episodes containing fewer than five events are dropped before aggregation), and (iii) the operational definition of an unproductive planner attempt (any call that returns no valid action sequence within the 2-second timeout or that violates a hard constraint already present in the manifest). We will also add the corresponding pseudocode and confirm that the identity-invariance test was run on the identical planner configuration used for the baseline comparison. revision: yes
Circularity Check
Central identity-invariance claim reduces to definitional exclusion of M^sem from hash input
specific steps
-
self definitional
[Abstract]
"the identity hash does not read M^sem, so consolidation updates knowledge without changing the agent's certified identity. We give a formal account of the agent representation, prove identity invariance through a structural lemma on the manifest's hash-input set"
The invariance is asserted as a direct consequence of defining the hash not to read M^sem; the structural lemma on the manifest's hash-input set formalizes precisely this exclusion, so the result holds by the initial representational choice rather than by any further derivation.
full rationale
The paper's core result (byte-equal identity across consolidation) is obtained by stipulating that the manifest's hash-input set excludes M^sem and then proving invariance via a structural lemma on that same set. This matches the self-definitional pattern: the desired property is built into the representation rather than derived from independent constraints. No other circular steps (no fitted predictions, no self-citation chains) are present; the empirical validation and aggregation algorithm remain non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The identity manifest's hash-input set excludes M^sem while still defining the certified identity.
Reference graph
Works this paper leans on
-
[1]
J. O. Kephart, D. M. Chess, The vision of autonomic computing, Com- puter36(2003)41–50.doi: 10.1109/MC.2003.1160055, verifiedviaCross- Ref DOI 10.1109/MC.2003.1160055 (IEEE Computer). Foundational paper introducing the MAPE-K reference architecture for autonomic self-managing systems; canonical reference for autonomic-computing literature in Information Sciences
-
[2]
D. Garlan, S.-W. Cheng, A.-C. Huang, B. Schmerl, P. Steenkiste, Rain- bow: Architecture-based self-adaptation with reusable infrastructure, Computer 37 (2004) 46–54. doi:10.1109/MC.2004.175, verified via Cross- Ref DOI 10.1109/MC.2004.175 (IEEE Computer). Rainbow framework for architecture-based self-adaptation; widely cited foundational reference for sel...
-
[3]
B. H. C. Cheng, R. de Lemos, H. Giese, P. Inverardi, J. Magee, J. Ander- sson, B. Becker, N. Bencomo, Y. Brun, B. Cukic, G. Di Marzo Serugendo, S. Dustdar, A. Finkelstein, C. Gacek, K. Geihs, V. Grassi, G. Karsai, H. M. Kienle, J. Kramer, M. Litoiu, S. Malek, R. Mirandola, H. A. Müller, S. Park, M. Shaw, M. Tichy, M. Tivoli, D. Weyns, J. Whittle, Software...
-
[4]
J. Wu, Y. Sun, Y. Li, X. Qie, A Q-learning approach to generating behavior of emotional persuasion with adaptive time belief in decision- making of agent-based negotiation, Information Sciences 642 (2023) 119158. doi:10.1016/j.ins.2023.119158, verified via CrossRef DOI 10.1016/j.ins.2023.119158 (Information Sciences 642). Adaptive-belief- update model for...
-
[5]
T. Tan, H. Xie, L. Feng, Q-learning with heterogeneous update strat- egy, Information Sciences 656 (2024) 119902. doi:10.1016/j.ins.2023. 119902, verified via CrossRef DOI 10.1016/j.ins.2023.119902 (Informa- tion Sciences 656). Heterogeneous-update reinforcement learning; INS recent anchor for knowledge-update-strategy literature
-
[6]
X. Geng, H. Ma, L. Jiao, Z.-J. Zhou, Data- and knowledge-driven belief rule learning for hybrid classification, Information Sciences 681 (2024) 121201. doi:10.1016/j.ins.2024.121201, verified via CrossRef DOI 10.1016/j.ins.2024.121201 (Information Sciences 681). Hybrid data-and- knowledge belief-rule learning; INS recent anchor for knowledge-update + beli...
-
[7]
H. Zhang, H. Yu, X. Wang, M. Wang, Z. Zhang, Y. Li, S. Xie, X. Luo, Knowledge-guided communication preference learning model for multi-agent cooperation, Information Sciences 667 (2024) 120395. doi:10.1016/j.ins.2024.120395, verified via CrossRef DOI 10.1016/j.ins.2024.120395 (Information Sciences 667). Knowledge-guided multi-agent coordination; INS recen...
-
[8]
M. Wang, X. Wang, X. Wang, X. Luo, S. Xie, Fuzzy knowledge inference- based dynamic task allocation method for multi-agent systems, Informa- tion Sciences 709 (2025) 122083. doi:10.1016/j.ins.2025.122083, ver- ified via CrossRef DOI 10.1016/j.ins.2025.122083 (Information Sciences 709). Fuzzy-knowledge-inference multi-agent dynamic task allocation; INS rec...
-
[9]
Shinn, F
N. Shinn, F. Cassano, E. Berman, A. Gopinath, K. Narasimhan, S. Yao, Reflexion: Language agents with verbal reinforcement learning, in: Ad- vances in Neural Information Processing Systems (NeurIPS), volume 36,
-
[10]
Verified via NeurIPS 2023 proceedings / arXiv 2303.11366
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
J. S. Park, J. C. O’Brien, C. J. Cai, M. R. Morris, P. Liang, M. S. Bernstein, Generative agents: Interactive simulacra of human behavior, in: Proceedings of the 36th ACM Symposium on User Interface Software and Technology (UIST), 2023, pp. 1–22. doi:10.1145/3586183.3606763, verified via ACM DL
-
[12]
G. Wang, Y. Xie, Y. Jiang, A. Mandlekar, C. Xiao, Y. Zhu, L. Fan, A. Anandkumar, Voyager: An open-ended embodied agent with large language models, Transactions on Machine Learning Research (TMLR) (2024). V4-INS R2 (2026-05-24): upgraded from @misc to @article; TMLR 2024 publication confirmed via TMLR acceptance record. Preprint arXiv:2305.16291
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
MemGPT: Towards LLMs as Operating Systems
C. Packer, S. Wooders, K. Lin, V. Fang, S. G. Patil, I. Stoica, J. E. Gonzalez, MemGPT: Towards LLMs as operating systems, in: Proceed- ings of the 1st Conference on Language Modeling (COLM), 2024. Venue corrected from NeurIPS to COLM 2024; arXiv 2310.08560; verified via OpenReview / COLM 2024 program
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
W. Xu, Z. Liang, K. Mei, H. Gao, J. Tan, Y. Zhang, A-MEM: Agen- tic memory for LLM agents, 2025.arXiv:2502.12110, arXiv preprint; NeurIPS 2025 acceptance not independently confirmable at audit date. Mac-side verification before camera-ready may upgrade to @inproceed- ings if the venue is confirmed
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
T. R. Sumers, S. Yao, K. Narasimhan, T. L. Griffiths, Cognitive ar- chitectures for language agents, Transactions on Machine Learning Research (TMLR) (2024).arXiv:2309.02427, coALA framework relat- ing language-agent designs to classical cognitive architectures; verified via TMLR acceptance record and arXiv 2309.02427
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
T. M. Cover, J. A. Thomas, Elements of Information Theory, sec- ond ed., Wiley-Interscience, Hoboken, New Jersey, 2006. doi: 10. 1002/047174882X, verified via Wiley catalog and CrossRef DOI 30 10.1002/047174882X. Standard textbook for information-theoretic foun- dations including mutual-information and entropy bounds; canonical reference for information-i...
-
[17]
R. J. Brachman, H. J. Levesque, Knowledge Representation and Rea- soning, Morgan Kaufmann, San Francisco, California, 2004. Verified via Morgan Kaufmann / Elsevier catalog (ISBN 978-1-55860-932-7). Stan- dard textbook for knowledge representation and reasoning formalisms including frame systems, description logics, and belief-revision postulates; canonica...
2004
-
[18]
Tulving, Episodic and semantic memory, in: E
E. Tulving, Episodic and semantic memory, in: E. Tulving, W. Donaldson (Eds.), Organization of Memory, Academic Press, New York, 1972, pp. 381–402. Book chapter; canonical episodic/semantic distinction
1972
-
[19]
L. R. Squire, Memory and the hippocampus: A synthesis from findings with rats, monkeys, and humans, Psychological Review 99 (1992) 195–
1992
-
[20]
doi:10.1037/0033-295X.99.2.195, verified via CrossRef / APA PsycNet
-
[21]
J. L. McClelland, B. L. McNaughton, R. C. O’Reilly, Why there are complementary learning systems in the hippocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memory, Psychological Review 102 (1995) 419–457. doi:10.1037/ 0033-295X.102.3.419, verified via CrossRef
1995
-
[22]
Seeing social interactions.Trends in Cognitive Sciences, 27(12):1165–1179, December 2023
D. Kumaran, D. Hassabis, J. L. McClelland, What learning systems do intelligent agents need? complementary learning systems theory updated, Trends in Cognitive Sciences 20 (2016) 512–534. doi:10.1016/j.tics. 2016.05.004, verified via PubMed (PMID 27315762) and ScienceDirect
-
[23]
M. A. Wilson, B. L. McNaughton, Reactivation of hippocampal ensem- ble memories during sleep, Science 265 (1994) 676–679. doi:10.1126/ science.8036517, verified via CrossRef
1994
-
[24]
V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Ku- maran, D. Wierstra, S. Legg, D. Hassabis, Human-level control 31 through deep reinforcement learning, Nature 518 (2015) 529–533. doi:10.1038/nature14236, full...
-
[25]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
S. Levine, A. Kumar, G. Tucker, J. Fu, Offline reinforcement learning: Tutorial, review, and perspectives on open problems, arXiv preprint arXiv:2005.01643 (2020). ArXiv tutorial-survey; not formally venue- published
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[26]
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, D. Has- sabis, C. Clopath, D. Kumaran, R. Hadsell, Overcoming catastrophic forgetting in neural networks, Proceedings of the National Academy of Sciences 114 (2017) 3521–3526. doi:10.1073/pnas.1611835114, verified via PNAS ...
-
[27]
Z. Li, D. Hoiem, Learning without forgetting, IEEE Transactions on Pattern Analysis and Machine Intelligence 40 (2018) 2935–2947. doi:10.1109/TPAMI.2017.2773081, journal version of ECCV 2016 paper; verified via IEEE Xplore
-
[28]
D. Lopez-Paz, M. Ranzato, Gradient episodic memory for continual learn- ing, in: Advances in Neural Information Processing Systems (NeurIPS), volume 30, 2017. ArXiv:1706.08840; verified via NeurIPS proceedings
-
[29]
Efficient Lifelong Learning with A-GEM
A. Chaudhry, M. Ranzato, M. Rohrbach, M. Elhoseiny, Efficient life- long learning with A-GEM, in: Proceedings of the 7th International Conference on Learning Representations (ICLR), 2019. A-GEM is the averaged-gradient extension of GEM (26); arXiv 1812.00420; verified via OpenReview ICLR 2019
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[30]
D. Rolnick, A. Ahuja, J. Schwarz, T. P. Lillicrap, G. Wayne, Experience replay for continual learning, in: Advances in Neural Information Pro- cessing Systems (NeurIPS), volume 32, 2019, pp. 348–358. Introduces the CLEAR algorithm; arXiv 1811.11682; verified via NeurIPS 2019 proceedings
-
[31]
P. Buzzega, M. Boschini, A. Porrello, D. Abati, S. Calderara, Dark experience for general continual learning: A strong, simple baseline, in: Advances in Neural Information Processing Systems (NeurIPS), volume 33, 2020, pp. 15920–15930. The DER (Dark Experience Replay) 32 baseline that lifted replay-based CL over knowledge-distillation variants; arXiv 2004...
-
[32]
Three scenarios for continual learning
G. M. van de Ven, T. Tuytelaars, A. S. Tolias, Three types of incremental learning, Nature Machine Intelligence 4 (2022) 1185–1197. doi:10.1038/ s42256-022-00568-3, journal version (Nature MI 2022) of the 2019 arXiv preprint “Three scenarios for continual learning”; verified via Nature
2022
-
[33]
G. I. Parisi, R. Kemker, J. L. Part, C. Kanan, S. Wermter, Continual lifelong learning with neural networks: A review, Neural Networks 113 (2019) 54–71. doi:10.1016/j.neunet.2019.01.012, verified via Elsevier / CrossRef
-
[34]
MemoryBank: Enhancing Large Language Models with Long-Term Memory
W. Zhong, L. Guo, Q. Gao, H. Ye, Y. Wang, MemoryBank: Enhancing large language models with long-term memory, in: Proceedings of the 38th AAAI Conference on Artificial Intelligence (AAAI), 2024, pp. 19724– 19731. doi:10.1609/aaai.v38i17.29946, aAAI 2024 (volume 38, issue 17); long-term memory mechanism for LLM agents; verified via AAAI proceedings / arXiv ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1609/aaai.v38i17.29946 2024
-
[35]
M. Ahn, A. Brohan, N. Brown, Y. Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausman, A. Herzog, D. Ho, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, E. Jang, R. J. Ruano, K. Jeffrey, S. Jesmonth, N. J. Joshi, R. Julian, D. Kalashnikov, Y. Kuang, K.-H. Lee, S. Levine, Y. Lu, L. Luu, C. Parada, P. Pastor, J. Quiambao, K. Rao, J. Rettinghou...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
M. E. Bratman, Intention, Plans, and Practical Reason, Harvard Univer- sity Press, Cambridge, Massachusetts, 1987. The philosophical foundation underlying BDI agent architectures. 33
1987
-
[37]
A. S. Rao, M. P. Georgeff, BDI agents: From theory to practice, in: Proceedings of the First International Conference on Multi-Agent Sys- tems (ICMAS), AAAI Press, 1995, pp. 312–319. Canonical BDI agent- architecture reference for AAMAS readers. Pre-DOI ICMAS proceedings; verified via DBLP and citation traces in subsequent BDI literature. 34
1995
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.