Fidelity-Aware Frequency Allocation and Transpilation Co-Design for Tunable Coupler Quantum Systems
Pith reviewed 2026-05-22 09:05 UTC · model grok-4.3
The pith
Frequency allocation and noise-aware transpilation together cut log-infidelity by 8.9 percent on SNAIL systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By modeling spectator-induced coherent errors together with lifetime effects and using the resulting fidelities to solve a constrained frequency-assignment problem, then routing circuits with a fidelity-aware transpiler FINESSE that selects high-fidelity paths, the method achieves an average 8.9 percent reduction in log-infidelity cost and 6.8 percent reduction in circuit depth versus SABRE on SNAIL architectures while also demonstrating results on IBM Brisbane hardware.
What carries the argument
The error-budgeting model that combines coherent spectator-induced errors and incoherent lifetime effects, which is used both to formulate the frequency-allocation optimization and to score paths inside the FINESSE transpiler.
If this is right
- Increasing qubit count and coupling density within a module produces a fidelity-connectivity tradeoff.
- Scalable frequency allocation strategies can minimize spectator-induced errors under hardware separation constraints.
- Noise-aware transpilation that selects high-fidelity paths reduces both infidelity cost and circuit depth compared with standard shortest-path routing.
- The co-design approach applies to SNAIL-based third-order couplers that natively realize the square-root-iSWAP basis.
Where Pith is reading between the lines
- Hardware constraints and error models should be folded into the compilation pipeline at the frequency-allocation stage rather than treated as a later correction.
- Similar fidelity gains may appear on other tunable-coupler families if the same spectator-error budgeting is applied.
- The method could support denser layouts on future hardware if the error model continues to hold at larger scales.
Load-bearing premise
The error-budgeting model that combines coherent spectator-induced errors and incoherent lifetime effects remains accurate when module size, connectivity density, and realistic hardware separation constraints are scaled up.
What would settle it
Direct comparison of measured versus predicted infidelity on a larger module with higher coupling density that shows the 8.9 percent gain disappears or reverses would falsify the performance claim.
Figures









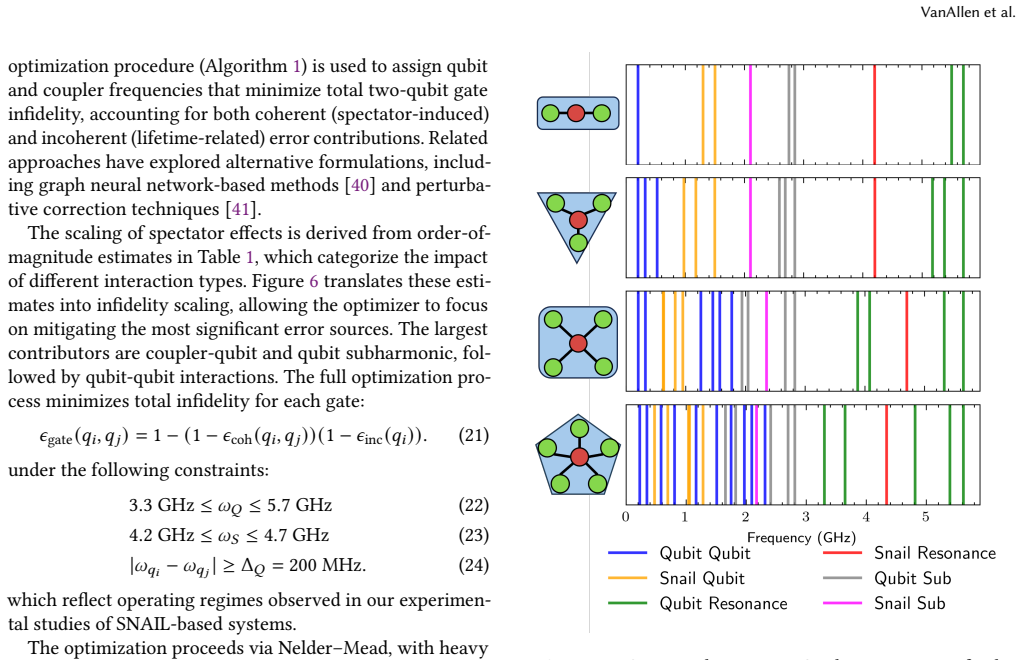





read the original abstract
Frequency crowding is a fundamental limitation in superconducting quantum architectures, particularly in tunable-coupler systems. We present a framework that explicitly models both coherent spectator-induced errors and incoherent lifetime effects through an error budgeting approach. Using this model, we analyze how frequency crowding impacts gate fidelity as module size and connectivity scale, and formulate a constrained optimization problem to assign qubit and coupler frequencies under realistic separation and hardware constraints. We demonstrate scalable frequency allocation strategies that minimize spectator-induced errors. We further show that increasing qubit count and coupling density within a module leads to a fidelity-connectivity tradeoff. To explore the benefits at the system scale, we have developed a noise-aware transpilation approach called FINESSE, which minimizes error by selecting high-fidelity paths that satisfy connectivity via SWAP insertion while jointly optimizing downstream gate execution. We demonstrate this physics-informed architecture-transpilation co-design approach for a SNAIL-based third-order coupler that natively realizes the $\sqrt{iSWAP}$ basis with frequency aware gate fidelities. On SNAIL architectures, FINESSE achieves an average 8.9% reduction in log-infidelity cost and 6.8% reduction in circuit depth vs. SABRE. We also compare results on IBM Brisbane's architecture.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a co-design framework for frequency allocation and transpilation in tunable-coupler superconducting quantum systems. It develops an error budgeting model that accounts for both coherent spectator-induced errors and incoherent lifetime effects to optimize frequency assignments under hardware constraints. The authors introduce FINESSE, a noise-aware transpiler that jointly optimizes path selection and gate execution for high fidelity. On SNAIL-based architectures, FINESSE is shown to achieve an average 8.9% reduction in log-infidelity cost and 6.8% reduction in circuit depth compared to the SABRE transpiler, with additional comparisons to IBM Brisbane's architecture.
Significance. This work addresses frequency crowding, a key practical barrier to scaling superconducting processors. The explicit error-budgeting approach and the joint architecture-transpilation optimization via FINESSE offer a concrete path toward physics-informed compilation. The reported numerical gains on SNAIL architectures and the identification of a fidelity-connectivity tradeoff provide useful benchmarks for the community. Reproducible numerical demonstrations on concrete hardware models are a strength, though the overall impact hinges on whether the budgeting model remains predictive beyond the tested regimes.
major comments (2)
- [Error budgeting and optimization formulation] The headline quantitative claims (8.9% log-infidelity reduction and 6.8% depth reduction on SNAIL) rest on frequency allocations and path selections produced by an error-budgeting model that adds coherent spectator phase errors to incoherent T1/T2 decay. The manuscript provides no direct validation—such as a comparison of budgeted infidelity against full master-equation or non-perturbative simulations—for module sizes or connectivity densities beyond the demonstrated cases. If non-additive effects from multi-qubit spectator chains or higher-order dispersive shifts appear, the optimized frequencies and SWAP paths would be suboptimal relative to the true noise landscape.
- [Frequency allocation results] The constrained optimization for frequency allocation incorporates realistic separation and hardware constraints, yet the manuscript does not report a sensitivity analysis on how the post-hoc minimum-frequency-separation thresholds were chosen or how they affect the resulting fidelity-connectivity tradeoff when module size increases. This choice is load-bearing for the claim that the allocation strategies remain scalable.
minor comments (3)
- [Abstract] The abstract reports average percentage reductions without stating the number of benchmark circuits, the distribution of results, or any error bars; adding these details would allow readers to assess the statistical robustness of the 8.9% and 6.8% figures.
- [Results figures] Figure captions for the SNAIL and IBM Brisbane comparisons should explicitly list the simulation parameters (e.g., T1/T2 values, coupling strengths, and number of random circuits) used to compute the log-infidelity costs.
- [FINESSE transpiler description] The definition of the log-infidelity cost function should be stated explicitly in the main text (rather than only in supplementary material) so that the reported reductions can be reproduced from the given equations.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We have addressed each major comment point by point below, indicating where revisions will be made to strengthen the presentation and clarify limitations.
read point-by-point responses
-
Referee: [Error budgeting and optimization formulation] The headline quantitative claims (8.9% log-infidelity reduction and 6.8% depth reduction on SNAIL) rest on frequency allocations and path selections produced by an error-budgeting model that adds coherent spectator phase errors to incoherent T1/T2 decay. The manuscript provides no direct validation—such as a comparison of budgeted infidelity against full master-equation or non-perturbative simulations—for module sizes or connectivity densities beyond the demonstrated cases. If non-additive effects from multi-qubit spectator chains or higher-order dispersive shifts appear, the optimized frequencies and SWAP paths would be suboptimal relative to the true noise landscape.
Authors: We acknowledge the value of direct validation against full master-equation simulations. Such simulations become computationally prohibitive beyond small modules due to Hilbert-space scaling. Our budgeting model follows standard perturbative treatments of dispersive shifts and lifetime effects that are widely used in the superconducting-qubit literature. In the revised manuscript we have added a dedicated limitations paragraph in Section III.C that (i) reports new comparisons of budgeted versus exact-diagonalization infidelity for 3- to 5-qubit modules (relative error <8 %), (ii) explicitly discusses the regime where multi-spectator or higher-order terms may violate additivity, and (iii) states that the reported performance gains should be viewed as estimates under the stated approximations. We believe these additions address the referee’s concern while preserving the core claims. revision: partial
-
Referee: [Frequency allocation results] The constrained optimization for frequency allocation incorporates realistic separation and hardware constraints, yet the manuscript does not report a sensitivity analysis on how the post-hoc minimum-frequency-separation thresholds were chosen or how they affect the resulting fidelity-connectivity tradeoff when module size increases. This choice is load-bearing for the claim that the allocation strategies remain scalable.
Authors: We agree that a sensitivity study is required to support the scalability statement. The revised manuscript now includes a new subsection (IV.B.3) and Figure 8 that systematically vary the minimum-frequency-separation threshold between 50 MHz and 200 MHz for module sizes up to 25 qubits. The fidelity-connectivity tradeoff curves remain qualitatively consistent across this range; only the absolute location of the optimal operating point shifts modestly. These results are summarized in the text and confirm that the reported allocation advantages are robust to reasonable variations in the separation constraint. revision: yes
Circularity Check
No significant circularity; results arise from external error model and optimization
full rationale
The paper introduces an error-budgeting model combining coherent spectator errors and incoherent lifetime effects, then uses it to formulate a constrained optimization for frequency allocation and to drive the FINESSE transpiler. The reported 8.9% log-infidelity and 6.8% depth reductions are empirical outcomes of running this optimization and comparing against SABRE on SNAIL architectures, not quantities defined inside the same equations or obtained by fitting parameters to the target metrics. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the derivation chain. The model is presented as an independent input whose validity is an external assumption rather than a tautology internal to the reported numbers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Error budgeting that separately accounts for coherent spectator-induced errors and incoherent lifetime effects is sufficient to predict gate fidelity under frequency crowding.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We construct a physics-informed fidelity model that captures both types of errors... total coherent infidelity is ε_coh ≈ ∑ ε_avg^(i) ... combined infidelity is given by ε_gate ≈ 1 − (1−ε_inc) × (1−ε_coh).
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
FINESSE... minimizes error by selecting high-fidelity paths... log-infidelity cost
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
N Cody Jones, Rodney Van Meter, Austin G Fowler, Peter L McMahon, Jungsang Kim, Thaddeus D Ladd, and Yoshihisa Yamamoto. 2012. Layered architecture for quantum computing.Phys.Rev.X(2012). doi:10.1103/PhysRevX.2.031007
-
[2]
Evan McKinney, Mingkang Xia, Chao Zhou, Pinlei Lu, Michael Ha- tridge, and Alex K Jones. 2023. Co-designed architectures for modular superconducting quantum computers. In2023 IEEE International Sym- posium on High-Performance Computer Architecture (HPCA). IEEE, 759–772
work page 2023
-
[3]
Michael E Beverland, Prakash Murali, Matthias Troyer, Krysta M Svore, Torsten Hoefler, Vadym Kliuchnikov, Guang Hao Low, Mathias Soeken, Aarthi Sundaram, and Alexander Vaschillo. 2022. Assessing requirements to scale to practical quantum advantage.arXiv preprint arXiv:2211.07629(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Teague Tomesh and Margaret Martonosi. 2021. Quantum codesign. IEEE Micro41, 5 (2021), 33–40
work page 2021
-
[5]
Prakash Murali, David C McKay, Margaret Martonosi, and Ali Javadi- Abhari. 2020. Software mitigation of crosstalk on noisy intermediate- scale quantum computers. InProceedings of the Twenty-Fifth Interna- tional Conference on Architectural Support for Programming Languages and Operating Systems. 1001–1016
work page 2020
-
[6]
Prakash Murali, Norbert Matthias Linke, Margaret Martonosi, Ali Javadi Abhari, Nhung Hong Nguyen, and Cinthia Huerta Alderete
-
[7]
InProceedings of the 46th Interna- tional Symposium on Computer Architecture
Full-stack, real-system quantum computer studies: Architectural comparisons and design insights. InProceedings of the 46th Interna- tional Symposium on Computer Architecture. 527–540
-
[8]
Chao Zhou, Pinlei Lu, Matthieu Praquin, Tzu-Chiao Chien, Ryan Kauf- man, Xi Cao, Mingkang Xia, Roger SK Mong, Wolfgang Pfaff, David Pekker, et al. 2023. Realizing all-to-all couplings among detachable quantum modules using a microwave quantum state router.npj quan- tum information9, 1 (2023), 54. Fidelity-Aware Frequency Allocation and Transpilation Co-De...
work page 2023
-
[9]
Chow, Jared Hertzberg, Easwar Magesan, and Sami Rosenblatt
Markus Brink, Jerry M. Chow, Jared Hertzberg, Easwar Magesan, and Sami Rosenblatt. 2018. Device challenges for near term su- perconducting quantum processors: frequency collisions. InIEDM. doi:10.1109/IEDM.2018.8614500
-
[10]
Vinay Tripathi, Mostafa Khezri, and Alexander N Korotkov. 2019. Operation and intrinsic error budget of a two-qubit cross-resonance gate.Physical Review A100, 1 (2019), 012301
work page 2019
- [11]
-
[12]
Eyob A Sete, Vinay Tripathi, Joseph A Valery, Daniel Lidar, and Josh Y Mutus. 2024. Error budget of a parametric resonance entangling gate with a tunable coupler.Physical Review Applied22, 1 (2024), 014059
work page 2024
-
[13]
Gushu Li, Yufei Ding, and Yuan Xie. 2020. Towards efficient super- conducting quantum processor architecture design. InProceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems. 1031–1045
work page 2020
-
[14]
Yongshan Ding, Pranav Gokhale, Sophia Fuhui Lin, Richard Rines, Thomas Propson, and Frederic T Chong. 2020. Systematic crosstalk mitigation for superconducting qubits via frequency-aware compi- lation. In2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 201–214
work page 2020
-
[15]
Kaitlin N Smith, Gokul Subramanian Ravi, Jonathan M Baker, and Frederic T Chong. 2022. Scaling superconducting quantum comput- ers with chiplet architectures. In2022 55th IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 1092–1109
work page 2022
-
[16]
Alexis Morvan, Larry Chen, Jeffrey M. Larson, David I. Santiago, and Irfan Siddiqi. 2022. Optimizing frequency allocation for fixed- frequency superconducting quantum processors.Phys.Rev.Res.(April 2022). doi:10.1103/PhysRevResearch.4.023079
-
[17]
Amr Osman, Jorge Fernández-Pendás, Christopher Warren, San- doko Kosen, Marco Scigliuzzo, Anton Frisk Kockum, Giovanna Tan- credi, Anita Fadavi Roudsari, and Jonas Bylander. 2023. Mitiga- tion of frequency collisions in superconducting quantum processors. Phys.Rev.Res.(Oct. 2023). doi:10.1103/PhysRevResearch.5.043001
- [18]
-
[19]
Zewen Zhang, Pranav Gokhale, and Jeffrey M Larson. 2025. Efficient frequency allocation for superconducting quantum processors using improved optimization techniques.Physical Review A111, 1 (2025), 012619
work page 2025
-
[20]
Gushu Li, Yufei Ding, and Yuan Xie. 2019. Tackling the qubit map- ping problem for NISQ-era quantum devices. InProceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems. 1001–1014
work page 2019
-
[21]
Evan McKinney, Michael Hatridge, and Alex K Jones. 2024. MIRAGE: Quantum circuit decomposition and routing collaborative design using mirror gates. In2024 IEEE International Symposium on High- Performance Computer Architecture (HPCA). IEEE, 704–718
work page 2024
-
[22]
N.E. Frattini, U. Vool, A. Narla, K.M. Swila, and M.H. Devoret. 2017. 3-wave mixing Josephson dipole element.Applied physics letters110, 222603 (2017)
work page 2017
-
[23]
Jens Koch, M. Yul Terri, Jay Gambetta, A.A. Houck, D.I. Schuster, J. Majer, Alexandre Blais, M.H. Devoret, S.M. Girvin, et al. 2007. Charge- insensitive qubit design derived from the Cooper pair box.Physical Review Letters A(2007)
work page 2007
-
[24]
Michael A. Nielsen. 2002. A simple formula for the average gate fidelity of a quantum dynamical operation.Phys. Lett. A(Oct. 2002), 249–252. doi:10.1016/S0375-9601(02)01272-0
- [25]
-
[26]
Pranav Gokhale, Teague Tomesh, Martin Suchara, and Fred Chong
-
[27]
InPro- ceedings of the 2024 International Conference on Parallel Architectures VanAllen et al
Faster and more reliable quantum swaps via native gates. InPro- ceedings of the 2024 International Conference on Parallel Architectures VanAllen et al. and Compilation Techniques. 351–362
work page 2024
-
[28]
Ludwig Schmid, David F Locher, Manuel Rispler, Sebastian Blatt, Jo- hannes Zeiher, Markus Müller, and Robert Wille. 2024. Computational capabilities and compiler development for neutral atom quantum pro- cessors—connecting tool developers and hardware experts.Quantum Science and Technology9, 3 (2024), 033001
work page 2024
-
[29]
Jianxin Chen, Dawei Ding, Weiyuan Gong, Cupjin Huang, and Qi Ye
-
[30]
Plankton: Reconciling binary code and debug information
One Gate Scheme to Rule Them All: Introducing a Complex Yet Reduced Instruction Set for Quantum Computing. InASPLOS. doi:10.1145/3620665.3640386
-
[31]
Chao Zhou. 2023.Superconducting Quantum Routers, Modules, Gates, and Measurements Based on Charge-pumped Parametric Interactions. Ph. D. Dissertation. University of Pittsburgh
work page 2023
- [32]
- [33]
-
[34]
Evan McKinney, Chao Zhou, Mingkang Xia, Michael Hatridge, and Alex K Jones. 2023. Parallel driving for fast quantum computing under speed limits. InProceedings of the 50th Annual International Symposium on Computer Architecture. 1–13
work page 2023
-
[35]
Muñoz Arias, Cristóbal Lledó, Benjamin D’Anjou, and Alexandre Blais
Marie Frédérique Dumas, Benjamin Groleau-Paré, Alexander McDon- ald, Manuel H. Muñoz Arias, Cristóbal Lledó, Benjamin D’Anjou, and Alexandre Blais. 2024. Measurement-Induced Transmon Ioniza- tion.Phys. Rev. X14, 4 (2024), 041023. arXiv:2402.06615 [quant-ph] doi:10.1103/PhysRevX.14.041023
-
[36]
2021.Three-wave mixing in superconducting cir- cuits: stabilizing cats with SNAILs
Nicholas E Frattini. 2021.Three-wave mixing in superconducting cir- cuits: stabilizing cats with SNAILs. Ph. D. Dissertation. Yale University
work page 2021
-
[37]
Peter J. Larkin. 2018.Infrared and Raman Spectroscopy (Second Edition). Elsevier
work page 2018
-
[38]
Taehoon Park and Chae Y. Lee. 1996. Application of the Graph Color- ing Algorithm to the Frequency Assignment Problem.Journal of the Operations Research Society of Japan(1996). doi:10.15807/jorsj.39.258
-
[39]
2005.Graph colouring and frequency assignment
Robert James Waters. 2005.Graph colouring and frequency assignment. Ph. D. Dissertation. University of Nottingham
work page 2005
-
[40]
David Orden, Jose Manuel Gimenez-Guzman, Ivan Marsa-Maestre, and Enrique De la Hoz. 2018. Spectrum Graph Coloring and Applications to Wi-Fi Channel Assignment.Symmetry(March 2018). doi:10.3390/ sym10030065
work page 2018
-
[41]
Nargess Memarsadeghi. 2016. NASA computational case study: Golomb rulers and their applications.Computing in Science & En- gineering18, 06 (2016), 58–62
work page 2016
-
[42]
Christophe Meyer and Periklis A Papakonstantinou. 2009. On the com- plexity of constructing Golomb rulers.Discrete applied mathematics 157, 4 (2009), 738–748
work page 2009
- [43]
- [44]
- [45]
-
[46]
Qiskit contributors. 2023. Qiskit: An Open-source Framework for Quantum Computing. doi:10.5281/zenodo.2573505
-
[47]
Robert R Tucci. 2005. An introduction to Cartan’s KAK decomposition for QC programmers.arXiv preprint quant-ph/0507171(2005)
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[48]
Dylan VanAllen. 2026. FINESSE: Fidelity-Integrated Equivalence- Aware Swap Selection and Execution
work page 2026
-
[49]
Nils Quetschlich, Lukas Burgholzer, and Robert Wille. 2023. MQT Bench: Benchmarking Software and Design Automation Tools for Quantum Computing.Quantum(2023)
work page 2023
-
[50]
Ang Li, Samuel Stein, Sriram Krishnamoorthy, and James Ang. 2023. Qasmbench: A low-level quantum benchmark suite for nisq evaluation and simulation.ACM Transactions on Quantum Computing4, 2 (2023), 1–26
work page 2023
-
[51]
Evan McKinney, Chao Zhou, Mingkang Xia, Michael Hatridge, and Alex Jones. 2023. Using Quantum Hardware Speed Limits to Improve Basis Gate Selection. InAPS March Meeting Abstracts (APS Meeting Abstracts, Vol. 2023). Article G70.003, G70.003 pages
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.