Frequency-adaptive tensor neural networks for high-dimensional multi-scale problems
Pith reviewed 2026-05-18 21:33 UTC · model grok-4.3
The pith
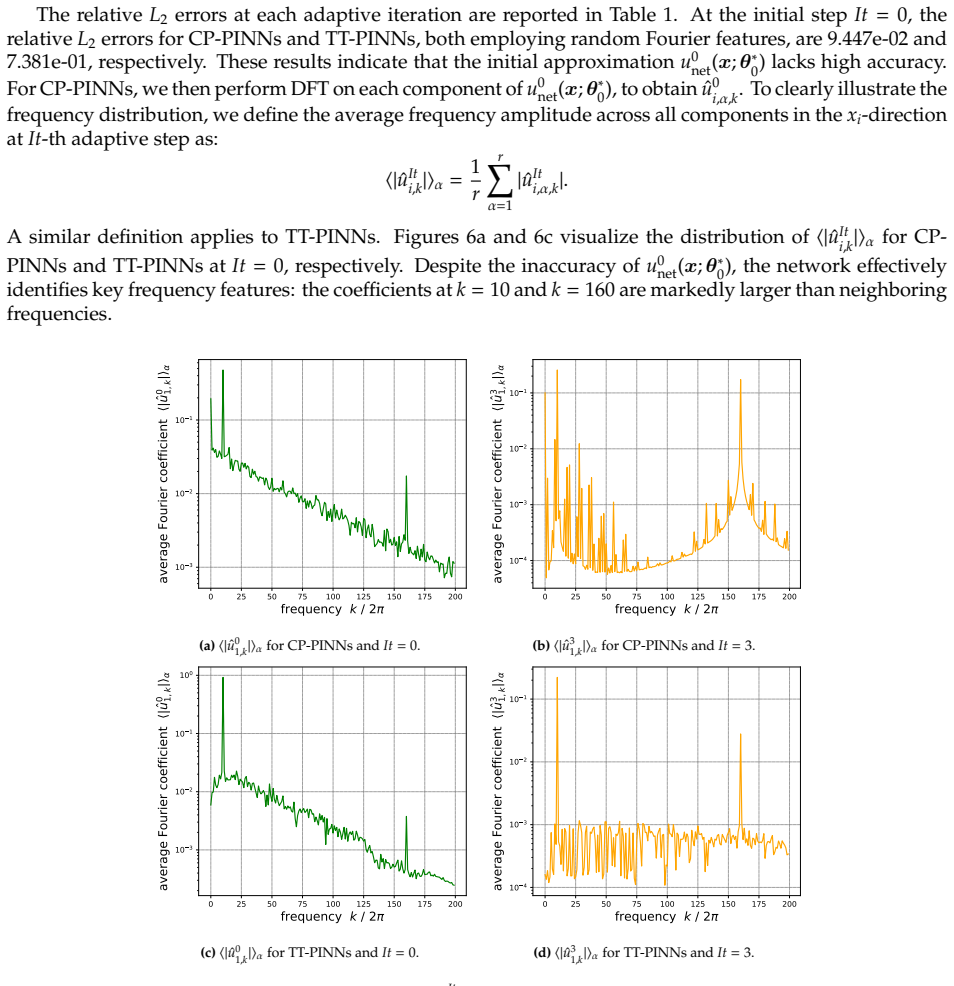
Tensor neural networks capture high-frequency features in high-dimensional multi-scale problems by applying discrete Fourier transforms to their one-dimensional component functions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
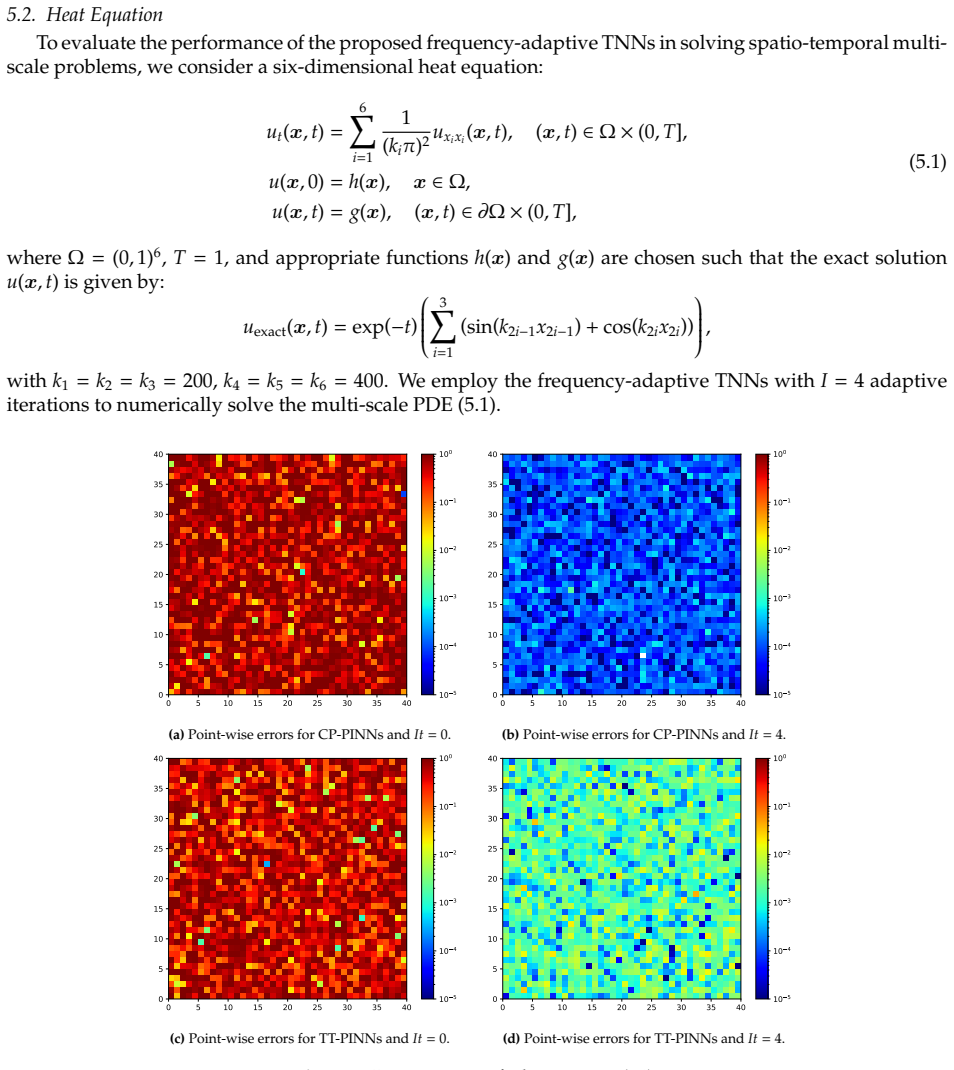
Performing the Discrete Fourier Transform on the one-dimensional component functions of a tensor neural network extracts the frequency content of the corresponding high-dimensional function without incurring the curse of dimensionality; combining this extraction with random Fourier features produces a frequency-adaptive TNN whose training dynamics can represent both low- and high-frequency structures, thereby enabling accurate solutions to high-dimensional multi-scale problems.
What carries the argument
Frequency-adaptive TNN algorithm that augments standard tensor networks with random Fourier features and extracts frequency information via discrete Fourier transforms applied separately to each one-dimensional component function.
If this is right
- TNNs can now represent solutions containing both smooth and oscillatory components in dimensions where direct high-dimensional Fourier analysis is infeasible.
- Training dynamics of tensor networks can be steered toward high-frequency modes without changing the underlying tensor decomposition.
- The same one-dimensional transform strategy can be reused inside other tensor-based solvers to add frequency awareness at modest extra cost.
- Robustness across different multi-scale regimes follows from the separation of frequency extraction from the high-dimensional representation.
Where Pith is reading between the lines
- The approach may generalize to other tensor decompositions or to physics-informed networks that already use Fourier features.
- It suggests a broader principle: frequency adaptation can be factored along the same low-rank structure used for the spatial representation itself.
- One could test whether the extracted frequencies can be updated dynamically during training rather than computed once in advance.
- Similar component-wise transforms might help other neural architectures that suffer from the frequency principle in high dimensions.
Load-bearing premise
That the frequency features of a high-dimensional function can be recovered accurately by transforming only its one-dimensional tensor factors rather than the full function.
What would settle it
A controlled numerical test on a known high-dimensional multi-scale function in which the frequency-adaptive TNN produces larger errors than a standard TNN or fails to recover the high-frequency components identified by full-dimensional Fourier analysis.
Figures








read the original abstract
Tensor neural networks (TNNs) have demonstrated their superiority in solving high-dimensional problems. However, similar to conventional neural networks, TNNs are also influenced by the Frequency Principle, which limits their ability to accurately capture high-frequency features of the solution. In this work, we analyze the training dynamics of TNNs by Fourier analysis and enhance their expressivity for high-dimensional multi-scale problems by incorporating random Fourier features. Leveraging the inherent tensor structure of TNNs, we further propose a novel approach to extract frequency features of high-dimensional functions by performing the Discrete Fourier Transform to one-dimensional component functions. This strategy effectively mitigates the curse of dimensionality. Building on this idea, we propose a frequency-adaptive TNNs algorithm, which significantly improves the ability of TNNs in solving complex multi-scale problems. Extensive numerical experiments are performed to validate the effectiveness and robustness of the proposed frequency-adaptive TNNs algorithm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes frequency-adaptive tensor neural networks (TNNs) for high-dimensional multi-scale problems. It analyzes TNN training dynamics via Fourier analysis, augments expressivity with random Fourier features, and introduces a method to extract frequency features of high-dimensional functions by applying the Discrete Fourier Transform to the one-dimensional component functions of the tensor decomposition. This is presented as mitigating the curse of dimensionality, yielding a frequency-adaptive algorithm that significantly improves TNN performance on complex multi-scale problems, supported by extensive numerical experiments.
Significance. If the central frequency-extraction step is shown to recover relevant modes even for non-separable targets, the work could offer a practical advance for scientific machine learning applications involving high-dimensional multi-scale functions, such as PDE solvers. The exploitation of tensor structure to perform only 1D DFTs is a conceptually appealing way to sidestep full high-dimensional Fourier analysis.
major comments (1)
- [frequency feature extraction procedure] The core technical claim (abstract and the description of the frequency-adaptive algorithm): performing the Discrete Fourier Transform on one-dimensional component functions is asserted to extract frequency features of high-dimensional functions while mitigating the curse of dimensionality. For non-separable multi-scale functions whose frequencies arise from cross-dimensional interactions (e.g., modes depending on sums or products of coordinates), the 1D marginal spectra do not contain the joint frequency information; the paper must therefore supply either a theoretical argument or a concrete numerical counter-example showing that the adaptation mechanism still targets the correct high-frequency content.
minor comments (2)
- [Abstract] The abstract states that 'extensive numerical experiments' validate the method but provides no information on test functions, baselines, error metrics, or quantitative gains; the main text should include a concise table summarizing these details for reproducibility.
- [Methods] Notation for the tensor decomposition and the frequency-adaptation step could be clarified with a small illustrative example in the methods section.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review of our manuscript. We address the major comment point by point below, providing clarification on the frequency extraction mechanism while remaining faithful to the paper's content and results.
read point-by-point responses
-
Referee: The core technical claim (abstract and the description of the frequency-adaptive algorithm): performing the Discrete Fourier Transform on one-dimensional component functions is asserted to extract frequency features of high-dimensional functions while mitigating the curse of dimensionality. For non-separable multi-scale functions whose frequencies arise from cross-dimensional interactions (e.g., modes depending on sums or products of coordinates), the 1D marginal spectra do not contain the joint frequency information; the paper must therefore supply either a theoretical argument or a concrete numerical counter-example showing that the adaptation mechanism still targets the correct high-frequency content.
Authors: We appreciate the referee's highlighting of this subtlety. In the tensor decomposition underlying TNNs (CP or tensor-train format), a high-dimensional function is expressed as a sum or contraction of products of one-dimensional component functions. Cross terms arising from coordinate sums or products (e.g., sin(x+y) expanding into products of trigonometric functions) are therefore encoded in the frequency content of the individual 1D components. Applying the 1D DFT to these components identifies the frequencies that, when combined through the tensor structure, produce the observed high-dimensional multi-scale behavior. This is consistent with the Fourier analysis of TNN training dynamics already developed in the manuscript. Our extensive numerical experiments (Section 5) include non-separable test problems with interacting scales, where the frequency-adaptive algorithm yields clear accuracy gains over baseline TNNs, confirming that the adaptation targets the relevant content in practice. We will insert a short clarifying paragraph in the revised version to make this tensor-structure argument explicit. revision: partial
Circularity Check
No significant circularity; frequency-adaptive TNNs defined via explicit construction and externally validated
full rationale
The paper defines its frequency-adaptive TNNs algorithm through a sequence of explicit constructions: Fourier analysis of TNN training dynamics, incorporation of random Fourier features, and a novel extraction of frequency features via DFT applied separately to the one-dimensional component functions of the tensor decomposition. These steps are presented as a methodological proposal whose effectiveness is then checked against external numerical experiments on multi-scale problems. No derivation reduces a claimed result to a fitted parameter renamed as prediction, no self-citation chain is invoked as load-bearing justification, and the mitigation of the curse of dimensionality follows directly from the stated algorithmic choice rather than from any self-referential definition. The overall chain therefore remains self-contained with independent empirical support.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Tensor neural networks are influenced by the Frequency Principle in the same way as conventional neural networks.
- ad hoc to paper Discrete Fourier Transform applied to one-dimensional component functions extracts frequency features of high-dimensional functions while mitigating the curse of dimensionality.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Leveraging the inherent tensor structure of TNNs, we further propose a novel approach to extract frequency features of high-dimensional functions by performing the Discrete Fourier Transform to one-dimensional component functions. This strategy effectively mitigates the curse of dimensionality.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define the spectral error ... and simplify it as ... gradients ... Hx(z) and Hy(z) decay exponentially ...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A. Krizhevsky, I. Sutskever, G. E. Hinton, Imagenet classification with deep convolutional neural networks, Advances in Neural Information Processing Systems 25 (2012)
work page 2012
-
[2]
G. Hinton, L. Deng, D. Yu, G. E. Dahl, A.-r. Mohamed, N. Jaitly, A. Senior, V . Vanhoucke, P . Nguyen, T. N. Sainath, et al., Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups, IEEE Signal Processing Magazine 29 (6) (2012) 82–97
work page 2012
-
[3]
Vaswani, Attention is all you need, Advances in Neural Information Processing Systems (2017)
A. Vaswani, Attention is all you need, Advances in Neural Information Processing Systems (2017)
work page 2017
-
[4]
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, BERT: Pre-training of deep bidirectional transformers for language understanding, in: NAACL-HLT 2019, (2019), pp. 4171–4186
work page 2019
- [5]
-
[6]
J. Han, A. Jentzen, et al., Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations, Communications in Mathematics and Statistics 5 (4) (2017) 349–380. 24
work page 2017
-
[7]
B. Yu, et al., The deep Ritz method: A deep learning-based numerical algorithm for solving variational problems, Communications in Mathematics and Statistics 6 (1) (2018) 1–12
work page 2018
-
[8]
Y. Zang, G. Bao, X. Ye, H. Zhou, Weak adversarial networks for high-dimensional partial di fferential equations, Journal of Computational Physics 411 (2020) 109409
work page 2020
- [9]
-
[10]
J. Han, A. Jentzen, W. E, Solving high-dimensional partial di fferential equations using deep learning, Proceedings of the National Academy of Sciences 115 (34) (2018) 8505–8510
work page 2018
-
[11]
J. Han, L. Zhang, R. Car, et al., Deep potential: A general representation of a many-body potential energy surface, Communications in Computational Physics, 23 (3) (2018) 629
work page 2018
-
[12]
J. He, L. Li, J. Xu, C. Zheng, Relu deep neural networks and linear finite elements, Journal of Compu- tational Mathematics, 38 (3) (2020) 502–527
work page 2020
-
[13]
Y. L. Ming, et al., Deep Nitsche method: Deep Ritz method with essential boundary conditions, Communications in Computational Physics, 29 (5) (2021) 1365–1384
work page 2021
- [14]
-
[15]
C. M. Strofer, J.-L. Wu, H. Xiao, E. Paterson, Data-driven, physics-based feature extraction from fluid flow fields using convolutional neural networks, Communications in Computational Physics 25 (3) (2019) 625–650
work page 2019
-
[16]
Z. Wang, Z. Zhang, A mesh-free method for interface problems using the deep learning approach, Journal of Computational Physics 400 (2020) 108963
work page 2020
-
[17]
N. Rahaman, A. Baratin, D. Arpit, F. Draxler, M. Lin, F. Hamprecht, Y. Bengio, A. Courville, On the spectral bias of neural networks, in: International Conference on Machine Learning, PMLR, (2019), pp. 5301–5310
work page 2019
-
[18]
Z. J. Xu, Understanding training and generalization in deep learning by Fourier analysis, CoRR abs/1808.04295 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Z.-Q. J. Xu, Frequency principle: Fourier analysis sheds light on deep neural networks, Communications in Computational Physics 28 (5) ((2020),) 1746–1767
work page 2020
-
[20]
Explicitizing an Implicit Bias of the Frequency Principle in Two-layer Neural Networks
Y. Zhang, Z.-Q. J. Xu, T. Luo, Z. Ma, Explicitizing an implicit bias of the frequency principle in two-layer neural networks, CoRR abs/1905.10264 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[21]
Z.-Q. J. Xu, Y. Zhang, Y. Xiao, Training behavior of deep neural network in frequency domain, in: Neural Information Processing: 26th International Conference, ICONIP 2019, Sydney, NSW, Australia, December 12–15, 2019, Proceedings, Part I 26, Springer, (2019), pp. 264–274
work page 2019
- [22]
- [23]
-
[24]
S. Zeng, Z. Zhang, Q. Zou, Adaptive deep neural networks methods for high-dimensional partial differential equations, Journal of Computational Physics 463 (2022) 111232
work page 2022
-
[25]
F. L. Hitchcock, The expression of a tensor or a polyadic as a sum of products, Journal of Mathematics and Physics 6 (1-4) (1927) 164–189. 25
work page 1927
-
[26]
L. R. Tucker, Some mathematical notes on three-mode factor analysis, Psychometrika 31 (3) (1966) 279–311
work page 1966
-
[27]
I. V . Oseledets, Tensor-train decomposition, SIAM Journal on Scientific Computing 33 (5) (2011) 2295– 2317
work page 2011
- [28]
-
[29]
M. Bachmayr, A. Cohen, Kolmogorov widths and low-rank approximations of parametric elliptic PDEs, Mathematics of Computation 86 (304) (2017) 701–724
work page 2017
-
[30]
A. Novikov, D. Podoprikhin, A. Osokin, D. P . Vetrov, Tensorizing neural networks, Advances in Neural Information Processing Systems 28 (2015)
work page 2015
-
[31]
P . Jin, S. Meng, L. Lu, MIONet: Learning multiple-input operators via tensor product, SIAM Journal on Scientific Computing 44 (6) (2022) A3490–A3514
work page 2022
-
[32]
S. K. Vemuri, T. Büchner, J. Niebling, J. Denzler, Functional tensor decompositions for physics-informed neural networks, in: International Conference on Pattern Recognition, Springer, (2025), pp. 32–46
work page 2025
-
[33]
Y. Wang, H. Xie, P . Jin, Tensor neural network and its numerical integration, Journal of Computational Mathematics 42 (6) (2024) 1714–1742
work page 2024
-
[34]
Z. Liu, W. Cai, Z.-Q. J. Xu, Multi-scale deep neural network (MscaleDNN) for solving Poisson- Boltzmann equation in complex domains, Communications in Computational Physics 28 (5) (2020) 1970–2001
work page 2020
-
[35]
L. Zhang, W. Cai, Z.-Q. J. Xu, A correction and comments on " multi-scale deep neural network (MscaleDNN) for solving Poisson-Boltzmann equation in complex domains cicp, 28 (5): 1970–2001, 2020", Communications in Computational Physics 33 (5) (2023) 1509–1513
work page 1970
-
[36]
M. Tancik, P . Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Raghavan, U. Singhal, R. Ramamoorthi, J. Barron, R. Ng, Fourier features let networks learn high frequency functions in low dimensional domains, Advances in Neural Information Processing Systems 33 (2020) 7537–7547
work page 2020
-
[37]
S. Wang, H. Wang, P . Perdikaris, On the eigenvector bias of Fourier feature networks: From regression to solving multi-scale PDEs with physics-informed neural networks, Computer Methods in Applied Mechanics and Engineering 384 (2021) 113938
work page 2021
- [38]
- [39]
- [40]
-
[41]
B. N. Khoromskij, C. Schwab, Tensor-structured Galerkin approximation of parametric and stochastic elliptic PDEs, SIAM Journal on Scientific Computing 33 (1) (2011) 364–385
work page 2011
- [42]
-
[43]
Y. Wang, Z. Lin, Y. Liao, H. Liu, H. Xie, Solving high-dimensional partial di fferential equations using tensor neural network and a posteriori error estimators, Journal of Scientific Computing 101 (3) (2024) 1–29. 26
work page 2024
- [44]
-
[45]
E. D. Zhong, T. Bepler, J. H. Davis, B. Berger, Reconstructing continuous distributions of 3D protein structure from cryo-EM images, in: International Conference on Learning Representations, (2020)
work page 2020
-
[46]
M. Chen, R. Niu, W. Zheng, Adaptive multi-scale neural network with Resnet blocks for solving partial differential equations, Nonlinear Dynamics 111 (7) (2023) 6499–6518
work page 2023
- [47]
- [48]
-
[49]
D. P . Kingma, J. Ba, Adam: A method for stochastic optimization, in: Proceedings of the 3rd International Conference on Learning Representations (ICLR), (2015)
work page 2015
-
[50]
I. E. Lagaris, A. Likas, D. I. Fotiadis, Artificial neural networks for solving ordinary and partial di ffer- ential equations, IEEE Transactions on Neural Networks 9 (5) (1998) 987–1000
work page 1998
-
[51]
S. Wang, S. Sankaran, P . Perdikaris, Respecting causality for training physics-informed neural networks, Computer Methods in Applied Mechanics and Engineering 421 (2024) 116813
work page 2024
-
[52]
W. Cai, X. Li, L. Liu, A phase shift deep neural network for high frequency approximation and wave problems, SIAM Journal on Scientific Computing 42 (5) (2020) A3285–A3312
work page 2020
-
[53]
A. D. Jagtap, K. Kawaguchi, G. E. Karniadakis, Adaptive activation functions accelerate convergence in deep and physics-informed neural networks, Journal of Computational Physics 404 (2020) 109136
work page 2020
- [54]
-
[55]
J. Chen, X. Chi, Z. Yang, et al., Bridging traditional and machine learning-based algorithms for solving PDEs: The random feature method, J Mach Learn 1 (2022) 268–98
work page 2022
-
[56]
G. Beylkin, M. J. Mohlenkamp, Numerical operator calculus in higher dimensions, Proceedings of the National Academy of Sciences 99 (16) (2002) 10246–10251
work page 2002
-
[57]
G. Beylkin, M. J. Mohlenkamp, Algorithms for numerical analysis in high dimensions, SIAM Journal on Scientific Computing 26 (6) (2005) 2133–2159
work page 2005
-
[58]
C. Wu, M. Zhu, Q. Tan, Y. Kartha, L. Lu, A comprehensive study of non-adaptive and residual-based adaptive sampling for physics-informed neural networks, Computer Methods in Applied Mechanics and Engineering 403 (2023) 115671
work page 2023
-
[59]
Z. Gao, L. Yan, T. Zhou, Failure-informed adaptive sampling for PINNs, SIAM Journal on Scientific Computing 45 (4) (2023) A1971–A1994
work page 2023
-
[60]
K. Tang, X. Wan, C. Yang, DAS-PINNs: A deep adaptive sampling method for solving high-dimensional partial differential equations, Journal of Computational Physics 476 (2023) 111868
work page 2023
- [61]
-
[62]
X.-A. Li, Z.-Q. J. Xu, L. Zhang, Subspace decomposition based DNN algorithm for elliptic type multi- scale PDEs, Journal of Computational Physics 488 (2023) 112242. 27 Appendix A. Computational Details The gradient of spectral loss L(kx, ky) with respect to wx,j is calculated as: ∂L(kx, ky) ∂wx,j = D(kx, ky) ∂D(kx, ky) ∂wx,j + D(kx, ky) ∂D(kx, ky) ∂wx,j =...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.