ChatHealthAI: Aligning Electronic Health Record Representations with Large Language Models for Grounded Clinical Reasoning
Pith reviewed 2026-06-28 14:20 UTC · model grok-4.3
The pith
ChatHealthAI aligns EHR foundation model representations with frozen LLMs through a task-aware resampler to enable grounded natural-language clinical reasoning while preserving predictive accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
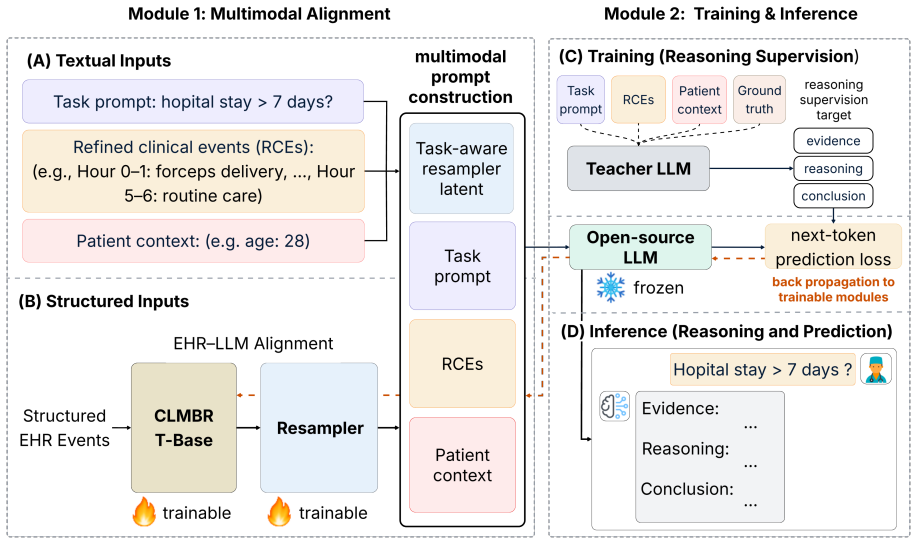
ChatHealthAI is a multimodal reasoning framework that aligns structured EHR representations from a pretrained EHR foundation model with the semantic space of a frozen LLM through a task-aware resampler; by integrating longitudinal patient representations with refined clinical event descriptions, it enables clinically grounded natural-language reasoning while maintaining accurate patient prediction.
What carries the argument
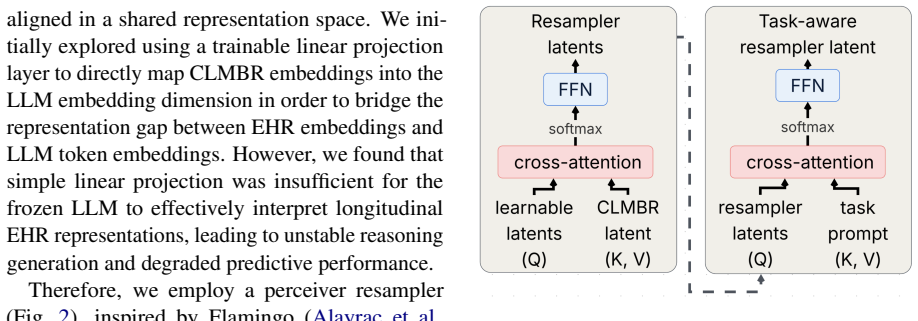
The task-aware resampler, which maps EHR foundation model representations into the LLM semantic space.
If this is right
- Natural-language reasoning on longitudinal EHR data becomes clinically grounded rather than hallucinated.
- Interpretability of patient predictions increases through language-based explanations.
- Predictive performance on clinical tasks remains competitive with standalone EHR models.
- The same alignment approach supports multiple downstream clinical predictive tasks.
Where Pith is reading between the lines
- The resampler technique could be tested on non-healthcare longitudinal datasets to check generality.
- Interactive clinical systems might use the language outputs for real-time physician queries.
- If the alignment holds, it reduces the need for separate fine-tuning of LLMs on raw EHR tokens.
- Performance on rare events or long time horizons could be checked as a next measurement.
Load-bearing premise
The task-aware resampler can map EHR foundation model representations into the LLM semantic space without substantial loss of predictive signal or introduction of reasoning artifacts.
What would settle it
An experiment showing that the resampler produces either a significant drop in predictive performance on the EHRSHOT tasks or reasoning outputs that fail to ground in the original EHR data compared to unaligned baselines.
Figures
read the original abstract
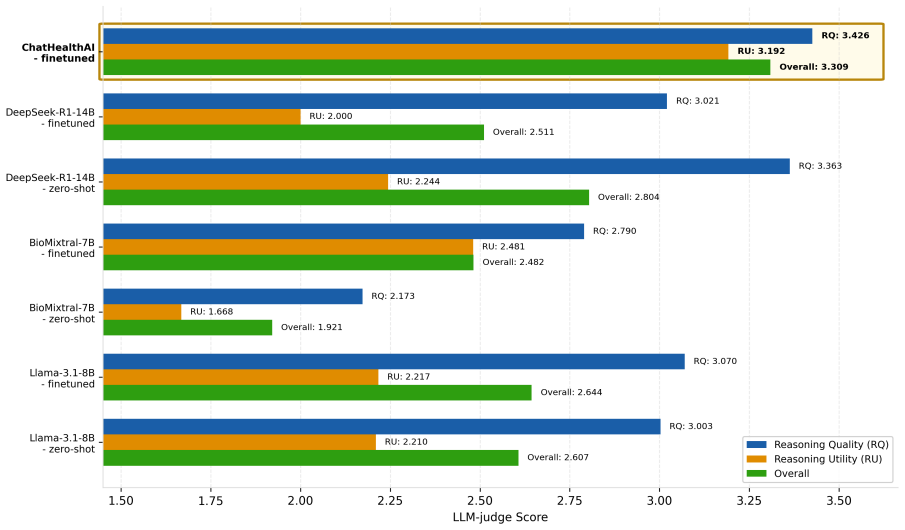
Large language models (LLMs) exhibit strong natural-language reasoning abilities for clinical decision support, but struggle to effectively model structured longitudinal electronic health records (EHRs). In contrast, EHR foundation models can learn predictive patient representations, yet lack interpretable language-based reasoning. To bridge this gap, we propose ChatHealthAI, a multimodal reasoning framework that aligns structured EHR representations from a pretrained EHR foundation model with the semantic space of a frozen LLM through a task-aware resampler. By integrating longitudinal patient representations with refined clinical event descriptions, ChatHealthAI enables clinically grounded natural-language reasoning while maintaining accurate patient prediction. We evaluated ChatHealthAI on three clinical predictive tasks from the EHRSHOT benchmark. Results show that ChatHealthAI improves reasoning quality and interpretability while preserving competitive predictive performance. These findings highlight the potential of integrating EHR foundation models with pretrained LLMs for interpretable clinical prediction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ChatHealthAI, a multimodal framework that aligns longitudinal EHR representations from a pretrained foundation model with the semantic space of a frozen LLM via a task-aware resampler, combined with refined clinical event descriptions, to enable grounded natural-language reasoning on clinical tasks while preserving predictive accuracy. It reports evaluation on three EHRSHOT benchmark tasks, claiming improved reasoning quality and interpretability alongside competitive predictive performance.
Significance. If the alignment mechanism demonstrably preserves predictive signal without introducing artifacts, the work would address a meaningful gap between high-accuracy EHR foundation models and interpretable LLM-based reasoning in clinical AI, potentially enabling more transparent decision support systems.
major comments (2)
- [Abstract] Abstract: the central claim that the task-aware resampler 'maintains accurate patient prediction' and yields 'competitive predictive performance' is unsupported by any quantitative metrics, baseline comparisons, deltas, statistical tests, or ablation results, leaving the no-substantial-loss assumption unverified and load-bearing for the overall contribution.
- [Evaluation] Evaluation section (referenced via EHRSHOT tasks): no ablation removing the resampler or direct comparison to the base EHR foundation model is described, so it is impossible to confirm that mapping to LLM space does not degrade predictive signal as required by the framework's design.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments correctly identify areas where quantitative support for the central claims can be strengthened. We address each point below and will revise the manuscript to incorporate the requested evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the task-aware resampler 'maintains accurate patient prediction' and yields 'competitive predictive performance' is unsupported by any quantitative metrics, baseline comparisons, deltas, statistical tests, or ablation results, leaving the no-substantial-loss assumption unverified and load-bearing for the overall contribution.
Authors: We agree that the abstract would be strengthened by explicit quantitative support. The evaluation on EHRSHOT tasks includes performance numbers that underpin the claim of competitive predictive performance, but these are not summarized in the abstract. We will revise the abstract to include specific metrics, baseline comparisons, deltas, and statistical details from the experiments. revision: yes
-
Referee: [Evaluation] Evaluation section (referenced via EHRSHOT tasks): no ablation removing the resampler or direct comparison to the base EHR foundation model is described, so it is impossible to confirm that mapping to LLM space does not degrade predictive signal as required by the framework's design.
Authors: We agree that an explicit ablation comparing the full model against the base EHR foundation model (without the task-aware resampler) is needed to directly verify preservation of predictive signal. We will add this ablation study, including the relevant metrics and comparisons, to the evaluation section. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents an architectural framework (task-aware resampler aligning EHR representations to LLM space) and reports empirical results on EHRSHOT tasks. No equations, derivations, or mathematical claims appear in the provided text. The central claim is an empirical integration result rather than a reduction of a 'prediction' to fitted inputs or a self-citation chain. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked. The derivation is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Retrieval-Augmented Generation for Large Language Models: A Survey
Retain: An interpretable predictive model for healthcare using reverse time attention mechanism. InAdvances in Neural Information Processing Sys- tems, volume 29. Emily Croxford and 1 others. 2025. Automating evalu- ation of ai text generation in healthcare with a large language model.medRxiv. Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Y...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Biomistral: A collection of open-source pretrained large language models for medical domains,
Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. InFindings of the Association for Com- putational Linguistics: ACL 2023, pages 8003–8017. Association for Computational Linguistics. Andrew Jaegle, Felix Gimeno, Andrew Brock, Andrew Zisserman, Oriol Vinyals, and Joao Carreira. 2021. Perceiver: G...
-
[3]
Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large lan- guage models.arXiv preprint arXiv:2301.12597. Yikuan Li, Shishir Rao, José Roberto Ayala Solares, Abdelaali Hassaine, Rema Ramakrishnan, Dexter Canoy, Yajie Zhu, Kazem Rahimi, and Gholamreza Salimi-Khorshidi. 2020. Behrt: Transformer for elec- tronic health recor...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[4]
Capabilities of Gemini Models in Medicine
Capabilities of gemini models in medicine. arXiv preprint arXiv:2404.18416. Karan Singhal, Shekoofeh Azizi, Tao Tu, S. Sara Mah- davi, Jason Wei, Hyung Won Chung, Nathan Scales, 10 Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, and 1 others. 2023. Large language models encode clinical knowledge.Nature, 620(7972):172–180. Karan Singhal, Tao Tu, Juraj Got...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Patient clinical events
-
[6]
Expected structure:
Model-generated explanation. Expected structure:
-
[7]
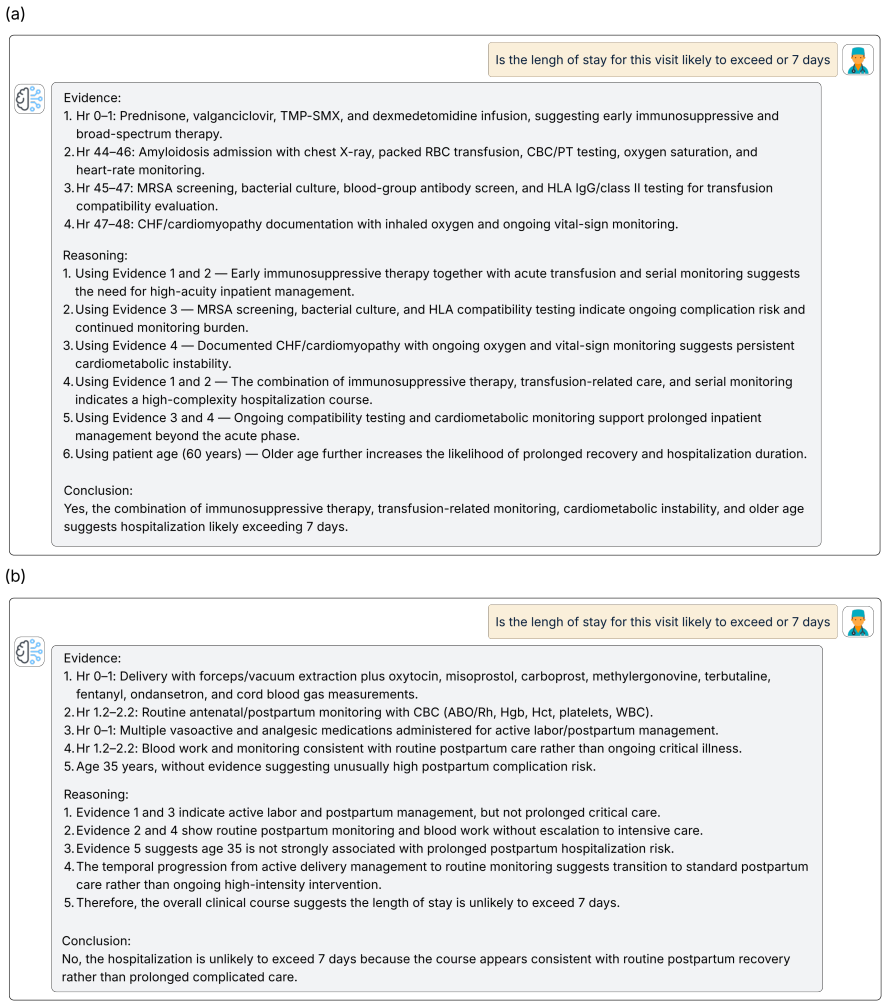
Evidence: a numbered list of clinical evidence items
-
[8]
Reasoning: step-by-step reasoning that refers back to the evidence
-
[9]
Evaluate all dimensions on a 1–5 Likert scale
Conclusion: a final Yes/No prediction with a short explanation. Evaluate all dimensions on a 1–5 Likert scale. General scoring guide • 1 = Poor:mostly incorrect, unsupported, incoherent, or misleading. •2 = Weak:contains major problems, but a small portion is acceptable. •3 = Fair:partially correct and usable, but with clear limitations. •4 = Good:mostly ...
-
[10]
• 2 = several important unsupported claims
evidence_grounding Does each Evidence item and major reasoning claim come from the provided clinical events or patient context? • 1 = mostly hallucinated or unsupported. • 2 = several important unsupported claims. • 3 = partially grounded, but some claims are vague or weakly supported. • 4 = mostly grounded, with only minor unsupported 12 or vague claims....
-
[11]
• 2 = limited relevance; many selected events do not help answer the task
clinical_relevance Is the selected evidence relevant to the task instruction? • 1 = mostly irrelevant evidence. • 2 = limited relevance; many selected events do not help answer the task. • 3 = mixed relevant and irrelevant evidence. • 4 = mostly relevant evidence, with minor irrelevant details. • 5 = highly relevant evidence that directly supports the cli...
-
[12]
• 2 = mentions time but does not use it meaningfully
temporal_reasoning Does the explanation correctly reason over the event timeline? • 1 = ignores or misuses temporal order. • 2 = mentions time but does not use it meaningfully. • 3 = partially uses temporal sequence. • 4 = mostly uses temporal progression correctly. • 5 = clearly reasons over progression, escalation, de-escalation, or stability over time
-
[13]
• 2 = weak clinical logic with major gaps
clinical_coherence Is the reasoning medically plausible and internally consistent? • 1 = clinically incoherent or contradictory. • 2 = weak clinical logic with major gaps. • 3 = partially coherent but unclear or incomplete. • 4 = mostly coherent and medically plausible. • 5 = clinically coherent, plausible, and internally consistent
-
[14]
• 2 = missing several important pieces of evidence
completeness Does the explanation provide enough evidence to justify the conclusion? • 1 = insufficient explanation. • 2 = missing several important pieces of evidence. • 3 = partially sufficient but incomplete. • 4 = mostly complete with minor omissions. • 5 = complete and well-supported
-
[15]
• 2 = several unsupported severity or causal claims
safety_overclaiming Does the explanation avoid unsupported severity claims, diagnoses, causal claims, risk claims, or misleading wording? • 1 = frequent overclaiming or potentially unsafe claims. • 2 = several unsupported severity or causal claims. • 3 = some overclaiming or unsupported wording. • 4 = mostly cautious, with minor wording issues. • 5 = caut...
-
[16]
• 2 = mostly misaligned with the correct outcome
outcome_alignment Does the final prediction and explanation align with the ground-truth label? • 1 = prediction/conclusion is wrong or explanation supports the wrong outcome. • 2 = mostly misaligned with the correct outcome. • 3 = partially aligned but ambiguous or weak. • 4 = mostly aligned with the correct outcome. • 5 = clearly aligned with the correct outcome
-
[17]
severe”, “high-acuity
clinical_usefulness Would this explanation help a clinician understand the prediction? • 1 = misleading, unsafe, or clinically unhelpful. • 2 = weak usefulness; may confuse the reader. • 3 = somewhat useful but incomplete or partly misleading. • 4 = clinically useful with minor limitations. • 5 = highly useful, well grounded, and decision-relevant. Task-s...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.