REDI-Match: Rotation-Equivariant Distillation for Efficient and Robust Dense Matching
Pith reviewed 2026-07-01 06:59 UTC · model grok-4.3
The pith
REDI-Match distills semantic representations from vision foundation models into a lightweight rotation-equivariant encoder to overcome rotation challenges in dense matching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
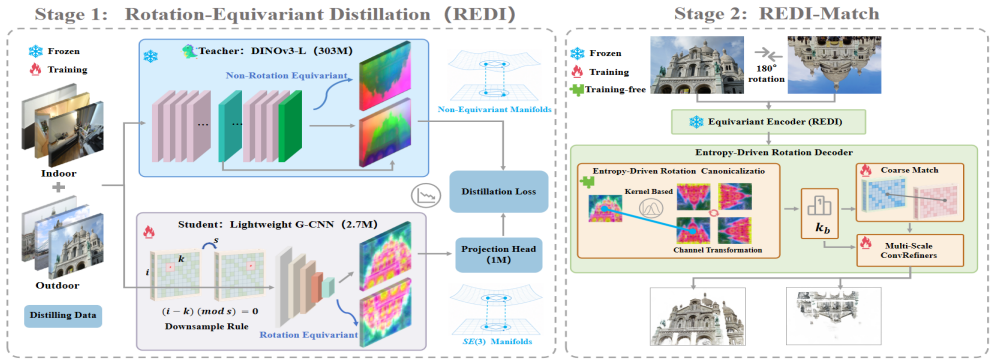
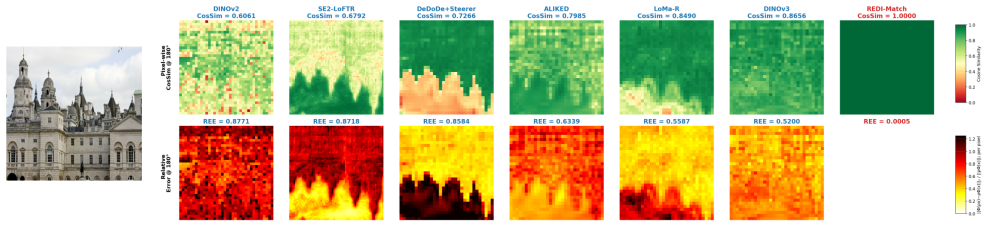
REDI-Match establishes a new state-of-the-art across multiple benchmarks by using a Rotation-Equivariant Distillation paradigm that transfers the non-equivariant semantic representations of a VFM into a lightweight strictly rotation-equivariant encoder, leveraging an equivariant geometric architecture to constrain robust high-dimensional semantics, and equipping the decoder with an entropy-driven spatial alignment module that evaluates discrete rotation hypotheses to lock onto the canonical coordinate system before continuous refinement.
What carries the argument
Rotation-Equivariant Distillation (REDI) paradigm, which transfers semantics from a VFM while enforcing strict rotational equivariance via geometric architecture constraints on the encoder.
If this is right
- Achieves new state-of-the-art performance across multiple dense matching benchmarks.
- Delivers a 13.89% absolute improvement in pose accuracy on the SatAst dataset.
- Runs 1.9 times faster than the prior state-of-the-art method while maintaining higher accuracy.
- Supports real-time inference at approximately 41 frames per second on a single consumer GPU.
Where Pith is reading between the lines
- The same distillation approach could extend to other geometric properties such as scale or reflection equivariance in matching tasks.
- Lightweight equivariant encoders produced this way might replace full VFMs in other geometry-sensitive vision pipelines where compute is limited.
- Testing the framework on synthetic rotations outside the training distribution would clarify how well the equivariance generalizes beyond observed angles.
Load-bearing premise
The non-equivariant semantic representations of a VFM can be distilled into a lightweight strictly rotation-equivariant encoder while preserving the robust high-dimensional semantics required for accurate dense matching.
What would settle it
An experiment showing that the distilled equivariant encoder yields matching accuracy no higher than a non-distilled equivariant baseline on a dataset with extreme in-plane rotations, indicating loss of semantic capacity during distillation.
Figures



read the original abstract
Vision Foundation Models (VFMs) have significantly advanced dense feature matching, yet severe in-plane rotation remains a critical challenge. Existing solutions face a fundamental dilemma: data-driven methods require inefficient parameter scaling to implicitly learn rotations, whereas strictly equivariant networks lack the semantic capacity of modern VFMs. Consequently, current frameworks typically freeze VFMs and shift the entire burden of rotation generalization to the downstream decoder. To break this architectural bottleneck, we propose REDI-Match, an efficient framework driven by a novel Rotation-Equivariant Distillation (REDI) paradigm. Instead of relying on rotation data augmentation to establish rotational correspondences, REDI distills the non-equivariant semantic representations of a VFM into a lightweight, strictly rotation-equivariant encoder, leveraging an equivariant geometric architecture to constrain robust high-dimensional semantics. To fully exploit these features, we equip the decoder with an entropy-driven spatial alignment module. By evaluating discrete rotation hypotheses, this mechanism explicitly locks onto the canonical coordinate system, eliminating global ambiguity before continuous refinement. Extensive experiments demonstrate that REDI-Match establishes a new state-of-the-art (SOTA) across multiple benchmarks. Notably, it achieves a 13.89% absolute pose accuracy improvement on the highly challenging SatAst dataset while operating 1.9x faster than the current SOTA (RoMa v2), enabling real-time inference (~41 FPS) on a single RTX 4090 GPU. Code: https://github.com/YinjiGe/REDI-Match.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces REDI-Match for dense feature matching under severe in-plane rotations. It proposes the Rotation-Equivariant Distillation (REDI) paradigm to transfer semantic representations from a frozen non-equivariant Vision Foundation Model into a lightweight strictly rotation-equivariant encoder, using an equivariant geometric architecture to constrain high-dimensional semantics. The decoder is augmented with an entropy-driven spatial alignment module that evaluates discrete rotation hypotheses to resolve global ambiguity before refinement. The authors report new state-of-the-art results across benchmarks, including a 13.89% absolute pose accuracy gain on SatAst and 1.9× faster inference than RoMa v2 at ~41 FPS on an RTX 4090.
Significance. If the REDI distillation step demonstrably preserves the semantic richness of the VFM within the equivariant encoder (rather than collapsing it under the inductive bias), the framework would resolve a recognized architectural trade-off between strict equivariance and semantic capacity. The reported combination of accuracy gains on a challenging dataset and real-time speed would constitute a practical advance for rotation-robust matching if the performance attribution holds.
major comments (2)
- [Abstract] Abstract: The central performance claims (13.89% pose accuracy improvement on SatAst, 1.9× speedup) rest on the unverified assertion that REDI successfully distills 'robust high-dimensional semantics' from a non-equivariant VFM into a strictly rotation-equivariant encoder. No derivation, feature-space comparison, or ablation is supplied to show that semantic capacity is retained rather than reduced by the equivariant constraint; without this evidence the gains cannot be attributed to the claimed architectural breakthrough.
- [Abstract] Abstract: The entropy-driven spatial alignment module is described only at a high level ('evaluates discrete rotation hypotheses... explicitly locks onto the canonical coordinate system'). No equation, pseudocode, or analysis is given for how entropy is computed or how the discrete-to-continuous transition is performed, leaving open whether the module introduces additional hyperparameters or post-hoc choices that affect the reported results.
minor comments (1)
- The abstract states 'extensive experiments demonstrate' SOTA results but supplies neither dataset details, baseline implementations, nor error bars; these must be expanded in the full manuscript for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, clarifying the evidence in the full manuscript and indicating where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claims (13.89% pose accuracy improvement on SatAst, 1.9× speedup) rest on the unverified assertion that REDI successfully distills 'robust high-dimensional semantics' from a non-equivariant VFM into a strictly rotation-equivariant encoder. No derivation, feature-space comparison, or ablation is supplied to show that semantic capacity is retained rather than reduced by the equivariant constraint; without this evidence the gains cannot be attributed to the claimed architectural breakthrough.
Authors: The full manuscript supplies the requested evidence: Section 3.2 derives the REDI distillation objective, and Section 4.3 reports feature-space comparisons (cosine similarity distributions and t-SNE visualizations) together with an ablation isolating the contribution of the equivariant constraint versus semantic retention. These results directly link the preserved capacity to the reported accuracy gains. To make the attribution explicit for readers who focus on the abstract, we will add a brief clause referencing these analyses. revision: yes
-
Referee: [Abstract] Abstract: The entropy-driven spatial alignment module is described only at a high level ('evaluates discrete rotation hypotheses... explicitly locks onto the canonical coordinate system'). No equation, pseudocode, or analysis is given for how entropy is computed or how the discrete-to-continuous transition is performed, leaving open whether the module introduces additional hyperparameters or post-hoc choices that affect the reported results.
Authors: We agree the abstract is high-level. Section 3.4 provides the entropy formula (Equation 6), the discrete hypothesis selection procedure, the continuous refinement step, and Algorithm 1 (pseudocode). The module uses only the rotation hypotheses already enumerated in the equivariant encoder and introduces no extra hyperparameters. We will revise the abstract to include a short reference to the entropy computation and the deterministic selection rule. revision: yes
Circularity Check
No circularity: REDI-Match claims rest on empirical benchmark results, not self-referential definitions or fitted inputs.
full rationale
The paper proposes a new REDI distillation paradigm that transfers semantics from a frozen VFM into a lightweight rotation-equivariant encoder, followed by an entropy-driven alignment module. No equations, self-citations, or steps are presented that reduce the claimed SOTA gains (e.g., 13.89% pose accuracy on SatAst) to quantities defined by construction from the inputs or prior fitted parameters. The derivation is self-contained: the method is described as an architectural innovation whose validity is asserted via external experimental evaluation rather than internal identities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Vision foundation models contain transferable semantic representations that remain useful when mapped to strictly equivariant architectures
invented entities (1)
-
Rotation-Equivariant Distillation (REDI) paradigm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Hpatches: A benchmark and evaluation of handcrafted and learned local descriptors
Vassileios Balntas, Karel Lenc, Andrea Vedaldi, and Krys- tian Mikolajczyk. Hpatches: A benchmark and evaluation of handcrafted and learned local descriptors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5173–5182, 2017. 6
2017
-
[2]
A case for using rotation invariant features in state of the art feature matchers
Georg B¨okman and Fredrik Kahl. A case for using rotation invariant features in state of the art feature matchers. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition Workshops (CVPRW), pages 5110–5119, 2022. 2, 6, 7
2022
-
[3]
Steerers: A framework for rotation equivariant keypoint descriptors
Georg B¨okman, Johan Edstedt, Michael Felsberg, and Fredrik Kahl. Steerers: A framework for rotation equivariant keypoint descriptors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4885–4895, 2024. 3, 6, 7
2024
-
[4]
Improving Transformer-based Image Matching by Cascaded Capturing Spatially Informative Keypoints
Chenjie Cao and Yanwei Fu. Improving Transformer-based Image Matching by Cascaded Capturing Spatially Informative Keypoints. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 12095–12105,
-
[5]
Emerg- ing properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerg- ing properties in self-supervised vision transformers. InPro- ceedings of the IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 9650–9660, 2021. 1, 3
2021
-
[6]
RDD: Robust Feature De- tector and Descriptor using Deformable Transformer
Gonglin Chen, Tianwen Fu, Haiwei Chen, Wenbin Teng, Hanyuan Xiao, and Yajie Zhao. RDD: Robust Feature De- tector and Descriptor using Deformable Transformer. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6394–6403, 2025. 3
2025
-
[7]
ASpanFormer: Detector-Free Image Matching with Adaptive Span Transformer
Hongkai Chen, Zixin Luo, Lei Zhou, Yurun Tian, Ming- min Zhen, Tian Fang, David McKinnon, Yanghai Tsin, and Long Quan. ASpanFormer: Detector-Free Image Matching with Adaptive Span Transformer. InEuropean Conference on Computer Vision (ECCV 2022), pages 20–36, 2022. 3, 7
2022
-
[8]
Group equivariant convolu- tional networks
Taco Cohen and Max Welling. Group equivariant convolu- tional networks. InProceedings of the International Confer- ence on Machine Learning (ICML), pages 2990–2999, 2016. 2, 3
2016
-
[9]
Cohen and Max Welling
Taco S. Cohen and Max Welling. Steerable cnns. InInterna- tional Conference on Learning Representations (ICLR), 2017. 2, 3
2017
-
[10]
Scannet: Richly- annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly- annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5828–5839, 2017. 6
2017
-
[11]
Superpoint: Self-supervised interest point detection and description
Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabi- novich. Superpoint: Self-supervised interest point detection and description. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 224–236, 2018. 3, 7
2018
-
[12]
van Gemert
Tom Edixhoven, Attila Lengyel, and Jan C. van Gemert. Using and abusing equivariance. InProceedings of the IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), pages 119–128. IEEE, 2023. 4
2023
-
[13]
Dkm: Dense kernelized feature matching for geometry estimation
Johan Edstedt, Ioannis Athanasiadis, M˚arten Wadenb¨ack, and Michael Felsberg. Dkm: Dense kernelized feature matching for geometry estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17765–17775, 2023. 1, 3, 6, 7
2023
-
[14]
Dedode: Detect, don’t describe—describe, don’t detect for local feature matching
Johan Edstedt, Georg B ¨okman, M ˚arten Wadenb ¨ack, and Michael Felsberg. Dedode: Detect, don’t describe—describe, don’t detect for local feature matching. InProceedings of the IEEE International Conference on 3D Vision (3DV), pages 148–157. IEEE, 2024. 3
2024
-
[15]
Dedode v2: Analyzing and improving the dedode keypoint detector
Johan Edstedt, Georg B¨okman, and Zhenjun Zhao. Dedode v2: Analyzing and improving the dedode keypoint detector. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4245–4253,
-
[16]
RoMa: Robust Dense Feature Match- ing
Johan Edstedt, Qiyu Sun, Georg B¨okman, M˚arten Wadenb¨ack, and Michael Felsberg. RoMa: Robust Dense Feature Match- ing. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), pages 19790– 19800, 2024. 1, 3, 6, 7
2024
-
[17]
arXiv preprint arXiv:2511.15706 (2025)
Johan Edstedt, David Nordstr ¨om, Yushan Zhang, Georg B¨okman, Jonathan Astermark, Viktor Larsson, Anders Hey- den, Fredrik Kahl, M˚arten Wadenb¨ack, and Michael Felsberg. Roma v2: Harder better faster denser feature matching.arXiv preprint arXiv:2511.15706, 2025. 2, 3, 6, 7
-
[18]
Top- icfm: Robust and interpretable topic-assisted feature match- ing
Khang Truong Giang, Soohwan Song, and Sungho Jo. Top- icfm: Robust and interpretable topic-assisted feature match- ing. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), pages 2447–2455, 2023. 3
2023
-
[19]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distill- ing the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015. 3
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[20]
Image match- ing across wide baselines: From paper to practice.Interna- tional Journal of Computer Vision (IJCV), 129(2):517–547,
Yuhe Jin, Dmytro Mishkin, Anastasiia Mishchuk, Jiri Matas, Pascal Fua, Kwang Moo Yi, and Eduard Trulls. Image match- ing across wide baselines: From paper to practice.Interna- tional Journal of Computer Vision (IJCV), 129(2):517–547,
-
[21]
Learning rotation-equivariant features for visual cor- respondence
Jongmin Lee, Byungjin Kim, Seungwook Kim, and Minsu Cho. Learning rotation-equivariant features for visual cor- respondence. InProceedings of the IEEE/CVF Conference 9 on Computer Vision and Pattern Recognition (CVPR), pages 21887–21897, 2023. 2, 6
2023
-
[22]
Megadepth: Learning single- view depth prediction from internet photos
Zhengqi Li and Noah Snavely. Megadepth: Learning single- view depth prediction from internet photos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2041–2050, 2018. 6
2041
-
[23]
CoMatch: Dynamic Covisibility-Aware Transformer for Bilateral Subpixel-Level Semi-Dense Image Matching
Zizhuo Li, Yifan Lu, Linfeng Tang, Shihua Zhang, and Jiayi Ma. CoMatch: Dynamic Covisibility-Aware Transformer for Bilateral Subpixel-Level Semi-Dense Image Matching. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 18521–18530, 2025. 7
2025
-
[24]
LightGlue: Local Feature Matching at Light Speed
Philipp Lindenberger, Paul-Edouard Sarlin, and Marc Polle- feys. LightGlue: Local Feature Matching at Light Speed. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 17627–17638, 2023. 3, 7
2023
-
[25]
LiftFeat: 3D Geometry- Aware Local Feature Matching
Yepeng Liu, Wenpeng Lai, Zhou Zhao, Yuxuan Xiong, Jinchi Zhu, Jun Cheng, and Yongchao Xu. LiftFeat: 3D Geometry- Aware Local Feature Matching. InProceedings of the IEEE International Conference on Robotics and Automation (ICRA), pages 11714–11720, 2025. 3
2025
-
[26]
LoMa: Local Feature Matching Revisited
David Nordstr¨om, Johan Edstedt, Georg B¨okman, Jonathan Astermark, Anders Heyden, Viktor Larsson, M ˚arten Wadenb¨ack, Michael Felsberg, and Fredrik Kahl. Loma: Local feature matching revisited. arXiv preprint arXiv:2604.04931, 2026. 7
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Who handles orientation? investigating invariance in feature matching
David Nordstr¨om, Johan Edstedt, Georg B¨okman, and Fredrik Kahl. Who handles orientation? investigating invariance in feature matching. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition Workshops (CVPRW), 2026. 3, 6, 7
2026
-
[28]
Maxime Oquab, Timoth´ee Darcet, Th´eo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mido Ass- ran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po- Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv´e J´egou, Julien Mairal, Pa...
2024
-
[29]
Re- lational knowledge distillation
Wonpyo Park, Dongju Kim, Yan Lu, and Minsu Cho. Re- lational knowledge distillation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3967–3976, 2019. 3
2019
-
[30]
GlueStick: Robust Image Matching by Sticking Points and Lines Together
R´emi Pautrat, Iago Su´arez, Yifan Yu, Marc Pollefeys, and Vik- tor Larsson. GlueStick: Robust Image Matching by Sticking Points and Lines Together. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9706–9716, 2023. 3
2023
-
[31]
Fitnets: Hints for thin deep nets
Adriana Romero, Nicolas Ballas, Samira Ebrahimi Kahou, Antoine Chassang, Carlo Gatta, and Yoshua Bengio. Fitnets: Hints for thin deep nets. InInternational Conference on Learning Representations (ICLR), 2015. 3
2015
-
[32]
ORB: An efficient alternative to SIFT or SURF
Ethan Rublee, Vincent Rabaud, Kurt Konolige, and Gary Bradski. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Com- puter Vision (ICCV), pages 2564–2571, 2011. 3
2011
-
[33]
SuperGlue: Learning Feature Matching With Graph Neural Networks
Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. SuperGlue: Learning Feature Matching With Graph Neural Networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4937–4946, 2020. 1, 3
2020
-
[34]
Benchmarking 6dof outdoor visual localization in changing conditions
Torsten Sattler, Will Maddern, Carl Toft, Akihiko Torii, Lars Hammarstrand, Erik Stenborg, Daniel Safari, Masatoshi Oku- tomi, Marc Pollefeys, Josef Sivic, et al. Benchmarking 6dof outdoor visual localization in changing conditions. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8601–8610, 2018. 6
2018
-
[35]
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha¨el Ramamonjisoa, et al. Di- nov3.arXiv preprint arXiv:2508.10104, 2025. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
LoFTR: Detector-Free Local Feature Matching With Transformers
Jiaming Sun, Zehong Shen, Yuang Wang, Hujun Bao, and Xi- aowei Zhou. LoFTR: Detector-Free Local Feature Matching With Transformers. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 8922–8931, 2021. 1, 3
2021
-
[37]
Inloc: Indoor visual localization with dense match- ing and view synthesis
Hajime Taira, Masatoshi Okutomi, Torsten Sattler, Mircea Cimpoi, Marc Pollefeys, Josef Sivic, Tomas Pajdla, and Aki- hiko Torii. Inloc: Indoor visual localization with dense match- ing and view synthesis. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), pages 7199–7209, 2018. 6
2018
-
[38]
Quadtree Attention for Vision Transformers
Shitao Tang, Jiahui Zhang, Siyu Zhu, and Ping Tan. Quadtree Attention for Vision Transformers. InInternational Confer- ence on Learning Representations (ICLR), 2021. 3
2021
-
[39]
GLU- Net: Global-Local Universal Network for Dense Flow and Correspondences
Prune Truong, Martin Danelljan, and Radu Timofte. GLU- Net: Global-Local Universal Network for Dense Flow and Correspondences. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 6258–6268, 2020. 3
2020
-
[40]
Similarity-preserving knowl- edge distillation
Frederick Tung and Greg Mori. Similarity-preserving knowl- edge distillation. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV), pages 1365– 1374, 2019. 3
2019
-
[41]
DISK: Learning local features with policy gradient
Michał Tyszkiewicz, Pascal Fua, and Eduard Trulls. DISK: Learning local features with policy gradient. InAdvances in Neural Information Processing Systems (NeurIPS), pages 14254–14265, 2020. 7
2020
-
[42]
Aerialmegadepth: Learn- ing aerial-ground reconstruction and view synthesis
Khiem Vuong, Anurag Ghosh, Deva Ramanan, Srinivasa Narasimhan, and Shubham Tulsiani. Aerialmegadepth: Learn- ing aerial-ground reconstruction and view synthesis. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21674–21684, 2025. 6
2025
-
[43]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5294–5306, 2025. 6, 7
2025
-
[44]
Efficient LoFTR: Semi-Dense Local Feature Matching with Sparse-Like Speed
Yifan Wang, Xingyi He, Sida Peng, Dongli Tan, and Xiaowei Zhou. Efficient LoFTR: Semi-Dense Local Feature Matching with Sparse-Like Speed. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21666–21675, 2024. 3, 7
2024
-
[45]
General e(2)-equivariant 10 steerable cnns
Maurice Weiler and Gabriele Cesa. General e(2)-equivariant 10 steerable cnns. InAdvances in Neural Information Processing Systems (NeurIPS), pages 14334–14345, 2019. 2, 3, 4
2019
-
[46]
Adaptive Spot-Guided Transformer for Consistent Local Feature Matching
Jiahuan Yu, Jiahao Chang, Jianfeng He, Tianzhu Zhang, Jiyang Yu, and Feng Wu. Adaptive Spot-Guided Transformer for Consistent Local Feature Matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21898–21908, 2023. 3
2023
-
[47]
Learning Two-View Correspondences and Geometry Using Order-Aware Network
Jiahui Zhang, Dawei Sun, Zixin Luo, Anbang Yao, Lei Zhou, Tianwei Shen, Yurong Chen, Hongen Liao, and Long Quan. Learning Two-View Correspondences and Geometry Using Order-Aware Network. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 5844–5853, 2019. 3
2019
-
[48]
Yuchen Zhang, Nikhil Keetha, Chenwei Lyu, Bhuvan Jhamb, Yutian Chen, Yuheng Qiu, Jay Karhade, Shreyas Jha, Yaoyu Hu, Deva Ramanan, et al. Ufm: A simple path towards unified dense correspondence with flow.arXiv preprint arXiv:2506.09278, 2025. 3, 7
-
[49]
Aliked: A lighter keypoint and descriptor extraction network via deformable transforma- tion.IEEE Transactions on Instrumentation and Measure- ment, 72:1–16, 2023
Xiaoming Zhao, Xingming Wu, Weihai Chen, Peter CY Chen, Qingsong Xu, and Zhengguo Li. Aliked: A lighter keypoint and descriptor extraction network via deformable transforma- tion.IEEE Transactions on Instrumentation and Measure- ment, 72:1–16, 2023. 6, 7
2023
-
[50]
Patch2Pix: Epipolar-Guided Pixel-Level Correspondences
Qunjie Zhou, Torsten Sattler, and Laura Leal-Taixe. Patch2Pix: Epipolar-Guided Pixel-Level Correspondences. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4669–4678,
-
[51]
PMatch: Paired Masked Image Modeling for Dense Geometric Matching
Shengjie Zhu and Xiaoming Liu. PMatch: Paired Masked Image Modeling for Dense Geometric Matching. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21909–21918, 2023. 7 11
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.