Uncertainty-Aware LLM-Guided Policy Shaping for Sparse-Reward Reinforcement Learning
Pith reviewed 2026-06-28 02:42 UTC · model grok-4.3
The pith
Integrating uncertainty-modulated LLM guidance from A* paths improves sparse-reward RL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
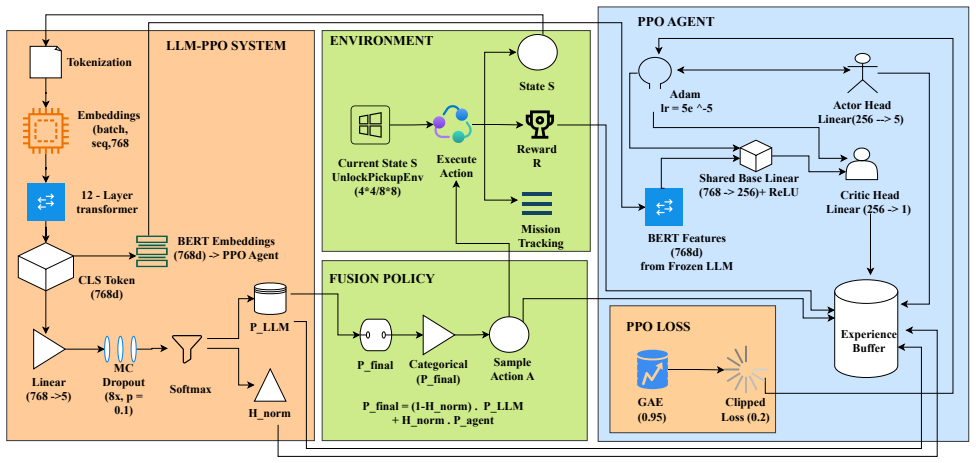
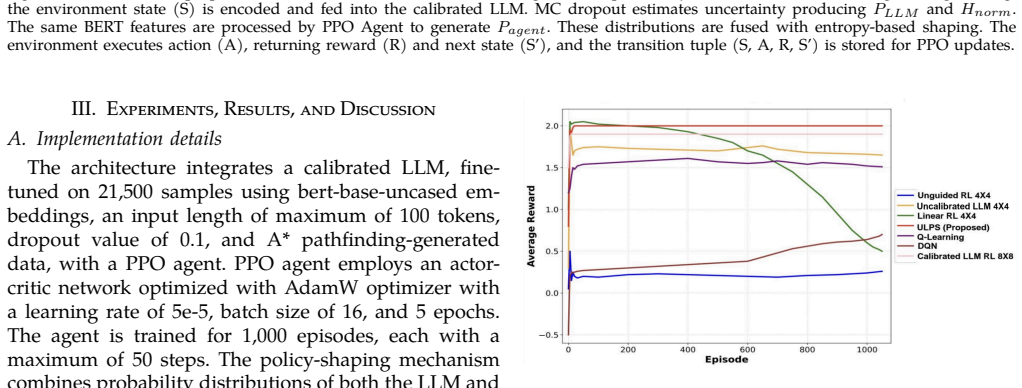
ULPS integrates symbolic A* trajectories to fine-tune a BERT model, supplies action suggestions during PPO training whose influence is conditioned on epistemic uncertainty estimated via MC dropout, and uses an entropy-based blending mechanism to balance LLM guidance and the learned policy, resulting in more than 9% improvement in execution accuracy, fewer environment interactions, and higher reward AUC.
What carries the argument
Entropy-based blending mechanism that adaptively balances LLM guidance and the learned policy based on epistemic uncertainty from MC dropout.
If this is right
- More than 9% improvement in execution accuracy after fine-tuning compared to baselines.
- Fewer environment interactions required for training.
- Higher reward AUC on the MiniGridUnlockPickup benchmark.
- Consistent improvements in success rate and sample complexity over unguided and uncalibrated RL.
Where Pith is reading between the lines
- Applying similar uncertainty-aware blending could extend the benefits to partially observable environments where LLM priors might be less reliable.
- The framework might scale to multi-agent settings by incorporating uncertainty across agents in the blending step.
- Testing on other sparse-reward benchmarks would confirm if the A* to LLM to RL pipeline generalizes beyond MiniGridUnlockPickup.
Load-bearing premise
Epistemic uncertainty estimates from MC dropout reliably signal when to trust LLM suggestions enough to blend them without introducing bias or destabilizing the PPO training.
What would settle it
If ablating the uncertainty estimation and using fixed blending weights or no blending produces equivalent or better results than the full ULPS on the same benchmark, the value of the uncertainty-aware component would be falsified.
Figures

read the original abstract
Sparse rewards and heterogeneous task sequences remain persistent challenges in Reinforcement Learning (RL), often resulting in slow convergence, weak generalization, and inefficient exploration. We propose Uncertainty-Aware LLM-Guided Policy Shaping (ULPS), a novel framework that integrates a calibrated Large Language Model (LLM) into the RL training loop to provide structured, uncertainty-modulated behavioral guidance. ULPS employs an A*-based oracle to synthesize optimal symbolic trajectories, which are used to fine-tune a BERT-based language model. During training, this model supplies action suggestions whose influence is conditioned on epistemic uncertainty estimated via Monte Carlo (MC) dropout. An entropy-based blending mechanism adaptively balances LLM guidance and the learned policy (via Proximal Policy Optimization, PPO), allowing the agent to prioritize reliable priors while preserving adaptability. We evaluate ULPS on the MiniGridUnlockPickup benchmark and observe consistent improvements in success rate, reward efficiency, and sample complexity over unguided, uncalibrated, and standard RL baselines. ULPS achieves more than 9% improvement in execution accuracy after fine-tuning, requires fewer environment interactions, and yields higher reward AUC. Our results demonstrate that integrating symbolic A* trajectories, pretrained language priors, and uncertainty-aware control offers a principled and effective approach to multi-task reinforcement learning in sparse-reward domains, with potential extensibility to partially observable and multi-agent settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Uncertainty-Aware LLM-Guided Policy Shaping (ULPS), which fine-tunes a BERT model on A*-synthesized optimal trajectories and uses Monte Carlo dropout to estimate epistemic uncertainty; this uncertainty modulates an entropy-based mixer that blends LLM action suggestions with a PPO policy during training. The framework is evaluated on the MiniGridUnlockPickup benchmark and reports >9% gains in execution accuracy, reduced environment interactions, and higher reward AUC relative to unguided, uncalibrated, and standard RL baselines.
Significance. If the uncertainty calibration and blending mechanism are shown to be reliable, the approach could offer a practical way to inject structured priors into sparse-reward RL while mitigating the risk of harmful guidance, with potential relevance to sample-efficient multi-task learning.
major comments (3)
- [Abstract] Abstract: the headline claims (>9% execution accuracy improvement, higher reward AUC, lower sample complexity) are presented without any description of the experimental protocol, number of random seeds, statistical tests, or precise baseline definitions, rendering the central empirical result unevaluable.
- [Method (uncertainty estimation and blending)] The load-bearing assumption that MC-dropout variance on the fine-tuned BERT produces a well-calibrated scalar for the entropy mixer is unsupported; the manuscript supplies neither calibration plots, correlation between dropout variance and suggestion accuracy, nor an ablation that isolates the uncertainty term from the A* prior itself.
- [Experiments] No evidence is given that the entropy-based blending avoids either reverting to unguided PPO or silently regularizing the policy toward the A* oracle distribution; without such diagnostics the reported gains cannot be attributed to the uncertainty-aware component.
minor comments (2)
- [Method] Notation for the entropy mixer and the precise form of the blending weight should be stated explicitly rather than described only in prose.
- [Abstract] The abstract refers to 'calibrated' LLM but provides no details on the calibration procedure beyond MC dropout.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims (>9% execution accuracy improvement, higher reward AUC, lower sample complexity) are presented without any description of the experimental protocol, number of random seeds, statistical tests, or precise baseline definitions, rendering the central empirical result unevaluable.
Authors: We agree that the abstract would benefit from additional context on the experimental setup. In the revised version we will expand the abstract to briefly note the use of multiple random seeds, the MiniGridUnlockPickup benchmark protocol, and the specific baselines (unguided PPO, uncalibrated LLM guidance, and standard RL). revision: yes
-
Referee: [Method (uncertainty estimation and blending)] The load-bearing assumption that MC-dropout variance on the fine-tuned BERT produces a well-calibrated scalar for the entropy mixer is unsupported; the manuscript supplies neither calibration plots, correlation between dropout variance and suggestion accuracy, nor an ablation that isolates the uncertainty term from the A* prior itself.
Authors: This observation is correct: the current manuscript does not include calibration plots, correlation analysis, or an ablation isolating the uncertainty term. We will add these elements (calibration plots, variance-accuracy correlation, and uncertainty-ablated variant) to the method and experiments sections in the revision. revision: yes
-
Referee: [Experiments] No evidence is given that the entropy-based blending avoids either reverting to unguided PPO or silently regularizing the policy toward the A* oracle distribution; without such diagnostics the reported gains cannot be attributed to the uncertainty-aware component.
Authors: We acknowledge the need for explicit diagnostics on blending behavior. The manuscript reports aggregate performance gains but does not provide the requested analysis of blending weights or oracle-regularization checks. We will include these diagnostics (e.g., blending-weight trajectories and comparison to non-uncertainty variants) in the revised experiments. revision: yes
Circularity Check
No circularity; purely empirical method with no derivation chain
full rationale
The paper describes an engineering pipeline (A* oracle trajectories for BERT fine-tuning, MC dropout for epistemic uncertainty, entropy-based blending into PPO) evaluated on MiniGridUnlockPickup. No equations, first-principles derivations, or predictions are offered that could reduce to inputs by construction. Claims rest on reported benchmark deltas rather than any self-referential fitting or self-citation load-bearing step. This is the normal case of an applied RL method whose validity is external to any internal reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Playing Atari with Deep Reinforcement Learning
V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstraet al., “Playing atari with deep reinforcement learn- ing,”ArXiv, vol. abs/1312.5602, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[2]
Mastering the game of go with deep neural networks and tree search,
D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. van den Driesscheet al., “Mastering the game of go with deep neural networks and tree search,”Nature, vol. 529, pp. 484–489, 2016
2016
-
[3]
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,”ArXiv, vol. abs/1801.01290, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Memory based trajectory-conditioned policies for learn- ing from sparse rewards,
Y. Guo, J. Choi, M. Moczulski, S. Feng, S. Bengio, M. Norouzi et al., “Memory based trajectory-conditioned policies for learn- ing from sparse rewards,” inNeural Information Processing Sys- tems, 2020
2020
-
[5]
Learning Montezuma's Revenge from a Single Demonstration
T. Salimans and R. J. Chen, “Learning montezuma’s revenge from a single demonstration,”ArXiv, vol. abs/1812.03381, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Deep reinforcement learning from human preferences
P. F. Christiano, J. Leike, T. B. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,”ArXiv, vol. abs/1706.03741, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
S. Casper, X. Davies, C. Shia, T. K. Gibert, J. Scherrer, J. Rando et al., “Open problems and fundamental limitations of re- inforcement learning from human feedback,”arXiv preprint arXiv:2307.15217, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Distributional reasoning in llms: Parallel reasoning processes in multi-hop reasoning,
Y. Shalev, A. Feder, and A. Goldstein, “Distributional reasoning in llms: Parallel reasoning processes in multi-hop reasoning,” ArXiv, vol. abs/2406.13858, 2024
-
[9]
Guiding pretraining in reinforcement learning with large lan- guage models,
Y. Du, O. Watkins, Z. Wang, C. Colas, T. Darrell, P. Abbeelet al., “Guiding pretraining in reinforcement learning with large lan- guage models,” inInternational Conference on Machine Learning, 2023
2023
-
[10]
Language models as zero-shot planners: Extracting actionable knowledge for embodied agents,
W. Huang, P. Abbeel, D. Pathak, and I. Mordatch, “Language models as zero-shot planners: Extracting actionable knowledge for embodied agents,”ArXiv, vol. abs/2201.07207, 2022
-
[11]
arXiv preprint arXiv:2303.00001 , year=
M. Kwon, S. M. Xie, K. Bullard, and D. Sadigh, “Reward design with language models,”ArXiv, vol. abs/2303.00001, 2023
-
[12]
Constitutional AI: Harmlessness from AI Feedback
Y. Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones et al., “Constitutional ai: Harmlessness from ai feedback,”arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Large language mod- els are overconfident and amplify human bias,
F. Sun, N. Li, K. Wang, and L. Goette, “Large language mod- els are overconfident and amplify human bias,”ArXiv, vol. abs/2505.02151, 2025
-
[14]
Relying on the unreliable: The impact of language models’ reluctance to express uncertainty,
K. Zhou, J. D. Hwang, X. Ren, and M. Sap, “Relying on the unreliable: The impact of language models’ reluctance to express uncertainty,”ArXiv, vol. abs/2401.06730, 2024
-
[15]
Guiding reinforcement learn- ing using uncertainty-aware large language models,
M. Shoaeinaeini and B. Harrison, “Guiding reinforcement learn- ing using uncertainty-aware large language models,”2025 IEEE 7th International Conference on Trust, Privacy and Security in Intelligent Systems, and Applications (TPS-ISA), pp. 363–371, 2024
2025
-
[16]
Dropout as a bayesian approxi- mation: Representing model uncertainty in deep learning,
Y. Gal and Z. Ghahramani, “Dropout as a bayesian approxi- mation: Representing model uncertainty in deep learning,” in International Conference on Machine Learning, 2015
2015
-
[17]
M. Chevalier-Boisvert, B. Dai, M. Towers, R. de Lazcano, L. Willems, S. Lahlouet al., “Minigrid & miniworld: Modular & customizable reinforcement learning environments for goal- oriented tasks,”ArXiv, vol. abs/2306.13831, 2023
-
[18]
MiniGrid-UnlockPickup-v0 Environ- ment,
Farama Foundation, “MiniGrid-UnlockPickup-v0 Environ- ment,” 2025, miniGrid Documentation
2025
-
[19]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Biet al., “Deepseek- math: Pushing the limits of mathematical reasoning in open language models,”ArXiv, vol. abs/2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.