Dangerous Liaisons of Convex Learning and Non-Affine Aggregation
Pith reviewed 2026-06-29 04:58 UTC · model grok-4.3
The pith
Monotonicity of aggregated gradients holds if and only if the aggregation rule is positively affine.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We prove that the monotonicity of aggregated gradients is preserved if and only if the aggregation rule is positively affine. Consequently, non-affine aggregation prevents steady convergence and substantially degrade algorithmic stability. We quantify these drawbacks and propose a path forward by identifying sufficient conditions under which monotonicity can be restored.
What carries the argument
The monotonicity of the aggregated gradient update operator, which is preserved exactly when the aggregation function is positively affine.
If this is right
- Non-affine aggregation rules necessarily destroy last-iterate convergence guarantees in convex settings.
- Algorithmic stability is substantially degraded under non-affine aggregation.
- Sufficient conditions exist that allow monotonicity to be restored even when constraints are enforced.
- Disparate failure modes across adaptive, private, robust and fair learning systems share the same root cause in loss of monotonicity.
Where Pith is reading between the lines
- Pipeline designers who add non-affine constraints must either revert to affine aggregation or accept weaker convergence and stability bounds.
- The result offers a single explanation for why many practical systems exhibit slower or less reliable training than their unconstrained counterparts.
Load-bearing premise
Last-iterate convergence and generalization guarantees in first-order convex learning hinge on the monotonicity of the update operator.
What would settle it
A single counter-example consisting of a non-affine aggregation rule together with a convex problem where the aggregated gradient remains monotone would falsify the if-and-only-if claim.
Figures

read the original abstract
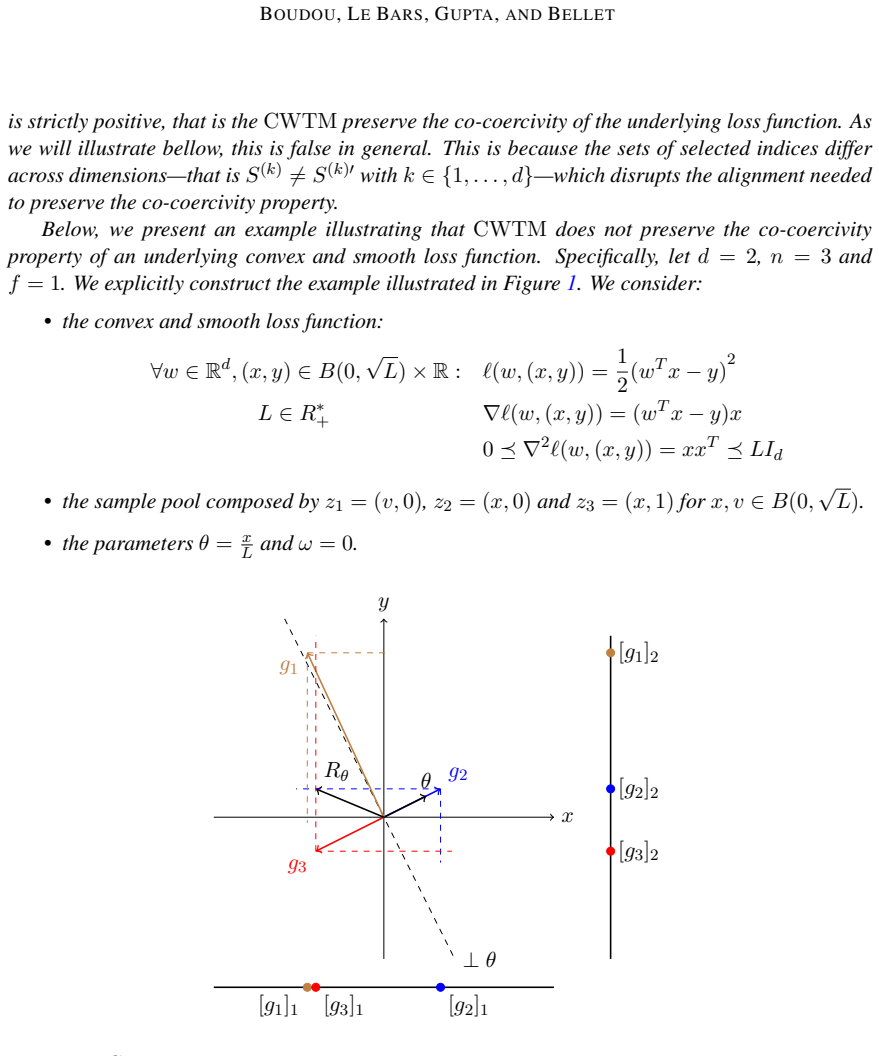
Last-iterate convergence and generalization guarantees in first-order convex learning hinge on the monotonicity of the update operator. While linear averaging preserves the monotonicity of gradient updates, this property is often violated when gradients are aggregated non-affinely, as in modern pipelines enforcing constraints like adaptivity, privacy, robustness or fairness. Whether it is possible to design non-affine aggregation rules that maintain monotonicity has remained an open question. We answer this question negatively: we prove that the monotonicity of aggregated gradients is preserved if and only if the aggregation rule is positively affine. Consequently, non-affine aggregation prevents steady convergence and substantially degrade algorithmic stability. We quantify these drawbacks and propose a path forward by identifying sufficient conditions under which monotonicity can be restored. Our results provide a unified theoretical framework explaining the disparate failure modes observed in modern learning systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proves that the monotonicity of aggregated gradients is preserved if and only if the aggregation rule is positively affine. It concludes that non-affine aggregation rules (common for adaptivity, privacy, robustness or fairness) therefore prevent steady last-iterate convergence and degrade stability in first-order convex learning, while identifying sufficient conditions under which monotonicity can be restored.
Significance. If the iff characterization holds, the result supplies a parameter-free derivation with no ad-hoc axioms or invented entities that unifies disparate failure modes observed in modern pipelines. The constructive identification of restoration conditions is a further strength. The overall significance is tempered by the need to substantiate the necessity (rather than sufficiency) of monotonicity for the cited convergence guarantees.
major comments (2)
- [Abstract] Abstract: the statement that last-iterate convergence and generalization guarantees 'hinge on the monotonicity of the update operator' is invoked to conclude that non-affine rules 'prevent steady convergence,' yet no derivation or citation is supplied establishing necessity (as opposed to sufficiency) of monotonicity across the relevant function classes; this step is load-bearing for the algorithmic-failure claim.
- [Introduction] The necessity direction of the iff result is used to assert that non-affine rules degrade stability; if other operator properties can substitute for monotonicity, the 'only if' implication for practical systems does not follow. This requires explicit treatment (with a concrete test or counter-example class) in the main body.
minor comments (1)
- The abstract would be clearer if it briefly indicated the function classes or standing assumptions (e.g., convexity, smoothness) under which the iff statement is proved.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. Below we respond point-by-point to the major comments, indicating where revisions will be made to address the concerns about substantiating the role of monotonicity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that last-iterate convergence and generalization guarantees 'hinge on the monotonicity of the update operator' is invoked to conclude that non-affine rules 'prevent steady convergence,' yet no derivation or citation is supplied establishing necessity (as opposed to sufficiency) of monotonicity across the relevant function classes; this step is load-bearing for the algorithmic-failure claim.
Authors: We agree that the abstract would be strengthened by explicit support for the centrality of monotonicity. In the revision we will add citations to standard references on monotone operators (e.g., works establishing necessity of monotonicity for last-iterate convergence of forward-backward and proximal methods on convex problems) and a short clarifying sentence distinguishing sufficiency from necessity in the relevant function classes. revision: yes
-
Referee: [Introduction] The necessity direction of the iff result is used to assert that non-affine rules degrade stability; if other operator properties can substitute for monotonicity, the 'only if' implication for practical systems does not follow. This requires explicit treatment (with a concrete test or counter-example class) in the main body.
Authors: We accept the need for explicit treatment. The revised manuscript will include a brief remark (or short subsection) supplying a concrete counter-example class—a simple convex quadratic where a deliberately non-monotone but otherwise Lipschitz update produces persistent oscillation—showing that monotonicity cannot be substituted by other standard operator properties in the usual convergence arguments. This will be placed after the statement of the iff result. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core contribution is a direct mathematical proof establishing an if-and-only-if equivalence between preservation of monotonicity under aggregation and the aggregation rule being positively affine. No steps in the described derivation chain reduce by construction to fitted parameters, self-definitions, or self-citation chains that bear the load of the central claim. The premise that convergence hinges on monotonicity is stated as an external assumption motivating the work rather than derived from the paper's own results, leaving the iff characterization self-contained and independent.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Last-iterate convergence and generalization guarantees in first-order convex learning hinge on the monotonicity of the update operator.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2506.18020v2 , year=
Byzantine Failures Harm the Generalization of Robust Distributed Learning Algorithms More Than Data Poisoning , author=. arXiv preprint arXiv:2506.18020v2 , year=
-
[2]
Machine Learning , year =
C\'esar Sabater and Aur\'elien Bellet and Jan Ramon , title =. Machine Learning , year =
-
[3]
CCS , year =
Kasra Abbaszadeh and Christodoulos Pappas and Jonathan Katz and Dimitrios Papadopoulos , title =. CCS , year =
-
[4]
ICLR , year =
Ali Shahin Shamsabadi and Gefei Tan and Tudor Ioan Cebere and Aurélien Bellet and Hamed Haddadi and Nicolas Papernot and Xiao Wang and Adrian Weller , title =. ICLR , year =
-
[5]
2024 , publisher=
Learning Theory from First Principles , author=. 2024 , publisher=
2024
-
[6]
2013 , publisher=
Concentration Inequalities: A Nonasymptotic Theory of Independence , author=. 2013 , publisher=
2013
-
[7]
1987 , publisher =
Rudin, Walter , title =. 1987 , publisher =
1987
-
[8]
High-Dimensional Probability: An Introduction with Applications in Data Science , publisher=
Vershynin, Roman , year=. High-Dimensional Probability: An Introduction with Applications in Data Science , publisher=
-
[9]
NeurIPS , title =
Bottou, L\'. NeurIPS , title =
-
[10]
ICML , year =
On the Privacy-Robustness-Utility Trilemma in Distributed Learning , author =. ICML , year =
-
[11]
Improved Stability and Generalization Guarantees of the Decentralized
Le Bars, Batiste and Bellet, Aur\'. Improved Stability and Generalization Guarantees of the Decentralized. ICML , year =
-
[12]
AISTATS , year =
Differentially Private Federated Learning on Heterogeneous Data , author =. AISTATS , year =
-
[13]
2021 , volume =
Foundations and Trends® in Machine Learning , title =. 2021 , volume =
2021
-
[14]
AISTATS , year =
Fixing by Mixing: A Recipe for Optimal Byzantine ML under Heterogeneity , author =. AISTATS , year =
-
[15]
Coherent gradients: An approach to understanding generalization in gradient descentbased optimization , year =
Chatterjee, Satrajit , booktitle =. Coherent gradients: An approach to understanding generalization in gradient descentbased optimization , year =
-
[16]
EUROCRYPT , year=
Distributed Differential Privacy via Shuffling , author=. EUROCRYPT , year=
-
[17]
AISTATS , year =
Privacy Amplification by Decentralization , author =. AISTATS , year =
-
[18]
ICML , year =
Robust Collaborative Learning with Linear Gradient Overhead , author =. ICML , year =
-
[19]
Farhadkhani, Sadegh and Guerraoui, Rachid and Gupta, Nirupam and Pinot, Rafael and Stephan, John , booktitle =
-
[20]
ACM Computing Surveys , articleno =
Guerraoui, Rachid and Gupta, Nirupam and Pinot, Rafael , title =. ACM Computing Surveys , articleno =. 2024 , volume =
2024
-
[21]
and Kamath, Gautam and Majid, Mahbod and Narayanan, Shyam , title =
Hopkins, Samuel B. and Kamath, Gautam and Majid, Mahbod and Narayanan, Shyam , title =. 2023 , booktitle =
2023
-
[22]
ACM Trans
Kifer, Daniel and Machanavajjhala, Ashwin , title =. ACM Trans. Database Syst. , articleno =. 2014 , publisher =
2014
-
[23]
McMahan, Brendan and Moore, Eider and Ramage, Daniel and Hampson, Seth and Arcas, Blaise Aguera y , booktitle =
-
[24]
ICML , year =
Rényi Pufferfish Privacy: General Additive Noise Mechanisms and Privacy Amplification by Iteration via Shift Reduction Lemmas , author =. ICML , year =
-
[25]
Communication Compression for
Rammal, Ahmad and Gruntkowska, Kaja and Fedin, Nikita and Gorbunov, Eduard and Richtarik, Peter , booktitle =. Communication Compression for
-
[26]
and Albarqouni, Shadi and Bakas, Spyridon and Galtier, Mathieu N
Rieke, Nicola and Hancox, Jonny and Li, Wenqi and Milletarì, Fausto and Roth, Holger R. and Albarqouni, Shadi and Bakas, Spyridon and Galtier, Mathieu N. and Landman, Bennett A. and Maier-Hein, Klaus and Ourselin, Sébastien and Sheller, Micah and Summers, Ronald M. and Trask, Andrew and Xu, Daguang and Baust, Maximilian and Cardoso, M. Jorge , year=. The ...
-
[27]
Sparsified SGD with Memory , year =
Stich, Sebastian U and Cordonnier, Jean-Baptiste and Jaggi, Martin , booktitle =. Sparsified SGD with Memory , year =
-
[28]
Differentially Private Learning Needs Hidden State (Or Much Faster Convergence) , year =
Ye, Jiayuan and Shokri, Reza , booktitle =. Differentially Private Learning Needs Hidden State (Or Much Faster Convergence) , year =
-
[29]
Yin, Dong and Chen, Yudong and Kannan, Ramchandran and Bartlett, Peter , booktitle =
-
[30]
Federated Learning With Sparsified Model Perturbation: Improving Accuracy Under Client-Level Differential Privacy , volume=
Hu, Rui and Guo, Yuanxiong and Gong, Yanmin , year=. Federated Learning With Sparsified Model Perturbation: Improving Accuracy Under Client-Level Differential Privacy , volume=. IEEE Transactions on Mobile Computing , publisher=
-
[31]
Rényi Differential Privacy , booktitle=
Mironov, Ilya , year=. Rényi Differential Privacy , booktitle=
-
[32]
Calibrating Noise to Sensitivity in Private Data Analysis
Dwork, Cynthia and McSherry, Frank and Nissim, Kobbi and Smith, Adam. Calibrating Noise to Sensitivity in Private Data Analysis. Theory of Cryptography. 2006
2006
-
[33]
Brendan and Mironov, Ilya and Talwar, Kunal and Zhang, Li , year=
Abadi, Martin and Chu, Andy and Goodfellow, Ian and McMahan, H. Brendan and Mironov, Ilya and Talwar, Kunal and Zhang, Li , year=. Deep Learning with Differential Privacy , booktitle=
-
[34]
The Complexity of Computing the Optimal Composition of Differential Privacy , booktitle=
Murtagh, Jack and Vadhan, Salil , year=. The Complexity of Computing the Optimal Composition of Differential Privacy , booktitle=
-
[35]
and Bengio, Y
Kawaguchi, K. and Bengio, Y. and Kaelbling, L. , year=. Generalization in Deep Learning , booktitle=
-
[36]
2024 , publisher=
Robust Machine Learning: Distributed Methods for Safe AI , author=. 2024 , publisher=
2024
-
[37]
Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=
Gaussian differential privacy , author=. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=
-
[38]
NeurIPS , year=
Numerical composition of differential privacy , author=. NeurIPS , year=
-
[39]
2019 , eprint=
Differential Privacy as a Causal Property , author=. 2019 , eprint=
2019
-
[40]
ICLR , year=
Private Federated Learning Without a Trusted Server: Optimal Algorithms for Convex Losses , author=. ICLR , year=
-
[41]
AISTATS , year =
Private Non-Convex Federated Learning Without a Trusted Server , author =. AISTATS , year =
-
[42]
JMLR , year=
Stability and Generalization , author=. JMLR , year=
-
[43]
COLT , year =
Sharper Bounds for Uniformly Stable Algorithms , author =. COLT , year =
-
[44]
ICML , year =
Data-Dependent Stability of Stochastic Gradient Descent , author =. ICML , year =
-
[45]
COLT , year=
Private robust estimation by stabilizing convex relaxations , author=. COLT , year=
-
[46]
NeurIPS , year=
Privacy amplification by subsampling: Tight analyses via couplings and divergences , author=. NeurIPS , year=
-
[47]
FOCS , year=
Privacy amplification by iteration , author=. FOCS , year=
-
[48]
ICML , year=
Fine-grained analysis of stability and generalization for stochastic gradient descent , author=. ICML , year=
-
[49]
ICML , year=
Learning from history for byzantine robust optimization , author=. ICML , year=
-
[50]
JMLR , volume=
Learning with differential privacy: Stability, learnability and the sufficiency and necessity of ERM principle , author=. JMLR , volume=
-
[51]
JMLR , year =
Shai Shalev-Shwartz and Ohad Shamir and Nathan Srebro and Karthik Sridharan , title =. JMLR , year =
-
[52]
Proceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing , pages=
Does learning require memorization? a short tale about a long tail , author=. Proceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing , pages=
-
[53]
Communications of the ACM , volume=
Understanding deep learning (still) requires rethinking generalization , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[54]
arXiv preprint arXiv:2312.14712 , year=
Can Machines Learn Robustly, Privately, and Efficiently? , author=. arXiv preprint arXiv:2312.14712 , year=
-
[55]
arXiv preprint arXiv:2405.00491 , year=
On the Relevance of Byzantine Robust Optimization Against Data Poisoning , author=. arXiv preprint arXiv:2405.00491 , year=
-
[56]
2009 , booktitle =
Dwork, Cynthia and Lei, Jing , title =. 2009 , booktitle =
2009
-
[57]
ICML , year=
From robustness to privacy and back , author=. ICML , year=
-
[58]
Instance-optimality in differential privacy via approximate inverse sensitivity mechanisms , year =
Asi, Hilal and Duchi, John C , booktitle =. Instance-optimality in differential privacy via approximate inverse sensitivity mechanisms , year =
-
[59]
NeurIPS , year=
Privacy induces robustness: Information-computation gaps and sparse mean estimation , author=. NeurIPS , year=
-
[60]
STOC , year=
Privately estimating a Gaussian: Efficient, robust, and optimal , author=. STOC , year=
-
[61]
NeurIPS , year=
Robust and differentially private mean estimation , author=. NeurIPS , year=
-
[62]
arXiv preprint arXiv:2306.12608 , year=
DP-BREM: differentially-private and byzantine-robust federated learning with client momentum , author=. arXiv preprint arXiv:2306.12608 , year=
-
[63]
arXiv preprint arXiv:2408.08628 , year=
A survey on secure decentralized optimization and learning , author=. arXiv preprint arXiv:2408.08628 , year=
-
[64]
ICASSP , year=
On the tradeoff between privacy preservation and Byzantine-robustness in decentralized learning , author=. ICASSP , year=
-
[65]
arXiv preprint arXiv:2205.00107 , year=
Bridging differential privacy and byzantine-robustness via model aggregation , author=. arXiv preprint arXiv:2205.00107 , year=
-
[66]
ICML , year=
Train faster, generalize better: Stability of stochastic gradient descent , author=. ICML , year=
-
[67]
COLT , year=
Generalization bounds via convex analysis , author=. COLT , year=
-
[68]
arXiv preprint arXiv:1910.07485 , year=
Excess risk bounds in robust empirical risk minimization , author=. arXiv preprint arXiv:1910.07485 , year=
-
[69]
arXiv preprint arXiv:1710.05468 , year=
Generalization in deep learning , author=. arXiv preprint arXiv:1710.05468 , year=
-
[70]
STOC , year=
Does learning require memorization? a short tale about a long tail , author=. STOC , year=
-
[71]
UAI , year=
Stability of sgd: Tightness analysis and improved bounds , author=. UAI , year=
-
[72]
Machine learning , volume=
Robustness and generalization , author=. Machine learning , volume=. 2012 , publisher=
2012
-
[73]
ICML , year =
Robustness Implies Generalization via Data-Dependent Generalization Bounds , author =. ICML , year =
-
[74]
UAI , year =
Tighter Generalization Bounds for Iterative Differentially Private Learning Algorithms , author =. UAI , year =
-
[75]
JMLR , year =
Ali Ramezani-Kebrya and Kimon Antonakopoulos and Volkan Cevher and Ashish Khisti and Ben Liang , title =. JMLR , year =
-
[76]
IJCAI , publisher =
Stability and Generalization for Randomized Coordinate Descent , author =. IJCAI , publisher =
-
[77]
Beyond Lipschitz: Sharp Generalization and Excess Risk Bounds for Full-Batch
Konstantinos Nikolakakis and Farzin Haddadpour and Amin Karbasi and Dionysios Kalogerias , booktitle=. Beyond Lipschitz: Sharp Generalization and Excess Risk Bounds for Full-Batch
-
[78]
Smoothness, Low Noise and Fast Rates , volume =
Srebro, Nathan and Sridharan, Karthik and Tewari, Ambuj , booktitle =. Smoothness, Low Noise and Fast Rates , volume =
-
[79]
Applied and Computational Harmonic Analysis , volume=
Unregularized online learning algorithms with general loss functions , author=. Applied and Computational Harmonic Analysis , volume=. 2017 , publisher=
2017
-
[80]
Linear convergence of gradient and proximal-gradient methods under the polyak-
Karimi, Hamed and Nutini, Julie and Schmidt, Mark , booktitle=. Linear convergence of gradient and proximal-gradient methods under the polyak-. 2016 , organization=
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.