Can LLMs Judge Better Than They Generate? Evaluating Task Asymmetry, Mechanistic Interpretability and Transferability for In-Context QA
Pith reviewed 2026-06-29 04:14 UTC · model grok-4.3
The pith
LLMs generate answers more accurately than they self-evaluate on three of four in-context QA benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
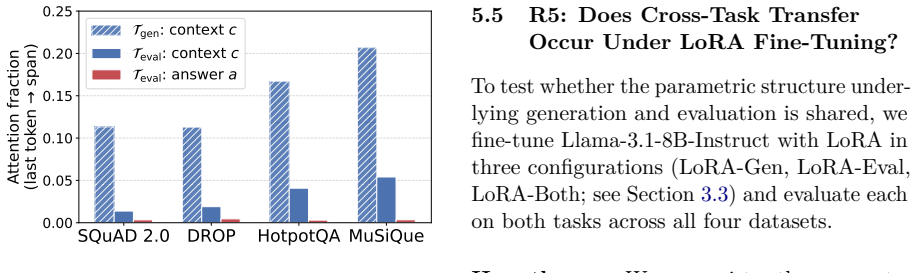
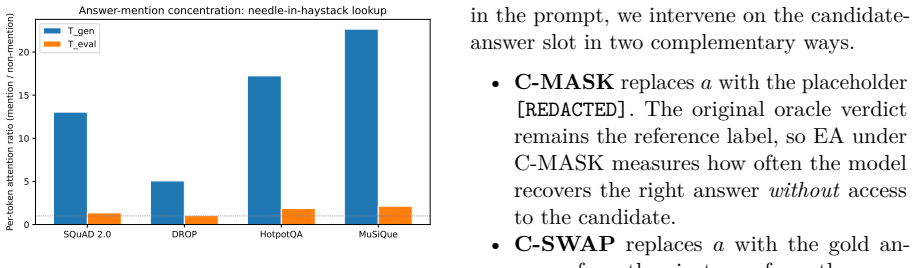
In a controlled in-context QA setting where each model judges the answer it itself generated from the supplied passage, generation accuracy exceeds self-evaluation accuracy on three of four benchmarks while the reverse holds on multi-hop reasoning; attention analysis shows evaluation attends far less to context and the candidate answer, and LoRA fine-tuning for one task produces negative transfer to the other.
What carries the argument
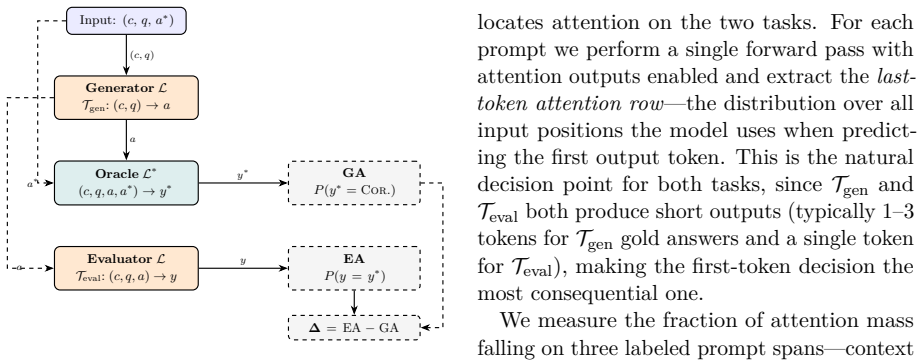
The controlled self-evaluation pipeline in which the model judges its own generated answer using only the provided context passage.
If this is right
- Self-evaluation pipelines cannot be assumed to be easier or more reliable than the generation they are meant to improve.
- Multi-hop reasoning tasks can invert the observed asymmetry between generation and evaluation.
- Attention allocation during evaluation differs sharply from attention during generation.
- Fine-tuning one capability produces negative transfer to the other rather than neutral or positive transfer.
Where Pith is reading between the lines
- Self-improvement loops that alternate generation and self-judgment may accumulate errors faster than expected on single-hop tasks.
- Separate specialized heads or modules for judgment may be required rather than relying on the same weights used for generation.
- The attention deficit during evaluation suggests that adding explicit context-retrieval steps inside the judge could reduce the asymmetry.
Load-bearing premise
That restricting the model to the supplied context and its own generated answer removes all confounds and isolates a genuine difference between the two tasks.
What would settle it
Running the same four-benchmark protocol on additional models and finding that self-evaluation accuracy exceeds generation accuracy on every benchmark would falsify the reported asymmetry.
Figures
read the original abstract
LLM-as-a-Judge and self-evaluation pipelines implicitly assume that evaluation is easier than generation. We test this in a controlled in-context QA setting where a context passage is the sole information source and each model judges the answer it generated, removing the parametric-knowledge confound of open-domain comparisons. Across four benchmarks (SQuAD 2.0, DROP, HotpotQA, MuSiQue) and two models, evaluation is not uniformly easier: generation accuracy exceeds self-evaluation on three of four, with multi-hop MuSiQue the exception. Attention analysis reveals why: evaluation attends to context 3--5x less than generation does and barely reads the candidate answer. LoRA fine-tuning confirms the asymmetry is not a training artifact: generation fine-tuning induces over-acceptance and evaluation fine-tuning degrades generation. These findings challenge core assumptions in self-evaluation pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in a controlled in-context QA setting—where a context passage is the sole information source and each model judges the answer it generated—evaluation is not uniformly easier than generation. Across four benchmarks (SQuAD 2.0, DROP, HotpotQA, MuSiQue) and two models, generation accuracy exceeds self-evaluation on three of four, with multi-hop MuSiQue the exception. Attention analysis shows evaluation attends to context 3-5x less than generation and barely reads the candidate answer. LoRA fine-tuning confirms the asymmetry is not a training artifact: generation fine-tuning induces over-acceptance while evaluation fine-tuning degrades generation.
Significance. If the results hold, they challenge core assumptions underlying LLM-as-a-Judge and self-evaluation pipelines. The controlled in-context design removes the parametric-knowledge confound, directly isolating task asymmetry. Credit is due for the multi-benchmark empirical design, mechanistic attention analysis, and LoRA transfer experiments that provide explanatory and falsifiable support. The work has clear implications for improving evaluation reliability in LLMs, particularly for multi-hop reasoning.
minor comments (1)
- Abstract: the two models are not named; specifying them (and any relevant hyperparameters) in the methods section would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our work, the recognition of its significance for LLM-as-a-Judge pipelines, and the recommendation for minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper reports purely empirical results from controlled in-context QA experiments across four benchmarks, attention analysis, and LoRA fine-tuning ablations. No equations, derivations, first-principles predictions, or fitted parameters are presented as outputs; the central claims rest on direct accuracy comparisons that isolate the generation-vs-evaluation asymmetry without reducing to self-definitional inputs or self-citation chains. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention weights in transformer models reflect the relative importance the model assigns to different input tokens
Reference graph
Works this paper leans on
-
[1]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Language models of code are few-shot planners and reasoners for multi-document summarization with attribution , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[2]
Do Before You Judge: Self-Reference as a Pathway to Better
Lin, Wei-Hsiang and Wei, Sheng-Lun and Huang, Hen-Hsen and Chen, Hsin-Hsi , booktitle =. Do Before You Judge: Self-Reference as a Pathway to Better. 2025 , address =
2025
-
[3]
The Generative
Oh, Juhyun and Kim, Eunsu and Cha, Inha and Oh, Alice , booktitle =. The Generative. 2024 , url =
2024
-
[4]
2025 , url =
Jiang, Dongwei and Zhang, Jingyu and Weller, Orion and Weir, Nathaniel and Van Durme, Benjamin and Khashabi, Daniel , booktitle =. 2025 , url =
2025
-
[5]
arXiv preprint arXiv:2303.17557 , year =
Recognition, Recall, and Retention of Few-Shot Memories in Large Language Models , author =. arXiv preprint arXiv:2303.17557 , year =
-
[6]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , month = jul, year =
Bavaresco, Anna and Bernardi, Raffaella and Bertolazzi, Leonardo and Elliott, Desmond and Fern. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , month = jul, year =
-
[7]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. Judging. 2023 , url =
2023
-
[8]
2023 , url =
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , booktitle =. 2023 , url =
2023
-
[9]
The Twelfth International Conference on Learning Representations , year =
Large Language Models Cannot Self-Correct Reasoning Yet , author =. The Twelfth International Conference on Learning Representations , year =
-
[10]
and Feng, Shi , booktitle =
Panickssery, Arjun and Bowman, Samuel R. and Feng, Shi , booktitle =. 2024 , url =
2024
-
[11]
2022 , url =
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish , journal =. 2022 , url =
2022
-
[12]
Know What You Don
Rajpurkar, Pranav and Jia, Robin and Liang, Percy , booktitle =. Know What You Don. 2018 , url =
2018
-
[13]
and Salakhutdinov, Ruslan and Manning, Christopher D
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William W. and Salakhutdinov, Ruslan and Manning, Christopher D. , booktitle =. 2018 , url =
2018
-
[14]
2019 , url =
Dua, Dheeru and Wang, Yizhong and Dasigi, Pradeep and Stanovsky, Gabriel and Singh, Sameer and Gardner, Matt , booktitle =. 2019 , url =
2019
-
[15]
Constructing A Multi-hop
Ho, Xanh and Duong Nguyen, Anh-Khoa and Sugawara, Saku and Aizawa, Akiko , booktitle =. Constructing A Multi-hop. 2020 , url =
2020
-
[16]
Advances in Neural Information Processing Systems , volume =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
2022
-
[17]
Constitutional
Bai, Yuntao and Jones, Andy and Ndousse, Kamal and Askell, Amanda and Chen, Anna and DasSarma, Nova and Drain, Dawn and Fort, Stanislav and Ganguli, Deep and Henighan, Tom and others , journal =. Constitutional. 2022 , url =
2022
-
[18]
Asai, Akari and Wu, Zeqiu and Wang, Yizhong and Sil, Avirup and Hajishirzi, Hannaneh , booktitle =. Self-. 2024 , url =
2024
-
[19]
2025 , eprint =
Donors and Recipients: On Asymmetric Transfer Across Tasks and Languages with Parameter-Efficient Fine-Tuning , author =. 2025 , eprint =
2025
-
[20]
Psychological Review , volume =
Recognition and Retrieval Processes in Free Recall , author =. Psychological Review , volume =
-
[21]
Dubey, Abhimanyu and others , journal =. The. 2024 , url =
2024
-
[22]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =. 2022 , url =
2022
-
[23]
Transformer Circuits Thread , year =
A Mathematical Framework for Transformer Circuits , author =. Transformer Circuits Thread , year =
-
[24]
Transformer Circuits Thread , year =
In-Context Learning and Induction Heads , author =. Transformer Circuits Thread , year =
-
[25]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle =. Locating and Editing Factual Associations in. 2022 , url =
2022
-
[26]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting Latent Predictions from Transformers with the Tuned Lens , author =. arXiv preprint arXiv:2303.08112 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Dissecting Recall of Factual Associations in Auto-Regressive Language Models , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.