Triospect: A Three-Dimensional Framework for Robust Statistical AI-Generated Text Detection Against Diverse Attacks
Pith reviewed 2026-07-01 05:55 UTC · model grok-4.3
The pith
Triospect adds content and expression perspectives to statistical detection to make AI-generated text identification robust against attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By integrating content and expression perspectives with traditional statistical features, Triospect achieves robust detection of AI-generated text even after diverse attacks that manipulate textual characteristics.
What carries the argument
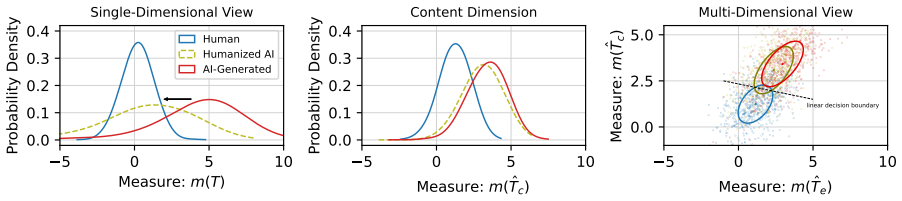
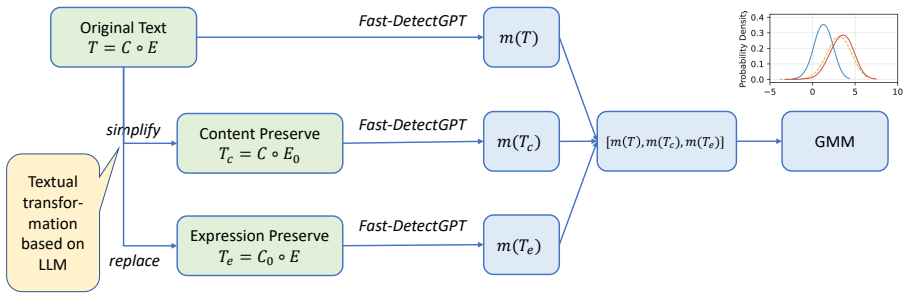
The Triospect framework, which combines statistical, content, and expression perspectives for detection.
If this is right
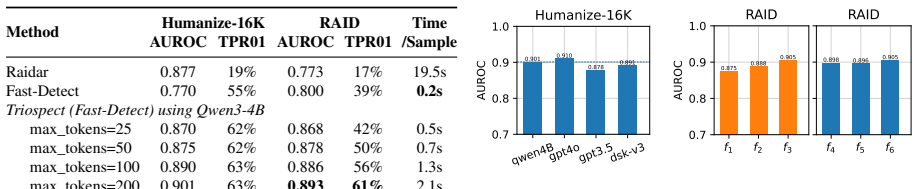
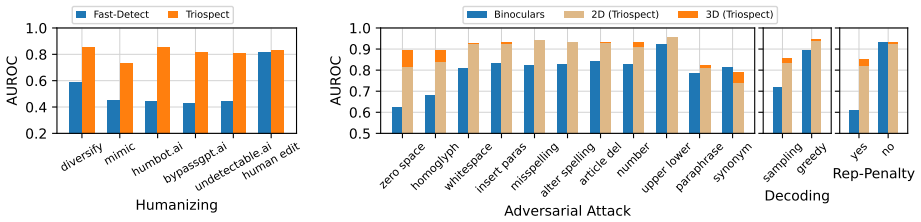
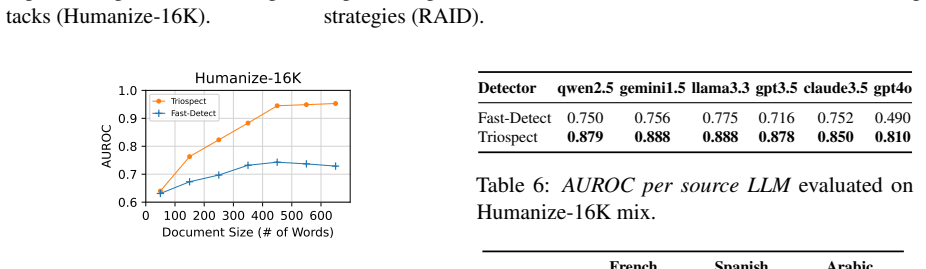
- Improves baseline by 22.3% AUROC and 13% TPR01 on Humanize-16K after-attack subset.
- Improves by 9.1% AUROC and 22% TPR01 on adversarial RAID.
- Remains effective across 17 attacks, 12 domains, and 17 source models.
- The framework is the first statistical method to enhance reliability against attacks using these additional perspectives.
Where Pith is reading between the lines
- Similar multi-perspective ideas might apply to detecting other forms of generated media like images or audio.
- Attackers could develop methods targeting all three perspectives at once, requiring further evolution of the approach.
- Integration of these perspectives might reduce false positives in detection systems used for content moderation.
Load-bearing premise
The content and expression perspectives supply information independent of statistical features, and gains will hold for attacks beyond those tested.
What would settle it
An experiment showing no performance gain when adding content and expression features on a new set of attacks not included in the original benchmarks would falsify the robustness claim.
Figures
read the original abstract
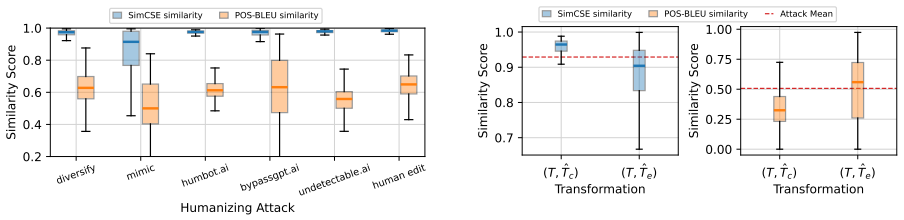
Existing AI-generated text detectors are vulnerable to attacks that manipulate textual characteristics. In this study, we propose a novel Triospect Detection Framework by using additional perspectives of content (core ideas) and expression (stylistic elements) within a given text. Experiments on two benchmarks involving 17 attacks, 12 domains, and 17 source models demonstrate that Triospect is robust against these attacks. It improves the strong baseline by a significant margin of 22.3% (AUROC) and 13% (TPR01) on the Humanize-16K after-attack subset, and by 9.1% (AUROC) and 22% (TPR01) on the adversarial RAID. This framework marks a pioneering effort in statistical methods to enhance detection reliability against attacks. We release our data and code at https://github.com/baoguangsheng/triospect.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Triospect, a three-dimensional statistical framework for AI-generated text detection that augments base statistical features with content (core ideas) and expression (stylistic) perspectives. Experiments on two benchmarks covering 17 attacks, 12 domains, and 17 source models report AUROC/TPR01 gains of 22.3%/13% on the Humanize-16K after-attack subset and 9.1%/22% on adversarial RAID relative to a strong baseline. The authors release data and code.
Significance. If the content and expression perspectives demonstrably supply information independent of statistical signals, the framework could meaningfully advance robust detection methods. The public release of data and code is a clear strength supporting reproducibility and follow-on work.
major comments (2)
- [Experiments section] Experiments section: no ablation studies, feature-correlation matrices, or mutual-information analyses are reported that isolate the contribution of the content and expression perspectives from the statistical baseline. This evidence is required to substantiate the central claim that the three perspectives are additive and independent; absent such checks, the reported 22.3 % AUROC lift on Humanize-16K could arise from richer statistical feature engineering alone.
- [Section 4] Section 4 (results on adversarial RAID and Humanize-16K): the generalization claim beyond the specific 17 attacks is asserted without leave-one-attack-out, cross-attack, or theoretical analysis. The reported robustness therefore remains tied to the exact attack set tested and does not yet establish broader applicability.
minor comments (1)
- [Abstract] The abstract states that the framework 'marks a pioneering effort in statistical methods'; this phrasing is unnecessary and should be replaced by a factual description of the contribution.
Simulated Author's Rebuttal
Thank you for the constructive review. We address each major comment below and will revise the manuscript to incorporate additional analyses where they strengthen the evidence for our claims.
read point-by-point responses
-
Referee: [Experiments section] Experiments section: no ablation studies, feature-correlation matrices, or mutual-information analyses are reported that isolate the contribution of the content and expression perspectives from the statistical baseline. This evidence is required to substantiate the central claim that the three perspectives are additive and independent; absent such checks, the reported 22.3 % AUROC lift on Humanize-16K could arise from richer statistical feature engineering alone.
Authors: We agree that explicit ablation studies and correlation analyses are needed to isolate the contributions. In the revised manuscript we will add (i) ablation experiments that remove the content perspective and the expression perspective in turn and report the resulting AUROC/TPR01 drops, and (ii) feature-correlation matrices together with mutual-information values computed between the statistical, content, and expression feature sets to demonstrate that the added perspectives supply information beyond the statistical baseline. revision: yes
-
Referee: [Section 4] Section 4 (results on adversarial RAID and Humanize-16K): the generalization claim beyond the specific 17 attacks is asserted without leave-one-attack-out, cross-attack, or theoretical analysis. The reported robustness therefore remains tied to the exact attack set tested and does not yet establish broader applicability.
Authors: The manuscript limits its claims to robustness against the 17 attacks evaluated on the two benchmarks; no broader generalization beyond this attack set is asserted. To provide additional evidence of robustness within the tested attack distribution, we will include leave-one-attack-out results (training on 16 attacks, testing on the held-out attack) in the revised Section 4. revision: yes
Circularity Check
No circularity in empirical framework or reported gains
full rationale
The manuscript describes an empirical three-perspective detector evaluated on fixed benchmarks with 17 attacks. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would make the AUROC/TPR01 improvements equivalent to the input data by construction. The central claim rests on experimental deltas rather than any derivation that reduces to its own definitions or prior self-citations. This is the common honest case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Moustafa Alzantot, Yash Sharma, Ahmed Elgo- hary, Bo-Jhang Ho, Mani Srivastava, and Kai- Wei Chang
Detecting fake news using machine learn- ing: A systematic literature review.arXiv preprint arXiv:2102.04458. Moustafa Alzantot, Yash Sharma, Ahmed Elgo- hary, Bo-Jhang Ho, Mani Srivastava, and Kai- Wei Chang. 2018. Generating natural lan- guage adversarial examples.arXiv preprint arXiv:1804.07998. arXiv. 2024. arxiv.Cornell University. Taseef Ayub, Rayee...
-
[2]
Eugene Bagdasaryan and Vitaly Shmatikov
The art of deception: humanizing ai to outsmart detection.Global Knowledge, Memory and Communication. Eugene Bagdasaryan and Vitaly Shmatikov. 2022. Spinning language models: Risks of propaganda- as-a-service and countermeasures. In2022 IEEE Symposium on Security and Privacy (SP), pages 769–786. IEEE. Anton Bakhtin, Sam Gross, Myle Ott, Yuntian Deng, Marc...
2022
-
[3]
Guangsheng Bao, Yanbin Zhao, Juncai He, and Yue Zhang
Real or fake? learning to discriminate ma- chine from human generated text.arXiv preprint arXiv:1906.03351. Guangsheng Bao, Yanbin Zhao, Juncai He, and Yue Zhang. 2025. Glimpse: Enabling white-box methods to use proprietary models for zero-shot llm-generated text detection.The Thirteenth In- ternational Conference on Learning Representa- tions. Guangsheng...
-
[4]
arXiv preprint arXiv:2405.07940
Raid: A shared benchmark for robust evaluation of machine-generated text detectors. arXiv preprint arXiv:2405.07940. Alok Kumar Dwivedi, Indika Mallawaarachchi, and Luis A Alvarado. 2017. Analysis of small sample size studies using nonparametric boot- strap test with pooled resampling method.Statis- tics in medicine, 36(14):2187–2205. Salijona Dyrmishi, S...
-
[5]
Angela Fan, Mike Lewis, and Yann Dauphin
Tweepfake: About detecting deepfake tweets.Plos one, 16(5):e0251415. Angela Fan, Mike Lewis, and Yann Dauphin. 2018. Hierarchical neural story generation. InPro- ceedings of the 56th Annual Meeting of the Asso- ciation for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics. Linda S Flower and John R Hayes. 2016. T...
2018
-
[6]
Simcse: Simple contrastive learning of sentence embeddings. InProceedings of the 2021 Conference on Empirical Methods in Natu- ral Language Processing, pages 6894–6910. Sebastian Gehrmann, Hendrik Strobelt, and Alexander M Rush. 2019. Gltr: Statistical de- tection and visualization of generated text. In Proceedings of the 57th Annual Meeting of the Associ...
-
[7]
Adversarial Examples for Evaluating Reading Comprehension Systems
Radar: Robust ai-text detection via adver- sarial learning.Advances in Neural Information Processing Systems, 36:15077–15095. Andrew Ilyas, Shibani Santurkar, Dimitris Tsipras, Logan Engstrom, Brandon Tran, and Aleksander Madry. 2019. Adversarial examples are not bugs, they are features.Advances in neural informa- tion processing systems, 32. Daphne Ippol...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[8]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
A watermark for large language models. InInternational Conference on Machine Learn- ing, pages 17061–17084. PMLR. Moshe Koppel, Jonathan Schler, and Shlomo Arg- amon. 2009. Computational methods in author- ship attribution.Journal of the American Society for information Science and Technology, 60(1):9– 26. Kalpesh Krishna, Yixiao Song, Marzena Karpin- ska...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[9]
Towards Deep Learning Models Resistant to Adversarial Attacks
Towards deep learning models resis- tant to adversarial attacks.arXiv preprint arXiv:1706.06083. Chengzhi Mao, Carl V ondrick, Hao Wang, and Jun- feng Yang. 2024. Raidar: generative ai detection via rewriting. InThe Twelfth International Con- ference on Learning Representations. Elyas Masrour, Bradley Emi, and Max Spero
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Damage: Detecting adversarially modified ai generated text.arXiv preprint arXiv:2501.03437. Quinn McNemar. 1947. Note on the sampling error of the difference between correlated proportions or percentages.Psychometrika, 12(2):153–157. Eric Mitchell, Yoonho Lee, Alexander Khazatsky, Christopher D Manning, and Chelsea Finn. 2023. Detectgpt: Zero-shot machine...
-
[11]
Can AI-Generated Text be Reliably Detected?
IEEE. Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2018. Semantically equivalent adver- sarial rules for debugging nlp models. InPro- ceedings of the 56th Annual Meeting of the Asso- ciation for Computational Linguistics (volume 1: long papers), pages 856–865. Vinu Sankar Sadasivan, Aounon Kumar, Sriram Balasubramanian, Wenxiao Wang, and Soheil...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track
Detectrl: Benchmarking llm-generated text detection in real-world scenarios. InThe Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track. Yang Xu, Yu Wang, Hao An, Zhichen Liu, and Yongyuan Li. 2024. Detecting subtle differences between human and model languages using spec- trum of relative likelihood. InProceeding...
2024
-
[13]
In The Twelfth International Conference on Learn- ing Representations
Dna-gpt: Divergent n-gram analysis for training-free detection of gpt-generated text. In The Twelfth International Conference on Learn- ing Representations. William J Youden. 1950. Index for rating diagnos- tic tests.Cancer, 3(1):32–35. Xiao Yu, Yuang Qi, Kejiang Chen, Guoqiang Chen, Xi Yang, Pengyuan Zhu, Xiuwei Shang, Weim- ing Zhang, and Nenghai Yu. 20...
-
[14]
Write a student essay (no title) in {nwords} words (split into {nparagraphs} paragraphs) based on the given title: {title}
by crawling PDFs published between 2020 and 2024, randomly selecting 200 papers per year. Using S2ORC (Lo et al., 2020), the PDFs are parsed to extract titles and introductions. These titles are then used to prompt LLMs to generate new paper introductions. Creative WritingWe randomly pull 1,000 sam- ples from WritingPrompts (Fan et al., 2018), with each s...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.