Geometric and Information Compression of Representations in Deep Learning
Pith reviewed 2026-06-26 14:50 UTC · model grok-4.3
The pith
Low mutual information does not reliably correspond to geometric compression in neural network representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
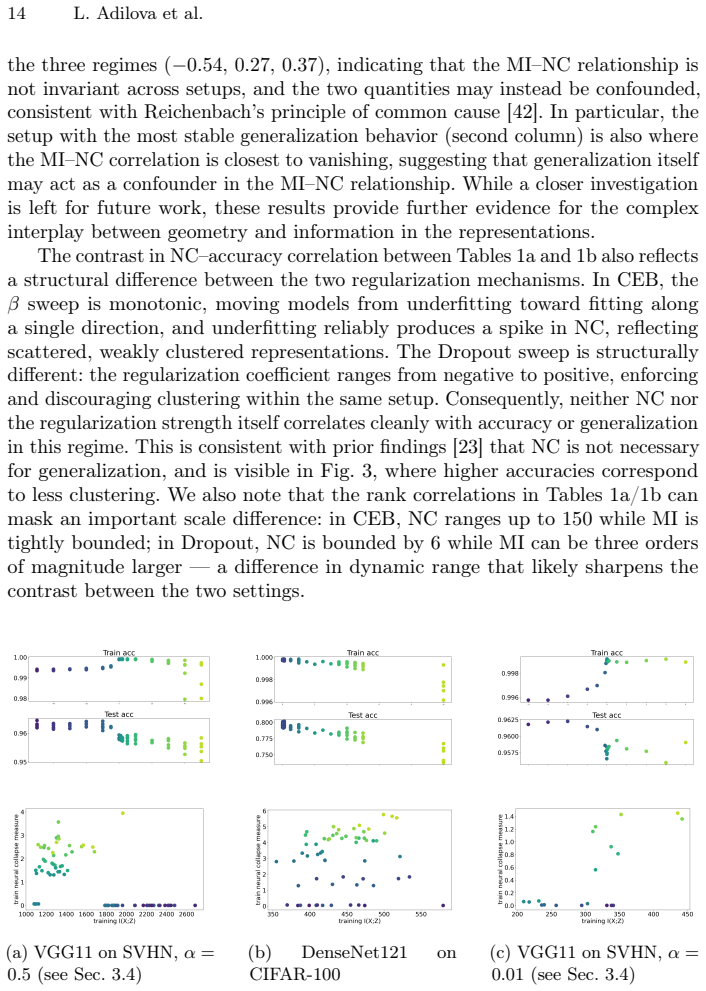
Our findings show that low MI does not reliably correspond to geometric compression, and that the connection between the two is more nuanced than often assumed. Indeed, our experiments reveal a negative and nonlinear relationship that can reverse when varying training setup. Our results put forward a hypothesis that generalization acts as a potential confounder in this connection rather than being their direct consequence.
What carries the argument
Class-wise clustering as a measure of geometric compression, paired with mutual information estimation under controlled noise injection in conditional entropy bottleneck and continuous dropout networks.
If this is right
- Low mutual information cannot be treated as direct evidence of geometric compression.
- The sign and strength of the MI-geometry link depend on details of the training procedure.
- Generalization performance can confound attempts to link information compression directly to geometric compression.
- Varying noise injection or network type can alter or invert the observed relationship.
Where Pith is reading between the lines
- Separate metrics may be needed when trying to enforce both information and geometric properties in the same model.
- Experiments that hold generalization fixed could isolate whether a direct MI-geometry link exists.
- Prior claims that equate the two forms of compression may need re-evaluation under controlled generalization conditions.
- Regularization strategies could be designed to target geometry independently of mutual information objectives.
Load-bearing premise
Class-wise clustering serves as a sufficient unbiased measure of geometric compression and the chosen MI estimation with noise schemes isolates the MI-geometry link without uncontrolled effects from generalization.
What would settle it
A consistent positive linear correlation between lower mutual information and stronger class-wise clustering that holds across multiple training setups and does not reverse would contradict the reported nuanced relationship.
Figures



read the original abstract
Deep neural networks transform input data into latent representations that support a wide range of downstream tasks. These representations can be characterized along information-theoretic and geometric dimensions, but their relationship remains poorly understood. A central open question is whether low mutual information (MI) between inputs and representations necessarily implies geometrically compressed latent spaces and vice versa. We investigate this question using class-wise clustering as a measure of geometric compression and theoretically sound MI estimation in conditional entropy bottleneck (CEB) networks and continuous dropout networks. We evaluate the interplay between MI, geometric compression, and generalization on classification tasks under controlled noise injection schemes. Our findings show that low MI does not reliably correspond to geometric compression, and that the connection between the two is more nuanced than often assumed. Indeed, our experiments reveal a negative and nonlinear relationship that can reverse when varying training setup. Our results put forward a hypothesis that generalization acts as a potential confounder in this connection rather than being their direct consequence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates whether low mutual information (MI) between inputs and latent representations in deep networks necessarily implies geometric compression (and vice versa). Using class-wise clustering as a proxy for geometric compression together with theoretically sound MI estimators, the authors conduct experiments in conditional entropy bottleneck (CEB) networks and continuous dropout networks on classification tasks under controlled noise injection. They report a negative, nonlinear relationship between MI and the clustering measure that can reverse with changes in training setup, and hypothesize that generalization performance acts as a confounder rather than a direct consequence of the MI-geometry link.
Significance. If the central empirical relationship is shown to be robust to the choice of geometric-compression proxy, the result would usefully qualify the information-bottleneck narrative in representation learning by demonstrating that MI reduction and geometric compression are not interchangeable. The explicit use of theoretically sound MI estimators is a methodological strength that could be leveraged by follow-up work.
major comments (1)
- [Abstract] Abstract and experimental setup: the central claim that low MI does not reliably correspond to geometric compression (and that the relationship is negative/nonlinear and reversible) rests on class-wise clustering as the sole measure of geometric compression. This proxy primarily quantifies label-driven class separability encouraged by the classification objective; it does not isolate intrinsic geometric quantities such as manifold volume, intrinsic dimension, or local curvature independent of label information. Because the same factors (bottleneck, noise) modulate both MI and the clustering metric, the observed nuance and reversal may be an artifact of the measurement choice rather than evidence against a direct MI-geometry link.
minor comments (1)
- [Abstract] The abstract states the main findings but supplies no quantitative values, error bars, or controls; readers cannot assess effect sizes or statistical support without the full results tables or figures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The major comment concerns our use of class-wise clustering as the geometric compression proxy. We address this point directly below and outline textual revisions to better scope our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental setup: the central claim that low MI does not reliably correspond to geometric compression (and that the relationship is negative/nonlinear and reversible) rests on class-wise clustering as the sole measure of geometric compression. This proxy primarily quantifies label-driven class separability encouraged by the classification objective; it does not isolate intrinsic geometric quantities such as manifold volume, intrinsic dimension, or local curvature independent of label information. Because the same factors (bottleneck, noise) modulate both MI and the clustering metric, the observed nuance and reversal may be an artifact of the measurement choice rather than evidence against a direct MI-geometry link.
Authors: We agree that class-wise clustering, as implemented via the Davies-Bouldin index on the latent representations, primarily captures label-driven separability induced by the supervised objective rather than purely intrinsic geometric properties. The manuscript already states in the abstract and Section 3 that this is the chosen proxy for geometric compression in classification settings. Our central empirical finding is therefore scoped to the relationship between MI and this specific clustering measure; we do not claim equivalence to all possible geometric notions. The observed negative nonlinear relationship and its reversal under different training regimes remain valid observations for this proxy. To address the concern, we will revise the abstract to explicitly qualify the proxy, add a limitations paragraph in the discussion acknowledging that the measure is label-dependent, and note that alternative intrinsic measures (e.g., manifold dimension estimators) lie outside the current scope but would be valuable for follow-up work. revision: yes
Circularity Check
Empirical study with observations from experiments; no derivation chain or self-referential reductions
full rationale
The paper reports experimental findings on the relationship between mutual information and class-wise clustering in CEB and dropout networks under noise injection. All central claims are presented as direct observations from these measurements rather than as derivations from equations or first principles. No load-bearing steps reduce by construction to fitted parameters, self-citations, or ansatzes; the work is self-contained via its experimental protocol and does not invoke uniqueness theorems or rename known results as new derivations.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
IEEE transactions on pattern analysis and machine intelligence40(12), 2897–2905 (2018)
Achille, A., Soatto, S.: Information dropout: Learning optimal representations through noisy computation. IEEE transactions on pattern analysis and machine intelligence40(12), 2897–2905 (2018)
2018
-
[2]
In: The Eleventh International Conference on Learning Representations (2023)
Adilova, L., Geiger, B.C., Fischer, A.: Information plane analysis for dropout neural networks. In: The Eleventh International Conference on Learning Representations (2023)
2023
-
[3]
Advances in Neural Information Processing Systems35, 17626–17638 (2022)
Agrawal, K.K., Mondal, A.K., Ghosh, A., Richards, B.: Assessing representation quality in self-supervised learning by measuring eigenspectrum decay. Advances in Neural Information Processing Systems35, 17626–17638 (2022)
2022
-
[4]
In: International Conference on Learning Representations (2017)
Alemi, A.A., Fischer, I., Dillon, J.V., Murphy, K.: Deep variational information bottleneck. In: International Conference on Learning Representations (2017)
2017
-
[5]
IEEE Transactions on Pattern Analysis and Machine Intelligence42(9), 2225–2239 (2019)
Amjad, R.A., Geiger, B.C.: Learning representations for neural network-based classification using the information bottleneck principle. IEEE Transactions on Pattern Analysis and Machine Intelligence42(9), 2225–2239 (2019)
2019
-
[6]
In: International Conference on Learning Representations (2018)
Belghazi, M.I., Baratin, A., Rajeshwar, D., Ozair, S., Bengio, Y., Courville, A., Hjelm, R.D.: Mutual information neural estimation. In: International Conference on Learning Representations (2018)
2018
-
[7]
Bhargava, P., Drozd, A., Rogers, A.: Generalization in nli: Ways (not) to go beyond simple heuristics (2021)
2021
-
[8]
Advances in Neural Information Processing Systems31(2018)
Blier, L., Ollivier, Y.: The description length of deep learning models. Advances in Neural Information Processing Systems31(2018)
2018
-
[9]
In: Advances in Neural Information Processing Systems
Chechik, G., Globerson, A., Tishby, N., Weiss, Y.: Information bottleneck for Gaussian variables. In: Advances in Neural Information Processing Systems. vol. 16 (2003)
2003
-
[10]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
Cheng, E., Kervadec, C., Baroni, M.: Bridging information-theoretic and geomet- ric compression in language models. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 12397–12420 (2023)
2023
-
[11]
In: International Conference on Machine Learning
Cheng, Y., Song, J., Miao, Y.: Club: A contrastive log-ratio upper bound of mutual information. In: International Conference on Machine Learning. PMLR (2020)
2020
-
[12]
In: International conference on machine learning
Cisse, M., Bojanowski, P., Grave, E., Dauphin, Y., Usunier, N.: Parseval networks: Improving robustness to adversarial examples. In: International conference on machine learning. pp. 854–863. PMLR (2017)
2017
-
[13]
Dziugaite, G.K., Roy, D.M.: Computing nonvacuous generalization bounds for deep (stochastic) neural networks with many more parameters than training data. arXiv preprint arXiv:1703.11008 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
In: Proc
Federici, M., Dutta, A., Forré, P., Kushman, N., Akata, Z.: Learning robust repre- sentations via multi-view information bottleneck. In: Proc. Int. Conf. on Learning Representations (ICLR). virtual (Apr 2020) Geometric and Information Compression of Representations 17
2020
-
[15]
Entropy22(9), 999 (2020)
Fischer, I.: The conditional entropy bottleneck. Entropy22(9), 999 (2020)
2020
-
[16]
In: International Conference on Learning Representations (2021)
Galanti, T., György, A., Hutter, M.: On the role of neural collapse in transfer learning. In: International Conference on Learning Representations (2021)
2021
-
[17]
In: International conference on machine learning
Garrido, Q., Balestriero, R., Najman, L., Lecun, Y.: Rankme: Assessing the down- stream performance of pretrained self-supervised representations by their rank. In: International conference on machine learning. pp. 10929–10974. PMLR (2023)
2023
-
[18]
Entropy22(11), 1229 (Nov 2020), open-access
Geiger, B.C., Fischer, I.S.: A comparison of variational bounds for the information bottleneck functional. Entropy22(11), 1229 (Nov 2020), open-access
2020
-
[19]
IEEE Transactions on Neural Networks and Learning Systems33(12), 7039–7051 (Dec 2022)
Geiger, B.C.: On information plane analyses of neural network classifiers – a review. IEEE Transactions on Neural Networks and Learning Systems33(12), 7039–7051 (Dec 2022)
2022
-
[20]
Journal of Machine Learning Research3(Mar), 1307–1331 (2003)
Globerson, A., Tishby, N.: Sufficient dimensionality reduction. Journal of Machine Learning Research3(Mar), 1307–1331 (2003)
2003
-
[21]
In: International Conference on Machine Learning (2019)
Goldfeld, Z.: Estimating information flow in deep neural networks. In: International Conference on Machine Learning (2019)
2019
-
[22]
Advances in neural information processing systems30(2017)
Gomez, A.N., Ren, M., Urtasun, R., Grosse, R.B.: The reversible residual net- work: Backpropagation without storing activations. Advances in neural information processing systems30(2017)
2017
-
[23]
In: Advances in Neural Information Processing Systems (2025)
Han, T., Adilova, L., Petzka, H., Kleesiek, J., Kamp, M.: Flatness is necessary, neural collapse is not: Rethinking generalization via grokking. In: Advances in Neural Information Processing Systems (2025)
2025
-
[24]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
2016
-
[25]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Huang, G., Liu, Z., Van Der Maaten, L., Weinberger, K.Q.: Densely connected convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4700–4708 (2017)
2017
-
[26]
In: International Conference on Learning Representations (2019)
Jiang, Y., Neyshabur, B., Mobahi, H., Krishnan, D., Bengio, S.: Fantastic general- ization measures and where to find them. In: International Conference on Learning Representations (2019)
2019
-
[27]
In: Interna- tional Conference on Learning Representations (2016)
Keskar, N.S., Mudigere, D., Nocedal, J., Smelyanskiy, M., Tang, P.T.P.: On large- batch training for deep learning: Generalization gap and sharp minima. In: Interna- tional Conference on Learning Representations (2016)
2016
-
[28]
In: International Conference on Learning Representations (2019)
Kolchinsky, A., Tracey, B.D., Van Kuyk, S.: Caveats for information bottleneck in deterministic scenarios. In: International Conference on Learning Representations (2019)
2019
-
[29]
Birkhäuser Boston, MA (2012)
Krantz, S.G., Parks, H.R.: A primer of real analytics functions. Birkhäuser Boston, MA (2012)
2012
-
[30]
Proceedings of the IEEE86(11), 2278–2324 (1998)
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proceedings of the IEEE86(11), 2278–2324 (1998)
1998
-
[31]
In: The 22nd international conference on artificial intelligence and statistics
Liang, T., Poggio, T., Rakhlin, A., Stokes, J.: Fisher-rao metric, geometry, and complexity of neural networks. In: The 22nd international conference on artificial intelligence and statistics. pp. 888–896. PMLR (2019)
2019
-
[32]
In: Pro- ceedings of the 2022 SIAM International Conference on Data Mining (SDM)
Marx, A., Fischer, J.: Estimating mutual information via geodesic k nn. In: Pro- ceedings of the 2022 SIAM International Conference on Data Mining (SDM). pp. 415–423. SIAM (2022)
2022
-
[33]
In: International Conference on Artificial Intelligence and Statistics
McAllester, D., Stratos, K.: Formal limitations on the measurement of mutual information. In: International Conference on Artificial Intelligence and Statistics. pp. 875–884. PMLR (2020) 18 L. Adilova et al
2020
-
[34]
In: Advances in Neural Information Processing Systems
Moyer, D., Gao, S., Brekelmans, R., Galstyan, A., Ver Steeg, G.: Invariant represen- tations without adversarial training. In: Advances in Neural Information Processing Systems. vol. 31 (2018)
2018
-
[35]
Representation Learning with Contrastive Predictive Coding
van den Oord, A., Li, Y., Vinyals, O.: Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Proceedings of the National Academy of Sciences117(40), 24652–24663 (2020)
Papyan, V., Han, X., Donoho, D.L.: Prevalence of neural collapse during the terminal phase of deep learning training. Proceedings of the National Academy of Sciences117(40), 24652–24663 (2020)
2020
-
[37]
In: ICLR 2026 Workshop on Geometry-grounded Representation Learning and Generative Modeling (2026)
Patel, L., Bukkapatnam, K.S., Batra, S.: Learning compact representations via intrinsic dimension regularization. In: ICLR 2026 Workshop on Geometry-grounded Representation Learning and Generative Modeling (2026)
2026
-
[38]
In: Workshop on Machine Learning and Compression @ NeurIPS (2024)
Patel, N., Shwartz-Ziv, R.: Learning to compress: Local rank and information compression in deep neural networks. In: Workshop on Machine Learning and Compression @ NeurIPS (2024)
2024
-
[39]
Advances in neural information processing systems34, 18420–18432 (2021)
Petzka, H., Kamp, M., Adilova, L., Sminchisescu, C., Boley, M.: Relative flatness and generalization. Advances in neural information processing systems34, 18420–18432 (2021)
2021
- [40]
-
[41]
IEEE Transactions on Information Forensics and Security18, 2060–2075 (2023)
Razeghi, B., Calmon, F.P., Gunduz, D., Voloshynovskiy, S.: Bottlenecks CLUB: Unifying information-theoretic trade-offs among complexity, leakage, and utility. IEEE Transactions on Information Forensics and Security18, 2060–2075 (2023). https://doi.org/10.1109/TIFS.2023.3262112
-
[42]
Reichenbach, H.: The direction of time, vol. 65. Univ of California Press (1991)
1991
- [43]
-
[44]
In: Proc
Saxe, A.M., Bansal, Y., Dapello, J., Advani, M., Kolchinsky, A., Tracey, B.D., Cox, D.D.: On the information bottleneck theory of deep learning. In: Proc. International Conference on Learning Representations (ICLR). Vancouver (May 2018)
2018
-
[45]
Shwartz-Ziv, R., Tishby, N.: Opening the black box of deep neural networks via information.arXiv:1703.00810v3 [cs.LG](Apr 2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Very Deep Convolutional Networks for Large-Scale Image Recognition
Simonyan, K.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[47]
In: Workshop on Machine Learning and Compression @ NeurIPS (2024)
Skean, O., Arefin, M.R., Shwartz-Ziv, R.: Does representation matter? exploring intermediate layers in large language models. In: Workshop on Machine Learning and Compression @ NeurIPS (2024)
2024
-
[48]
The journal of machine learning research15(1), 1929–1958 (2014)
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., Salakhutdinov, R.: Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research15(1), 1929–1958 (2014)
1929
-
[49]
Turc, I., Chang, M., Lee, K., Toutanova, K.: Well-read students learn better: The impact of student initialization on knowledge distillation. CoRRabs/1908.08962 (2019),http://arxiv.org/abs/1908.08962
-
[50]
Differential and Combinatorial Topology, Princeton Univ Press pp
Whitney, H.: Local properties of analytic varieties. Differential and Combinatorial Topology, Princeton Univ Press pp. 205–244 (1965)
1965
-
[51]
In: British Machine Vision Conference 2016
Zagoruyko, S., Komodakis, N.: Wide residual networks. In: British Machine Vision Conference 2016. British Machine Vision Association (2016)
2016
-
[52]
Zhang, X., Zhao, J., LeCun, Y.: Character-level convolutional networks for text classification. Advances in neural information processing systems28(2015) Geometric and Information Compression of Representations 19 A Proof of Theorem 1 To prove the theorem, we use the following proposition, which extends Proposi- tion 3.5 of [2] to non-constant real analyt...
2015
-
[53]
WRN28-4 + CIFAR-10:256
-
[54]
DenseNet-121 + CIFAR-100:256 For the setups in Gaussian dropout experiments the following hyper parame- ters were used:
-
[55]
ResNet18 + CIFAR-10: batch size128, learning rate0.1, training for100 epochs with SGD with weight decay of5e− 4, momentum0 .9and cosine annealing learning rate scheduler
-
[56]
VGG11 + SVHN: batch size256, learning rate0.01, training for150epochs with SGD with weight decay of5e− 4, momentum0 .9and cosine annealing learning rate scheduler
-
[57]
DenseNet-121 + CIFAR-100: batch size256, learning rate0.1, training for 200epochs with SGD with weight decay of5e− 4, momentum0 .9and cosine annealing learning rate scheduler
-
[58]
logistic
mini-BERT + AG News: batch size256, learning rate1e− 5, training for 20epochs with AdamW with weight decay of1e− 2and cosine annealing learning rate scheduler. B.3 Per-seed Confidence Intervals for Dropout Setup In Table 2, we report per-seed correlations for the Gaussian dropout setup, aggregated to obtain a mean and standard deviation, alongside the ove...
-
[59]
1(a)), which indicates that noise causes class-specific distributions to overlap
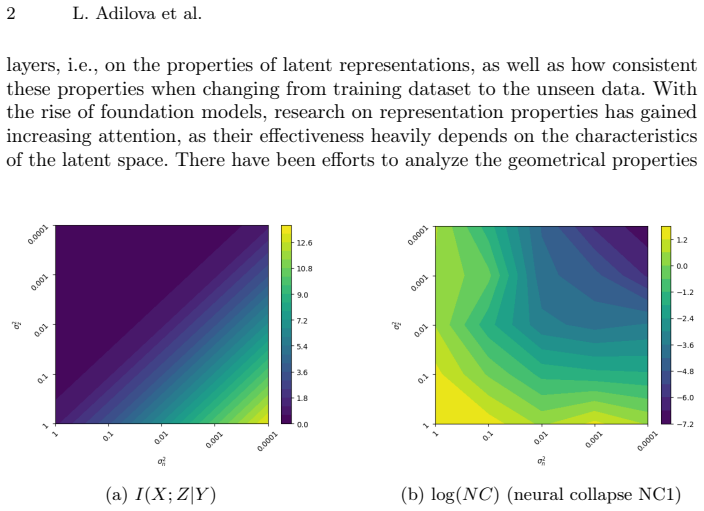
A large encoder noise varianceσ2 n (lower left corner of Fig. 1(a)), which indicates that noise causes class-specific distributions to overlap
-
[60]
1(a)), which indicates that samples from the same class are mapped closely in latent space, at least via the deterministic part ofµ(x)of the encoder
A small varianceσ2 z of the encoder mean (upper right corner of Fig. 1(a)), which indicates that samples from the same class are mapped closely in latent space, at least via the deterministic part ofµ(x)of the encoder. In contrast, the neural collapse measureN C is small only if bothσ2 n and σ2 z are small (upper right corner of Fig. 1(b)). While geometri...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.