Towards Robustness against Typographic Attack with Training-free Concept Localization
Pith reviewed 2026-07-03 14:39 UTC · model grok-4.3
The pith
Specific attention heads in vision transformers encode the lexical bias behind typographic attacks and can be adjusted directly to restore visual focus.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
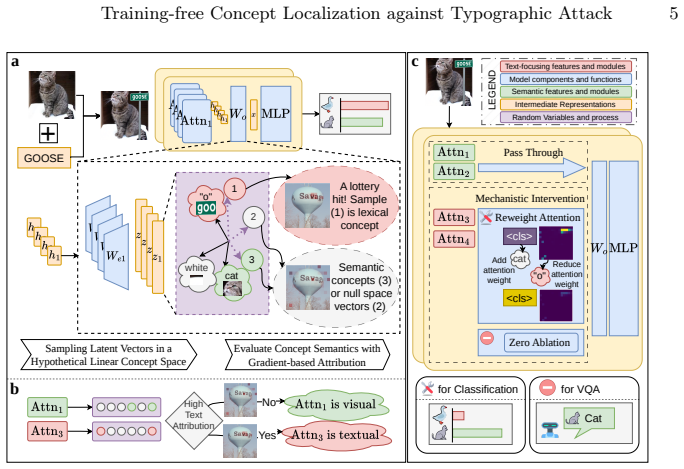
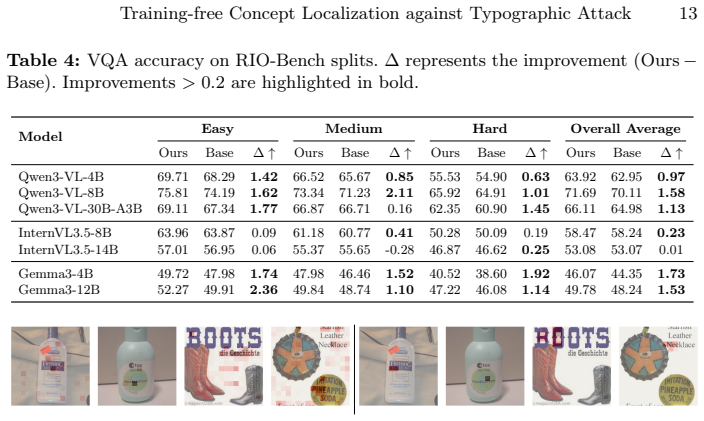
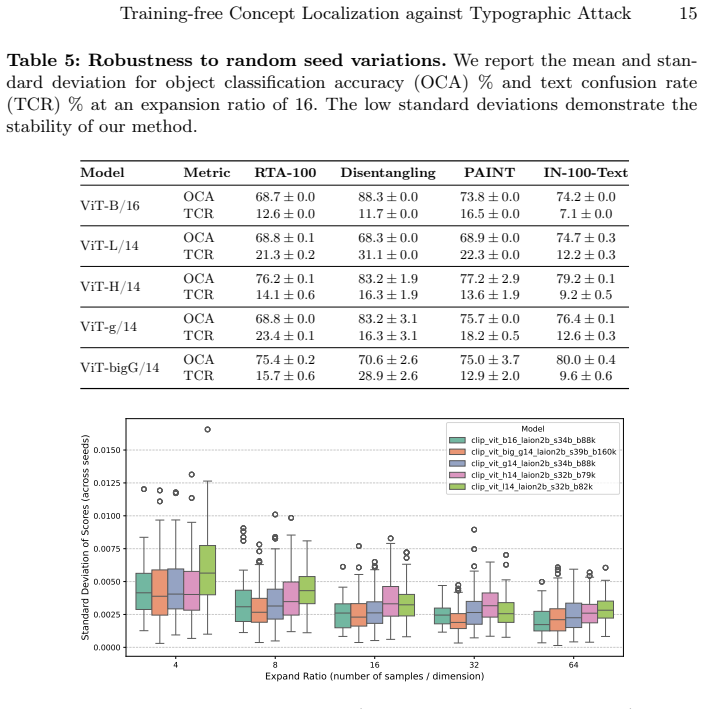
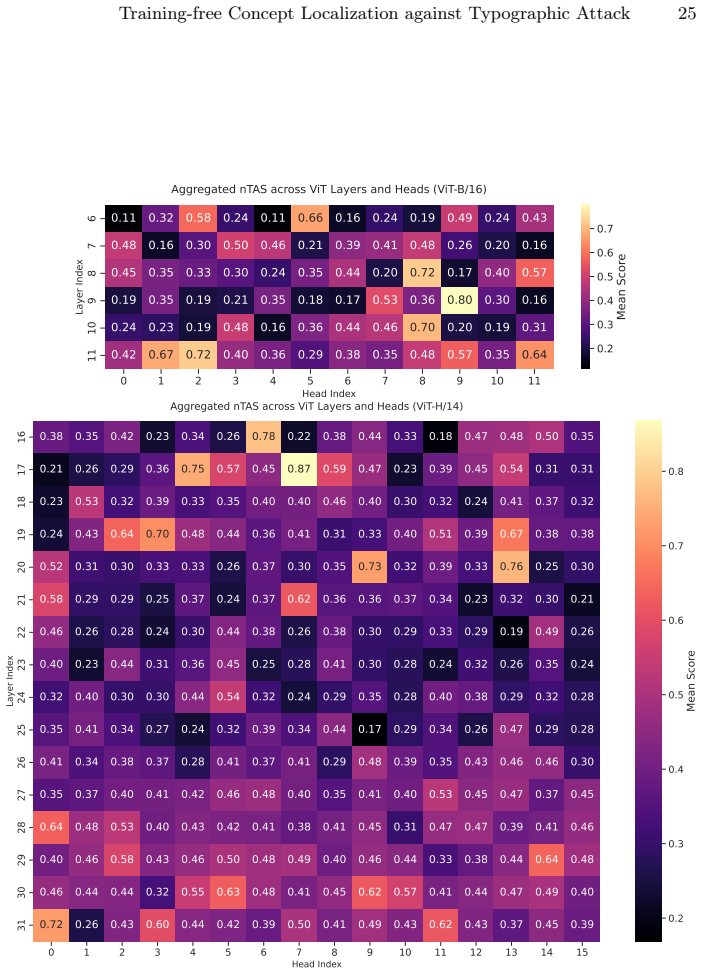
The central claim is that sampling-based interpretations of hidden states, followed by quantitative attribution of semantic versus lexical focus and probabilistic circuit mining, isolate particular ViT attention heads that disproportionately encode lexical information; simple interventions applied to those heads, such as selective adjustment of attention weights, substantially improve robustness to typographic attacks in object classification and yield measurable gains when applied to the vision encoders of state-of-the-art LVLMs on RIO-Bench VQA tasks under attack.
What carries the argument
Sampling-based attribution combined with probabilistic circuit mining that isolates individual ViT attention heads encoding lexical information.
If this is right
- Interventions on the mined circuits raise object-classification accuracy under typographic attack without any model retraining.
- The same interventions outperform both supervised and other training-free defense methods.
- Applying the intervention to vision encoders of multiple large vision-language models produces clear accuracy gains on Visual Question Answering under typographic interference.
- The mechanistic localization is reusable across different CLIP-based architectures.
Where Pith is reading between the lines
- The attacks appear to be carried by a small, localized subset of heads rather than being diffusely distributed across the entire transformer.
- Similar attribution-plus-intervention pipelines could be tested on other documented failure modes such as hallucination or spatial reasoning errors in the same models.
- Because the method requires no gradient updates, it could be applied at inference time on deployed systems where retraining is costly or impossible.
- The approach suggests that interpretability techniques originally developed for language models can be transferred to isolate and patch concrete visual-semantic conflicts.
Load-bearing premise
The sampling procedure and subsequent probabilistic analysis correctly identify the specific attention heads whose lexical encoding is the mechanistic cause of typographic attacks.
What would settle it
A controlled test in which the identified heads are ablated or re-weighted exactly as proposed yet robustness on typographic-attack images shows no improvement or worsens relative to an untouched baseline.
Figures




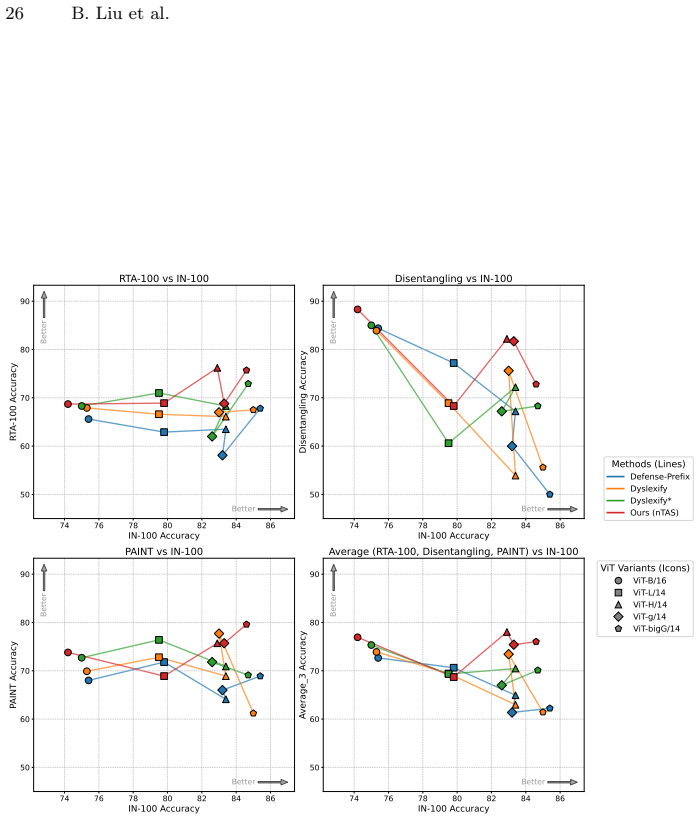
read the original abstract
Models trained via Contrastive Language-Image Pretraining (CLIP) serve as the foundational vision encoders for most modern Large Vision Language Models (LVLMs). Despite their widespread adoption, CLIP models exhibit a critical yet underexplored failure mode: irrelevant text appearing within images confounds visual representations, biasing them toward lexical meaning rather than true visual semantics. This robustness issue, commonly described as a Typographic Attack (TA), exposes a vulnerability that poses a significant risk to safety-critical applications such as autonomous driving. To achieve interpretable and effective robustness against TA, we propose a novel, training-free mechanistic interpretability method. Our method provides sampling-based interpretations of hidden state representations and quantitatively attributes semantic versus lexical focus to individual attention heads. Through probabilistic analysis and circuit mining, we isolate specific Vision Transformer (ViT) components that disproportionately encode lexical information, thereby identifying the mechanistic source of TA. We further show that simple interventions applied directly to the identified circuits, without any additional training, can substantially improve robustness against Typographic Attacks in object classification. These interventions, such as selective adjustment of attention weights, also outperform both supervised and training-free defense methods. Our experiments demonstrate that applying the proposed intervention to the vision encoders of several state-of-the-art LVLMs yields substantial gains in Visual Question Answering accuracy under Typographic Attack interference on RIO-Bench. These results confirm both the efficacy and the generalizability of our mechanistic approach. Code is released at https://github.com/Liu-524/SamplingTAR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a training-free mechanistic interpretability pipeline—sampling-based attribution of hidden states, probabilistic analysis to quantify lexical vs. semantic focus per attention head, and circuit mining—identifies specific ViT components in CLIP encoders as the source of typographic attacks; simple interventions on those circuits (e.g., selective attention-weight adjustment) then yield substantial robustness gains in object classification that outperform both supervised and training-free baselines, with the same interventions generalizing to improve VQA accuracy under TA on RIO-Bench for multiple LVLMs.
Significance. If the attribution correctly isolates lexical-encoding heads and the interventions prove effective without retraining, the work supplies both a mechanistic account of a known CLIP failure mode and a practical, interpretable defense that could be applied to safety-critical vision-language systems; the released code and explicit intervention descriptions strengthen verifiability.
minor comments (3)
- Abstract and §3: the description of the probabilistic analysis that attributes 'lexical information' to heads would benefit from an explicit formula or pseudocode for the attribution score, as the current prose leaves the exact aggregation over samples unclear.
- §4.2 and Table 2: the claim that interventions 'outperform both supervised and training-free defense methods' should include the precise baseline implementations and hyper-parameters used for comparison to allow direct replication.
- Figure 3 caption: axis labels and the meaning of the color scale for head-wise lexical scores are not defined in the caption or surrounding text.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. No specific major comments were raised in the report, so we have no point-by-point responses to provide. We will address any minor issues identified during the revision process.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes a sampling-based attribution method to identify ViT attention heads encoding lexical information via probabilistic analysis and circuit mining, followed by direct training-free interventions such as attention weight adjustment. No equations or steps reduce the reported robustness gains to quantities fitted on the same attack data by construction, nor does the central claim rely on self-citation chains or imported uniqueness theorems. The method is presented as mechanistic analysis with released code for external verification, making the derivation self-contained against the described inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Azuma, H., Matsui, Y.: Defense-prefix for preventing typographic attacks on CLIP. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 3644–3653 (2023)
2023
-
[2]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-VL: A versatile vision-language model for understanding, localization, text reading, and beyond. arXiv preprint arXiv:2308.12966 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-VL technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Cao, Y., Xing, Y., Zhang, J., Lin, D., Zhang, T., Tsang, I., Liu, Y., Guo, Q.: Scenetap: Scene-coherent typographic adversarial planner against vision-language models in real-world environments. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 25050–25059 (June 2025)
2025
-
[5]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 24185–24198. IEEE (2024)
2024
-
[6]
Cheng, H., Xiao, E., Gu, J., Yang, L., Duan, J., Zhang, J., Cao, J., Xu, K., Xu, R.: Unveiling typographic deceptions: Insights of the typographic vulnerability in large vision-language models. In: Computer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part LIX. p. 179–196. Springer-Verlag, Berlin, ...
-
[7]
arXiv preprint arXiv:2405.14169 (2024)
Chung, N., Gao, S., Vu, T.A., Zhang, J., Liu, A., Lin, Y., Dong, J.S., Guo, Q.: Towards transferable attacks against vision-llms in autonomous driving with ty- pography. arXiv preprint arXiv:2405.14169 (2024)
-
[8]
In: The Twelfth International Conference on Learning Representations (2024), https://openreview.net/forum?id=2dnO3LLiJ1
Darcet, T., Oquab, M., Mairal, J., Bojanowski, P.: Vision transformers need regis- ters. In: The Twelfth International Conference on Learning Representations (2024), https://openreview.net/forum?id=2dnO3LLiJ1
2024
-
[9]
In: 2009 IEEE Conference on Computer Vision and Show Me Examples 17 Pattern Recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition. pp. 248–255 (2009).https://doi.org/10.1109/CVPR.2009. 5206848
-
[10]
In: In- ternational Conference on Learning Representations (2021),https://openreview
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., Houlsby, N.: An image is worth 16x16 words: Transformers for image recognition at scale. In: In- ternational Conference on Learning Representations (2021),https://openreview. net/forum?id=YicbFdNTTy
2021
-
[11]
arXiv preprint arXiv:2505.20229 (2025)
Dreyer, M., Hufe, L., Berend, J., Wiegand, T., Lapuschkin, S., Samek, W.: From what to how: Attributing CLIP’s latent components reveals unexpected semantic reliance. arXiv preprint arXiv:2505.20229 (2025)
-
[12]
Transformer Circuits Thread (2022), https://transformer- circuits.pub/2022/toy_model/index.html Training-free Concept Localization against Typographic Attack 17
Elhage, N., Hume, T., Olsson, C., Schiefer, N., Henighan, T., Kravec, S., Hatfield-Dodds, Z., Lasenby, R., Drain, D., Chen, C., Grosse, R., McCan- dlish, S., Kaplan, J., Amodei, D., Wattenberg, M., Olah, C.: Toy mod- els of superposition. Transformer Circuits Thread (2022), https://transformer- circuits.pub/2022/toy_model/index.html Training-free Concept ...
2022
-
[13]
Transformer Circuits Thread (2021), https://transformer-circuits.pub/2021/framework/index.html
Elhage, N., Nanda, N., Olsson, C., Henighan, T., Joseph, N., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., DasSarma, N., Drain, D., Ganguli, D., Hatfield- Dodds, Z., Hernandez, D., Jones, A., Kernion, J., Lovitt, L., Ndousse, K., Amodei, D., Brown, T., Clark, J., Kaplan, J., McCandlish, S., Olah, C.: A mathemat- ical framework for transformer circ...
2021
-
[14]
In: International Conference on Learning Representations (2019), https://openreview.net/forum?id=rJl-b3RcF7
Frankle, J., Carbin, M.: The lottery ticket hypothesis: Finding sparse, trainable neural networks. In: International Conference on Learning Representations (2019), https://openreview.net/forum?id=rJl-b3RcF7
2019
-
[15]
In: The Twelfth International Confer- ence on Learning Representations (2024),https://openreview.net/forum?id= 5Ca9sSzuDp
Gandelsman, Y., Efros, A.A., Steinhardt, J.: Interpreting CLIP’s image repre- sentation via text-based decomposition. In: The Twelfth International Confer- ence on Learning Representations (2024),https://openreview.net/forum?id= 5Ca9sSzuDp
2024
-
[16]
arXiv preprint arXiv:2406.04341 (2024),https://arxiv.org/ abs/2406.04341
Gandelsman, Y., Efros, A.A., Steinhardt, J.: Interpreting the second-order effects of neurons in CLIP. arXiv preprint arXiv:2406.04341 (2024),https://arxiv.org/ abs/2406.04341
-
[17]
Gemma Team, Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ramé, A., Rivière, M., Rouillard, L., Mesnard, T., Cideron, G., Grill, J.B., Ramos, S., Yvinec, E., Casbon, M., Pot, E., Penchev, I., Liu, G., Visin, F., Kenealy, K., Beyer, L., Zhai, X., Tsitsulin, A., Busa-Fekete, R., Feng, A., Sachdeva, N., Coleman,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Distill6(3), e30 (2021)
Goh, G., Cammarata, N., Voss, C., Carter, S., Petrov, M., Schubert, L., Radford, A., Olah, C.: Multimodal neurons in artificial neural networks. Distill6(3), e30 (2021)
2021
-
[19]
In: The Twelfth In- ternational Conference on Learning Representations (2024),https://openreview
Huben, R., Cunningham, H., Smith, L.R., Ewart, A., Sharkey, L.: Sparse autoen- coders find highly interpretable features in language models. In: The Twelfth In- ternational Conference on Learning Representations (2024),https://openreview. net/forum?id=F76bwRSLeK
2024
-
[20]
In: The Fourteenth International Conference on Learning Representations (2026),https: //openreview.net/forum?id=UI7mbsIZeN
Hufe, L., Venhoff, C., Dreyer, M., Purelku, E., Lapuschkin, S., Samek, W.: Dyslexify: A mechanistic defense against typographic attacks in CLIP. In: The Fourteenth International Conference on Learning Representations (2026),https: //openreview.net/forum?id=UI7mbsIZeN
2026
-
[21]
Advances in Neural Information Processing Systems35, 29262–29277 (2022)
Ilharco, G., Wortsman, M., Gadre, S.Y., Song, S., Hajishirzi, H., Kornblith, S., Farhadi, A., Schmidt, L.: Patching open-vocabulary models by interpolating weights. Advances in Neural Information Processing Systems35, 29262–29277 (2022)
2022
-
[22]
arXiv preprint arXiv:2406.17759 (2024),https://arxiv.org/abs/2406.17759
Kissane, C., Krzyzanowski, R., Bloom, J.I., Conmy, A., Nanda, N.: Interpreting attention layer outputs with sparse autoencoders. arXiv preprint arXiv:2406.17759 (2024),https://arxiv.org/abs/2406.17759
-
[23]
In: Bouamor, H., Pino, J., Bali, K
Li, C., Wang, S., Zhang, Y., Zhang, J., Zong, C.: Interpreting and exploiting functional specialization in multi-head attention under multi-task learning. In: Bouamor, H., Pino, J., Bali, K. (eds.) Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 16460–16476. Associ- ation for Computational Linguistics, Singapore...
-
[24]
Advances in neural information processing systems36, 34892–34916 (2023)
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023)
2023
-
[25]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Materzyńska, J., Torralba, A., Bau, D.: Disentangling visual and written concepts in CLIP. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 16410–16419 (June 2022)
2022
-
[26]
In: Proceedings of the 41st International Con- ference on Machine Learning
Park, K., Choe, Y.J., Veitch, V.: The linear representation hypothesis and the geometry of large language models. In: Proceedings of the 41st International Con- ference on Machine Learning. ICML’24, JMLR.org (2024)
2024
-
[27]
In: Meila, M., Zhang, T
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning. Proceed- ings of Machine Learning Res...
2021
-
[28]
Advances in neural information processing systems35, 25278–25294 (2022)
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: LAION-5B: An open large-scale dataset for training next generation image-text models. Advances in neural information processing systems35, 25278–25294 (2022)
2022
-
[29]
Kaggle (2021),https://www.kaggle.com/datasets/ ambityga/imagenet100, accessed: 2026-01-16
Shekhar, A.: ImageNet100. Kaggle (2021),https://www.kaggle.com/datasets/ ambityga/imagenet100, accessed: 2026-01-16
2021
-
[30]
arXiv preprint arXiv:2506.17052 (2025)
Su, J., Kempe, J., Ullrich, K.: From concepts to components: Concept-agnostic at- tention module discovery in transformers. arXiv preprint arXiv:2506.17052 (2025)
-
[31]
Tian, Y., Krishnan, D., Isola, P.: Contrastive multiview coding. In: Computer Vision – ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XI. p. 776–794. Springer-Verlag, Berlin, Heidelberg (2020). Training-free Concept Localization against Typographic Attack 19 https://doi.org/10.1007/978-3-030-58621-8_45,https://doi....
-
[32]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tong, S., Liu, Z., Zhai, Y., Ma, Y., LeCun, Y., Xie, S.: Eyes wide shut? exploring the visual shortcomings of multimodal llms. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9568–9578 (2024)
2024
-
[33]
In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L.u., Polosukhin, I.: Attention is all you need. In: Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 30. Curran Associates, Inc. (2017),https://proceedings.neurips....
2017
-
[34]
In: ICLR 2025 Workshop on Foundation Models in the Wild (2025),https://openreview.net/forum?id= U4z69U9m9t
Wang, G., Bai, L., Nah, W.J., Wang, J., Zhang, Z., Chen, Z., Wu, J., Islam, M., Liu, H., Ren, H.: Surgical-LVLM: Learning to adapt large vision-language model for grounded visual question answering in robotic surgery. In: ICLR 2025 Workshop on Foundation Models in the Wild (2025),https://openreview.net/forum?id= U4z69U9m9t
2025
-
[35]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al.: InternVL3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency. arXiv preprint arXiv:2508.18265 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
In: Chiruzzo, L., Ritter, A., Wang, L
Wang, X., Zhao, Z., Larson, M.: Typographic attacks in a multi-image setting. In: Chiruzzo, L., Ritter, A., Wang, L. (eds.) Proceedings of the 2025 Confer- ence of the Nations of the Americas Chapter of the Association for Compu- tational Linguistics: Human Language Technologies (Volume 1: Long Papers). pp. 12594–12604. Association for Computational Lingu...
-
[37]
CoRRabs/2512.11899(2025).https://doi.org/10
Waseda, F., Yamabe, S., Shiono, D., Sasaki, K., Takahashi, T.: Read or ignore? A unified benchmark for typographic-attack robustness and text recognition in vision-language models. CoRRabs/2512.11899(2025).https://doi.org/10. 48550/ARXIV.2512.11899,https://doi.org/10.48550/arXiv.2512.11899
-
[38]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-Image technical report. arXiv preprint arXiv:2508.02324 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Yang, Z., Jia, X., Li, H., Yan, J.: LLM4Drive: A survey of large language models for autonomous driving. arXiv preprint arXiv:2311.01043 (2023)
-
[40]
{text_word}
Zaigrajew, V., Baniecki, H., Biecek, P.: Interpreting CLIP with hierarchical sparse autoencoders. In: Forty-second International Conference on Machine Learning (2025),https://openreview.net/forum?id=5MQQsenQBm 20 B. Liu et al. A Appendix A.1 Dataset Details Circuit Mining Dataset.Our training-free concept mining process takes a text-injected image dataset...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.