μFlow: Leveraging Average Images for Improving Generalisation of Deepfake Faces Detectors
Pith reviewed 2026-06-30 06:22 UTC · model grok-4.3
The pith
A normalizing flow on averaged real-image features detects deepfakes by likelihood without any fake training examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Averaging multiple real images amplifies consistent generative traces, allowing a normalizing flow trained solely on the resulting real-feature distribution to produce a likelihood criterion that separates individual real images from fake images generated by unseen models.
What carries the argument
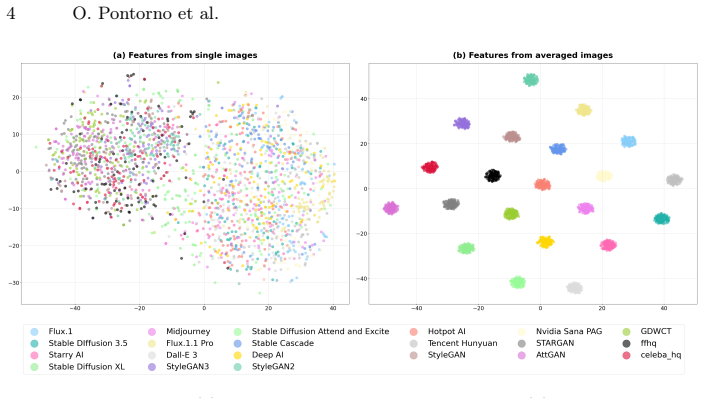
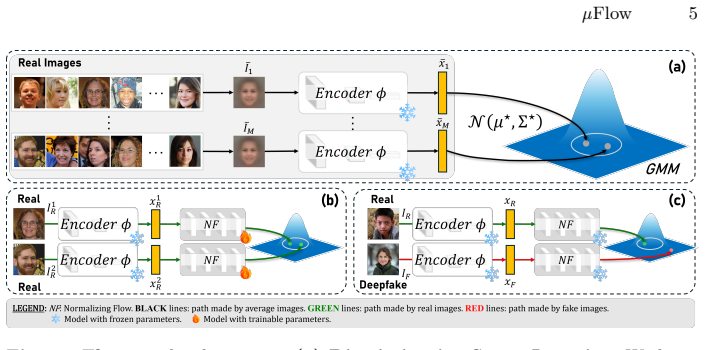
Averaging of real images to amplify generative traces, followed by a normalizing flow that models the distribution of the resulting averaged features and scores individual images by likelihood under that distribution.
If this is right
- Deepfake detectors can be trained without ever seeing fake images or creating pseudo-fakes.
- Generalization holds when both the real and fake evaluation sets come from generators absent from training.
- The same real-only training procedure works across different generator families such as GANs and diffusion models.
- Detection reduces to a likelihood threshold rather than a learned decision boundary between real and fake classes.
Where Pith is reading between the lines
- The averaging step may be replaced by other aggregation operators that preserve consistent traces while suppressing image-specific content.
- The approach could be applied to other domains where subtle but consistent artifacts appear across many samples, such as sensor fingerprinting or medical image anomaly detection.
- Because the flow is trained only on real data, periodic retraining on fresh real photographs could maintain performance as new camera models appear.
Load-bearing premise
Averaging multiple images reliably strengthens shared generative traces enough for the flow to separate real from fake samples on the basis of likelihood.
What would settle it
On a new fully out-of-distribution test set containing both unseen real photographs and images from a previously unseen generator, the likelihood scores produced by the flow fail to separate the two classes better than chance or a simple supervised baseline.
Figures

read the original abstract
Current generative models, including GANs and diffusion models, have reached an outstanding level of photorealism, posing significant risks to privacy and security. To ensure real-world applicability, deepfake detectors must generalise effectively to unseen generators. However, most existing approaches rely on supervised training with both real and fake images, which limits their generalisation especially across generators categories (e.g. GANs vs DMs). In this work, we introduce $\mu$Flow, a one-class deepfake detector trained only on real images without relying on pseudo-deepfakes or synthetic artifacts. Our approach builds on the observation that averaging multiple images amplifies consistent generative traces, producing highly discriminative feature representations. We leverage this property by modelling the distribution of features extracted from averaged images and training a normalizing flow to align the feature space of individual images with this distribution. This alignment yields a likelihood-based criterion that separates real and fake samples while promoting strong generalisation. We evaluate $\mu$Flow on a fully out-of-distribution setting, where both real and fake datasets are unseen during training. Experimental results show that our method significantly outperforms SOTA detectors. Project page: https://opontorno.github.io/MuFlow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces μFlow, a one-class deepfake detector trained exclusively on real images. It observes that averaging multiple images amplifies consistent generative traces in feature space, trains a normalizing flow to model the distribution of features from these averaged real images, and uses likelihood scores on individual-image features (aligned to the same space) as the detection criterion. The central empirical claim is that this yields significantly better generalization than supervised SOTA detectors on a fully out-of-distribution test setting where both real and fake datasets are unseen during training.
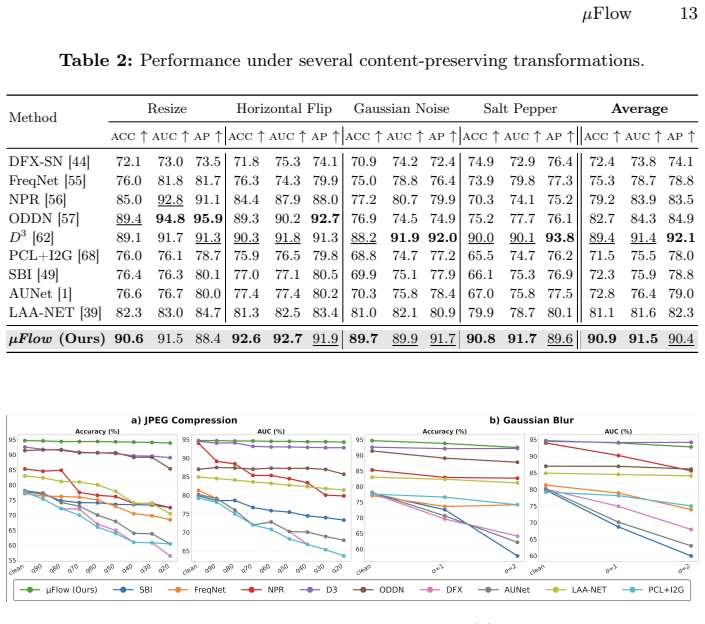
Significance. If the empirical results are robust, the work would offer a practical route to one-class deepfake detection that avoids reliance on fake samples or pseudo-artifacts, potentially improving cross-generator generalization (GANs to diffusion models). The use of averaging as a trace-amplification step and normalizing flows for likelihood-based separation is a coherent design choice that could be adopted more broadly if supported by detailed validation.
major comments (2)
- [Abstract] Abstract: the claim of 'significantly outperforms SOTA detectors' on fully OOD data is presented without any implementation details, ablation studies, error bars, dataset descriptions, or quantitative tables; the central generalization claim therefore cannot be evaluated from the supplied text.
- [Abstract] The weakest assumption (averaging reliably amplifies consistent generative traces in a way that permits a flow trained on averaged real features to separate individual real vs. fake images via likelihood) is stated but receives no supporting analysis or counter-example testing in the provided material.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the core modeling assumption. The full manuscript contains the requested details, analyses, and quantitative results, but we agree the abstract can be strengthened for clarity. We address each comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of 'significantly outperforms SOTA detectors' on fully OOD data is presented without any implementation details, ablation studies, error bars, dataset descriptions, or quantitative tables; the central generalization claim therefore cannot be evaluated from the supplied text.
Authors: The abstract is intentionally concise as a high-level summary. All requested elements are present in the manuscript: implementation details and architecture in Section 3, dataset descriptions and the fully OOD protocol in Section 4.1, quantitative tables with error bars in Tables 1–2, and ablation studies in Section 4.3. The generalization claim is evaluated on multiple unseen real and fake datasets (both GAN- and diffusion-based). We will revise the abstract to add a brief clause referencing the multi-dataset OOD evaluation setting. revision: partial
-
Referee: [Abstract] The weakest assumption (averaging reliably amplifies consistent generative traces in a way that permits a flow trained on averaged real features to separate individual real vs. fake images via likelihood) is stated but receives no supporting analysis or counter-example testing in the provided material.
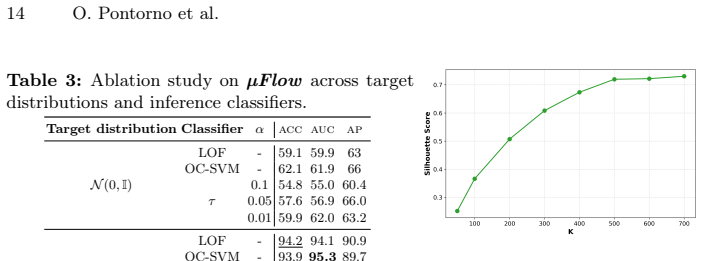
Authors: The abstract states the observation concisely due to length constraints. Supporting analysis appears in the body: Section 3.1 motivates the approach with feature visualizations demonstrating trace amplification via averaging, while Section 4.3 provides ablation studies and counter-examples showing degraded performance when averaging is removed. We will revise the abstract or introduction to explicitly reference this empirical support. revision: partial
Circularity Check
No significant circularity detected
full rationale
The abstract and supplied description present a one-class detector that averages real images to amplify traces, fits a normalizing flow to the resulting feature distribution, and uses likelihood on individual images for separation. No equations, parameter-fitting steps, self-citations, or uniqueness theorems are shown that would reduce any claimed prediction or result to its own inputs by construction. The approach relies on an empirical premise and standard normalizing-flow machinery without visible self-definitional loops or fitted-input renamings. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Bai, W., Liu, Y., Zhang, Z., Li, B., Hu, W.: Aunet: Learning relations between ac- tion units for face forgery detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 24709–24719 (2023)
2023
-
[2]
Black Forest Labs: FLUX.1: Open-weight 12b parameter text-to-image model (of- ficial announcement).https://bfl.ai/blog/24-08-01-bfl(2024), official launch announcement introducing the FLUX.1 model suite (whitepaper/blog post)
2024
-
[3]
Black Forest Labs: FLUX 1.1 [pro]: Advanced text-to-image generation model (2024),https://blackforestlabs.ai/1- 1- pro/, official documentation page (model description, not an academic paper)
2024
-
[4]
Bongini, P., Mandelli, S., Montibeller, A., Casu, M., Pontorno, O., Ragaglia, C.V., Zanchetta, L., Aquilina, M., Wani, T.M., Guarnera, L., Tondi, B., Boato, G., Bestagini, P., Amerini, I., De Natale, F., Battiato, S., Barni, M.: Wild: a new in-the-wild image linkage dataset for synthetic image attribution. In: 2025 International Joint Conference on Neural...
-
[5]
Chefer, H., Alaluf, Y., Vinker, Y., Wolf, L., Cohen-Or, D.: Attend-and-excite: Attention-basedsemanticguidancefortext-to-imagediffusionmodels.ACMTrans- actions on Graphics (Proc. SIGGRAPH)42(4), 148:1–148:10 (2023).https: //doi.org/10.1145/3592116 16 O. Pontorno et al
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Cho, W., Choi, S., Park, D.K., Shin, I., Choo, J.: Image-to-image translation via group-wise deep whitening-and-coloring transformation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10639– 10647 (2019)
2019
-
[7]
In: Pro- ceedings of the IEEE conference on computer vision and pattern recognition
Choi, Y., Choi, M., Kim, M., Ha, J.W., Kim, S., Choo, J.: Stargan: Unified gener- ative adversarial networks for multi-domain image-to-image translation. In: Pro- ceedings of the IEEE conference on computer vision and pattern recognition. pp. 8789–8797 (2018)
2018
-
[8]
Journal of Imaging9(2023).https: //doi.org/10.3390/jimaging9050089
Coccomini, D., Caldelli, R., Falchi, F., Gennaro, C.: On the generalization of deep learning models in video deepfake detection. Journal of Imaging9(2023).https: //doi.org/10.3390/jimaging9050089
-
[9]
ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP) pp
Corvi, R., Cozzolino, D., Zingarini, G., Poggi, G., Nagano, K., Verdoliva, L.: On the detection of synthetic images generated by diffusion models. ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP) pp. 1–5 (2022),https://api.semanticscholar.org/CorpusID: 253254809
2023
-
[10]
In: ICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Corvi, R., Cozzolino, D., Zingarini, G., Poggi, G., Nagano, K., Verdoliva, L.: On the detection of synthetic images generated by diffusion models. In: ICASSP 2023- 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5. IEEE (2023)
2023
-
[11]
2024 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition Workshops (CVPRW) pp
Cozzolino, D., Poggi, G., Corvi, R., Nießner, M., Verdoliva, L.: Raising the bar of ai-generated image detection with clip. 2024 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition Workshops (CVPRW) pp. 4356–4366 (2023), https://api.semanticscholar.org/CorpusID:265552100
2024
-
[12]
DeepAI: Deepai text-to-image generator (2024),https://deepai.org/machine- learning-model/text2img, online text-to-image generation service (documenta- tion page)
2024
-
[13]
In: 2009 IEEE conference on computer vision and pattern recognition
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: Imagenet: A large- scale hierarchical image database. In: 2009 IEEE conference on computer vision and pattern recognition. pp. 248–255. Ieee (2009)
2009
-
[14]
In: Pro- ceedings of the 35th International Conference on Neural Information Processing Systems
Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. In: Pro- ceedings of the 35th International Conference on Neural Information Processing Systems. NIPS ’21, Curran Associates Inc., Red Hook, NY, USA (2021)
2021
-
[15]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A.H., Chechik, G., Cohen-Or, D.: An image is worth one word: Personalizing text-to-image gen- eration using textual inversion. ArXivabs/2208.01618(2022),https://api. semanticscholar.org/CorpusID:251253049
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Advances in Neural In- formation Processing Systems27(2014)
Goodfellow, I.J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y.: Generative adversarial nets. Advances in Neural In- formation Processing Systems27(2014)
2014
-
[17]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops
Guarnera, L., Giudice, O., Battiato, S.: Deepfake detection by analyzing convo- lutional traces. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. pp. 666–667 (2020)
2020
-
[18]
Gudovskiy,D.,Ishizaka,S.,Kozuka,K.:Cflow-ad:Real-timeunsupervisedanomaly detection with localization via conditional normalizing flows. In: 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 1819–1828 (2022).https://doi.org/10.1109/WACV51458.2022.00188
-
[19]
IEEE transactions on image processing28(11), 5464–5478 (2019) µFlow 17
He, Z., Zuo, W., Kan, M., Shan, S., Chen, X.: Attgan: Facial attribute editing by only changing what you want. IEEE transactions on image processing28(11), 5464–5478 (2019) µFlow 17
2019
-
[20]
Advances in Neural Information Processing Systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems33, 6840–6851 (2020)
2020
-
[21]
Hotpot AI: Hotpot ai: Ai-powered image and text generation tools (2024),https: //hotpot.ai/, official website of Hotpot.ai image generator service
2024
-
[22]
In: International Conference on Learning Representations (ICLR) (2018)
Karras, T., Aila, T., Laine, S., Lehtinen, J.: Progressive growing of gans for im- proved quality, stability, and variation. In: International Conference on Learning Representations (ICLR) (2018)
2018
-
[23]
In: Advances in Neural Information Processing Systems 34 (NeurIPS 2021) (2021),https://proceedings.neurips
Karras, T., Aittala, M., Laine, S., Härkönen, E., Hellsten, J., Lehtinen, J., Aila, T.: Alias-free generative adversarial networks. In: Advances in Neural Information Processing Systems 34 (NeurIPS 2021) (2021),https://proceedings.neurips. cc/paper/2021/hash/076ccd93ad68be51f23707988e934906-Abstract.html
2021
-
[24]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Karras, T., Laine, S., Aila, T.: A style-based generator architecture for generative adversarial networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4401–4410 (2019)
2019
-
[25]
Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., Aila, T.: Analyzing and improving the image quality of StyleGAN. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8107–8116 (2020).https://doi.org/10.1109/CVPR42600.2020.00813
-
[26]
Kaur, A., Noori Hoshyar, A., Saikrishna, V., Firmin, S., Xia, F.: Deepfake video detection: challenges and opportunities. Artificial Intelligence Review57(6), 159 (May2024).https://doi.org/10.1007/s10462-024-10810-6,https://doi.org/ 10.1007/s10462-024-10810-6
-
[27]
Neural Networks160, 216–226 (2023)
Ke, J., Wang, L.: Df-udetector: An effective method towards robust deepfake de- tection via feature restoration. Neural Networks160, 216–226 (2023)
2023
-
[28]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops
Khalid, H., Woo, S.S.: Oc-fakedect: Classifying deepfakes using one-class varia- tional autoencoder. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. pp. 656–657 (2020)
2020
-
[29]
IEEE Access12, 1880–1908 (2023)
Khan, S.A., Dang-Nguyen, D.T.: Deepfake detection: analyzing model generaliza- tion across architectures, datasets, and pre-training paradigms. IEEE Access12, 1880–1908 (2023)
1908
-
[30]
Kim, G., Kwon, T., Ye, J.C.: Diffusionclip: Text-guided diffusion models for robust image manipulation. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2416–2425 (2022).https://doi.org/10.1109/ CVPR52688.2022.00246
-
[31]
Kingma,D.P.,Welling,M.:Auto-EncodingVariationalBayes.In:2ndInternational Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14- 16, 2014, Conference Track Proceedings (2014)
2014
-
[32]
In: Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R
Kingma, D.P., Dhariwal, P.: Glow: Generative flow with invertible 1x1 convolu- tions. In: Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R. (eds.) Advances in Neural Information Processing Systems. vol. 31. Curran Associates, Inc. (2018),https://proceedings.neurips.cc/paper_files/ paper/2018/file/d139db6a236200b21cc7f7529...
2018
-
[33]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Larue, N., Vu, N.S., Struc, V., Peer, P., Christophides, V.: Seeable: Soft discrep- ancies and bounded contrastive learning for exposing deepfakes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 21011–21021 (2023)
2023
-
[34]
Pattern Recognition Letters183, 64–70 (2024) 18 O
Leyva, R., Sanchez, V., Epiphaniou, G., Maple, C.: Data-agnostic face image synthesis detection using bayesian cnns. Pattern Recognition Letters183, 64–70 (2024) 18 O. Pontorno et al
2024
-
[35]
Li, Z., Zhang, J., Lin, Q., Xiong, J., Long, Y., Deng, X., Zhang, Y., Liu, X., Huang, M., Xiao, Z., Chen, D., He, J., Li, J., Li, W., Zhang, C., Quan, R., Lu, J., Huang, J., Yuan, X., Zheng, X., Li, Y., Zhang, J., Zhang, C., Chen, M., Liu, J., Fang, Z., Wang, W., Xue, J., Tao, Y., Zhu, J., Liu, K., Lin, S., Sun, Y., Li, Y., Wang, D., Chen, M., Hu, Z., Xia...
2024
-
[36]
Stability AI Official Blog (Feb 2024),https: //stability.ai/news/introducing- stable- cascade, official research preview announcement by Stability AI
Lopez, J.: Introducing stable cascade. Stability AI Official Blog (Feb 2024),https: //stability.ai/news/introducing- stable- cascade, official research preview announcement by Stability AI
2024
-
[37]
doi:10.1109/ICASSP49357.2023.10095889 , abstract =
Mejri, N., Ghorbel, E., Aouada, D.: Untag: Learning generic features for unsuper- vised type-agnostic deepfake detection. In: ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5 (2023). https://doi.org/10.1109/ICASSP49357.2023.10095983
-
[38]
Midjourney, Inc.: Midjourney (text-to-image generative service) (2022),https:// www.midjourney.com/, proprietary AI image generation model (no public technical paper)
2022
-
[39]
Nguyen, D., Mejri, N., Singh, I.P., Kuleshova, P., Astrid, M., Kacem, A., Ghorbel, E., Aouada, D.: Laa-net: Localized artifact attention network for quality-agnostic andgeneralizabledeepfakedetection.In:ProceedingsoftheIEEE/CVFConference on Computer Vision and Pattern Recognition. pp. 17395–17405 (2024)
2024
-
[40]
2023 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR) pp
Ojha, U., Li, Y., Lee, Y.J.: Towards universal fake image detectors that gen- eralize across generative models. 2023 IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition (CVPR) pp. 24480–24489 (2023),https://api. semanticscholar.org/CorpusID:257038440
2023
-
[41]
OpenAI: DALL·E 3 Technical Report (2024),https://cdn.openai.com/papers/ dall-e-3.pdf, official technical report
2024
-
[42]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: SDXL: Improving latent diffusion models for high-resolution im- age synthesis. In: International Conference on Learning Representations (ICLR) (2024),https://arxiv.org/abs/2307.01952, accepted to ICLR 2024 – arXiv preprint arXiv:2307.01952
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
In: 2024 IEEE international conference on image processing (ICIP)
Pontorno, O., Guarnera, L., Battiato, S.: On the exploitation of dct-traces in the generative-ai domain. In: 2024 IEEE international conference on image processing (ICIP). pp. 3806–3812. IEEE (2024)
2024
-
[44]
Multimedia Tools and Applications pp
Pontorno, O., Guarnera, L., Battiato, S.: Deepfeaturex-sn: Generalization of deep- fake detection via contrastive learning. Multimedia Tools and Applications pp. 1–20 (2025)
2025
-
[45]
Robertson, D.J., Kramer, R.S.S., Burton, A.M.: Face averages enhance user recog- nition for smartphone security. PLOS ONE10(3), 1–11 (03 2015).https:// doi.org/10.1371/journal.pone.0119460,https://doi.org/10.1371/journal. pone.0119460
-
[46]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-Resolution Image Synthesis with Latent Diffusion Models . In: 2022 IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR). pp. 10674–10685. IEEE Computer Society, Los Alamitos, CA, USA (Jun 2022).https://doi.org/ 10.1109/CVPR52688.2022.01042,https://doi.ieeecomputersociety...
-
[47]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., Aberman, K.: Dream- Booth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Genera- tion . In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR). pp. 22500–22510. IEEE Computer Society, Los Alamitos, CA, USA (Jun 2023).https://doi.org/10.1109/CVPR52729.2023....
-
[48]
In: Proceedings of the 36th International Conference on Neural Information Processing Systems
Saharia, C., Chan, W., Saxena, S., Lit, L., Whang, J., Denton, E., Ghasemipour, S.K.S., Ayan, B.K., Mahdavi, S.S., Gontijo-Lopes, R., Salimans, T., Ho, J., Fleet, D.J.,Norouzi,M.:Photorealistictext-to-imagediffusionmodelswithdeeplanguage understanding. In: Proceedings of the 36th International Conference on Neural Information Processing Systems. NIPS ’22,...
2022
-
[49]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Shiohara, K., Yamasaki, T.: Detecting deepfakes with self-blended images. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18720–18729 (2022)
2022
-
[50]
Neural Computing and Applications36(31), 19759–19775 (2024)
Soudy, A.H., Sayed, O., Tag-Elser, H., Ragab, R., Mohsen, S., Mostafa, T., Abo- hany, A.A., Slim, S.O.: Deepfake detection using convolutional vision transformers and convolutional neural networks. Neural Computing and Applications36(31), 19759–19775 (2024)
2024
-
[51]
Stability AI Official Blog (Oct 2023),https://stability.ai/news/introducing- stable- diffusion- 3- 5, of- ficial model release announcement
Stability AI: Introducing stable diffusion 3.5. Stability AI Official Blog (Oct 2023),https://stability.ai/news/introducing- stable- diffusion- 3- 5, of- ficial model release announcement
2023
-
[52]
In: Proceedings of the Winter Conference on Applications of Computer Vision (WACV) Workshops
Stamnas, S., Sanchez, V.: Difffake: Exposing deepfakes using differential anomaly detection. In: Proceedings of the Winter Conference on Applications of Computer Vision (WACV) Workshops. pp. 695–705 (February 2025)
2025
-
[53]
StarryAI:Starryai(aiartgenerator)(2023),https://starryai.com/,commercial text-to-image generator service (no academic publication)
2023
-
[54]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Tan, C., Tao, R., Liu, H., Gu, G., Wu, B., Zhao, Y., Wei, Y.: C2p-clip: Injecting category common prompt in clip to enhance generalization in deepfake detection. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 7184–7192 (2025)
2025
-
[55]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Tan, C., Zhao, Y., Wei, S., Gu, G., Liu, P., Wei, Y.: Frequency-aware deepfake detection: Improving generalizability through frequency space domain learning. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 5052–5060 (2024)
2024
-
[56]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tan, C., Zhao, Y., Wei, S., Gu, G., Liu, P., Wei, Y.: Rethinking the up-sampling operations in cnn-based generative network for generalizable deepfake detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 28130–28139 (2024)
2024
-
[57]
The 39th Annual AAAI Conference on Artificial Intelligence (AAAI 2025) (2024)
Tao, R., Le, M., Tan, C., Liu, H., Qin, H., Zhao, Y.: Oddn: Addressing unpaired data challenges in open-world deepfake detection on online social networks. The 39th Annual AAAI Conference on Artificial Intelligence (AAAI 2025) (2024)
2025
-
[58]
Network: computa- tion in neural systems14(3), 391 (2003)
Torralba, A., Oliva, A.: Statistics of natural image categories. Network: computa- tion in neural systems14(3), 391 (2003)
2003
-
[59]
Torralba, A., Oliva, A.: Statistics of natural image categories. Network: Com- putation in Neural Systems14(3), 391–412 (2003).https://doi.org/10.1088/ 0954-898X_14_3_302,https://doi.org/10.1088/0954-898X_14_3_302, pMID: 12938764
-
[60]
In: Proceedings 20 O
Wang, R.,Juefei-Xu, F., Ma, L., Xie, X., Huang, Y., Wang, J., Liu,Y.: Fakespotter: a simple yet robust baseline for spotting ai-synthesized fake faces. In: Proceedings 20 O. Pontorno et al. of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence. pp. 3444–3451 (2021)
2021
-
[61]
Xie, E., Chen, J., Chen, J., Cai, H., Tang, H., Lin, Y., Zhang, Z., Li, M., Zhu, L., Lu, Y., Han, S.: Sana: Efficient high-resolution image synthesis with linear diffusion transformer (2024),https://arxiv.org/abs/2410.10629, arXiv preprint – NVIDIA Research (SANA model)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Yang, Y., Qian, Z., Zhu, Y., Russakovsky, O., Wu, Y.: Dˆ 3: Scaling up deepfake detection by learning from discrepancy. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 23850–23859 (2025)
2025
-
[63]
ArXivabs/2306.08247 (2023),https://api.semanticscholar.org/CorpusID:259165446
Yang, Y., Wang, R., Qian, Z., Zhu, Y., Wu, Y.: Diffusion in diffusion: Cyclic one-way diffusion for text-vision-conditioned generation. ArXivabs/2306.08247 (2023),https://api.semanticscholar.org/CorpusID:259165446
-
[64]
ArXivabs/2503.19683(2025),https://api
Yermakov, A., Cech, J., Matas, J.: Unlocking the hidden potential of clip in generalizable deepfake detection. ArXivabs/2503.19683(2025),https://api. semanticscholar.org/CorpusID:277313445
-
[65]
arXiv preprint arXiv:2111.07677 (2021)
Yu, J., Zheng, Y., Wang, X., Li, W., Wu, Y., Zhao, R., Wu, L.: Fastflow: Unsuper- vised anomaly detection and localization via 2d normalizing flows. arXiv preprint arXiv:2111.07677 (2021)
-
[66]
In: Proceedings of the 1st on Deepfake Forensics Workshop: Detection, Attribution, Recognition, and Adversarial Challenges in the Era of AI-Generated Media
Yuan, Z., Wang, K., Quan, W., Yan, D.M., Wu, T.: Clip-flow: A universal discrim- inator for ai-generated images inspired by anomaly detection. In: Proceedings of the 1st on Deepfake Forensics Workshop: Detection, Attribution, Recognition, and Adversarial Challenges in the Era of AI-Generated Media. pp. 3–11 (2025)
2025
-
[67]
In: 2019 IEEE international workshop on information forensics and security (WIFS)
Zhang, X., Karaman, S., Chang, S.F.: Detecting and simulating artifacts in gan fake images. In: 2019 IEEE international workshop on information forensics and security (WIFS). pp. 1–6. IEEE (2019)
2019
-
[68]
In: Proceedings of the IEEE/CVF international conference on computer vision
Zhao, T., Xu, X., Xu, M., Ding, H., Xiong, Y., Xia, W.: Learning self-consistency for deepfake detection. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 15023–15033 (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.