Unlocking Compositional Generalization in Continual Few-Shot Learning
Pith reviewed 2026-05-20 21:35 UTC · model grok-4.3
The pith
By decoupling representation learning from compositional inference using frozen self-supervised Vision Transformers, models achieve superior generalization to novel concepts with minimal forgetting in continual few-shot learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
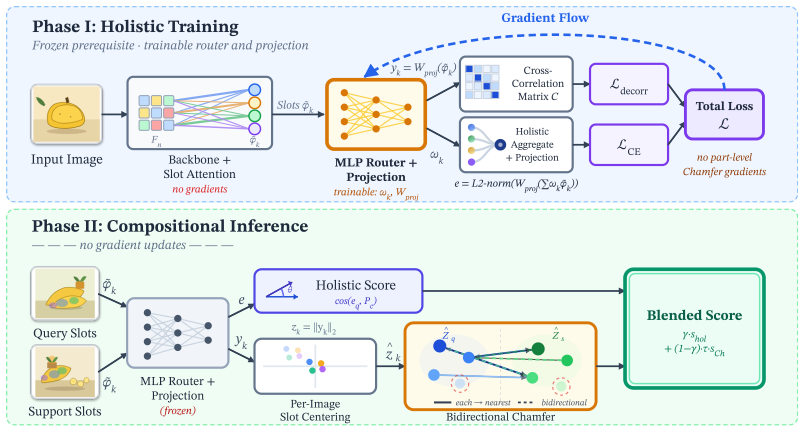
Leveraging the inherent patch-level semantic geometry of self-supervised Vision Transformers, the framework uses a dual-phase strategy where slot representations are optimized entirely toward holistic class identity during training to preserve generalizable object-level geometries, and at inference the preserved slots are dynamically composed to match novel scenes, offering dual benefits of no representation drift and preserved capacity for novel-concept transfer.
What carries the argument
The dual-phase strategy that decouples training-time holistic optimization of slots for class identity from inference-time dynamic composition, relying on the patch-level semantic geometry of self-supervised Vision Transformers.
If this is right
- The frozen backbone prevents representation drift across continual tasks.
- Holistic optimization during training maintains the features' ability to transfer to novel concepts.
- This results in state-of-the-art performance on unseen-concept generalization.
- Minimal forgetting is achieved across standard continual learning benchmarks.
Where Pith is reading between the lines
- This decoupling could be tested in other architectures beyond Vision Transformers to see if similar benefits emerge.
- The approach implies that general pre-trained geometries may suffice for composition if not specialized too narrowly during fine-tuning.
- Extending the method to multi-modal continual learning might reveal if the same separation principle applies to language or other data types.
Load-bearing premise
The patch-level semantic geometry in self-supervised Vision Transformers remains general and composable enough for novel concepts even when slots are optimized solely for holistic class identity.
What would settle it
A direct comparison on a benchmark featuring concepts with completely different visual structures from the training set, where the method shows equivalent or worse generalization than global embedding baselines, would falsify the claim.
Figures
read the original abstract
Object-centric representations promise a key property for few-shot learning: Rather than treating a scene as a single unit, a model can decompose it into individual object-level parts that can be matched and compared across different concepts. In practice, this potential is rarely realized. Continual learners either collapse scenes into global embeddings, or train with part-level matching objectives that tie representations too closely to seen patterns, leaving them unable to generalize to truly novel concepts. In this paper, we identify this fundamental structural conflict and pioneer a new paradigm that strictly decouples representation learning from compositional inference. Leveraging the inherent patch-level semantic geometry of self-supervised Vision Transformers (ViTs), our framework employs a dual-phase strategy. During training, slot representations are optimized entirely toward holistic class identity, preserving highly generalizable, object-level geometries. At inference, preserved slots are dynamically composed to match novel scenes. We demonstrate that this paradigm offers dual structural benefits: The frozen backbone naturally prevents representation drift, while our lightweight, holistic optimization preserves the features' capacity for novel-concept transfer. Extensive experiments validate this approach, achieving state-of-the-art unseen-concept generalization and minimal forgetting across standard continual learning benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a paradigm for continual few-shot learning that decouples representation learning from compositional inference. It leverages the inherent patch-level semantic geometry of self-supervised Vision Transformers by keeping the backbone frozen and optimizing slot representations exclusively toward holistic class identity during training. At inference, preserved slots are dynamically composed to match novel scenes. The approach claims dual benefits of preventing representation drift and preserving capacity for novel-concept transfer, achieving state-of-the-art unseen-concept generalization and minimal forgetting on standard continual learning benchmarks.
Significance. If the central claims hold, the work could meaningfully advance compositional generalization in continual few-shot settings by resolving the tension between stable representations and flexibility for unseen recombinations. The strategy of using pre-trained ViT patch geometry without part-level matching objectives during training is a clear strength, as is the explicit separation of training and inference phases. This could offer a simpler path than methods that tie representations closely to seen patterns.
major comments (2)
- [§3] §3 (Method): The claim that holistic slot optimization for class identity leaves the underlying patch-level semantic geometry of the frozen ViT untouched and recombinable for novel concepts is load-bearing for the central generalization argument, yet the manuscript provides no derivation, invariance analysis, or ablation demonstrating that the objective does not induce alignments that reduce flexibility for unseen object recombinations as tasks accumulate.
- [§5] §5 (Experiments): The abstract and results sections assert state-of-the-art performance on unseen-concept generalization and minimal forgetting, but without specific quantitative numbers, baseline comparisons, or ablation tables isolating the contribution of holistic optimization versus the frozen backbone, the strength of the empirical support cannot be fully assessed.
minor comments (1)
- [§3.1] The description of 'slots' and their relation to ViT patches could be introduced with more precise notation or a diagram in the early method section to improve clarity for readers unfamiliar with object-centric representations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address the major comments point by point below, outlining how we will strengthen the manuscript through targeted revisions.
read point-by-point responses
-
Referee: [§3] §3 (Method): The claim that holistic slot optimization for class identity leaves the underlying patch-level semantic geometry of the frozen ViT untouched and recombinable for novel concepts is load-bearing for the central generalization argument, yet the manuscript provides no derivation, invariance analysis, or ablation demonstrating that the objective does not induce alignments that reduce flexibility for unseen object recombinations as tasks accumulate.
Authors: We agree that an explicit analysis would better support this load-bearing claim. In the revised manuscript, we will add a short theoretical derivation showing that holistic class-identity optimization on frozen self-supervised ViT patches preserves their original semantic geometry (due to the absence of part-level matching losses). We will also include a new ablation that measures slot recombinability on held-out novel concept compositions after sequential tasks, directly comparing against part-level baselines to quantify retained flexibility. revision: yes
-
Referee: [§5] §5 (Experiments): The abstract and results sections assert state-of-the-art performance on unseen-concept generalization and minimal forgetting, but without specific quantitative numbers, baseline comparisons, or ablation tables isolating the contribution of holistic optimization versus the frozen backbone, the strength of the empirical support cannot be fully assessed.
Authors: The full manuscript already reports quantitative results and baseline comparisons in Section 5. To address the request for clearer isolation of contributions, we will expand the experiments with an additional ablation table that separately varies the holistic optimization objective and the frozen backbone, reporting exact numerical values for unseen-concept accuracy and forgetting on the standard benchmarks. revision: yes
Circularity Check
No circularity: claims rest on empirical validation of decoupled optimization rather than self-referential definitions or fitted predictions
full rationale
The paper's core argument identifies a structural conflict between representation learning and compositional inference, then proposes a dual-phase strategy that optimizes slots solely for holistic class identity while freezing the ViT backbone. No equations appear that define a target quantity in terms of itself or rename a fitted parameter as a prediction. The preservation of patch-level geometry is presented as an empirical property of self-supervised ViTs rather than a derived result that reduces to the training objective by construction. Central claims are supported by benchmark experiments on unseen-concept generalization and forgetting, which are falsifiable outside any internal fit. Self-citations, if present, are not load-bearing for the uniqueness of the paradigm.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-supervised Vision Transformers possess inherent patch-level semantic geometry that can be preserved for novel concepts.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
During training, slot representations are optimized entirely toward holistic class identity, preserving highly generalizable, object-level geometries. At inference, preserved slots are dynamically composed to match novel scenes.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We escape this trap via strict phase separation: Holistic training, and compositional inference.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Does Continual Learning Meet Compositionality?
Liao, Weiduo and Wei, Ying and Jiang, Mingchen and Zhang, Qingfu and Ishibuchi, Hisao , booktitle=. Does Continual Learning Meet Compositionality?
-
[2]
Mark McDonnell and Dong Gong and Amin Parvaneh and Ehsan Abbasnejad and Anton van den Hengel , booktitle=. Ran. 2023 , url=
work page 2023
-
[3]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Expandable Subspace Ensemble for Pre-Trained Model-Based Class-Incremental Learning , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[4]
Weighted Ensemble Models Are Strong Continual Learners , year =
Marouf, Imad Eddine and Roy, Subhankar and Tartaglione, Enzo and Lathuili\`. Weighted Ensemble Models Are Strong Continual Learners , year =. Computer Vision – ECCV 2024: 18th European Conference, Milan, Italy, September 29–October 4, 2024, Proceedings, Part LXXI , pages =. doi:10.1007/978-3-031-73209-6_18 , abstract =
-
[5]
Advances in Neural Information Processing Systems , volume=
Object-Centric Learning with Slot Attention , author=. Advances in Neural Information Processing Systems , volume=
-
[6]
The Eleventh International Conference on Learning Representations , year=
Bridging the Gap to Real-World Object-Centric Learning , author=. The Eleventh International Conference on Learning Representations , year=
-
[7]
Transactions on Machine Learning Research , issn=
Maxime Oquab and Timoth. Transactions on Machine Learning Research , issn=. 2024 , url=
work page 2024
-
[8]
Zhou, Jinghao and Wei, Chen and Wang, Huiyu and Shen, Wei and Xie, Cihang and Yuille, Alan and Kong, Tao , booktitle=. i
-
[9]
Proceedings of the 38th International Conference on Machine Learning , pages=
Learning Transferable Visual Models From Natural Language Supervision , author=. Proceedings of the 38th International Conference on Machine Learning , pages=
-
[10]
Proceedings of the 38th International Conference on Machine Learning , pages=
Barlow Twins: Self-Supervised Learning via Redundancy Reduction , author=. Proceedings of the 38th International Conference on Machine Learning , pages=
-
[11]
Bardes, Adrien and Ponce, Jean and LeCun, Yann , booktitle=
-
[12]
Learning robust global representations by penalizing local predictive power
SimpleShot: Revisiting Nearest-Neighbor Classification for Few-Shot Learning , author=. arXiv preprint arXiv:1911.04623 , year=
-
[13]
FEAT: Few-Shot Learning via Embedding Adaptation with Set-to-Set Functions , author=. CVPR , year=
- [14]
-
[15]
Compositional Few-Shot Class Incremental Learning , author=. Preprint , year=
-
[16]
Compositional Zero-Shot Learning via Fine-Grained Dense Feature Composition , author=. NeurIPS , year=
-
[17]
Learning Graph Embeddings for Compositional Zero-Shot Learning , author=. CVPR , year=
-
[18]
On the Interaction of Variance Objectives and Classification Losses , author=. Preprint , year=
-
[19]
Eva-02: A visual representation for neon genesis,
EVA-02: A Visual Representation for Neon Genesis , author=. arXiv preprint arXiv:2303.11331 , year=
-
[20]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =
Caron, Mathilde and Touvron, Hugo and Misra, Ishan and J\'egou, Herv\'e and Mairal, Julien and Bojanowski, Piotr and Joulin, Armand , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , month =. 2021 , pages =
work page 2021
- [21]
-
[22]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Zou, Yixiong and Zhang, Shanghang and Zhou, Haichen and Li, Yuhua and Li, Ruixuan , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
work page 2024
-
[23]
Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence,
Evolutionary Generalized Zero-Shot Learning , author =. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence,. 2024 , month =. doi:10.24963/ijcai.2024/70 , url =
-
[24]
The Fourteenth International Conference on Learning Representations , year=
Plug-and-Play Compositionality for Boosting Continual Learning with Foundation Models , author=. The Fourteenth International Conference on Learning Representations , year=
-
[25]
Bootstrap your own latent a new approach to self-supervised learning , year =
Grill, Jean-Bastien and Strub, Florian and Altch\'. Bootstrap your own latent a new approach to self-supervised learning , year =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
-
[26]
Proceedings of the 37th International Conference on Machine Learning , articleno =
Chen, Ting and Kornblith, Simon and Norouzi, Mohammad and Hinton, Geoffrey , title =. Proceedings of the 37th International Conference on Machine Learning , articleno =. 2020 , publisher =
work page 2020
-
[27]
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture , author=. 2023 , eprint=
work page 2023
-
[28]
International Conference on Learning Representations , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations , year=
- [29]
-
[30]
Learning Multiple Layers of Features from Tiny Images , author=
-
[31]
Wah, C. and Branson, S. and Welinder, P. and Perona, P. and Belongie, S. , institution=. The Caltech-
-
[32]
Advances in Neural Information Processing Systems , pages=
Matching Networks for One Shot Learning , author=. Advances in Neural Information Processing Systems , pages=
-
[33]
Hendrycks, Dan and Basart, Steven and Mu, Norman and Kadavath, Saurav and Wang, Frank and Dorundo, Evan and Desai, Rahul and Zhu, Tyler and Parajuli, Samyak and Guo, Mike and Song, Dawn and Steinhardt, Jacob and Gilmer, Justin , booktitle=. The Many Faces of Robustness:
-
[34]
Masked Autoencoders Are Scalable Vision Learners , booktitle =
He, Kaiming and Chen, Xinlei and Xie, Saining and Li, Yanghao and Doll. Masked Autoencoders Are Scalable Vision Learners , booktitle =. 2022 , pages =
work page 2022
-
[35]
Zhuang, Huiping and Liu, Yuchen and He, Run and Tong, Kai and Zeng, Ziqian and Chen, Cen and Wang, Yi and Chau, Lap-Pui , booktitle =. F-OAL: Forward-only Online Analytic Learning with Fast Training and Low Memory Footprint in Class Incremental Learning , url =. doi:10.52202/079017-1314 , editor =
-
[36]
Provable Compositional Generalization for Object-Centric Learning , author=. 2024 , eprint=
work page 2024
-
[37]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Reproducible Scaling Laws for Contrastive Language-Image Learning , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
- [38]
-
[39]
Vardan Papyan and X. Y. Han and David L. Donoho , title =. Proceedings of the National Academy of Sciences , volume =. 2020 , doi =. https://www.pnas.org/doi/pdf/10.1073/pnas.2015509117 , abstract =
-
[40]
LeJEPA: Provable and Scalable Self-Supervised Learning Without the Heuristics , author=. 2025 , eprint=
work page 2025
-
[41]
Computational Optimal Transport: With Applications to Data Science , publisher =
Peyr. Computational Optimal Transport: With Applications to Data Science , publisher =. 2019 , series =
work page 2019
-
[42]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Cuturi, Marco , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[43]
Learning Generative Models with
Genevay, Aude and Peyr. Learning Generative Models with. Proceedings of the 21st International Conference on Artificial Intelligence and Statistics (AISTATS) , series =. 2018 , publisher =
work page 2018
-
[44]
and Belanger, David and Linderman, Scott W
Mena, Gonzalo E. and Belanger, David and Linderman, Scott W. and Snoek, Jasper , title =. International Conference on Learning Representations (ICLR) , year =
-
[45]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Luise, Giulia and Rudi, Alessandro and Pontil, Massimiliano and Ciliberto, Carlo , title =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[46]
Interpolating between Optimal Transport and
Feydy, Jean and S. Interpolating between Optimal Transport and. Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics (AISTATS) , series =. 2019 , publisher =
work page 2019
- [47]
-
[48]
SIAM Journal on Optimization , volume =
Bolte, J. SIAM Journal on Optimization , volume =. 2007 , doi =
work page 2007
-
[49]
Proceedings of the 35th International Conference on Machine Learning (ICML) , pages =
Attention-based Deep Multiple Instance Learning , author =. Proceedings of the 35th International Conference on Machine Learning (ICML) , pages =. 2018 , publisher =
work page 2018
-
[50]
Dipam Goswami and Yuyang Liu and Bart. Fe. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[51]
SCIENCE CHINA Information Sciences , year=
PILOT: A Pre-Trained Model-Based Continual Learning Toolbox , author=. SCIENCE CHINA Information Sciences , year=
-
[52]
Continual learning with pre-trained models: A survey , author=. IJCAI , pages=
-
[53]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Zhou, Da-Wei and Wang, Qi-Wei and Qi, Zhi-Hong and Ye, Han-Jia and Zhan, De-Chuan and Liu, Ziwei , title =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.